Разбираем Blue/Green и Canary: как работают, чем отличаются, риски, метрики, маршрутизация трафика и пошаговые сценарии внедрения.
Стратегия деплоя — это заранее определённый способ выпускать изменения в продакшн так, чтобы снизить риск поломок и по возможности избежать простоя сервиса. Проще говоря, это ответ на вопрос: «как именно мы доставляем новую версию пользователям и что делаем, если что-то пошло не так».
Даже небольшое изменение может повлиять на производительность, совместимость или пользовательский опыт. Если выкатывать обновления «в лоб» (перезапустили сервис — и готово), вы рискуете получить недоступность, всплеск ошибок или сложный откат.
Стратегии развертывания помогают выпускать изменения более предсказуемо: ограничивать радиус поражения, быстрее находить проблему и возвращаться в стабильное состояние.
Главные задачи:
«Простой» выкат уместен, если сервис внутренний, нагрузка невысокая, есть окно обслуживания и цена ошибки небольшая.
Стратегии (вроде Blue/Green или Canary) особенно нужны, когда важен нулевой простой сервиса, много пользователей, изменения частые, а откат усложнён состоянием (миграции базы, кэши, очереди, зависимые сервисы). В таких случаях управление трафиком, метрики и заранее продуманный план отката — это базовая гигиена релизов.
Blue/Green деплой — это схема, где у вас есть два одинаковых окружения: условно Blue (текущее продакшен-окружение) и Green (готовится новая версия). Релиз сводится к тому, чтобы развернуть новую версию в «неактивном» окружении, проверить её и затем переключить трафик на него одним управляемым действием.
Типовой поток выглядит так: вы деплоите новую версию в Green, при необходимости прогреваете кэш/инициализируете фоновые задачи, выполняете smoke‑тесты и только потом меняете маршрутизацию на уровне балансировщика или ingress (например, в Kubernetes через Service/Ingress или через внешний L7/L4 балансировщик). В идеале переключение занимает секунды и почти не заметно пользователям.
Под окружением обычно понимают не только сами приложения, но и всё, что влияет на поведение:
Ключевая идея: Blue и Green должны быть максимально симметричны, иначе вы переключаете трафик на «другую систему», а не на новую версию.
Пока Green ещё не виден пользователям, его можно проверить без риска:
Хорошая практика — заранее определить, какие метрики и алерты считаются блокирующими для переключения (например, всплеск 5xx или рост времени ответа).
Даже корректно запущенная версия может деградировать после прихода реального трафика. Поэтому Green полезно прогреть:
Переключение делайте атомарно: один «рычаг» (правило маршрутизации), понятный команде и зафиксированный в runbook.
Типовой сценарий отката:
Главное преимущество Blue/Green деплоя — быстрый rollback. Но он «идеален» только при продуманной совместимости версий и миграций.
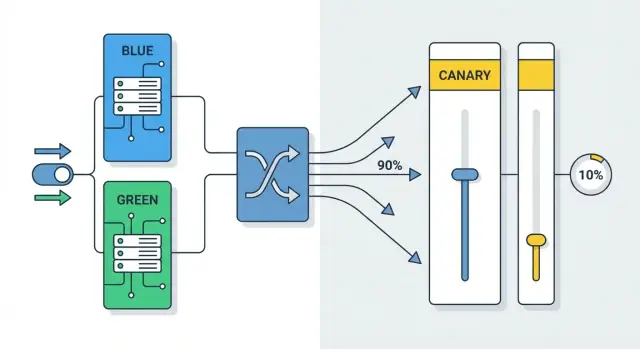
Canary‑релиз — это стратегия, при которой новая версия сервиса получает сначала очень небольшой процент реального трафика, а основная нагрузка продолжает идти на стабильную версию. Название отсылает к «канарейке в шахте»: если что-то пошло не так, проблемы проявятся рано и затронут минимальное число пользователей.
На практике это выглядит так: у вас параллельно работают две версии приложения (старая и новая), а маршрутизация распределяет запросы между ними по долям. Новая версия может быть выделена как отдельный deployment/ReplicaSet в Kubernetes или как отдельный пул инстансов за балансировщиком.
Обычно долю повышают ступенчато, проверяя здоровье системы на каждом шаге:
Шаги могут быть другими (например, 1–10–50–100) и часто зависят от критичности сервиса и времени наблюдения между повышениями.
Главный плюс Canary — раннее выявление проблем на реальном трафике: ошибки интеграций, рост латентности, неожиданные эффекты кэшей и очередей обычно проявляются быстрее, чем в тестовой среде.
Минус — повышенные требования к наблюдаемости и управлению маршрутизацией. Нужно уметь точно разделять трафик, сравнивать метрики старой и новой версий и быстро остановить раскатку (или вернуть долю к нулю), если показатели ухудшаются.
Канареечный релиз ценен только тогда, когда заранее понятно, что считать «успехом», а что — сигналом остановки. Иначе команда рискует либо пропустить деградацию, либо остановить релиз из‑за шума в данных.
Сравнивайте канарейку с контрольной группой (старая версия) на одном и том же временном окне.
Зафиксируйте правила до начала раскатки:
Важно договориться, кто принимает решение и сколько времени отводится на анализ, чтобы релиз не «зависал».
Выбор аудитории влияет на качество выводов. Частые варианты: по регионам, по сегментам (новые/возвращающиеся), по аккаунтам (внутренние, бета‑клиенты), по устройствам/каналам.
Практика: начинать с наименее рискованных сегментов, но не делать выборку слишком «идеальной» — иначе проблемы проявятся уже после полного включения.
Следите, чтобы группы были сопоставимы: одинаковые источники трафика, время суток, объём запросов. Избегайте одновременных изменений (маркетинговая акция, миграция БД, новый тариф) — они маскируют эффект релиза.
И закладывайте защиту от шума: минимальный объём событий, сглаживание кратких всплесков и проверка метрик на нескольких срезах (ошибки + латентность + бизнес‑результат), а не по одному сигналу.
Обе стратегии помогают выпускать изменения без простоя и снижать риск, но делают это по-разному: Blue/Green опирается на переключение между двумя окружениями, а Canary — на постепенное расширение доли трафика на новую версию.
| Фактор | Blue/Green | Canary |
|---|---|---|
| Стоимость | Выше: нужно 2 полноценных окружения | Обычно ниже: можно обойтись одним окружением и управлением трафиком |
| Риск | Ниже при корректных проверках: переключение контролируемое | Ниже при «плавном» росте: ошибка затронет часть пользователей |
| Скорость отката | Очень высокая: вернуться на Blue — секунды/минуты | Средняя: нужно уменьшать долю трафика и учитывать состояние |
| Сложность | Средняя: переключение, прогрев, проверка окружений | Выше: маршрутизация по долям, метрики/алерты, анализ качества |
| Подходит для изменений | Хорошо для крупных релизов и инфраструктурных изменений | Отлично для продуктовых и рискованных изменений на реальном трафике |
Blue/Green часто выигрывает там, где важен быстрый откат и чёткий контроль точки переключения:
Компромисс: вы платите ресурсами за второе окружение и должны заранее продумать совместимость версий с базой данных.
Canary особенно полезен в системах, где важно проверить поведение на живом трафике и контролировать качество релиза по метрикам:
Компромисс: нужна зрелая наблюдаемость (метрики/алерты, ошибки, латентность) и аккуратная работа с состоянием (сессии, очереди, фоновые джобы).
Практическое правило: если главный страх — «не смогу быстро откатить», начинайте с Blue/Green. Если главный страх — «не увижу проблему без реального трафика», выбирайте Canary (или комбинируйте с Blue/Green).
У Blue/Green и Canary всё держится на том, насколько точно вы умеете управлять потоком запросов. Даже хороший релиз «падает» на практике, если маршрутизация не позволяет гарантированно направить нужную долю трафика на нужную версию и быстро вернуть всё назад.
L4/L7‑балансировщик (NGINX/HAProxy, облачные LB) — самый универсальный уровень. Для Blue/Green достаточно переключить upstream или target group. Для Canary нужен весовой роутинг (например, 95/5) и возможность быстро поставить 0/100.
Ingress‑контроллер в Kubernetes упрощает управление правилами на уровне кластера. Типовые требования: поддержка весов, заголовков/куки для маршрутизации, health‑checks, предсказуемые таймауты.
Service mesh (Istio/Linkerd) даёт самый точный контроль: процент трафика, правила по заголовкам, зеркалирование запросов, ретраи/таймауты на уровне сервиса. Это удобно для Canary, но добавляет сложность эксплуатации.
Липкие сессии могут «запереть» пользователя на старой версии и исказить метрики Canary. Частые проблемы: несовместимый формат сессии, разные ключи шифрования, хранение состояния в памяти пода.
Что делать: выносить сессии в общий стор (Redis), использовать совместимые схемы данных, учитывать affinity при подсчёте долей и тестировать переключение на реальных сценариях авторизации.
Кэш и CDN способны незаметно смешать версии: один пользователь получает старый JS, другой — новый API. Помогают:
Для Blue/Green важно, чтобы оба окружения имели одинаковые секреты и политики доступа, иначе переключение превратится в инцидент. Для Canary — чтобы новая версия не получала лишних прав «на всякий случай».
Практический минимум: единый секрет‑менеджмент, принцип наименьших привилегий, изоляция сетевых политик между версиями, отдельные сервис‑аккаунты и аудит изменений перед переключением трафика.
Чтобы Blue/Green и Canary были безопасными, нужно заранее договориться, по каким сигналам вы решаете: «релиз успешен» или «пора откатывать». Наблюдаемость — это не «много графиков», а минимальный набор измерений, который даёт уверенность при переключении трафика.
Базовый технический набор — «4 золотых сигнала»:
Поверх этого добавьте бизнес‑метрики (конверсия, успешные оплаты, создание заказов, скорость обработки) и формализуйте SLO: например, «успешные запросы 99.9% за 30 дней» или «p95 < 300 мс для /checkout». Именно SLO помогает разруливать спорные случаи: «метрики чуть хуже, но в пределах цели».
Минимум для релиза:
Авто‑rollback имеет смысл только при строгих правилах:
Сделайте один релизный дашборд, где все графики продублированы по двум срезам: stable vs canary (или blue vs green). Обязательно: error‑rate, p95/p99, RPS, saturation, а также 1–2 бизнес‑метрики. Такой «двойной» вид ускоряет решение: продолжать раскатку, заморозить или откатить.
Blue/Green и Canary проще всего выглядят на уровне приложения: развернули новую версию, направили на неё часть трафика, при проблемах откатили. Но база данных — общий узел, который хранит состояние и редко бывает продублирован без боли. Именно поэтому миграции схемы и совместимость версий часто определяют, получится ли у вас нулевой простой сервиса.
При Blue/Green две версии приложения могут работать параллельно, а при Canary — точно работают параллельно. Если новая версия требует изменений схемы (колонка стала обязательной, поменялся тип, удалили таблицу), старая версия может начать падать или писать некорректные данные. В результате «переключение трафика» превращается в рискованную операцию, а не в управляемый шаг.
Практика, которая чаще всего спасает: делать миграции обратно‑совместимыми.
Expand/contract:
Ключевое правило: опасные изменения (удаление, переименование, ужесточение NOT NULL без дефолта) — только на этапе contract.
Если новая функциональность требует новой схемы, разделяйте «готовность схемы» и «включение фичи».
Используйте feature flags: сначала раскатываете код, который умеет работать и со старой схемой, и с новой (например, читает новое поле при наличии, иначе — старое). Затем выполняете expand‑миграции, прогрев и валидацию, и только после этого включаете фичу по флагу — сначала для небольшой доли пользователей.
База данных — не единственный источник состояния. Если у вас есть очереди/шина событий, деплой ломается и там.
event_type:v2) и поддерживайте чтение нескольких версий.Так вы сохраняете возможность Canary‑релиза без каскадных падений потребителей событий и без срочного rollback из‑за несовместимых контрактов.
Даже при Blue/Green и Canary иногда приходится срочно возвращаться к стабильной версии — или, наоборот, быстро выпускать исправление поверх проблемной. Важно заранее выбрать, какой сценарий у вас «по умолчанию», и какие данные/очереди при этом не пострадают.
Rollback (откат) — переключение на предыдущую версию при деградации метрик, ошибках или регрессии. Он уместен, когда:
Rollforward (вперёд) — выпуск исправления (hotfix) и продолжение движения вперёд. Он предпочтителен, когда:
При инциденте часто страдают не только запросы, но и фоновые задачи. Перед откатом/переключением проверьте:
Если вы используете события и очереди, откат приложения без отката форматов сообщений может сломать потребителей. Поэтому версионируйте контракты и поддерживайте обратную совместимость.
Авто‑откат экономит минуты, но требует строгих ограничений: ясные пороги (5xx, latency, saturation), окна наблюдения и защита от ложных срабатываний.
Ручной откат оправдан, если симптомы неоднозначны или требуется координация (например, остановка воркеров, блокировка опасных операций, включение feature flags).
После инцидента соберите короткий постмортем без поиска виноватых:
Хороший результат — когда следующий релиз проходит с тем же функционалом, но с меньшим риском повторения инцидента.
Автоматизация релизов важна не сама по себе, а как способ сделать Blue/Green деплой и Canary релиз повторяемыми: одинаковые шаги, одинаковые проверки, фиксируемые решения. Хороший CI/CD пайплайн снижает риск «ручных» ошибок и ускоряет rollback и rollforward.
Обычно поток выглядит так: сборка → тесты → деплой → проверка → переключение/расширение трафика.
На этапе сборки полезно сразу закрепить принцип неизменяемости: артефакт собирается один раз и дальше только продвигается по окружениям.
Отдельно полезно предусмотреть «операционные артефакты релиза»: runbook, список стоп‑сигналов, ссылки на релизный дашборд — чтобы релиз не зависел от знаний одного человека.
«Гейт» — это правило, которое не позволяет пайплайну двигаться дальше.
Для Canary удобно делать несколько гейтов на разных процентах трафика (1% → 10% → 50% → 100%). Для Blue/Green — один ключевой гейт перед cutover.
Версионируйте не только код, но и конфигурации: значения Helm/Kustomize, манифесты, параметры feature flags. Практика immutable images (например, тег по SHA) упрощает откат: вы точно знаете, что именно было запущено.
Чётко определите, кто и что делает:
Так контроль релиза остаётся предсказуемым даже при нулевом простое сервиса и сложном управлении трафиком.
Если вы делаете внутренние сервисы, админки или продуктовые прототипы и не хотите раздувать «классический» пайплайн на ранней стадии, часть задач можно закрывать платформенно. В TakProsto.AI (vibe‑coding платформа для российского рынка) вы собираете web/server/mobile приложение через чат, а дальше используете встроенные механики деплоя и хостинга, снапшоты и откаты, кастомные домены и режим planning mode для согласования изменений до выката.
Это не заменяет дисциплину Blue/Green или Canary в продакшене высоконагруженного продукта, но хорошо помогает быстрее довести идею до работающей версии, а затем — при необходимости — экспортировать исходный код и встроить проект в ваш привычный CI/CD.
В Kubernetes обе стратегии обычно собираются из одних и тех же примитивов, разница — в маршрутизации трафика.
Для Blue/Green чаще используют два набора Deployments (blue и green) и один стабильный Service, который указывает селектором на активный набор pod’ов. Переключение — смена селектора (или метки у pod’ов). Если входящий трафик идёт через Ingress, важно, чтобы он всегда вёл на один и тот же Service.
Для Canary нужен механизм разделения трафика: это может быть ingress‑контроллер с весами, service mesh или отдельный прокси‑слой. Суть — часть запросов идёт на canary Deployment, остальная — на стабильный.
Инструменты progressive delivery (без привязки к конкретному продукту) обычно добавляют:
Подготовка: определите SLO и стоп‑сигналы (пороги алертов), заведите dashboard, договоритесь о владельце релиза.
Совместимость: убедитесь, что новая версия может работать со старой (API/схемы), используйте feature flags для «выключаемых» изменений.
Первый релиз: начните с Canary 1–5% и коротких интервалов оценки; для Blue/Green заранее отрепетируйте переключение и возврат.
Расширение практики: автоматизируйте шаги в CI/CD, добавьте runbook и регулярные «учения» по откату.