Разбираем идеи оркестрации, связанные с Brendan Burns и Kubernetes: декларативное состояние, контроллеры, масштабирование и сервисные операции, ставшие стандартом.
Контейнеры упростили упаковку приложения: «собрал — запустил — работает». Но как только сервисов становится больше одного, выясняется, что запуск контейнера — это лишь начало. Нужно развернуть десятки экземпляров, обновлять их без простоя, распределять нагрузку, следить за здоровьем и быстро поднимать упавшие компоненты. Вручную или скриптами это быстро превращается в хрупкий набор соглашений, который держится на опыте отдельных инженеров.
В реальной эксплуатации команды снова и снова упираются в одни и те же задачи:
Оркестрация нужна, чтобы эти задачи решались системой, а не людьми каждый раз заново.
Когда подходы стандартизированы, новый сервис запускается по знакомому шаблону, а команды говорят на одном языке: «Deployment», «Service», «реплики», «пробы здоровья». Платформы и инструменты тоже проще унифицировать: меньше уникальных исключений, легче поддержка и обучение.
Kubernetes не просто «запускает контейнеры». Он закрепил набор идей: декларативное описание «что нужно», контроллеры и reconciliation, стандартные объекты для развертывания и доступа, встроенные механизмы масштабирования и обновлений.
Дальше по статье эти концепции разобраны простым языком — так, чтобы вы могли уверенно читать манифесты, понимать поведение кластера и делать практичные выводы для эксплуатации.
Brendan Burns — один из соавторов Kubernetes и заметный популяризатор подхода к эксплуатации контейнерных приложений. В период появления проекта он работал в Google, где вместе с коллегами (в том числе Joe Beda и Craig McLuckie) участвовал в создании Kubernetes как открытого проекта на основе накопленного опыта управления распределёнными системами.
Важно уточнить: вклад Burns обычно описывают не как «единоличное изобретение», а как участие в команде, которая оформила практики оркестрации в продукт и сообщество. Это проверяемый, общепринятый факт: Kubernetes с самого начала развивался публично (через репозитории, обсуждения и дизайн-документы), и роль ключевых участников видна по истории проекта.
Burns часто упоминают в контексте того, как Kubernetes «упаковал» сложные операции в понятные примитивы: декларативные описания, контроллеры, стандартные шаблоны развёртывания и обновлений. Его публичные выступления, статьи и книги помогли сделать эти идеи доступными не только инженерам платформ, но и командам разработки, которым нужно понимать, как запускать и сопровождать сервисы.
Отдельная заслуга — популяризация эксплуатационного мышления: не просто «запустить контейнер», а обеспечить повторяемое развёртывание, масштабирование, восстановление после сбоев и наблюдаемость как часть нормального процесса.
Если хотите углубиться, начните с источников, которые быстро дают опору на факты и термины:
Задолго до того, как слово «Kubernetes» стало нарицательным, крупные компании уже строили внутренние системы управления задачами и сервисами. Они решали практичную проблему: как запускать тысячи процессов на парке серверов, следить за их состоянием и обновлять без остановки бизнеса. Эти платформы редко становились публичными продуктами, но в них постепенно оформлялись общие идеи — расписание задач по ресурсам, контроль здоровья, автоматические перезапуски, раздельное управление «что запустить» и «где запустить».
Контейнеры упростили упаковку приложения и его зависимостей, но одновременно повысили динамичность среды. Стало проще запускать больше мелких сервисов, чаще выкатывать изменения и быстрее масштабироваться. Вручную поддерживать такую систему почти невозможно: если сервисов десятки или сотни, операции превращаются в поток повторяющихся действий и проверки «всё ли живо».
Из ранних систем в Kubernetes перекочевали базовые принципы: автоматизация «рутинных» операций, постоянная проверка состояния и стремление к предсказуемому шаблону развертывания. Разница в том, что Kubernetes упаковал эти идеи в открытый стандарт и дал общую модель для самых разных инфраструктур — от своих серверов до облака.
Декларативный подход в Kubernetes — это способ управлять системой через описание желаемого результата. Вместо того чтобы перечислять шаги («создай контейнер», «запусти процесс», «перезапусти при ошибке»), вы формулируете цель: каким должно быть состояние приложения прямо сейчас и постоянно.
Вы задаёте спецификацию (обычно в YAML): какие компоненты нужны, сколько их должно быть, какие ограничения и параметры считаются правильными. Это похоже на заказ в кафе: вы говорите «принесите капучино без сахара», а не инструктируете бариста, как молоть зёрна и греть молоко.
Важно, что декларация — не одноразовая команда, а «правило». Kubernetes воспринимает её как эталон.
У любой системы есть текущее состояние: что реально запущено на узлах, сколько процессов живы, какие поды упали, где не хватает ресурсов. Декларация описывает желаемое состояние: «всегда должно быть так».
Как только реальность расходится с желаемым (например, одна копия сервиса упала), Kubernetes стремится вернуть систему к описанному эталону. Для эксплуатационной команды это означает меньше ручного вмешательства: не нужно каждый раз «чинить руками», достаточно поддерживать корректное описание.
Вы пишете: «у сервиса должно быть 3 реплики». Дальше система сама следит, чтобы их действительно было три: запустит недостающую, пересоздаст удалённую, распределит по доступным ресурсам. Вам не нужно помнить порядок действий и проверок — вы задаёте норму.
Декларативные манифесты легко версионировать, пересоздавать окружения и одинаково выкатывать изменения. Один и тот же файл можно применить в тесте, стейджинге и проде, снижая риск «сделали в одном месте так, а в другом забыли». Это напрямую уменьшает количество ручных операций и делает развёртывания более предсказуемыми.
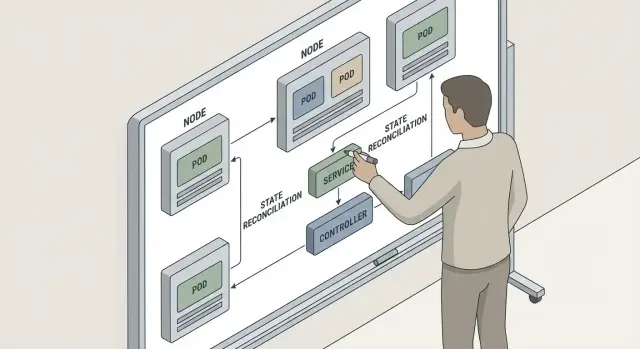
Одна из ключевых идей Kubernetes — контроллеры, которые не «выполняют разовую команду», а постоянно следят, чтобы реальность соответствовала заданному описанию. Это и есть согласование состояния (reconciliation): вы говорите системе, каким должно быть, а Kubernetes регулярно проверяет, как есть, и исправляет расхождения.
Логика контроллера устроена как непрерывная петля:
Важно, что reconciliation терпим к сбоям: если действие не удалось (узел недоступен, образ не скачался), контроллер попробует ещё раз, пока не достигнет нужного результата или пока входные условия не изменятся.
Отсюда естественно вытекает self-healing: Kubernetes не «лечит» приложение магически, но автоматически возвращает систему к заданной форме.
На практике это выражается в типовых сценариях:
Самые понятные примеры — ReplicaSet/Deployment. Deployment задаёт желаемое: «приложение версии X, 5 реплик». Контроллер Deployment следит за обновлениями и создаёт/управляет ReplicaSet’ами, а контроллер ReplicaSet доводит число Pod’ов до нужного.
Похожий принцип работает и на уровне инфраструктуры: контроллеры узлов отслеживают состояние Node и помогают «пересобрать» размещение рабочих нагрузок, если часть кластера стала недоступной. Именно эта непрерывная петля согласования и делает Kubernetes предсказуемым инструментом для эксплуатации.
В Kubernetes «идентичность» ресурсов устроена гибче, чем в системах, где всё держится на фиксированных именах. Имя Pod’а чаще всего случайно и недолговечно: под может пересоздаться, переехать на другой узел, получить новый IP — и это считается нормой. Поэтому для связи компонентов Kubernetes опирается не на «жесткие» имена, а на метки (labels) — пары ключ=значение, которые описывают, что это за объект.
Метка — это не просто подпись. Это договорённость о том, как вы группируете и находите объекты: «это веб‑часть», «это бэкенд», «это прод», «это версия v2». А селекторы (selectors) — правила отбора по этим меткам: «выбери всё, где app=web».
Практически любой «склеивающий» механизм в Kubernetes использует одну и ту же идею:
За счёт этого разные сущности остаются слабо связанными: вы меняете состав Pod’ов — а Service продолжает работать, потому что ищет не по именам, а по меткам.
app=web, tier=backendПредставим, что у вас есть Pod’ы с такими метками:
app=webtier=backendenv=prodТогда Service может выбирать только нужную группу:
selector:
app: web
tier: backend
Если вы добавите новые реплики бэкенда (или замените их при обновлении), достаточно, чтобы новые Pod’ы получили те же метки — и они автоматически попадут под обслуживание Service.
Метки и селекторы делают масштабирование и rolling update предсказуемыми:
app=web) и новую метку версии (version=v2). Это позволяет аккуратно переключать трафик (или разделять группы), не ломая адресацию и не привязываясь к конкретным именам Pod’ов.В итоге Kubernetes стандартизировал не только сущности вроде Pod и Service, но и сам подход: описывать связи между компонентами через простую, универсальную модель «описал метками → выбрал селектором».
Kubernetes сделал развертывание приложений повторяемым: вместо набора «уникальных» скриптов появился общий шаблон, понятный любой команде. Его ядро — связка Pod + Deployment.
Pod — это не «один контейнер», а минимальная единица, которая запускается и планируется на узел. Внутри Pod обычно один основной контейнер приложения, но могут быть и вспомогательные (например, для прокси, миграций, логирования). Важный момент: все контейнеры Pod разделяют сеть (один IP/портовое пространство) и могут разделять тома, поэтому взаимодействуют быстро и без лишней «склейки».
При этом Pod считается расходным: его можно пересоздать, переместить на другой узел, заменить при обновлении. Поэтому напрямую «держаться» за конкретный Pod — плохая идея; для этого есть Service.
Deployment описывает желаемое состояние: сколько реплик должно быть, какой образ и параметры запуска использовать. Он создает ReplicaSet, а тот уже следит, чтобы нужное число Pod реально работало. Так появляется стандартная модель: вы меняете декларацию — контроллеры приводят систему к нужному виду.
Deployment делает безопасное обновление типовым сценарием: rolling update постепенно поднимает новые Pod и убирает старые, сохраняя доступность. Если новая версия ведет себя плохо, rollback возвращает предыдущую ревизию без ручной «перекатки».
Чтобы это работало предсказуемо, почти всегда нужны:
Эти настройки превращают развертывание из героизма в рутину — именно поэтому Pod + Deployment стали стандартом де-факто.
Одна из главных «бытовых» проблем распределённых систем — сетевая адресация. Pod — сущность недолговечная: он пересоздаётся при обновлениях, переездах на другой узел, сбоях. Вместе с этим меняется IP, а иногда и сам набор подов, которые должны принимать трафик. Если другие компоненты будут ходить напрямую по IP подов, система быстро превратится в набор хрупких исключений и ручных правок.
Kubernetes решает это через Service — абстракцию, которая даёт приложению стабильное имя и «виртуальный адрес», за которым стоит динамический набор подов.
Service делает две вещи одновременно:
Важно: Service выбирает поды не «по списку», а по label selector. То есть привязка к бэкендам описывается декларативно: «все поды с такими метками».
На концептуальном уровне Service — это фронт, а реальный список адресов бэкендов хранится отдельно.
Контроллеры Kubernetes автоматически поддерживают эти списки в актуальном состоянии: под исчез — адрес исчез, новый под появился — адрес добавился.
Благодаря встроенному DNS, сервисы обычно находят друг друга по имени вида payments или payments.namespace. Это формирует базовый паттерн взаимодействия микросервисов: клиент зависит от имени сервиса, а не от конкретных инстансов. В результате rolling update, self-healing и горизонтальное масштабирование становятся «встроенными» возможностями, не требующими сложной сетевой логики в самом приложении.
Масштабирование в Kubernetes — это не «прикрутить побольше серверов», а стандартизированный набор механизмов, который делает рост нагрузки предсказуемым и управляемым. Идея проста: сначала вы задаёте базовую форму приложения, затем увеличиваете её «в ширину», а когда ручного управления становится мало — подключаете автоскейлинг.
Самый понятный сценарий — увеличить количество реплик (несколько одинаковых экземпляров). В Kubernetes это обычно означает: «держи N одинаковых Pod’ов» и обеспечь их замену при сбое. Такой подход хорошо работает для веб‑сервисов, воркеров очередей, API — всего, что можно размножать без сложной координации.
Важно помнить: реплики дают эффект только если входящий трафик распределяется, а состояние вынесено наружу (база данных, объектное хранилище, очередь). Иначе вы масштабируете не производительность, а хаос.
Когда нагрузка меняется волнами, включают автоскейлинг.
HPA (Horizontal Pod Autoscaler) добавляет/убавляет реплики по метрикам: чаще всего CPU, память, RPS, длина очереди или пользовательские метрики. VPA (Vertical Pod Autoscaler) подходит к проблеме иначе: предлагает/меняет ресурсы Pod’а (CPU/память), если приложение стабильно работает «в одном экземпляре», но требует больше мощности.
Скейлинг невозможен без планирования (scheduling). Kubernetes размещает Pod’ы на нодах, опираясь на запросы ресурсов (requests) и ограничения (limits). Requests — это «минимум, который мне нужен», по ним планировщик понимает, куда Pod поместится. Limits защищают ноду от прожорливых процессов. Без корректных requests/limits автоскейлинг часто начинает «стрелять в темноту».
Частая ошибка — «масштабирование без наблюдаемости»: вы увеличиваете реплики, но не видите, где узкое место (БД, сеть, внешнее API). Вторая — масштабирование без нагрузочных тестов: HPA настроен, но реальные пики приводят к лавинообразным таймаутам, потому что прогрев, кэш и лимиты не проверялись заранее.
Когда сервис уже запущен, основная работа часто начинается не с «развернуть», а с «поддерживать»: менять настройки без пересборки, безопасно хранить секреты, обновляться без простоев и быстро понимать, что пошло не так. Kubernetes превратил многие такие задачи в повторяемые практики и стандартные примитивы.
Для настроек есть ConfigMap, а для чувствительных данных — Secret. Важно, что это не «магия», а договорённость о форме: конфигурация хранится отдельно от образа и может подключаться как переменные окружения или как файлы, что упрощает переносимость между средами.
Обновления обычно идут через контролируемые механизмы развертывания (например, rolling update в Deployment): новая версия вводится постепенно, а откат становится процедурой, а не аварийной импровизацией.
Отдельный пласт — доступы. Kubernetes задаёт понятные границы: кто может читать Secret, кто — изменять Deployment, кто — смотреть события. Это снижает риск «случайных» прав и помогает разделять ответственность между командами.
Проверки readiness и liveness переводят часть рутинной диагностики в автоматический режим. Readiness отвечает на вопрос «можно ли уже направлять трафик», а liveness — «процесс не завис ли». В результате трафик не отправляется на неподготовленные экземпляры, а зависшие контейнеры перезапускаются без ручного вмешательства.
Наблюдаемость в Kubernetes складывается из повседневных действий: смотреть логи контейнера, метрики (нагрузка, ошибки, задержки) и события кластера. Часто именно события (например, проблемы с образами, лимитами ресурсов или сетевым доступом) дают самую быструю подсказку «почему сервис не поднялся», ещё до глубокого анализа метрик.
Одна из сильных идей Kubernetes — не пытаться «встроить всё на свете» в ядро, а дать понятный способ расширять платформу под свою предметную область. Именно здесь появляются CRD и Operators: вы превращаете знания эксплуатации в повторяемую механику, которую кластер выполняет сам.
CRD (CustomResourceDefinition) позволяет добавить в Kubernetes новый тип ресурса — такой же «родной», как Pod или Service. Например, можно описать ресурс PostgresCluster или KafkaTopic и управлять им через привычные инструменты: манифесты YAML, kubectl, RBAC, аудит, GitOps.
Ключевой эффект: команда перестаёт обсуждать десятки низкоуровневых объектов (StatefulSet, PVC, ConfigMap, политики бэкапа) и фиксирует намерение на уровне продукта: «нужен кластер базы на 3 узла, с бэкапом раз в сутки и шифрованием».
Operator — это контроллер, который наблюдает за вашими CRD и выполняет цикл согласования состояния (reconciliation). Он умеет не только создать ресурсы, но и поддерживать их жизнь: обновления, восстановление после сбоев, перевыбор лидера, миграции схемы, ротацию сертификатов.
Типовые кейсы, где Operators действительно полезны:
Operator имеет смысл, если жизненный цикл сервиса сложный и «ручные инструкции» постоянно приводят к ошибкам: много шагов, проверки здоровья, сценарии аварийного восстановления, тонкие зависимости.
Если же вам нужно лишь стандартно развернуть приложение, прокинуть конфигурацию и сделать rolling update, чаще достаточно Helm или набора манифестов: проще сопровождение, меньше кода, ниже риск скрытой логики в контроллере.
Kubernetes стал стандартом не потому, что «лучше всех запускает контейнеры», а потому что зафиксировал общий язык для инфраструктуры: единый API и набор типовых объектов, через которые команды описывают деплой, доступ к сервисам и повседневные операции. Когда этот язык одинаков в разных облаках и дата-центрах, практики становятся переносимыми, а знания — конвертируемыми между проектами.
Раньше многое зависело от конкретного провайдера или самописных скриптов. Kubernetes стандартизировал «контракт»: как описывать желаемое состояние (манифесты), как обновляться (rolling update), как обеспечивать самовосстановление (self-healing) и как подключать сервисы друг к другу. Это резко снижает стоимость смены инфраструктуры и упрощает найм: меньше «магии», больше общего инструментария.
На практике Kubernetes унифицировал ключевые операционные сценарии:
Важно, что это стандартизация не «железа», а процесса: как команда публикует изменения и поддерживает сервис в рабочем состоянии.
Kubernetes не решает всё «из коробки». Он не заменяет архитектурные решения, SRE-практики, наблюдаемость, управление стоимостью или безопасность целиком. Часто понадобятся дополнительные компоненты и правила: политики, шаблоны манифестов, CI/CD, логирование и трассировка.
Начните с пилота на одном-двух сервисах, зафиксируйте шаблоны (Deployment/Service/Ingress), сделайте гайдлайны по неймингу, меткам и ресурсам. Затем масштабируйте подход, добавляя автоматизацию и проверки. Если на вашем сайте есть материалы, полезно связать внедрение с внутренней документацией (/docs) или оценкой планов и поддержки (/pricing).
Отдельно стоит подумать о скорости вывода сервисов в эксплуатацию. Например, TakProsto.AI как vibe-coding платформа помогает быстрее собирать веб-, серверные и мобильные приложения через чат, а затем организовать повторяемые окружения: фиксировать конфигурацию, готовить артефакты и, при необходимости, экспортировать исходники для дальнейшего сопровождения командой. Для российских команд критично и то, что TakProsto.AI работает на серверах в России и использует локализованные и open-source LLM-модели, не отправляя данные за рубеж — это хорошо сочетается с идеей «стандартизации процессов» вокруг Kubernetes.
Если вы делаете внутренние гайды или делитесь опытом внедрения платформенных практик, у TakProsto.AI есть программы начисления кредитов за контент и рефералов — это может помочь компенсировать часть экспериментов и пилотов, пока команда выстраивает свой «золотой путь» деплоя и эксплуатации.
Оркестрация нужна, когда сервисов становится много и ручной запуск перестаёт масштабироваться. Она берёт на себя повторяющиеся операции:
Декларативно — значит описывать желаемое состояние (сколько реплик, какой образ, ресурсы, параметры), а не последовательность шагов. Дальше Kubernetes сам стремится привести текущее состояние к желаемому.
Практика: вы меняете YAML-манифест (например, реплики с 3 до 5), применяете его, и система сама создаёт недостающие Pod’ы и поддерживает их число.
Reconciliation — это непрерывный цикл «наблюдать → сравнить → исправить → повторить». Контроллеры постоянно проверяют, совпадает ли реальность с описанием в API, и устраняют расхождения.
Отсюда и self-healing: если Pod упал или узел стал недоступен, контроллеры попытаются восстановить нужное состояние (перезапуск, пересоздание, перенос).
Pod — минимальная единица запуска: один или несколько контейнеров с общими сетью и томами. Pod считается расходным: его можно пересоздать, и это нормально.
Deployment — надстройка для управления версией и количеством Pod’ов:
Service даёт стабильное имя и виртуальный IP для доступа к приложению, даже если Pod’ы пересоздаются и их IP меняются.
Service выбирает бэкенды по label selector, а актуальные адреса поддерживаются через Endpoints/EndpointSlice. В итоге клиенты зависят от имени сервиса, а не от конкретных инстансов.
Labels — это пары ключ=значение, которыми вы описываете объекты (например, app=web, env=prod). Selectors — правила отбора по этим меткам.
Это важно, потому что:
Главное правило: договоритесь о стандарте меток и придерживайтесь его во всех манифестах.
Rolling update постепенно вводит новую версию и убирает старую, сохраняя доступность. Rollback возвращает предыдущую ревизию, если новая ведёт себя плохо.
Чтобы обновления были предсказуемыми:
База — ручное масштабирование реплик (например, в Deployment). Автоскейлинг добавляет автоматику:
Без корректных requests/limits автоскейлинг часто работает хуже: планировщику и алгоритмам не на что опираться.
ConfigMap — для конфигурации, Secret — для чувствительных данных (токены, пароли, ключи). Их обычно подключают как переменные окружения или файлы.
Практичные советы:
CRD добавляет новый тип ресурса в API Kubernetes (например, условный PostgresCluster). Operator — контроллер, который поддерживает жизненный цикл такого ресурса через reconciliation.
Operator оправдан, когда у сервиса сложная эксплуатация: бэкапы, восстановление, переключение ролей, обновления по особой процедуре.
Если задача типовая (просто развернуть приложение, обновлять и масштабировать), чаще достаточно Helm или набора манифестов — проще сопровождать и меньше скрытой логики.