Бюджет производительности помогает держать скорость как ограничение продукта: метрики, быстрый аудит, правила приоритетов и короткий чек-лист перед релизом.
Обычно фразу «приложение стало медленным» слышат слишком поздно. На демо и на ноутбуке разработчика все летает, потом добавляются графики, виджеты, аналитика, новые экраны - и первая загрузка превращается в ожидание. У команды уже есть пользователи, сроки и привычка «потом оптимизируем», поэтому любое ускорение становится дорогим.
Если относиться к скорости как к ограничению продукта, она перестает быть разовой задачей «перед релизом». Это такое же условие, как безопасность, цена или поддержка мобильных устройств: новые фичи можно делать, но только если они помещаются в заранее заданные рамки.
Эти рамки и задает бюджет производительности. Он говорит не «надо быстрее», а «быстрее вот настолько, иначе фича не проходит».
Бюджет снимает бесконечные споры «у меня нормально». У всех разные устройства, сеть и привычки. Вместо ощущений появляется простое правило: если метрики вышли за пределы, значит есть проблема. Она одинаково видна продукту, разработке и дизайну.
Скорость реально влияет на продуктовые решения. В быстро собранном веб-прототипе легко подключить тяжелую библиотеку ради одного эффекта. Если это ухудшает первый экран и увеличивает отказы, решение меняется: эффект упрощают, переносят на вторичный экран или включают только по запросу.
Чаще всего ограничения по скорости влияют на выбор библиотек и UI-компонентов, объем данных на первом экране, использование анимаций и больших изображений, порядок подключения интеграций (чаты, аналитика), и то, как выглядит «минимально полезная» версия экрана.
Когда скорость задана как правило, команда быстрее выбирает компромиссы и реже переписывает все в последний момент.
Addy Osmani переводит разговор о скорости из разряда «хорошо бы ускорить» в разряд понятных правил. Его тезис простой: производительность должна быть ограничением продукта, как цена, сроки или требования к безопасности. Если это не ограничение, то в реальной работе скорость почти всегда проигрывает новым фичам.
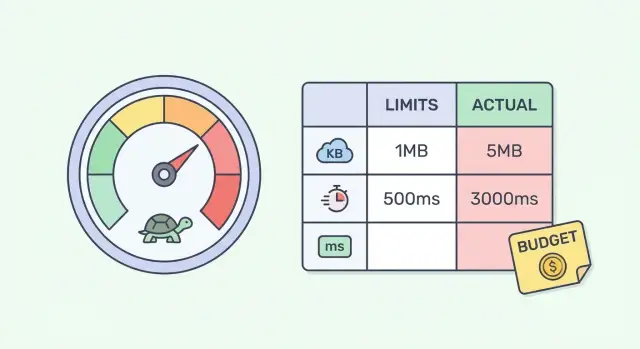
Бюджет производительности означает, что вы заранее решаете, что для приложения считается «достаточно быстро». Не в общих словах, а в числах и порогах. Тогда любой новый экран, библиотека или виджет оценивается не по вкусу, а по тому, укладывается ли он в лимиты.
Это сильно отличается от целей вроде «ускорить загрузку» или «сделать быстрее на 20%». Такие формулировки не отвечают на три вопроса: что именно измерять, где граница, и кто принимает решение, когда компромисс неизбежен. Бюджет дает правило: если вышли за порог, значит либо чиним, либо осознанно отказываемся от части задумки.
Практический смысл особенно заметен в проектах, которые растут в темпе: функциональность появляется за часы, а вес и сложность прибавляются незаметно. Это типичная ситуация для приложений, которые собирают через vibe-coding платформы вроде TakProsto.
Бюджеты помогают всем:
По сути, бюджет - это договор команды с пользователем: скорость важна не на словах, а по правилам, которые выполняются каждый раз.
Хороший бюджет отвечает на вопрос: что важнее для пользователя в вашем приложении - быстро увидеть полезный экран, быстро начать взаимодействовать, или не раздражаться от «прыгающей» верстки. Не пытайтесь измерять все сразу. Выберите минимум, который вы реально будете проверять перед каждым релизом.
Базовый набор метрик, понятный и продукту, и разработке:
Отдельно стоит договориться о бюджете на JavaScript: именно он часто превращает быстрый прототип в тяжелое приложение. Зафиксируйте два ограничения: общий объем JS для первого экрана и «сколько кусков» нужно скачать, чтобы экран стал интерактивным. Чем больше чанков и зависимостей, тем выше задержки и риск долгой обработки на слабых устройствах.
Чтобы не утонуть в страницах, выберите 1-2 пользовательских сценария и делайте бюджеты вокруг них. Для быстро собранных приложений это обычно вход и открытие главного рабочего экрана, плюс самый частый поток (создать запись, оформить заявку, найти товар).
Сценарии выбирают по простым критериям: самый частый путь, самый «денежный» путь (где конверсия), и самый тяжелый экран (где больше всего данных и логики). Если эти сценарии укладываются в бюджеты, остальные страницы чаще всего подтягиваются автоматически или требуют меньше усилий.
Лабораторные замеры - тесты в одинаковых условиях. Они полезны, когда вы часто меняете приложение и хотите сразу увидеть: стало быстрее или медленнее по сравнению с прошлой сборкой. Лаборатория хорошо ловит регрессы: один лишний пакет, тяжелый шрифт или новый виджет - и цифры поползли.
Полевые данные - то, что происходит у реальных людей: разные телефоны, сети, вкладки в фоне. Они отвечают на вопрос «пользователям правда стало лучше?» и защищают от самообмана красивыми результатами на идеальном ноутбуке.
Обычно хватает Lighthouse и замеров в DevTools с имитацией медленной сети и среднего устройства. Важно сохранять один и тот же профиль теста и прогонять его регулярно, иначе сравнение теряет смысл.
Полевые метрики дают системы RUM (сбор показателей в браузере пользователя) или отчеты по реальному трафику. Смотрите прежде всего на Core Web Vitals и распределения (например, 75-й перцентиль), а не на «среднее».
Если полевых данных пока нет, начните с лаборатории и прокси-метрик: вес начальной загрузки, количество запросов, размер основного JS, время до первого полезного экрана. Параллельно заложите простой сбор CWV, чтобы через 1-2 недели видеть реальность.
Чтобы не попасть в ловушку «меряем на топовом устройстве и радуемся», держите короткие правила: тестируйте на ограниченном профиле CPU и сети, проверяйте хотя бы один средний Android и слабую сеть, сравнивайте перцентили и худшие сценарии (холодный старт, пустой кеш), фиксируйте условия замеров в документе команды.
Цель такого аудита - не «сделать идеально», а быстро понять, где вы теряете время загрузки и какой пункт бюджета превышен. Делайте замеры на одной и той же странице и в одинаковых условиях, иначе сравнивать будет нечего.
Выберите один главный сценарий: первый вход, открытие каталога, создание сущности. Зафиксируйте «эталон»: устройство, сеть и точку старта (чистый кеш или прогретый).
Прогоните Lighthouse в режиме инкогнито, сохраните цифры и проблемные места. Смотрите не на «баллы», а на LCP, INP, CLS и список рекомендаций.
Выпишите 5-10 находок и отметьте тип влияния: тяжелые файлы, блокирующие ресурсы, лишний JavaScript, медленные запросы, сдвиги верстки. Рядом добавьте короткую причину, например «баннер грузится как PNG 2.5 МБ».
Привяжите находки к бюджету: превышен вес стартового JS, слишком много запросов до первого экрана, LCP выше цели, CLS скачет из-за поздней подгрузки шрифтов.
Выберите 1-2 правки с самым большим эффектом, внесите их и повторите замер. Сравнивайте «до/после» по тем же условиям.
Чтобы не утонуть, помечайте находки простыми ярлыками: «большой выигрыш, низкий риск», «большой выигрыш, высокий риск», «мелочь». Например, если Lighthouse показывает, что LCP упирается в hero-изображение, чаще всего быстрее всего помогает замена формата и размеров, плюс отложенная загрузка всего, что ниже первого экрана.
Когда времени мало, важнее не «оптимизировать все», а выбрать 1-2 изменения, которые реально почувствует человек. Бюджет задает границу, а приоритизация помогает быстрее вернуться в нее.
Сначала смотрите на то, что формирует ощущение скорости: главный элемент должен появляться быстро (LCP), а интерфейс должен отзываться без задержек (INP). Если эти метрики плохие, «косметика» вроде мелких правок во второстепенных скриптах обычно не дает видимого эффекта.
Если бюджет по JavaScript превышен, не начинайте с микро-оптимизаций. Почти всегда выигрывают простые вещи: удалить лишнее, отложить загрузку, разделить код, не грузить библиотеки на страницах, где они не нужны.
Если пользователь жалуется, что «все прыгает», это почти всегда про верстку. В приоритете - фиксировать размеры картинок, видео, рекламных блоков и карточек, которые появляются позже. Один правильно заданный размер (или контейнер с зарезервированным местом) часто дает больше, чем час «подкручивания» стилей.
Если проблема в медленной сети, первым делом сокращайте вес и количество запросов. Это обычно надежнее, чем пытаться «умнее кэшировать» то, что и так слишком тяжелое.
Практичный порядок, который помогает не распыляться:
Когда есть бюджет производительности, спорят не про вкусы, а про факты: что быстрее даст заметный эффект на Core Web Vitals и что можно исправить за день.
Самый частый источник проблем - лишний JavaScript. Приложение не обязано грузить все сразу.
Уберите тяжелые библиотеки, которые используются в одном месте (часто это дата-пикеры, графики, редакторы текста). Делите код по маршрутам: главная страница не должна тащить код админки и настроек. Отложите неважное: чаты поддержки, виджеты аналитики и A/B тесты подключайте после первого экрана. И внимательно относитесь к сторонним скриптам: каждый из них способен добавить задержки и блокировать поток.
Изображения и шрифты часто ухудшают LCP, потому что становятся самым большим элементом на первом экране.
Картинки: отдавайте правильный размер (не 3000 px в блок 400 px), используйте современные форматы, а ленивую загрузку включайте только для того, что ниже первого экрана. Частая ошибка - делать lazy для главного баннера, и LCP сразу ухудшается.
Шрифты: сократите начертания до 1-2, не тяните большие наборы символов, настройте загрузку так, чтобы текст появлялся сразу. Если шрифт не успел, пусть временно будет системный.
С CSS проблема обычно в «на всякий случай»: тяжелые глобальные стили и неиспользуемые правила. Уберите лишнее и избегайте дорогих эффектов на больших блоках.
Серверная часть тоже влияет: медленный ответ API или HTML портит LCP даже при хорошем фронтенде. Проверьте кэш, сжатие, время ответа и скорость базы. Если главная страница ждет длинный запрос за списком данных, часто помогает отдать скелет экрана сразу, а данные догрузить отдельно и добавить кэш на популярный запрос.
Чтобы бюджет работал, он должен стать частью правил выпуска, а не красивым слайдом. Самый простой шаг - добавить его в Definition of Done для фич, которые влияют на клиент: новые экраны, виджеты, аналитика, шрифты, медиа. Если фича не проходит проверку, она не считается готовой.
Дальше решите, что делает CI. Полезно разделить проверки на «ломает сборку» и «дает сигнал». Например: ломаем сборку, если вырос LCP или общий вес JS выше лимита для ключевой страницы; даем предупреждение, если слегка ухудшился INP или вырос размер изображений, но есть план фикса; отдельно задаем лимиты для новых страниц, чтобы не сравнивать их с уже оптимизированными.
Важно заранее договориться с дизайном и контентом о лимитах, иначе бюджет будут нарушать «по уважительной причине». Обычно это про медиа и визуал: максимальный вес изображений на экране, запрет на автоплей видео, ограничение числа шрифтов и начертаний, осторожность с тяжелыми анимациями.
Чтобы видеть регресс, храните историю замеров. Достаточно таблицы или артефактов сборки по ключевым страницам: дата, метрики, вес ресурсов, версия. Если вы собираете приложение в TakProsto, удобно сочетать это со снапшотами и откатом: после быстрых изменений можно быстро вернуться к стабильной версии и исправить причину точечно.
Самая частая причина провала простая: бюджет сделали, но им не пользуются. Команда ставит десяток метрик, потом не понимает, какая важнее и что делать при провале. В итоге бюджет превращается в таблицу для галочки.
Еще одна ловушка - копировать чужие пороги. Цифры из другого проекта часто не подходят вашей аудитории. Если часть пользователей сидит на старых Android и слабом 4G, цели «как на топовом ноутбуке» дадут ложное чувство успеха. А слишком жесткие цели демотивируют и начинают игнорироваться.
Обычно все упирается в одни и те же ошибки: ставят слишком много метрик, оптимизируют только главную страницу, гонятся за идеальными баллами Lighthouse вместо понятных улучшений первого экрана, проверяют на одном устройстве и в идеальной сети, не пересматривают цели по мере роста продукта.
Чтобы не застрять, заранее выберите 2-3 ключевых сценария и измеряйте их, а не один «красивый» экран. И сделайте бюджет решающим: если метрика просела, должно быть понятно, что чинить первым (например, тяжелые изображения, лишние скрипты, длинные запросы к API). Пороги можно и нужно пересматривать после крупных релизов и заметного роста функциональности.
Перед релизом важно проверить не только «все работает», но и «все быстро». Бюджет производительности должен работать как стоп-кран: если лимиты нарушены, релиз откладывается или идет с понятным риском и планом отката.
Сделайте один эталон для сравнения: сохраните свежие результаты замеров для 1-3 ключевых страниц (например, главный экран, каталог/лендинг, экран с самой тяжелой логикой). Эталон нужен, чтобы через неделю не спорить, стало ли хуже.
Пробегитесь по короткому списку и отмечайте только «да/нет». Если «нет», фиксируйте задачу и владельца:
Если LCP ухудшился, первым делом ищите, что задерживает главный контент: тяжелый шрифт, большой баннер, блокирующие скрипты.
Ситуация: за 7 дней вы собрали MVP личного кабинета (логин, список заказов, чат поддержки) и сразу начали наращивать функции. Делали быстро: React, готовые компоненты, несколько виджетов аналитики. Через две недели пользователи пишут: на мобильном интернете приложение открывается «тяжело», первые клики не срабатывают, при загрузке все прыгает.
Чтобы скорость не превратилась в вечный долг, введите простой бюджет из 4 пунктов и повесьте его рядом с требованиями к фичам:
Дальше нужен быстрый аудит: Lighthouse в мобильном профиле, список самых тяжелых скриптов, проверка экрана с худшим LCP. Важно не спорить о нюансах, а найти 1-2 причины, которые дают основной вклад.
Чаще всего всплывают две правки с максимальным эффектом. Первая - разделить код по маршрутам, чтобы первая загрузка не тащила весь интерфейс одним бандлом. Вторая - убрать «дорогие» блоки из первого экрана: переносить чат и графики ниже, грузить их по запросу, показывать простой скелет, пока тяжелые компоненты и данные не готовы.
Скорость легко потерять снова, если новые фичи проходят без проверки. Поэтому правило простое: каждая задача, которая добавляет библиотеку, виджет или новый экран, должна пройти контроль 4 бюджетов.
Если вы собираете приложение в TakProsto, эти бюджеты удобно фиксировать как продуктовые ограничения и проверять после каждого заметного изменения. А на этапе выкладки помогает то, что платформа поддерживает снапшоты и откат: если метрики просели, можно быстро вернуться к стабильной версии и спокойно разобрать причину.
Возьмите один сценарий, который приносит ценность прямо сейчас: вход в аккаунт и первый экран после него. На этом участке проще договориться о правилах и быстрее увидеть эффект.
Сделайте простую таблицу из четырех колонок: «бюджет», «текущее значение», «владелец», «дата замера». Владелец нужен не для контроля, а чтобы у метрики был человек, который скажет: «это сломалось, давайте чиним». Замеры фиксируйте одной и той же методикой, иначе цифры начнут спорить друг с другом.
Оптимизации планируйте как обычные задачи: что меняем, какой показатель должен улучшиться, как проверим. На спринт обычно хватает 1-2 задач на скорость, но доведенных до измеримого результата.
Если вы делаете проект через TakProsto (takprosto.ai), удобно записать бюджеты заранее в planning mode, чтобы «сделать фичу» автоматически означало «сделать и уложиться в пределы».
План на ближайший спринт:
Через спринт расширьте подход на второй сценарий. Так бюджеты становятся привычкой, а не разовой акцией перед релизом.
Лучший способ понять возможности ТакПросто — попробовать самому.