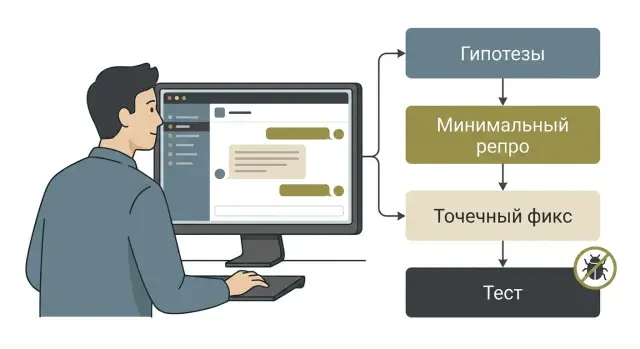
Практичная методика: Claude Code для поиска регрессий через гипотезы, минимальный репро, точечный фикс и тест, который не даст багу вернуться.
Скрытая регрессия - это баг, который появился после изменения кода, но долго не проявляется. Обычно он живет в углах продукта: редких сценариях, необычных данных, старых настройках, гонках между запросами. Пока пользователь не попадет ровно в нужную комбинацию условий, внешне все выглядит нормально.
Часто такие регрессии маскируются под случайность. Сигналы есть, но их трудно собрать в одну картину: редкие падения в логах без понятного паттерна, странные просадки метрик (например, конверсии или доли успешных платежей), багрепорты в стиле «не всегда воспроизводится», жалобы на медленную работу у части пользователей или проблемы после деплоя, которые исчезают после повторной попытки.
Ручное тестирование и ревью плохо ловят такие вещи по простой причине: люди проверяют ожидаемые пути. Ручные проверки идут по чеклисту, а чеклист почти никогда не покрывает случайные данные, нестабильную сеть, конкурирующие запросы и тонкие условия вроде пустого поля, таймзоны или некорректного кеша. Ревью тоже чаще смотрит на корректность изменения в изоляции, но редко моделирует последствия: кто еще читает этот флаг, где используется тот же DTO, что будет при старой версии клиента, что сломается при миграции схемы.
Отдельная проблема - частичные фиксы без понимания причины. Если приглушить симптом (добавить лишний try/catch, повтор запроса, скрыть ошибку в UI), регрессия становится еще более скрытой. Она продолжает портить данные или метрики, а отладка позже занимает больше времени, потому что первичный след уже замазан.
Пример из практики: на бэкенде меняют формат поля в ответе (Go + PostgreSQL), а фронт на React где-то не ожидает null. Падает это только на старых данных у части пользователей. Через неделю проблема всплывает как редкие ошибки на одном экране, и никто не связывает это с тем самым «небольшим» изменением.
Поэтому Claude Code полезен не как «волшебный поиск ошибки по логам», а как способ быстро собрать гипотезы, связать разрозненные сигналы и превратить их в управляемую проверку.
Claude Code особенно хорошо помогает там, где регрессия прячется между строк: код изменился немного, а поведение стало странным только в одном углу продукта. В таких случаях он ускоряет первый этап расследования: выдает правдоподобные причины и подсказывает, как проверить каждую по очереди, вместо многочасового гадания.
Его сильная сторона - работа с гипотезами. По симптомам и диффу он может предложить 5-7 вариантов: некорректное условие в новой ветке, гонка, кеш, ошибки в обработке пустых значений, несовместимость формата данных. Он же неплохо подсвечивает подозрительные места в изменениях: где менялись типы, где появилась оптимизация, где логика стала «чуть сложнее».
Важно помнить и ограничения. Если контекста мало, модель легко делает неверные допущения: путает версии библиотек, додумывает поведение окружения или предлагает исправление, которое выглядит логично, но не соответствует реальному стеку. Поэтому ответы лучше воспринимать как список идей, а не как истину.
Чтобы подсказки были точнее, дайте входные данные, которые можно проверить:
Фокус удерживается проще, чем кажется: один баг, один сценарий, один критерий готовности. Удобно заранее договориться о формате ответа: сначала 3-5 гипотез, затем что проверить для каждой, затем какой минимальный эксперимент подтвердит или опровергнет.
Пример: «После рефакторинга фильтра заказов иногда пропадает последний элемент на второй странице. Проявляется только при пустом поисковом запросе». В ответ вы получаете причины (ошибка пагинации, off-by-one, кеширование результата) и короткие проверки на 10 минут. Главный выигрыш здесь простой: меньше шума, больше управляемых шагов.
Чтобы Claude Code реально помог, ему нужны факты. Десять минут подготовки часто экономят часы переписки и ложных фиксов.
Начните с контекста изменения. Укажите, где вы впервые заметили поломку: версия релиза или номер сборки, хеш коммита, ветка, окружение (локально, staging, прод) и что менялось рядом по времени. Если регрессия появилась после конкретного PR, это особенно полезно: модель привяжет гипотезы к реальным диффам, а не будет строить версии вслепую.
Затем зафиксируйте ожидание в одной-двух фразах. Не «не работает авторизация», а «после ввода корректного кода из SMS пользователь должен попасть на главную, а сейчас остается на экране ввода и в логе появляется 401». Чем четче сформулировано «должно быть» и «получается», тем проще отделить баг от спорного поведения.
Дальше приложите артефакты, которые можно проверить: 20-50 строк логов вокруг ошибки, стек-трейс целиком, пример запроса (параметры, тело, заголовки), шаги воспроизведения и, если есть, границу между последним «хорошим» и первым «плохим» коммитом.
Отдельно обозначьте границы фикса: «не меняем схему БД», «не трогаем публичный API», «не обновляем зависимости», «не меняем UX». Это удерживает решение точечным и снижает риск новых регрессий.
И заранее определите критерий готовности. Не «ошибка исчезла», а проверяемое условие: репро больше не проходит, ключевой сценарий работает в нужных окружениях, и есть проверка (хотя бы ручная, а лучше тест), которая ломается на старом коде и проходит на новом.
Скрытые регрессии редко имеют одну очевидную причину. Первая задача - не угадать фикс, а быстро расширить поле возможных объяснений и тут же сузить его проверками.
Сведите входные данные в один абзац: что было нормально раньше, что стало плохо сейчас, где это видно (лог, UI, метрика) и после какого коммита или релиза появилось. Если есть список последних изменений, вынесите его отдельно: даже 5-10 пунктов дают модели опору.
Дальше попросите ответить в строгом формате: гипотеза -> как проверить -> что ожидаем увидеть -> следующий шаг. Так вы получите не абстрактные версии, а план отсева.
Хороший запрос заставляет модель сделать две вещи: (1) дать причины с приоритетом, (2) описать наблюдения, которые подтвердят или опровергнут каждую.
Вот шаблон, который удобно копировать:
Симптом: <что сломалось, где видно>
Окружение: <версия, флаги, платформа>
Когда появилось: <примерно, после каких изменений>
Последние изменения: <список 5-10 пунктов>
Составь 8 гипотез причин регрессии.
Для каждой: приоритет (высокий/средний/низкий), быстрый тест (до 10 минут), ожидаемое наблюдение, что делать дальше.
Отдельно выдели гипотезы, напрямую связанные с последними изменениями.
В конце перечисли, каких данных не хватает, чтобы сузить причины.
Ответ дай таблицей или нумерованным списком в одном формате.
Не спорьте с гипотезами на уровне мнений. Превращайте их в проверки и вычеркивайте все, что не проходит быстрый тест. Если модель предлагает сложную проверку, просите упрощение: «дай минимальный способ проверить это за 5 минут».
Чтобы ускориться, полезно держать короткий план на первые 20-30 минут: убедиться, что баг воспроизводится на чистом окружении и без кешей; сравнить поведение до/после последнего изменения (коммит или флаг); включить точечный лог в 1-2 местах, где расходятся ожидания; зафиксировать результат каждого шага одной строкой.
Мини-сценарий: после правки валидации форма стала «иногда» пропускать пустое поле. Пусть Claude Code предложит версии (порядок проверок, условие валидации, кеш состояния, гонка событий), а вы сразу проверяете две самые вероятные. Через 15 минут обычно остаются 1-2 реальные причины, с которыми уже можно делать минимальный репро.
Скрытая регрессия часто выглядит как туман: «иногда ломается», «у некоторых пользователей», «после недавних правок». На этом шаге задача одна: превратить туман в короткий сценарий, который воспроизводится стабильно. Тогда модель перестает гадать и начинает помогать как диагност.
Попросите свести проблему к одному пути: один пользователь, одно действие, один ожидаемый результат и один фактический. Разделяйте симптом и причину. Симптом вы наблюдаете (например, 500 или пустой список). Причину вы только подозреваете (например, «сломали кеш»). Если смешать их, модель будет чинить предположение вместо факта.
Что полезно попросить у Claude Code на этом шаге:
Дальше вы режете лишнее. Если у вас React фронтенд и Go бэкенд, попробуйте сначала воспроизвести проблему на уровне API: один запрос, одна запись в базе, один ответ. Если на API все чисто, переносите репро на фронтенд: один экран, один компонент, минимум состояния.
Пример: после изменения фильтрации в списке «заказы» у части пользователей список пустой. Минимальный репро может оказаться таким: «в базе есть 2 заказа, у одного статус NULL, запрос с параметром status=active возвращает 0 вместо 1». Это сразу задает рамку для теста и фикса: дело в NULL, а не в «сложном UI».
Если вы используете TakProsto (takprosto.ai) как среду для быстрых экспериментов, можно собрать маленький стендовый сценарий через чат: один эндпоинт, фикстуры для БД и короткая проверка ответа. Чем меньше движущихся частей, тем быстрее вы дойдете до точечного изменения.
Когда репро уже есть, цель - вернуть ожидаемое поведение с минимальными изменениями. Это особенно важно для скрытых регрессий: вы еще не до конца знаете, какие места в коде завязаны на текущую логику.
Лучше сразу просить у модели не один вариант, а несколько, чтобы осознанно выбрать самый безопасный.
Предложи 2-3 варианта фикса для этого репро.
Для каждого: (1) почему это точечный фикс, (2) что он точно не ломает, (3) возможные побочные эффекты,
(4) как быстро проверить каждый побочный эффект, (5) какой вариант самый безопасный и почему.
Ограничение: изменить минимум файлов и логики, без рефакторинга.
Обычно полезно получить три подхода: самый безопасный (с явной проверкой условий), самый простой (минимальная правка) и компромиссный (чуть шире, но лучше по смыслу). И обязательно спросить, почему не стоит чинить «в другом месте». Например, если баг в обработчике запроса, модель может предложить фикс на клиенте. Это выглядит быстро, но часто переносит проблему и делает поведение непредсказуемым.
Точечный фикс обычно выглядит так: вы меняете 1-2 места, которые напрямую связаны с репро; не трогаете публичные контракты и поведение на нормальном пути; оставляете дифф маленьким и читаемым, чтобы ревью действительно могло поймать ошибку.
После выбора варианта попросите перечислить побочные эффекты и план проверки. Если вы правите условие кеширования, последствия могут быть простыми и неприятными: выросла нагрузка, изменились коды ответов, всплыли редкие кейсы (пустой список, нулевое значение, таймзона).
Если модель предлагает большой рефакторинг, это повод остановиться. Спросите прямо: «какая минимальная правка исправит репро без перестройки структуры». Это почти всегда снижает риск новой регрессии.
Фикс без теста - это способ вернуться к той же проблеме через месяц. Цель простая: сделать так, чтобы найденная регрессия больше не возвращалась незаметно.
Начните с базового правила: тест должен воспроизводить ровно тот сценарий, который вы собрали в минимальном репро. Не расширяйте его «на всякий случай». Чем ближе тест к репро, тем меньше шансов получить нестабильность или ложные падения.
Тип теста выбирайте по месту, где проявилась регрессия: модульный (чистая функция, валидация), интеграционный (стык БД, HTTP, очереди, кеша), E2E (пользовательский сценарий), контрактный (формат запроса/ответа между сервисами).
Дальше сформулируйте задачу модели жестко: «Напиши тест, который падает до фикса и проходит после. Используй сценарий из репро. Назови тест так, чтобы по названию было понятно, что он защищает». Хорошее имя теста читается как причина прошлой поломки.
Добавьте одну проверку на тот самый крайний случай, который и вызвал регрессию: пустая строка, нулевое значение, лишний пробел, другой часовой пояс, неожиданный порядок элементов. Один точный триггер обычно лучше трех размытых.
Финальная самопроверка перед мерджем:
Самая частая причина провала: вы просите помощи у Claude Code, но не даете ему за что зацепиться. Тогда вместо расследования получается набор общих советов, которые звучат умно, но не приближают к багу.
Фразы вроде «после рефакторинга стало ломаться» почти бесполезны. Нужны опорные точки: что именно ломается, как это измеряется, и где граница между нормой и багом. Минимальный набор, который резко повышает качество ответа: версия или коммит, точный сценарий, ожидаемое и фактическое поведение, кусок лога или текст ошибки, входные данные и окружение (браузер, конфиг, фича-флаги).
Если вы одновременно меняете бизнес-логику, формат данных и обработку ошибок, вы теряете контроль. Методика работает, когда шаги маленькие: минимальный репро -> узкий фикс -> тест.
Хороший ориентир: если вы не можете объяснить фикс одним предложением, он, скорее всего, слишком широкий.
Если модель сказала «скорее всего проблема в кеше» - это не ответ, а гипотеза. Правильное действие: поставить дешевые проверки. Добавьте временный лог, выключите кеш флагом, зафиксируйте порядок действий. Если гипотеза не подтверждается за 10-15 минут, не надо ее дожимать.
Ловушка: тест проверяет деталь, которая изменилась вместе с багом, но не является причиной. Например, регрессия в React из-за неверной зависимости в useEffect, а тест проверяет текст уведомления, который заодно поменяли. Такой тест быстро начнет раздражать, и его отключат.
Перед тем как закреплять фикс тестом, коротко проверьте: тест падает на старом коде и проходит на новом; он проверяет инвариант, а не оформление (текст, тайминги, порядок рендеров); репро минимальный; один тест - один смысл.
Перед мерджем легко обрадоваться зеленому прогону и пропустить мелочь, которая вернет регрессию через неделю. Лучше потратить 10 минут на короткую проверку, чем потом снова собирать контекст.
Сначала проверьте воспроизводимость: минимальный репро должен запускаться одинаково локально и в CI (те же данные, флаги, версии зависимостей). Если локально баг ловится, а в CI нет, фикс превращается в лотерею.
Затем посмотрите на качество теста: он уверенно краснеет на старом коде и уверенно зеленеет на новом, и так несколько прогонов подряд. Если тест «иногда красный», он не защищает, а отвлекает.
И наконец, убедитесь, что вы не меняете поведение там, где это не требовалось. Быстро посмотрите дифф глазами и спросите себя: что здесь обязательно для исправления, а что просто «по пути»?
Короткий набор того, что стоит отметить перед мерджем:
Если вы работаете в TakProsto, полезно сохранить снапшот перед изменениями и после них, чтобы при неожиданном эффекте быстро сравнить поведение или откатиться через rollback.
Представьте ситуацию: после обновления зависимостей в парсере начал падать импорт, но только на редком формате данных, который встречается у 1-2% пользователей. В саппорт прилетает: «Иногда загрузка зависает, а в логах странная ошибка про дату и запятую в числе». Вручную поймать тяжело: в тестовых данных такого файла нет, а в проде он появляется раз в неделю.
Дальше цепочка выглядит просто. Жалобу превращаете в факты (версия сборки, пример строки, кусок стека). Затем просите Claude Code выдать гипотезы: что могло измениться из-за апдейта, какие входные данные пограничные, где поставить временное логирование. Из гипотез выбираете 1-2 самые проверяемые и делаете минимальный репро: маленький файл с одной проблемной записью и один вызов функции, который воспроизводит падение за секунды.
Когда баг стал управляемым, фикс должен быть точечным. Например, парсер раньше принимал числа вида "1,23" как 1.23, а новая версия библиотеки требует точку. Вы не переписываете весь импорт, а добавляете нормализацию только для этого поля и только в этом месте. После этого добавляете тест, который падает без фикса и проходит с ним.
Чтобы такие находки не терялись, договоритесь о простом порядке:
Команде помогает единый шаблон запроса: «симптом -> версии -> ожидание -> фактическое -> репро -> что нельзя сломать». В TakProsto удобно фиксировать такой план в Planning Mode и возвращаться к нему, когда контекст начинает расползаться. Так редкие регрессии перестают быть мистикой и превращаются в обычную задачу с понятным выходом: репро, фикс, тест и запись в историю.
Скрытая регрессия — это баг, который появился после изменения кода, но проявляется только в редких условиях: необычные данные, старые настройки, гонки запросов, нестабильная сеть, специфичная таймзона.
Типичный признак: «вроде все работает», но иногда всплывают странные падения в логах, просадки метрик или багрепорты «не всегда воспроизводится».
Потому что люди проверяют ожидаемые пути по чеклисту. А редкие кейсы обычно живут вне чеклиста: null в данных, пустые строки, старые записи в БД, конкурирующие события, кеш с устаревшим значением.
Ревью тоже часто смотрит изменение «в изоляции» и не моделирует последствия: кто еще использует тот же DTO, как поведет себя старая версия клиента, что будет при миграции.
Потому что «приглушение симптома» часто делает баг менее заметным, но не убирает причину.
Частые анти-примеры:
try/catch и скрыли ошибку в UI;В итоге регрессия может продолжать портить данные или метрики, а отладка позже становится сложнее.
Дайте факты, которые можно проверить:
И сразу обозначьте ограничения: что нельзя менять (схему БД, публичный API, зависимости, UX).
Попросите строгий формат: гипотеза → как проверить → что ожидаем увидеть → следующий шаг.
Так вы получите план отсева, а не «умные советы». Хорошо работает лимит на проверки: «быстрый тест до 10 минут» — это держит фокус и снижает шанс уйти в теории.
Относитесь к ответу как к списку идей, а не к диагнозу.
Простой фильтр:
Если гипотеза не подтверждается быстро, не «дожимайте» ее часами — переходите к следующей.
Цель — превратить «иногда ломается» в короткий сценарий, который воспроизводится стабильно.
Полезные шаги:
Когда репро занимает секунды, расследование резко ускоряется.
Выбирайте самый маленький дифф, который исправляет репро и не меняет поведение «нормального пути».
Практичный подход:
Если модель тянет к большому рефакторингу — возвращайте к вопросу: «какая минимальная правка чинит репро без перестройки структуры?»
Тест должен повторять ровно тот сценарий, который вы нашли в репро, и быть стабильным.
Короткие правила:
Тип теста выбирайте по месту бага: модульный, интеграционный, E2E или контрактный.
Удобно использовать платформу как «песочницу» для быстрых экспериментов: собрать маленький стендовый сценарий — один эндпоинт, фикстуры для БД, короткая проверка ответа.
Практично также:
Это особенно полезно для редких регрессий, где важна скорость итераций.