Разбираем, как Atlassian вырос из командного инструмента в корпоративный стандарт: механика внедрения снизу вверх, роль экосистемы и путь к enterprise.
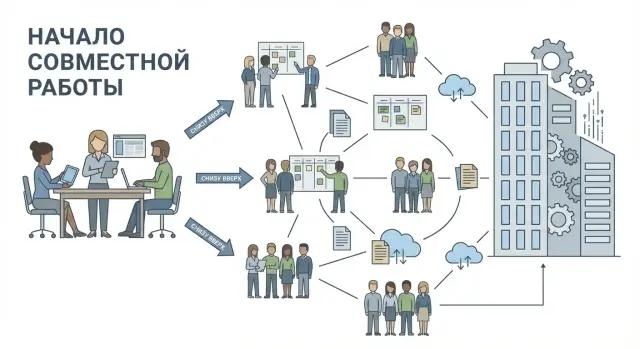
Внедрение снизу вверх (bottoms‑up adoption) — это сценарий, при котором продукт сначала «подхватывает» одна команда (или даже несколько людей), закрывая конкретную задачу, а затем использование естественно расширяется на соседние команды и уровень управления.
В отличие от классического внедрения через ИТ/закупки, стартовая точка здесь — не тендер и не приказ, а понятная ценность «здесь и сейчас».
При top‑down подходе компания сначала выбирает платформу, согласует бюджет, требования безопасности, обучение, а затем пытается «посадить» на инструмент всех сразу. Это даёт контроль и единообразие на старте, но часто плохо разгоняется: пользователи не всегда видят смысл менять привычные процессы.
Bottoms‑up работает наоборот: доказательство пользы появляется до большого решения. Команда начинает с малого (например, ведёт задачи в Jira или оформляет базу знаний в Confluence), показывает скорость и прозрачность — и уже на основе результата руководству проще поддержать масштабирование.
У продуктов класса Atlassian внутри одной компании быстро возникает сетевой эффект: как только часть людей ведёт работу в общем пространстве, остальным проще подключиться, чем оставаться «снаружи». Ценность совместной работы заметна быстро: меньше потерянных договорённостей, понятнее статус задач, проще онбординг новичков.
Обычно всё начинается с локальной боли: хаос в задачах, дублирование документов, отсутствие владельцев. Команда настраивает простой процесс, получает измеримый выигрыш (по срокам, качеству, снижению ручных согласований) и делает это повторяемой практикой: шаблоны, правила именования, минимальные роли.
Чтобы рост не превратился в «зоопарк», нужны несколько условий: ясные правила игры (что считаем стандартом), лёгкая поддержка для новых команд, прозрачная модель прав и доступа и момент, когда подключаются админы/безопасность — не слишком рано, но до того, как появятся десятки разрозненных инстансов и подходов.
Внедрение снизу вверх работает, когда продукт позволяет получить ощутимую пользу без «большого запуска» и без очереди на согласования. В логике Atlassian это видно особенно хорошо: один небольшой кейс запускается быстро, а дальше инструмент «притягивает» соседние команды через совместную работу.
Типичный старт — не корпоративная программа, а локальная инициатива: команда заводит пространство под проект, переносит текущие задачи, фиксирует договорённости и уже в первые часы получает видимость прогресса.
Ключевое условие — минимум настроек: базовые шаблоны, понятные сущности (задача, страница, комментарий) и привычные действия (назначить, обсудить, согласовать) дают быстрый эффект.
Рост начинается там, где продукт закрывает повседневные боли без обучения «с нуля»:
Чем меньше команде приходится выдумывать процесс самостоятельно, тем быстрее появляется привычка: открыл — сделал — увидел результат.
Дальше включается внутрикорпоративный сетевой эффект. Как только проект становится кросс‑командным, возникает естественная потребность «встречаться» в одном месте: общая доска задач, единые страницы с требованиями, прозрачные решения и история изменений.
Пригласить коллегу проще, чем пересылать статусы и файлы вручную — и это приглашение превращается в следующую точку роста.
Когда нескольким командам удобно взаимодействовать в одном инструменте, появляются повторяемые паттерны: одинаковые статусы, типы задач, шаблоны страниц, правила именования. Так продукт становится общим языком компании — не потому что его навязали, а потому что он экономит время и снижает количество ошибок в совместной работе.
Рост внедрения снизу вверх почти всегда стартует не с «решения компании», а с конкретной команды, у которой болит здесь и сейчас. Atlassian‑стек хорошо ложится на такие ситуации: можно начать с малого, быстро показать пользу и только потом расширять практику на соседние отделы.
Чаще всего первыми пользователями становятся:
Общий паттерн: инструмент выбирают те, кто отвечает за результат, а не за «владение системой». Поэтому старт обычно быстрый и прагматичный.
Хаос в задачах: задачи живут в чатах, письмах и таблицах; невозможно понять, что в работе и кто владелец.
Разрозненные документы: требования, решения и инструкции раскиданы по файлам; новички долго входят в контекст.
Отсутствие прозрачности: статус приходится «выбивать» вручную, встречи превращаются в пересказ того, что уже сделано.
В этих точках Jira/Confluence воспринимаются не как «ещё одна система», а как способ договориться о правилах работы.
На ранней стадии редко считают сложные метрики — обычно смотрят на практические изменения:
Частые стоп‑факторы: слишком сложные процессы, спор «как правильно», разрозненные схемы прав доступа и страх «мы настроим не так».
Практичный обходной путь: начать с минимального шаблона (например, один проект и несколько статусов), зафиксировать правила на одной странице, назначить владельца пространства/проекта и расширять только после первых результатов. Это снижает порог входа и даёт ощущение контроля без тяжёлой бюрократии.
У внедрения снизу вверх есть простое правило: продукт сначала должен «заработать» внутри небольшой команды, а монетизация — аккуратно подхватить уже появившуюся ценность. Поэтому тарифы — это не только про деньги, но и про то, какие сценарии вы поощряете.
Классическая модель, которую хорошо понимают пользователи продуктов Atlassian‑класса: бесплатный или очень доступный старт для малых команд, а дальше — расширение по мере того, как инструмент становится стандартом.
Важно, чтобы бесплатный уровень решал реальную задачу (например, прозрачность задач в команде или единое место для документации), а не был «демо‑режимом». Тогда расширение происходит естественно: добавляются новые пользователи, появляются дополнительные команды, возрастает критичность процессов.
Апгрейд должен быть логичным продолжением роста, а не платой за базовую ценность. Работают триггеры, которые пользователи воспринимают как справедливые:
Формула простая: «Когда инструмент становится общим и важным, вам понадобятся контроль и гарантии».
Две крайности встречаются чаще всего:
Хороший тест: человек должен понять различия тарифов за 60 секунд, не читая мелкий шрифт.
Страница /pricing должна объяснять, за что платят, без обещаний «автоматически повысим эффективность». Лучше писать через конкретные возможности и ситуации:
И добавьте короткие примеры «кому подходит» (команда, департамент, организация) — это помогает пользователю самому найти путь роста без участия продаж.
Когда внедрение идёт снизу вверх, сначала выигрывает скорость: каждая команда настраивает Jira/Confluence «под себя» и быстро получает пользу. Но на этапе масштабирования возникает обратная сторона — разнородные статусы, разные названия задач, десятки похожих проектов и пространств.
Единые практики нужны не ради контроля, а чтобы рост не превращался в хаос и не тормозил подключение новых команд.
Стандарты снижают стоимость входа. Новая команда получает готовый workflow, набор полей, типовые дашборды и шаблоны страниц — и начинает работать сразу, не изобретая велосипед.
Второй эффект — сопоставимость. Руководству и смежным командам проще понимать прогресс, риски и загрузку, когда «Blocked» означает одно и то же, а SLA и приоритеты читаются одинаково.
Рабочий подход — «80/20»: организация задаёт базовый каркас, а команды дополняют его под свою специфику.
Важно фиксировать не «как всем работать», а какой результат должен получиться (прозрачность, предсказуемость, безопасность) и через какие настройки это достигается.
Шаблоны — самый мягкий инструмент стандартизации: команда видит лучший вариант по умолчанию и редко хочет «сделать хуже».
Хорошо работают:
Центр экспертизы (CoE) при этом не должен быть «комитетом согласований». Его роль — поддерживать библиотеку шаблонов, проводить регулярные ревизии и помогать командам мигрировать на общий стандарт без боли.
Заранее введите простые правила гигиены: периодическая инвентаризация, обязательный владелец для каждого проекта/пространства, понятные критерии «живого» и «архивного».
И главное — удобный каталог: где искать существующие доски, пространства и шаблоны, чтобы не создавать копии.
Низовое внедрение обычно начинается с простого: команда «поставила себе» Jira или Confluence и начала решать локальную боль. Но как только продукт становится межкомандным и в нём появляется чувствительная информация (планы релизов, инциденты, клиентские данные), неизбежно подключаются ИТ, безопасность и комплаенс.
Это не «тормоз», а переход на следующий уровень зрелости.
Типовой триггер — рост числа пользователей и проектов: появляется потребность в единой идентичности и управлении доступами. В корпоративной реальности быстро всплывают три требования:
Важно заранее показать, что эти вещи поддерживаются и что их можно включать по мере роста — без остановки работы команд.
Лучше всего работает язык рисков и контроля. Не «нам так удобнее», а:
Практичный принцип — минимально необходимые права: доступ выдаётся по роли и задаче, а не «всем на всякий случай».
Параллельно фиксируется модель владения данными: кто владелец пространства/проекта, кто утверждает доступ, кто отвечает за жизненный цикл (архивирование, удаление, ретеншн).
Чтобы подключение админов и комплаенса прошло быстро, обычно собирают пакет:
Этот набор снижает количество встреч и переводит обсуждение из эмоций в проверяемые требования.
Интеграции часто становятся тем переломным моментом, когда продукт из «ещё одного инструмента» превращается в рабочий центр команды.
Для Atlassian‑стека это особенно заметно: Jira, Confluence и смежные продукты связывают задачи, знания, коммуникации и отчётность в один непрерывный процесс — без ручных копирований и «потерянных» статусов.
Когда карточка задачи автоматически подтягивает контекст (документы, требования, обсуждения, инциденты), у команды появляется единый источник правды. Важен не сам коннектор, а снижение стоимости переключения: меньше ручной рутины, меньше расхождений в данных, быстрее принятие решений.
Инструмент закрепляется как слой координации между разными функциями (разработка, поддержка, продукт, безопасность), потому что соединяет их привычные системы, а не заставляет всех мигрировать «в одну коробку».
Маркетплейс расширяет продуктовую ценность без бесконечного добавления функций в ядро. Партнёрские приложения закрывают отраслевые требования, локальные процессы, специфичную отчётность — и позволяют начать с малого, сохраняя общий стандарт.
Но «поставить плагин» — это ещё и управленческое решение: вы добавляете в контур новую логику, новые данные и иногда — новые зависимости.
Хороший фильтр простой:
Чтобы экосистема не превратилась в «зоопарк», заранее договоритесь о правилах: каталог одобренных интеграций, владельцы по доменам (например, ITSM, разработка, knowledge base), периодический пересмотр и деактивация неиспользуемого.
Практика, которая работает: вводить лёгкий процесс запроса интеграции с кратким обоснованием пользы и оценкой рисков — быстрее, чем полный закупочный цикл, но достаточно, чтобы сохранить контроль над безопасностью и данными.
Внедрение снизу вверх редко становится стандартом «само по себе». Почти всегда за ростом стоят внутренние чемпионы — люди, которые первыми получают пользу, умеют объяснить её другим и готовы потратить время на распространение практик.
Это не обязательно менеджеры: часто чемпионами становятся тимлиды, скрам‑мастера, аналитики, инженеры по качеству или руководители проектов.
Чемпион — это переводчик ценности на язык конкретной команды. Он не продаёт инструмент, а решает прикладную задачу: «как перестать терять запросы», «как синхронизировать работы между командами», «как прозрачно вести изменения».
Дальше включается простой эффект: когда появляется понятный шаблон и быстрый выигрыш, соседние команды начинают просить «сделайте нам так же».
Важно, что чемпионы формируют не только привычку пользоваться Jira/Confluence, но и нормы: как заводить задачи, как писать требования, как документировать решения, как проводить ретро. Именно эти нормы потом становятся основой корпоративной стандартизации.
Чтобы чемпионам было проще масштабировать практику, им нужны готовые активы, которые можно переиспользовать без долгой подготовки:
Чем меньше ручной работы, тем выше шанс, что локальный успех будет повторён в других подразделениях.
Сообщество пользователей превращает разрозненные инициативы в устойчивую систему. Хорошо работают регулярные ритмы:
Когда чемпионы появляются в нескольких командах, инициативу можно поднять на уровень программы: назначить владельца (обычно из PMO/Operations/IT), зафиксировать минимальные стандарты и метрики (активные пользователи, доля проектов по шаблону, время онбординга).
Дальше — формальная поддержка: каталог рекомендованных шаблонов, понятный путь запросов и признание чемпионов (роль, время в планах, доступ к обучению). Так bottoms‑up остаётся живым, но получает управляемость — без продаж «в лоб» и без лишней бюрократии.
Внедрение снизу вверх часто начинается как «инициатива команды», но в какой‑то момент продукт становится критичным для десятков групп. Тогда появляется новая реальность: ИТ, безопасность и закупки ждут не энтузиазм, а управляемость — и именно здесь аккаунт «взрослеет».
Признаки, что самообслуживания уже недостаточно и стоит вовлекать Sales/CS (даже если рост был органическим):
Закупкам важны не «лучшие практики», а предсказуемость и минимизация рисков. Обычно запрашивают:
Частый сценарий выглядит так: пилот в одной команде → расширение на несколько команд/департаментов → стандартизация как «рекомендованный инструмент» → корпоративный контракт.
Ключевой переход — от разрозненных подписок к единому владельцу процесса: кто администрирует, кто утверждает новые пространства/проекты, кто отвечает за жизненный цикл пользователей.
Вместо завышенных обещаний лучше собрать «папку решения»: реальные кейсы внутренних команд, перечень снятых болей, примеры стандартизации (шаблоны, процессы), требования ИТ и то, как они закрываются.
Финансовую часть безопаснее строить на наблюдаемой экономии времени и снижении операционных рисков, явно обозначая допущения и границы применимости.
Рост «снизу вверх» хорош скоростью, но в большой компании он почти неизбежно создаёт побочные эффекты. Если их не заметить вовремя, удобный набор инструментов превращается в набор разрозненных инсталляций, правил и ожиданий.
Команды приходят со своими привычками: разные статусы задач, разные определения «готово», разные ритуалы. Когда появляются общие отчёты или межкомандные зависимости, выясняется, что одинаковые слова означают разное.
Сдерживать это помогает не «один процесс для всех», а базовый каркас: минимальный набор обязательных полей, единые принципы именования, несколько рекомендованных шаблонов под типовые сценарии (разработка, поддержка, проекты). Важно оставить место для локальных особенностей — иначе будет сопротивление и обход правил.
Слишком лёгкий вход провоцирует появление множества отдельных пространств, проектов и автоматизаций, о которых ИТ и безопасность узнают постфактум. Это ведёт к разным правам доступа, утечкам контекста и невозможности собрать целостную картину по инициативам.
Практика: заранее определить, где создаются новые проекты/пространства, кто утверждает доступы, какие данные нельзя хранить вне корпоративных контуров и как выглядит «правильный» запрос на интеграцию. Чем понятнее путь «как можно», тем меньше соблазн делать «как получится».
На масштабе легко увлечься: отдельные workflow «под каждую команду», десятки кастомных полей, уникальные схемы прав и автоматизации. В итоге обновления и поддержка дорожают, обучение усложняется, а миграции становятся болезненными.
Полезное правило: сначала стандартизировать 80% типовых случаев и только затем разрешать исключения — с обоснованием, владельцем и сроком пересмотра.
Управляемость достигается не запретами, а распределённой ответственностью:
Так масштабирование сохраняет главное достоинство внедрения снизу вверх — инициативу команд — и при этом остаётся предсказуемым для ИТ, безопасности и руководителей.
Bottoms‑up подход применим не только к системам управления работой, но и к платформам, которые помогают быстро создавать внутренние продукты. Например, TakProsto.AI — это vibe‑coding платформа для российского рынка: команда может в формате чата собрать веб‑, серверное или мобильное приложение (React, Go + PostgreSQL, Flutter), быстро развернуть, подключить домен, а при необходимости — экспортировать исходники.
Почему это хорошо ложится на внедрение снизу вверх:
Отдельно важно для enterprise‑контекста: TakProsto.AI работает на серверах в России, использует локализованные и open‑source LLM‑модели и не отправляет данные за пределы страны — это упрощает ранние разговоры с ИТ и безопасностью.
Если вы хотите повторить подход Atlassian, начните не с «большого внедрения», а с условий, при которых продукт сам себя распространяет: быстрый старт, понятная ценность, безопасное расширение на соседние команды.
Найдите 1–2 команды с острой болью (хаос задач, согласования, потеря знаний) и дайте им сценарий, который можно запустить за день.
Цель — не идеальная настройка, а измеримый результат за 2–3 недели.
Как только появляются новые команды, заранее подготовьте минимум стандартов: нейминг, шаблоны, роли, владение пространствами/проектами.
Это снижает энтропию без бюрократии и облегчает подключение ИТ.
Лучший способ понять возможности ТакПросто — попробовать самому.