Понятное руководство по 6 типам SQL JOIN: что делают, чем отличаются и когда применять. Примеры запросов, типичные ошибки и советы по производительности.
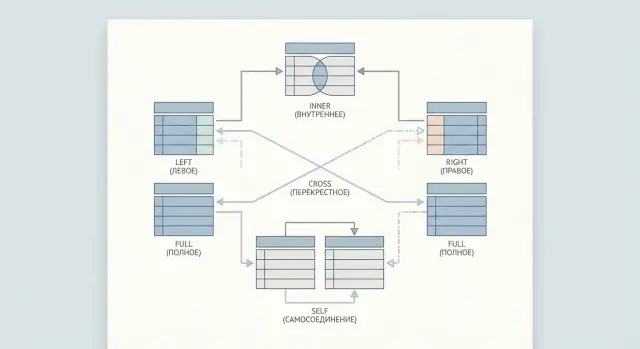
JOIN — это способ «склеить» данные из двух (или больше) таблиц в один результат запроса. В аналитике JOIN нужен, чтобы собрать единую картину: кто пользователь, что он заказал, оплатил ли заказ, когда это произошло и т. д. В приложениях JOIN помогает получать связанные данные за один запрос вместо серии отдельных запросов.
Важно помнить: результат JOIN — это таблица строк, а не «подстановка полей». База данных берёт строки из одной таблицы и сопоставляет их со строками из другой по условию.
NULL в колонках второй таблицы (например, LEFT JOIN).Полезный мысленный вопрос при чтении результата: «Сколько строк справа подходит к одной строке слева?» Он почти сразу объясняет, почему итоговый набор вырос.
id.ON (например, одинаковый user_id).Представим 3 таблицы:
users(id, name) — пользователи.orders(id, user_id, created_at, total) — заказы пользователя.payments(id, order_id, paid_at, amount) — оплаты заказа.Типичная цепочка в аналитике: users → orders → payments. Здесь JOIN отвечает на практические вопросы: какие пользователи делали заказы, сколько заказов у каждого, какие заказы остались без оплаты (в результате будут NULL по полям payments). Дальше разберём типы JOIN и научимся заранее понимать, какие строки попадут в итог и почему.
INNER JOIN — самый «строгий» вид соединения: он возвращает только те строки, для которых нашлась пара в обеих таблицах по условию ON. Если соответствия нет — строка просто не попадает в результат.
Представим две таблицы:
users(id, name) — список пользователейorders(id, user_id, created_at) — заказы, где user_id указывает на users.idЛогика INNER JOIN здесь простая: в выдаче окажутся только пользователи, у которых есть хотя бы один заказ (и сами заказы, которые им соответствуют).
ON и алиасами)SELECT
u.id,
u.name,
o.id AS order_id,
o.created_at
FROM users AS u
INNER JOIN orders AS o
ON o.user_id = u.id;
Как читать результат:
INNER JOIN удобно использовать, когда вам важны только активные клиенты, и «пустые» записи будут мешать анализу. Например, чтобы получить список пользователей, которые делали заказы за последний месяц:
SELECT DISTINCT
u.id,
u.name
FROM users AS u
INNER JOIN orders AS o
ON o.user_id = u.id
WHERE o.created_at >= CURRENT_DATE - INTERVAL '30 day';
Здесь INNER JOIN гарантирует: в список попадут только те, у кого реально есть заказ, а DISTINCT убирает повторы пользователей, если заказов было несколько.
Совет: условие связи держите в ON, а фильтры по датам/статусам — в WHERE. Так запрос проще читать и проверять.
LEFT JOIN нужен, когда «левая» таблица — основная, и вы хотите сохранить все её строки, даже если в правой таблице для части строк нет соответствий. В таких случаях столбцы справа заполнятся NULL.
Простой пример: у нас есть users и orders. Мы хотим увидеть всех пользователей и, если есть, их заказы.
SELECT
u.user_id,
u.email,
o.order_id,
o.created_at
FROM users u
LEFT JOIN orders o
ON o.user_id = u.user_id;
Примечание: в реальных схемах названия ключевых колонок могут различаться (id vs user_id, id vs order_id). Важно не имя поля, а смысл: вы соединяете PK↔FK (или иной уникальный ключ↔ссылка).
Критически важно понимать: условия в ON влияют на то, как соединяются таблицы, а условия в WHERE — на итоговый набор строк после соединения.
Если вы хотите ограничить правую таблицу, но при этом сохранить всех пользователей, фильтр обычно должен быть в ON:
SELECT u.user_id, o.order_id
FROM users u
LEFT JOIN orders o
ON o.user_id = u.user_id
AND o.status = 'paid';
Если написать WHERE o.status = 'paid', то пользователи без заказов (у которых o.status = NULL) исчезнут — это частая ловушка.
Один из самых полезных сценариев LEFT JOIN — поиск «нехваток»: кто есть в левой таблице, но отсутствует в правой.
SELECT u.user_id, u.email
FROM users u
LEFT JOIN orders o
ON o.user_id = u.user_id
WHERE o.user_id IS NULL;
Такой приём часто называют anti-join: мы соединяем, а затем оставляем только строки, где «пара» справа не нашлась.
Если после LEFT JOIN вы в WHERE проверяете столбцы правой таблицы на конкретные значения (WHERE o.created_at >= ..., WHERE o.status = ...), вы почти всегда отсекаете NULL и тем самым превращаете запрос в аналог INNER JOIN. Если цель — сохранить все строки слева, переносите такие условия в ON или используйте проверки с учётом NULL.
RIGHT JOIN полезен, когда вам важно сохранить все строки из правой таблицы, даже если в левой для них нет пары. По смыслу это «зеркало» LEFT JOIN, но на практике его используют реже: большинство команд предпочитает единый стиль и просто меняет таблицы местами, оставляя LEFT JOIN.
RIGHT JOIN.Пусть есть таблицы users и orders. Хотим получить все заказы, даже если пользователя уже нет в users.
Вариант с RIGHT JOIN:
SELECT
o.order_id,
o.user_id,
u.email
FROM users u
RIGHT JOIN orders o
ON u.user_id = o.user_id;
То же самое через LEFT JOIN — просто переставляем таблицы:
SELECT
o.order_id,
o.user_id,
u.email
FROM orders o
LEFT JOIN users u
ON u.user_id = o.user_id;
Результат будет одинаковым: если пользователь удалён или не найден, поля u.* станут NULL, но заказ останется.
Это частый сценарий для аналитики: заказы — факты, пользователи — справочник. «Потерять» заказ из-за отсутствующего пользователя нельзя, поэтому базовая таблица здесь — orders.
Выберите один стиль и придерживайтесь его:
orders, events, payments) — в FROM;users, products) — через LEFT JOIN;JOIN ... ON ... на новых строках.Так быстрее читать запросы и проще замечать ошибки в условиях ON.
FULL OUTER JOIN — это соединение, которое сохраняет строки с обеих сторон. Если для строки из левой таблицы нашлась пара справа — вы получите объединённую строку. Если пары нет — строка всё равно попадёт в результат, а недостающие поля второй таблицы будут заполнены NULL. То же самое работает и для строк из правой таблицы.
Главный сценарий — сверка данных из двух источников и поиск расхождений. Например:
В таких задачах FULL OUTER JOIN удобен тем, что сразу показывает три группы: совпавшие записи, «только слева» и «только справа».
Если после соединения вы видите NULL-значения только в колонках правой таблицы, это значит: запись есть слева, но не нашлось соответствия справа.
Если NULL-значения только в колонках левой таблицы, это наоборот: запись есть справа, но отсутствует слева.
Важно: интерпретируйте NULL аккуратно. NULL в результате может означать не только «нет пары», но и «в исходной таблице поле реально было NULL». Поэтому для определения отсутствия пары лучше проверять ключевую колонку второй таблицы.
Некоторые системы (например, MySQL в классическом виде) не имеют FULL OUTER JOIN. Идея обхода простая: сделать LEFT JOIN (все слева) и добавить к нему строки, которые есть только справа, через UNION (обычно UNION ALL + фильтр). Детали реализации зависят от СУБД и ключей, но логика всегда одна: «всё слева» + «всё справа, чего не было слева».
CROSS JOIN — это соединение «каждый с каждым». Он возвращает декартово произведение: для каждой строки из первой таблицы берётся каждая строка из второй.
Звучит просто, но именно поэтому это опасно: 10 000 строк × 10 000 строк = 100 000 000 строк результата. Часто CROSS JOIN «случайно» появляется из-за пропущенного условия ON в обычном JOIN — и запрос внезапно начинает считаться минутами.
Есть несколько нормальных сценариев, где «все комбинации» — то, что нужно:
Ключевой признак «здорового» CROSS JOIN: хотя бы одна из таблиц — маленький справочник или искусственно ограниченный набор.
Ограничивайте входные наборы до CROSS JOIN: фильтруйте даты, статусы, актуальные версии.
Джойните маленькие справочники (10–100 строк), а не «сырые» факты.
Сразу добавляйте ограничения после: например, отсекайте невозможные комбинации по условиям WHERE.
Ниже — заготовка «плановой сетки»: на каждый день месяца создаём строки для каждого тарифа, чтобы затем подтянуть факт и сравнить.
WITH days AS (
SELECT generate_series(date '2025-12-01', date '2025-12-31', interval '1 day')::date AS day
),
plans AS (
SELECT tariff_id, planned_revenue
FROM tariff_plan
WHERE month = date '2025-12-01'
)
SELECT
d.day,
p.tariff_id,
p.planned_revenue
FROM days d
CROSS JOIN plans p;
Такой результат удобно дальше соединять с фактом по (day, tariff_id) и сразу видеть пропуски: где план есть, а факта нет (или наоборот).
SELF JOIN — это обычный JOIN, только таблица соединяется сама с собой. Чтобы SQL понимал, где «левая», а где «правая» сторона, используют алиасы (псевдонимы): например, employees e и employees m.
SELF JOIN полезен, когда связь находится внутри одной таблицы: одна строка ссылается на другую (иерархия), либо вы сравниваете записи между собой (поиск дублей, конфликтов, несостыковок).
Предположим, в таблице employees есть id, name, manager_id (ссылка на employees.id). Тогда руководителя можно «подтянуть» так:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
Почему часто именно LEFT JOIN: у верхнего руководителя manager_id может быть NULL, и сотрудник всё равно должен остаться в выдаче.
Если нужно найти возможные дубли по email/телефону, удобнее сравнивать строки попарно, исключая «саму себя»:
SELECT
a.id AS id1,
b.id AS id2,
a.email
FROM users a
JOIN users b
ON a.email = b.email
AND a.id < b.id;
Условие a.id < b.id убирает зеркальные пары (1–2 и 2–1) и совпадение строки с самой собой.
ON: если перепутать ключи (например, e.id = m.id вместо e.manager_id = m.id), получите «самосовпадения» или бессмысленную выборку.a.id < b.id, и результат раздувается вдвое.manager_id, запрещать самоссылки и отслеживать циклы отдельной проверкой.Большинство «странных» результатов JOIN возникают не из-за самого JOIN, а из-за неверно выбранных ключей и условий в ON. Если заранее понять, какие поля действительно связывают таблицы, вы избежите дубликатов, потерянных строк и неожиданного раздувания выборки.
Идеальный сценарий — соединять первичный ключ (PK) одной таблицы с внешним ключом (FK) другой. PK гарантирует уникальность, а FK — корректную ссылку.
Если вы соединяете неуникальные поля (например, city или status), то легко получить много совпадений на одну строку — и результат умножится.
Иногда «ключ» — это комбинация полей: например, заказ в разрезе магазина и номера заказа. Тогда соединение делайте по всем частям составного ключа.
SELECT *
FROM orders o
JOIN payments p
ON o.shop_id = p.shop_id
AND o.order_id = p.order_id;
Если забыть одно поле (например, shop_id), вы рискуете склеить записи из разных магазинов и получить лишние строки.
NULL никогда не равен NULL, поэтому условие o.user_id = u.user_id не соединит строки, где оба значения NULL. Это обычно полезно: «неизвестные» идентификаторы не должны совпадать.
Но важно понимать последствия:
INNER JOIN строки с NULL в ключе просто исчезнут;LEFT JOIN они останутся слева, но поля справа будут NULL.Если вам нужно явно исключить такие строки, добавляйте фильтр в ON, чтобы не превратить LEFT JOIN в скрытый INNER JOIN через WHERE:
SELECT *
FROM orders o
LEFT JOIN users u
ON o.user_id = u.user_id
AND o.user_id IS NOT NULL;
Перед JOIN ответьте себе: связь один-к-одному, один-ко-многим или многие-ко-многим?
LEFT JOIN) или совпадений (для INNER JOIN).Практический тест: сравните количество строк до и после JOIN и проверьте, какой ключ даёт дубликаты (например, COUNT(*) vs COUNT(DISTINCT ...)). Если рост неожиданный — проблема почти всегда в ON.
Даже «правильный» JOIN может внезапно дать в 2–10 раз больше строк, странные суммы или исчезнувшие записи. Хорошая новость: большинство проблем повторяются — и их можно быстро диагностировать несколькими проверками.
Самая частая причина — вы соединяете сущность «один ко многим» (клиент → заказы) или даже «многие ко многим» (товары ↔ категории), а ожидаете одну строку на клиента.
Быстрая проверка: сравните количество строк до и после JOIN и посмотрите, какие ключи размножаются.
-- какие id стали встречаться чаще
select a.id, count(*) as cnt
from a
join b on b.a_id = a.id
group by a.id
having count(*) > 1
order by cnt desc;
Исправление: агрегируйте «правую» таблицу до нужной зернистости до соединения (подзапрос/CTE) или соединяйте по уникальному ключу.
Если вы делаете LEFT JOIN, но затем фильтруете поля правой таблицы в WHERE, вы часто превращаете его в INNER JOIN и теряете строки без пары.
Плохой паттерн:
select *
from a
left join b on b.a_id = a.id
where b.status = 'paid';
Лучше переносить фильтр в ON, сохраняя строки из A:
select *
from a
left join b
on b.a_id = a.id
and b.status = 'paid';
Суммы и количества «раздуваются», когда одна строка факта (например, заказ) после JOIN превращается в несколько строк (например, по позициям заказа). Симптом: общая сумма выше ожидаемой.
Защита: агрегируйте на уровне факта до JOIN, либо считайте уникальные сущности (например, count(distinct order_id)), либо используйте подзапрос, который возвращает одну строку на ключ.
Соединение по неуникальным полям (имя, город, дата рождения) почти гарантирует ложные совпадения и дубли. Даже если «сейчас работает», позже появится второй «Иван Петров» — и отчёт незаметно испортится.
Правило: соединяйте по стабильным ключам (id, внешний ключ), а текстовые поля используйте только для отображения. Для диагностики ищите значения, у которых в правой таблице больше одной строки на ключ.
JOIN почти всегда упирается в объём данных и то, как быстро СУБД находит строки по ключам. Хорошая новость: несколько привычек дают заметный прирост без «магии» и риска сломать логику.
Чаще всего помогает индекс на колонках, которые участвуют в ON: например, orders.customer_id и (обычно уже есть) customers.id. Если соединение идёт по нескольким полям, иногда нужен составной индекс в том же порядке, что и в условии.
Важно: индекс на внешнем ключе особенно полезен в LEFT JOIN, когда справа таблица большая.
SELECT * вреденВ больших JOIN SELECT * заставляет читать и передавать лишние столбцы, увеличивает память на сортировки/хеши и нагрузку на сеть.
Лучше перечислять только нужные поля и думать, из какой таблицы они берутся:
SELECT o.order_id, o.created_at, c.name
FROM orders o
JOIN customers c ON c.id = o.customer_id;
Дешевле соединять меньше строк.
Пример: сначала выбрать заказы за период, и только их присоединять к справочнику.
Откройте EXPLAIN/EXPLAIN ANALYZE и проверьте:
Seq Scan по большой таблице там, где ожидали индекс;Если план показывает огромный промежуточный результат, начните с предфильтрации и явного списка столбцов — это самые безопасные шаги.
Когда сомневаетесь, начните с вопроса: «какие строки обязаны быть в результате?»
Представим:
users(id, email)orders(id, user_id, created_at)payments(id, order_id, status)SELECT u.id, o.id AS order_id
FROM users u
JOIN orders o ON o.user_id = u.id;
SELECT u.id, COUNT(o.id) AS orders_cnt
FROM users u
LEFT JOIN orders o ON o.user_id = u.id
GROUP BY u.id;
SELECT o.id AS order_id, p.id AS payment_id
FROM orders o
FULL OUTER JOIN payments p ON p.order_id = o.id
WHERE o.id IS NULL OR p.id IS NULL;
SELECT u.id, s.status
FROM users u
CROSS JOIN (SELECT 'paid' AS status UNION ALL SELECT 'failed') s;
orders.user_id есть NULL?Держите в памяти простую опору: INNER — только пары, LEFT/RIGHT — «все с одной стороны», FULL — «все вообще», CROSS — «все комбинации», SELF — «связь внутри таблицы». Если результат вдруг «раздулся» или исчезли строки — первым делом перепроверьте ключи и условие ON.
Если вы не только пишете запросы, но и собираете внутренние инструменты/витрины для команды, удобно сразу закладывать правильные JOIN‑паттерны в прототип. Например, в TakProsto.AI (vibe‑coding платформа для российского рынка) можно в формате чата быстро собрать веб‑панель или небольшой сервис: React‑интерфейс, Go‑бэкенд с PostgreSQL, а затем итеративно дорабатывать SQL‑запросы, сохраняя снапшоты и откатываясь при необходимости. Это особенно полезно, когда вы отлаживаете кардинальность (1:N, N:N), переносите фильтры из WHERE в ON и проверяете, что отчёт не теряет строки и не раздувает суммы.
JOIN соединяет строки из двух таблиц по условию в ON.
INNER JOIN строка пропадёт, при LEFT JOIN останется с NULL справа.Полезная привычка: перед выполнением запроса спросить себя «сколько строк справа может соответствовать одной строке слева?» — это сразу объясняет рост результата.
INNER JOIN возвращает только пары строк, которые удовлетворяют условию ON.
Практический признак: если у сущности слева нет связанной записи справа, её не будет в результате вообще.
Типичный сценарий — «показать только активных»: пользователи, у которых есть заказы, или заказы, у которых есть платежи.
LEFT JOIN сохраняет все строки из левой таблицы и добавляет данные справа, если пара нашлась.
Используйте его, когда левая таблица — «основа отчёта»:
Отсутствие пары справа проявляется как NULL в колонках правой таблицы.
Правило простое:
ON — определяет, как строятся пары строк.WHERE — фильтрует готовый результат после JOIN.Если после LEFT JOIN поставить в WHERE условие на правую таблицу (например, WHERE o.status = 'paid'), строки без пары (где o.status = NULL) исчезнут — и запрос станет похож на INNER JOIN.
Чтобы сохранить строки слева, фильтры по правой таблице чаще переносите в ON:
LEFT JOIN orders o
ON o.user_id = u.id
AND o.status = 'paid'
Самый распространённый приём — LEFT JOIN + проверка IS NULL по ключу правой таблицы.
SELECT u.id, u.email
FROM users u
LEFT JOIN orders o ON o.user_id = u.id
WHERE o.user_id IS NULL;
Важно проверять именно ключ/идентификатор правой таблицы (или FK), а не произвольное поле, которое само по себе может быть NULL в данных.
RIGHT JOIN — «зеркало» LEFT JOIN: сохраняет все строки справа.
На практике его часто заменяют перестановкой таблиц и LEFT JOIN, чтобы придерживаться одного стиля:
-- эквивалент RIGHT JOIN
FROM orders o
LEFT JOIN users u ON u.id = o.user_id
Выбирайте вариант, который проще читать команде: чаще всего это «факты в FROM, справочники через LEFT JOIN».
FULL OUTER JOIN сохраняет строки с обеих сторон: совпавшие склеиваются, несовпавшие остаются с NULL на отсутствующей стороне.
Это удобно для сверок:
Чтобы отфильтровать расхождения, обычно проверяют ключи:
WHERE a.id IS NULL OR b.id IS NULL
Если FULL OUTER JOIN недоступен, собирают результат из двух частей:
LEFT JOIN)LEFT JOIN в обратную сторону + фильтр IS NULL)И объединяют через UNION ALL.
Ключевая идея: (всё слева) + (всё справа, чего не было слева).
CROSS JOIN даёт декартово произведение: каждая строка первой таблицы соединяется с каждой строкой второй.
Чтобы не получить взрыв строк:
CROSS JOIN (даты/статусы);rows(A) × rows(B).Частая причина «случайного» CROSS JOIN — забытое условие ON в обычном JOIN.
SELF JOIN нужен, когда связь хранится в той же таблице (иерархия или сравнение записей).
Два частых паттерна:
FROM employees e
LEFT JOIN employees m ON e.manager_id = m.id
JOIN users b ON a.email = b.email AND a.id < b.id
Всегда используйте алиасы и внимательно проверяйте условие ON, чтобы не получить самосовпадения или лишние пары.