Разбираем Amazon DynamoDB: устройство, модель данных, ключи и индексы, режимы ёмкости, транзакции и практики проектирования для масштабируемых систем.
DynamoDB решает практическую задачу: хранить и быстро отдавать данные с предсказуемой задержкой при росте нагрузки и объёма. Это управляемая NoSQL‑база, где вы платите за пропускную способность и хранение, а масштабирование и отказоустойчивость во многом берёт на себя AWS. Особенно хорошо она показывает себя там, где важны скорость, простая модель запросов и высокая параллельность.
Каталоги и справочники. Быстрый поиск по ключам и выборки по предсказуемым атрибутам (например, товары по категории с сортировкой по цене) — при условии правильного проектирования ключей.
Сессии, токены, профили. Данные в стиле «ключ → значение», быстрые чтения/записи, TTL для автоматической очистки.
События и активность. Ленты событий, истории действий, аудит — когда запись идёт постоянно, а чтение обычно по конкретному пользователю/объекту и диапазону времени.
IoT и телеметрия. Поток измерений, высокая частота записи, хранение по устройству и времени.
Если вам нужны сложные SQL‑запросы, множественные JOIN, агрегаты «на лету», произвольная аналитика ad‑hoc и отчётность по большому числу измерений — реляционная БД или отдельное аналитическое хранилище обычно подойдут лучше. DynamoDB эффективна, когда запросы заранее известны и укладываются в модель «получить данные по ключу/диапазону».
Главный навык — проектирование под паттерны доступа: сначала описывают, как приложение будет читать и писать данные, а затем под это подбирают partition key/sort key и, при необходимости, вторичные индексы. Важно также понимать ограничения запросов и заранее решать, какие операции должны быть быстрыми и дешёвыми.
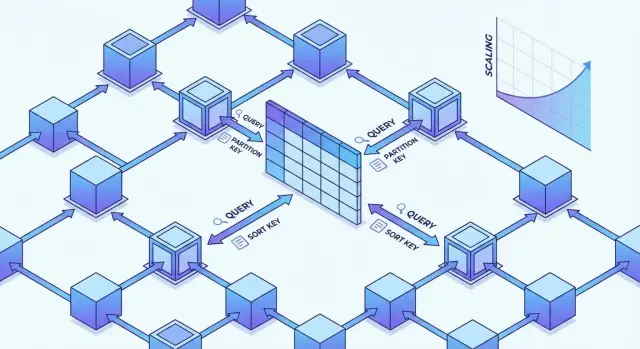
DynamoDB — распределённая key-value/документная база, где данные физически раскладываются по множеству узлов. Для разработчика это выглядит как одна таблица, но «внутри» всё держится на партициях (разделах) и детерминированной маршрутизации запросов по ключам.
Каждый элемент попадает в партицию на основе partition key: значение ключа хэшируется, и по результату выбирается конкретный набор физических разделов. Если у вас много запросов и/или записей с одним и тем же partition key, нагрузка концентрируется на небольшом числе партиций — появляются «горячие» ключи, растут задержки и вероятность throttling.
Sort key не определяет, в какую партицию попадёт элемент, но задаёт упорядочивание внутри партиции и делает возможными диапазонные выборки (например, события по времени).
Платформа берёт на себя:
От вас требуется другое: выбрать ключи и паттерны доступа так, чтобы распределение нагрузки было равномерным и операции попадали в «правильные» партиции.
Базовые операции GetItem/PutItem/UpdateItem/DeleteItem работают по первичному ключу и обычно самые предсказуемые по latency.
Query читает элементы в пределах одного partition key (с опциональными условиями по sort key) — это основной «правильный» способ выборок.
Scan проходит таблицу или индекс целиком, поэтому дорог по времени и по потреблению RCU; его обычно оставляют для админских задач, миграций и редких отчётов.
На дизайн напрямую влияют практические лимиты: размер элемента (до 400 КБ), постраничная выдача результатов, а также то, что запросы без точного partition key почти всегда ведут к Scan или индексу.
Ещё одна важная группа ограничений — пропускная способность и throttling: при «горячих» ключах или резких всплесках нагрузка может упираться в лимиты таблицы/индексов, поэтому ключи и индексы планируют под реальные паттерны чтения и записи.
DynamoDB хранит данные в таблицах (tables). Внутри таблицы лежат элементы (items) — по сути, записи. Каждый item — это набор атрибутов (attributes) с типами. При этом «схема» в классическом смысле минимальна: DynamoDB требует описать только ключевые атрибуты, а остальные поля могут отличаться от item к item.
Главный ориентир для понимания структуры таблицы — это то, какие ключи объявлены и какие атрибуты участвуют в индексах. Остальное — гибкое: можно хранить разные наборы полей для разных сущностей, если это соответствует вашим паттернам доступа.
Первичный ключ бывает двух видов:
Пример: таблица Orders.
PK = CUSTOMER#123 (partition key)SK = ORDER#2025-12-01T10:15:00Z (sort key)Так вы быстро получаете все заказы клиента запросом Query по PK, а сортировка по времени достигается естественно через SK.
DynamoDB поддерживает скаляры (String, Number, Binary, Boolean), а также Map и List, что удобно для JSON‑подобных документов. Есть и типы множеств: String Set / Number Set / Binary Set (полезны, когда важна уникальность значений в поле).
Размер одного item ограничен 400 KB. Если запись может вырасти больше (например, длинная история событий или большие вложения), обычно делают так:
Query.В DynamoDB схема «вырезается» не из нормализации, а из запросов. Практичный порядок такой: сначала фиксируете список операций (get по id, выборка последних событий, поиск по статусу), их частоту и SLA по задержке/стоимости, и только потом под это выбираете partition key и sort key. Если запрос не выражается ключами или индексом — он либо станет дорогим сканированием, либо потребует переработки модели.
Partition key отвечает за распределение данных и нагрузки по партициям. Хороший ключ:
Классический пример: USER#<id> для всех данных пользователя. Плохой пример: STATUS#active, если 80% запросов идут в один статус — получится «горячая» партиция.
Sort key помогает делать диапазонные запросы и сортировку внутри одного partition key: «последние N заказов», «события за период», «элементы по префиксу». Частая техника — композитные значения, например TS#2025-12-22T10:15:00Z или ORDER#<createdAt>#<orderId>, чтобы обеспечить и упорядочивание, и уникальность.
Если нагрузка неизбежно концентрируется (например, популярный товар или общий поток событий), добавляют шардирование ключа: PRODUCT#<id>#<shard>, где shard = hash(id) % N или случайное число. Записи распределяются равномернее, а чтение агрегируется запросами по всем шардам (обычно параллельно).
В single-table design разные сущности кладут в одну таблицу, различая их префиксами и «типами»:
Так вы строите ключи под конкретные паттерны доступа и избегаете лишних запросов и джоинов.
В DynamoDB вторичные индексы нужны не «для ускорения», а чтобы поддержать дополнительные паттерны доступа, которые невозможно выразить через primary key таблицы. Важно помнить: индекс — это отдельная структура хранения, а значит дополнительные записи, стоимость и иногда — задержки.
Если все ваши запросы укладываются в схему «знаю partition key — читаю один item или диапазон по sort key», базовой таблицы достаточно. Индекс имеет смысл, когда нужно искать по альтернативному ключу: например, находить заказы по customerId, а не по orderId, или выбирать сущности по статусу и времени.
Хорошее правило: сначала зафиксируйте список запросов (access patterns), а индекс добавляйте только под те, которые реально будут выполняться часто и должны быть быстрыми.
GSI (Global Secondary Index) позволяет задать альтернативные partition key и sort key, полностью независимые от ключей таблицы. Это самый гибкий инструмент, но он же чаще всего влияет на бюджет:
LSI (Local Secondary Index) «привязан» к partition key таблицы: partition key тот же, меняется только sort key. LSI полезен, когда вы хотите по тем же группам данных (одному partition) сортировать/фильтровать по другому критерию: например, сообщения чата по времени и по приоритету.
Ограничения: LSI нужно создавать при создании таблицы (позже не добавить), а размер данных в одном partition ограничен (практически это означает, что нельзя бесконечно накапливать данные под одним ключом).
Проекция определяет, какие атрибуты копируются в индекс:
KEYS_ONLY — минимальный объём, но чаще придётся делать дополнительный GetItem по таблице;INCLUDE — компромисс: держите в индексе только нужные поля для ответа;ALL — удобно, но дороже по хранению и записи.Частая практика: начинать с INCLUDE под конкретный ответ API и пересматривать проекцию при изменении требований.
Индексы стоит именовать так, чтобы было понятно, под какой запрос они сделаны: например, gsi_customerId_createdAt_v1. Суффикс версии помогает безопасно эволюционировать схему: создаёте новый индекс v2, переводите чтения на него, затем удаляете v1 — без остановки сервиса и с контролируемыми расходами.
DynamoDB ограничивает нагрузку через ёмкость чтения и записи. Это не «абстрактные лимиты», а понятная валюта, от которой зависят задержки, троттлинг и стоимость.
On-Demand подходит, когда трафик непредсказуемый (пики, редкие батчи, новая функция без исторических метрик). Платите за фактические запросы, зато меньше контроля.
Provisioned выгоднее при стабильной или прогнозируемой нагрузке: вы задаёте RCU/WCU и можете включить Auto Scaling. Это обычно лучший режим для «зрелых» сервисов с понятными SLO.
Пример: если вы пишете 200 записей/с по 2 КБ, потребуется ~400 WCU (округление вверх по размеру). Для чтений 500 запросов/с по 8 КБ со строгой консистентностью: 8 КБ = 2 блока по 4 КБ, значит ~1000 RCU.
В Provisioned включайте Auto Scaling с целевым потреблением (например, 70%). Для наблюдаемости заведите алерты на ConsumedRead/WriteCapacityUnits, ThrottledRequests и рост Latency — троттлинг часто означает неверную оценку ёмкости или «горячие» ключи.
BatchGet/BatchWrite уменьшают сетевые накладные расходы, но ёмкость списывается так же, как за эквивалентные одиночные операции. При перегрузке батчи чаще возвращают непроцессенные элементы — закладывайте повтор с backoff.
Снижайте размер чтения и записи: используйте ProjectionExpression, храните «узкие» представления для частых запросов, избегайте избыточных атрибутов в элементах. Это напрямую уменьшает потребляемые RCU/WCU и итоговый счёт (см. /pricing).
DynamoDB даёт несколько инструментов, чтобы балансировать между скоростью, стоимостью и корректностью данных. Понимание этих механизмов важно, когда система масштабируется и запросы начинают конкурировать друг с другом.
По умолчанию чтения eventually consistent: после записи может пройти короткое время, прежде чем все реплики будут возвращать новое значение. Это дешевле и обычно быстрее, поэтому подходит для лент, каталогов, кеш‑подобных данных и большинства пользовательских сценариев, где допустима «мгновенная устарелость».
Strongly consistent reads гарантируют чтение последней подтверждённой записи, но стоят дороже по RCU и могут иметь чуть большую задержку. Их обычно включают точечно: например, после критичной операции (оплата, смена прав доступа), когда нельзя показывать старое состояние.
Важно: сильная консистентность применяется к чтению из основной таблицы; для запросов через GSI сильная консистентность недоступна, и нужно проектировать потоки данных с учётом этого.
Условия позволяют сделать запись атомарной: «обнови, только если…». Это главный способ защититься от гонок без внешних блокировок.
Типовые паттерны:
attribute_not_exists(PK)#status = :pendingUpdateItem
SET #status = :paid
WHERE PK = :pk AND SK = :sk
CONDITION #status = :pending
Если условие не выполнено, DynamoDB вернёт ошибку условной проверки — и это нормальный, ожидаемый исход при конкуренции.
Транзакции (TransactWriteItems/TransactGetItems) нужны, когда требуется всё‑or‑ничего для нескольких элементов (включая разные таблицы): например, списать баланс и записать операцию в журнал одним действием.
Они дороже по потреблению ёмкости и задержке, а также накладывают лимиты на размер/количество затрагиваемых элементов. Поэтому их используют только там, где нельзя обойтись условными обновлениями и продуманной моделью данных.
Клиенты должны уметь ретраить запросы (таймауты, throttling). Чтобы повтор не создавал дубль, закладывают идемпотентность:
requestId) как часть PK/SK или отдельного «лок‑элемента»ClientRequestToken, чтобы повторная отправка не выполнила запись повторноДля обновлений «последняя запись побеждает» часто недостаточно. Тогда добавляют поле версии (например, version) и обновляют только при совпадении:
version = NConditionExpression version = N, увеличивая до N+1Так вы получаете предсказуемый контроль конфликтов без тяжёлых блокировок.
Подход single-table design в DynamoDB начинается не с «нормализации», а с перечисления запросов, которые система должна обслуживать. Дальше модель подгоняется под эти паттерны: одна таблица хранит разные типы сущностей, а ключи и индексы дают нужные выборки без джойнов.
Главная идея — группировать связанные данные в одну партицию и извлекать их одним Query. Это уменьшает количество сетевых походов, делает время ответа более предсказуемым и упрощает согласованное обновление связанных элементов.
Практический выигрыш: вместо «получить пользователя, потом заказы, потом позиции заказа» вы делаете один Query по партиции и получаете всё, что нужно, отсортированным по sort key.
Частый паттерн — «пользователь → его объекты». Например:
PK = USER#<userId>SK = PROFILE для профиляSK = ORDER#<orderId> для заказовSK = ORDERITEM#<orderId>#<lineId> для позицийТогда выборка заказов пользователя — это Query по PK с условием begins_with(SK, 'ORDER#'). Порядок можно кодировать в SK (например, ORDER#2025-12-22T10:00:00Z#<id>), чтобы удобно получать последние записи.
Query ограничивает чтение ключевыми условиями — это дешёвая часть.
FilterExpression отбрасывает элементы уже после чтения, поэтому вы платите RCU за все прочитанные данные, даже если вернули 1% результатов. Фильтры полезны как «дополировка», но не как основной механизм отбора.
Если нужны разные способы доступа (например, «все заказы по статусу» или «по email»), обычно создают GSI как материализованное представление: те же элементы, но с альтернативными ключами в индексе. Важно заранее понимать, какие запросы будут частыми, и делать под них индексы, а не пытаться «искать по любому полю».
Scan как основной запрос почти всегда означает, что ключи/индексы выбраны неверно.
Отдельный риск — «случайные ключи без смысла» (например, UUID в PK без группировки): вы теряете возможность собирать связанные данные одним Query и усложняете практически все прикладные сценарии чтения.
DynamoDB Streams — встроенный журнал изменений таблицы, который позволяет строить реактивные интеграции без опроса (polling). Он полезен, когда нужно запускать обработку «по факту» изменения данных: пересчёт агрегатов, синхронизация поискового индекса, отправка уведомлений или аудит.
Stream содержит события трёх типов: INSERT, MODIFY, REMOVE. Для каждого события можно настроить, какие образы данных попадут в запись:
Это важно для обработчиков: например, для инкрементального пересчёта удобно иметь и старое, и новое значение.
Самый распространённый путь — подписать AWS Lambda на Streams через event source mapping. Типовые use-cases:
OrderPaid) в очередь/шину;Lambda получает батчи записей; важно проектировать обработчик идемпотентным, потому что доставка «как минимум один раз».
Streams часто используют как CDC‑источник: DynamoDB → Lambda → SNS/SQS/Kinesis. Если требуется масштабируемая рассылка нескольким потребителям или более длительная ретенция, имеет смысл прокидывать события в Kinesis или писать в S3, а дальше строить пайплайн аналитики.
Порядок гарантируется только внутри одной shard, а значит на практике — в пределах группы ключей, но не глобально по таблице. Для дедупликации используйте стабильный идентификатор события (например, eventID) и таблицу/кэш обработанных событий или условные записи (conditional write).
Для диагностики опирайтесь на CloudWatch Logs и метрики задержки/ошибок. Для безопасного ретрая настройте DLQ или on-failure destination, а также частичные ответы батча (partial batch response), чтобы не «заваливать» всю пачку из‑за одной проблемной записи.
Полноценный replay ограничен временем хранения Streams, поэтому для переигрывания за более длинный период обычно дублируют события в Kinesis/S3 и переобрабатывают уже оттуда.
Чтобы DynamoDB оставалась «самообслуживаемой» в эксплуатации, важно заранее продумать жизненный цикл данных, стратегию восстановления и поведение при региональных сбоях. Эти механизмы обычно настраиваются один раз, но влияют на стоимость, риски и операционные процедуры постоянно.
TTL (Time To Live) позволяет помечать элементы временем истечения, после которого DynamoDB удалит их асинхронно. Это удобно, когда данные по смыслу временные и не должны «захламлять» таблицу.
Типичные кейсы:
Важно учитывать: удаление по TTL не происходит строго «в секунду истечения» — задержка допустима. Поэтому TTL нельзя использовать как точный таймер для бизнес‑логики, но можно — как механизм утилизации данных.
Для восстановления данных применяют два уровня защиты:
Point-in-Time Recovery (PITR) — непрерывное хранение изменений и возможность откатиться к состоянию таблицы на выбранный момент в прошлом (в пределах окна хранения). Это снижает риск от логических ошибок (например, случайного удаления/перезаписи).
On-demand backup — ручная или автоматизированная «снимковая» копия по требованию. Полезно перед рискованными миграциями, массовыми перерасчётами или релизами, когда хочется зафиксировать контрольную точку.
Глобальные таблицы реплицируют данные между регионами и дают низкие задержки чтения рядом с пользователем, а также повышают устойчивость при проблемах в одном регионе.
Ключевое требование — заранее определить, как вы обрабатываете конфликты записи. Если запись в один и тот же элемент может происходить из разных регионов, понадобится стратегия: строгое разделение зон записи, идемпотентные операции, версионирование/метки времени или прикладное разрешение конфликтов.
Выбор опций стоит привязать к целям:
Практика, которая отличает «настроено» от «работает»: регулярные учения на стенде. Воспроизведите сценарий (ошибка приложения, порча данных, потеря региона), восстановите таблицу из PITR/бэкапа, переключите конфигурацию, проверьте целостность и время восстановления — и задокументируйте шаги.
Безопасность в DynamoDB строится вокруг двух уровней: контроля доступа (кто и какие операции может делать) и защиты данных (как хранятся и передаются данные). При этом важно помнить о модели разделения ответственности: AWS обеспечивает безопасность управляемого сервиса, а приложение отвечает за корректные права, валидацию данных и логику авторизации.
Доступ к DynamoDB обычно выдаётся через IAM‑роли (для EC2/ECS/EKS/Lambda) или IAM‑пользователей (реже). Практика — выдавать права максимально узко:
GetItem/Query/PutItem, без административных UpdateTable;table/…/index/…).Для более тонкой защиты используют условия IAM (например, запрет Scan, ограничение по dynamodb:LeadingKeys для доступа к конкретным partition key), но их нужно тестировать на реальных паттернах запросов.
DynamoDB шифрует данные «на диске» по умолчанию. Управление ключами обычно делается через AWS KMS: можно оставить ключ AWS-managed или подключить customer-managed ключ для контроля ротации, политик и аудита использования ключа.
На стороне приложения всё равно стоит шифровать/токенизировать чувствительные поля, если нужны требования уровня «zero trust» к операторам или внешним интеграциям.
Если сервисы работают в VPC, используйте VPC endpoints (PrivateLink) для DynamoDB, чтобы трафик не выходил в интернет и не зависел от NAT. Это упрощает сетевую модель угроз и снижает число внешних точек входа.
Для контроля действий включают CloudTrail (кто вызывал API и какие), а метрики и аномалии отслеживают через CloudWatch. Для расследований полезно сочетать аудит API‑вызовов с прикладными логами (корреляционные ID, пользователь, бизнес‑операция).
AWS берёт на себя физическую безопасность, патчинг и изоляцию управляемой инфраструктуры. На вашей стороне остаются: правильные IAM‑политики, проверка прав пользователя на уровне бизнес‑логики (не путать с IAM), защита от утечек через логи, управление секретами и безопасная обработка ошибок.
У DynamoDB цена складывается из нескольких «ручек», и важно оценивать их вместе с выбранными индексами и паттернами доступа.
Основные составляющие:
Практика: сначала оцените самые дорогие операции (обычно записи + GSI), затем прикиньте рост данных, и только после этого выбирайте On-Demand или Provisioned.
Критичные метрики в CloudWatch: Latency (SuccessfulRequestLatency), ThrottledRequests, ConsumedReadCapacityUnits/ConsumedWriteCapacityUnits, Errors (4xx/5xx), а также SystemErrors. Троттлинг почти всегда означает: неверно подобранная ёмкость/авто‑скейлинг или «горячий» partition key.
Проверьте, какие запросы используют Scan вместо Query, не возвращаете ли вы «тяжёлые» элементы без проекции, и не тянете ли лишние атрибуты из индекса. Для точечной диагностики полезны CloudWatch Contributor Insights и логирование на уровне приложения с измерением размера ответа и количества ретраев.
Типовой безопасный путь:
Даже если в конкретном проекте вы не используете AWS/DynamoDB (например, из‑за требований к размещению данных), ключевые идеи из статьи остаются универсальными: начинайте с access patterns, проектируйте ключи/индексы под конкретные запросы, следите за «горячими» ключами, измеряйте стоимость операций и делайте идемпотентные обработчики событий.
Если вам нужно быстро проверить архитектуру, собрать прототип API и фронтенда, а затем итеративно доработать модель данных, это удобно делать в TakProsto.AI — платформе vibe‑coding для российского рынка. В TakProsto.AI можно описать систему в чате, включить planning mode, получить работающий web/серверный/мобильный прототип (React, Go + PostgreSQL, Flutter), а затем экспортировать исходники, развернуть и подключить свой домен. Это помогает быстрее «прогнать» паттерны доступа и нагрузочные сценарии до того, как вы окончательно зафиксируете схему (будь то DynamoDB или реляционная БД).
DynamoDB уместна, когда нужны быстрые чтения/записи с предсказуемой задержкой при росте нагрузки и минимальная операционная рутина.
Типовые кейсы:
Если вам нужны сложные ad-hoc запросы, множественные JOIN, агрегации «на лету», гибкая аналитика по разным измерениям и отчётность, DynamoDB обычно будет неудобной или дорогой.
В таких случаях чаще выигрывают:
partition key определяет, в какую физическую партицию попадёт item: значение хэшируется, и запросы маршрутизируются детерминированно. Поэтому от partition key зависит распределение нагрузки.
Практика:
STATUS#active при 80% обращений).sort key упорядочивает элементы внутри одного partition key и позволяет делать диапазонные выборки через Query.
Частые приёмы:
«Горячая» партиция появляется, когда много операций бьют в один и тот же partition key, концентрируя нагрузку на небольшом числе физических разделов.
Как лечить:
PRODUCT#<id>#<shard>, где shard = hash(id) % N или случайное значение;Query читает данные в рамках одного partition key (с условиями по sort key) — это основной «правильный» способ выборок.
Scan проходит таблицу/индекс целиком, поэтому:
Вторичные индексы добавляют новые паттерны доступа, которые нельзя выразить ключами таблицы.
PK/SK, максимально гибко, но дороже на записи и хранение; чтение — только eventual consistency.partition key, другой ; создаётся только при создании таблицы и подходит для альтернативной сортировки/фильтрации внутри одной группы.On-Demand выбирают, когда нагрузка непредсказуема (пики, новая функциональность, батчи без стабильного профиля). Вы платите за фактические запросы.
Provisioned выгоден при стабильной/прогнозируемой нагрузке:
Для зрелых сервисов чаще выигрывает Provisioned с корректными алертами на throttling и latency.
Eventual consistency дешевле и обычно быстрее, но после записи возможна короткая «устарелость» чтения. Strongly consistent reads возвращают последнее подтверждённое значение, но стоят дороже по RCU.
Практика:
Важно: для чтений через GSI strong consistency недоступна.
TTL автоматически удаляет временные данные (сессии, токены, кэш), но удаление асинхронное — не используйте TTL как точный таймер бизнес-логики.
Для восстановления данных:
Для multi-region используют глобальные таблицы, но заранее продумывают стратегию конфликтов записей (зоны записи, идемпотентность, версии/метки времени).
SK для «последних N событий»;SK для уникальности и сортировки, например ORDER#<createdAt>#<orderId>.Так вы получаете выборки без сканирования и без джойнов.
Scan оставляют для админских задач, миграций и редких разовых отчётов.
sort keyДобавляйте индекс только под реально частые и критичные запросы.