Разбираем, как телеметрия с endpoints и облачная аналитика превращают EDR в платформу данных: архитектура, метрики, юнит-экономика и риски.
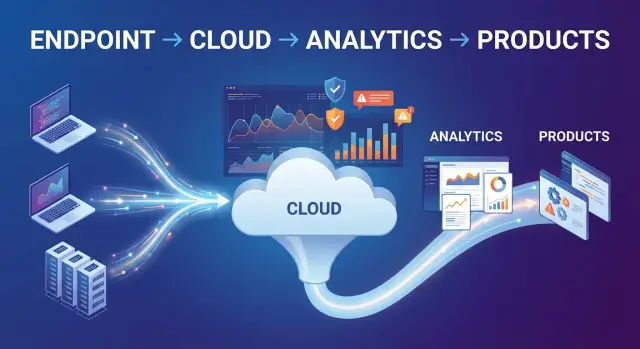
Раньше EDR воспринимали как «агента на компьютере», который умеет обнаруживать и расследовать инциденты на конечных точках. В модели платформы данных фокус смещается: главным активом становится не отдельная функция детекта, а поток телеметрии и способность превращать его в знания, решения и продуктовые модули.
Под платформой данных обычно понимают систему, которая:
Важно: ценность здесь возникает не только из набора функций, а из непрерывного цикла «данные → аналитика → улучшения → ещё более полезные данные».
Endpoint — место, где сходятся процессы, файлы, сетевые подключения, учётные записи и действия пользователя. Поэтому события с конечных точек часто дают более подробный и «проверяемый» сигнал, чем разрозненные логи периметра.
Чем шире покрытие (больше устройств, типов ОС, сценариев работы), тем выше шанс увидеть ранние признаки атаки, подтвердить цепочку действий и отличить реальную угрозу от «шума».
В EDR вы покупаете инструмент. В платформенной модели вы фактически инвестируете в канал данных и в аналитический слой, который со временем становится точнее: правила уточняются, модели обучаются, контекст обогащается.
Это влияет и на продуктовую упаковку: появляются дополнительные модули, сценарии XDR, управляемые сервисы, отчётность для комплаенса — всё на одной базе данных и идентичности.
Дальше — без «внутренней кухни» и предположений о реализации конкретных вендоров. Мы разберём проверяемые принципы: какие endpoint‑данные действительно полезны, как устроен конвейер доставки и идентификации событий, что происходит в облачной аналитике и почему эффект масштаба способен улучшать качество защиты — а также где у модели есть ограничения и риски.
Ценность платформы данных в кибербезопасности начинается не с «ещё одного агента», а с того, какие именно сигналы endpoint превращаются в пригодные для аналитики события. В контексте EDR/XDR телеметрия — это сырьё, из которого затем получаются детекты, расследования и управляемые реакции.
На практике наиболее полезные категории телеметрии на конечных устройствах выглядят так:
Количество событий само по себе не гарантирует лучшую защиту. Практически важны три вещи:
Полнота: покрывает ли телеметрия ключевые этапы атаки (запуск → закрепление → движение → эксфильтрация).
Точность и контекст: есть ли у события нужные поля (кто запустил, откуда пришёл файл, какая команда выполнялась), чтобы детект был уверенным.
Своевременность: как быстро событие попадает в аналитику. Опоздание на минуты иногда означает пропущенную возможность остановить атаку.
Даже одинаковые действия на Windows, macOS и Linux описываются по‑разному. Поэтому платформы нормализуют данные: приводят поля к единой модели (например, process_name, parent_process, device_id, user) и устраняют дубликаты.
Это снижает стоимость аналитики: одно правило или модель начинают работать сразу на разных ОС и источниках.
Самый высокий ROI обычно дают связанные цепочки: граф процессов + командная строка + сетевое соединение + контекст пользователя. Такие сигналы позволяют отличить «админскую утилиту» от действий злоумышленника, уменьшают ложные срабатывания и делают реакцию (изоляция хоста, блокировка процесса, сброс сессии) более уверенной.
Чтобы телеметрия стала активом, ей нужен предсказуемый конвейер: данные должны появляться на endpoint, безопасно доходить до облака и не терять смысл по дороге. На практике ценность создаёт не «объём ради объёма», а качество доставки и корректная привязка к контексту.
На endpoint обычно работает агент, который считывает события из ОС и приложений и приводит их к единому формату. Ключевая часть — буферизация: устройства бывают в офлайне, перезагружаются, «засыпают», а пользователь может закрыть крышку ноутбука в самый неудобный момент.
Поэтому агенту важно уметь:
Доставка телеметрии — это всегда компромисс между скоростью, стоимостью и влиянием на сеть. Даже если данные «не секретные», их всё равно передают по защищённому каналу: шифрование и проверка целостности снижают риск перехвата и подмены.
Не менее важно управление нагрузкой:
В корпоративных условиях это особенно заметно: часть устройств сидит за прокси/VPN, часть — в филиалах с нестабильным интернетом, а часть — в командировках. Конвейер должен учитывать эти режимы как норму.
Сырые события без идентификаторов быстро превращаются в шум. Поэтому при приёме и нормализации телеметрии системе нужны устойчивые «якоря»:
Это помогает избегать типичных ошибок: считать разные ноутбуки одним хостом из‑за совпавшего имени или, наоборот, дробить один endpoint на множество сущностей из‑за смены IP.
Отправлять «всё и всегда» дорого и не всегда полезно. Обычно выбирают смешанную модель: на endpoint агрегируют метрики и повторяющиеся события, а в облако отправляют то, что нужно для расследований и детектов (цепочки процессов, признаки эксплуатации, ключевые точки поведения).
Хороший баланс снижает стоимость хранения и трафика, но сохраняет доказательность: чтобы по телеметрии можно было не только поднять алерт, но и объяснить, что именно произошло и почему это важно.
После того как события с endpoint’ов приняты и нормализованы, основная «магия» переносится в облако: там поток превращается в пригодный для поиска, корреляции и детектов набор данных. Важно понимать, что это не один монолитный процесс, а несколько слоёв обработки, каждый из которых влияет на скорость расследований и стоимость.
Первый слой — потоковый конвейер. События попадают в очереди, чтобы система выдерживала пики (например, массовые обновления ПО или всплеск активности в сети) без потерь. Затем выполняются:
Результат — события становятся сопоставимыми между собой и готовыми для быстрых запросов.
Дальше данные раскладываются по уровням хранения. «Горячий» слой держит свежую телеметрию и индексы для мгновенного поиска. «Холодный» слой — более дешёвое хранение для ретроспективы и комплаенса.
Сроки хранения — не просто опция в настройках. Это компромисс между:
Для расследований критичны два качества: скорость ответа и предсказуемость. Хорошая платформа оптимизирует частые запросы (по хэшу, процессу, цепочке исполнения, сетевым соединениям) и поддерживает «сквозную» навигацию от алерта к исходным событиям — чтобы аналитик не тратил время на ручное склеивание фактов.
Цена аналитики в облаке растёт из‑за трёх факторов: объёма данных, сложности запросов и времени хранения. Архитектурные решения снижают себестоимость, когда платформа:
Итог: облачная аналитика — это не «хранилище логов», а фабрика, где телеметрия превращается в быстрый поиск, контекст и основу для дальнейших детектов.
Сама по себе телеметрия — это «сырьё». Ценность появляется в момент, когда поток событий превращается в детекты: понятные сигналы о подозрительной активности, приоритизированные и привязанные к контексту. Для этого используются не одиночные сигнатуры, а поведенческие модели и корреляции.
Одиночное событие (например, запуск процесса) редко достаточно, чтобы уверенно говорить об атаке. Поведенческий подход смотрит на цепочку: что запустилось, что создало, к каким ресурсам обратилось, как менялись привилегии, были ли попытки закрепления.
Корреляция соединяет разные «кусочки» в историю: действия пользователя, процесса, устройства и, при наличии интеграций, соседних систем. В результате детект описывает не «нашли строку», а «наблюдаем сценарий», что обычно лучше переносится на новые варианты атак.
Детекты в реальном времени нужны там, где важны секунды: эксплуатация уязвимости, запуск вредоносного кода, попытка отключить защиту. Такие правила и модели часто проще и строже — чтобы сработать быстро.
Пакетные расчёты (например, раз в час/день) полезны для более тяжёлой аналитики: поиск слабых сигналов, сравнение с историческим поведением, выявление редких комбинаций, пересчёт рисков. Это дополняет «быстрые» детекты и помогает находить то, что не бросается в глаза.
Качество детекта часто определяется не «умностью» алгоритма, а количеством контекста вокруг события. Обогащение помогает ответить на практические вопросы: это известный доверенный софт или нет, действие типично для данного отдела, есть ли совпадения с недавними инцидентами, какой критичности актив затронут.
Чем больше контекста и связей, тем легче отличать необычное, но легитимное поведение от реальной атаки — и тем меньше шума у аналитиков.
Правила и модели не «пишутся раз и навсегда». Они эволюционируют по циклу обратной связи: разбор инцидентов, результаты threat hunting (охоты за угрозами), наблюдение за обходами, доработка логики и порогов, затем повторная проверка на реальных данных.
В зрелой системе этот цикл превращает каждую расследованную атаку в улучшение детектов для всех: новые паттерны становятся правилами, а сложные сценарии — частью моделей и корреляций.
Модель «чем больше клиентов, тем лучше защита» опирается на простую идею: больше endpoint‑телеметрии даёт больше примеров реального поведения — как нормального, так и вредоносного. Это помогает быстрее замечать новые приёмы атак и точнее отличать инциденты от фонового шума.
При росте базы датчики видят больше вариаций одной и той же техники: разные версии ПО, привычки пользователей, схемы администрирования. В результате улучшаются:
Но эффект не бесконечен: после определённого объёма добавление однотипных данных даёт всё меньше новой информации, а стоимость хранения и обработки растёт.
Сетевой эффект проявляется сильнее всего, когда телеметрия превращается в обогащение: хэши, домены, цепочки процессов, признаки эксплуатации уязвимостей, последовательности действий злоумышленника. Чем больше подтверждённых наблюдений, тем легче:
Масштаб может вводить в заблуждение. Типичные риски:
Качество нужно измерять и защищать от деградации:
Масштаб действительно усиливает защиту, если поставщик умеет превращать рост телеметрии в проверяемые улучшения, а не просто в «больше данных».
Когда безопасность строится как платформа данных, продуктовая логика меняется: ценность продаётся не через набор разрозненных агентов, а через единый поток телеметрии, из которого можно извлекать разные ответы на разные вопросы. В этой модели данные — общий актив, а продукты — разные «линзы» аналитики и автоматизации над одним и тем же фундаментом.
Платформенный подход выигрывает, когда собранная endpoint‑телеметрия используется повторно. Один и тот же сенсор фиксирует процессы, сетевую активность, файловые операции, учётные события — а дальше это упаковывается в модули:
Покупатель воспринимает это как расширение функциональности, а поставщик — как монетизацию уже собранных данных с минимальными дополнительными издержками на сбор.
Единый сенсор снижает трение для расширения: чтобы подключить новый модуль, чаще не нужно разворачивать ещё один агент, пересогласовывать политики, увеличивать риск конфликтов и нагрузку на ИТ.
Это делает upsell более «мягким»: клиент платит за новые сценарии и аналитику, а не за новую установку на тысячи endpoints.
Упаковка почти всегда сводится к выбору оси тарификации:
На практике часто комбинируют: базовая цена за endpoint + доплаты за модули и/или повышенные лимиты данных. Это помогает одновременно удерживать простоту покупки и контролировать экономику обработки телеметрии.
Если смотреть на CrowdStrike как на платформу данных, то «качество детекта» — лишь половина истории. Вторая половина — сколько стоит производить, хранить и превращать телеметрию в решения, и как эти затраты масштабируются вместе с базой endpoint.
Фиксированные затраты — то, что вы платите «за саму фабрику»:
Переменные затраты растут с объёмом данных и активностью клиентов:
Для data‑platform модели важны не только CAC и LTV, но и технологические единицы:
Маржа улучшается не «магией», а инженерией:
Итог: сильная платформа выигрывает дважды — она повышает безопасность и одновременно снижает цену «одной единицы данных», превращая масштаб в прибыль.
Платформа становится стандартом не тогда, когда у неё «много функций», а когда вокруг неё выстраивается рабочая экосистема: данные свободно ходят между системами, а новые сценарии добавляются быстрее, чем их успевает написать внутренняя команда вендора.
Ключевой признак платформы — понятный контракт на обмен данными: API, вебхуки, коннекторы и стабильные схемы событий. На практике ценность дают интеграции с SIEM/SOAR (чтобы детекты и контекст уходили в единый центр реагирования), подключение дополнительных лог‑источников (облако, сетевые устройства, IAM), а также связка с ITSM (чтобы инцидент превращался в тикет с владельцем, SLA и историей изменений).
Важно, чтобы интеграция была не «экспортом ради экспорта», а поддерживала двусторонние сценарии: обогащение (подтянули CMDB/инвентаризацию), оркестрацию (запустили плейбук), контроль выполнения (закрыли инцидент после подтверждения).
Партнёрские приложения и маркетплейс расширяют набор use‑case без роста ядра команды: отраслевые правила, специфичные отчёты, интеграции с нишевыми системами. Чем проще партнёру получить доступ к событиям и контексту — тем быстрее платформа обрастает «длинным хвостом» сценариев.
Интеграции добавляют риски: разное качество данных, несовпадение идентификаторов сущностей, ответственность при ошибках и регулярная поддержка версий API/коннекторов. Чем больше связей, тем важнее валидация схем, мониторинг пайплайнов и прозрачная политика совместимости.
Смотрите на измеримые признаки: сколько реально поддерживаемых use‑case (не в презентации), каков time‑to‑value (время до первого полезного результата), удержание (retention) и доля клиентов, которые развивают интеграции спустя 3–6 месяцев. Если экосистема помогает быстрее внедрять новые сценарии и снижает стоимость изменений — платформа действительно становится стандартом.
Платформа телеметрии ценна ровно до тех пор, пока ей доверяют. Как только у клиента возникает ощущение «чёрного ящика», любые преимущества аналитики меркнут. Поэтому конфиденциальность и соответствие требованиям — не юридическое приложение к продукту, а часть архитектуры и операционной модели.
Ключевой принцип — собирать минимально достаточный набор для целей защиты. Для endpoint‑телеметрии это означает: не «всё подряд», а конкретные классы событий и атрибутов, которые помогают находить атаки и расследовать инциденты.
Практически это выражается в настройках: какие источники включены, какая детализация допустима, какие поля маскируются или исключаются, и как долго данные хранятся. Чем прозрачнее эти переключатели и политики, тем проще клиенту согласовать внедрение с безопасниками и юристами.
Внутри платформы важно строго разделять доступы: роли для SOC‑аналитиков, администраторов, аудиторов, плюс принцип наименьших привилегий. Не менее важны аудиторские журналы — кто и когда просматривал данные, менял правила, экспортировал результаты.
Это решает две задачи: снижает риск инсайдерских злоупотреблений и облегчает проверку соответствия (например, при внутреннем аудите или расследовании инцидента).
У клиентов часто есть обязательства по месту хранения данных, трансграничной передаче и срокам ретенции. «Облачная аналитика» должна уметь жить в этих рамках: поддерживать региональность, настраиваемые сроки хранения, юридически корректные механизмы передачи и удаления.
Хорошая практика — понятные материалы: какие данные собираются, зачем, как защищаются, кто имеет доступ и какие есть опции управления. Это снижает трение на старте проекта и помогает выстроить доверие к модели «телеметрия → облачная аналитика → детекты».
Модель «телеметрия → облачная аналитика → детекты» сильна, пока соблюдается баланс между объёмом данных, качеством обработки и возможностью клиента управлять результатом. Ниже — типовые точки, где платформа данных может начать работать хуже ожиданий.
Соблазн собирать «всё и всегда» приводит к двум проблемам. Первая — рост стоимости: трафик, хранение, обработка, лицензирование и косвенные расходы на администрирование. Вторая — шум: когда сигнал тонет в массе низкоценных событий, аналитике сложнее выделять аномалии, а командам SOC — реагировать приоритезированно.
Практический риск для бизнеса — платить за объём, который не даёт пропорционального роста детектов, и при этом ухудшать время реакции из‑за перегруженных очередей и интерфейсов.
Если ключевая аналитика выполняется в облаке, то качество защиты становится зависимым от доступности сервиса и каналов связи. Возможны задержки доставки событий (latency), «окна слепоты» при деградации сети, а также ограничения в изолированных сегментах.
Даже при хорошей архитектуре неизбежны вопросы к RTO/RPO, планам на инциденты у провайдера и режимам работы при частичной недоступности: что происходит с детектами, расследованиями и политиками на endpoint, если облако временно недоступно.
Данные со временем меняются: обновляются ОС и приложения, появляются новые паттерны поведения, меняются привычки пользователей. Это дрейф данных — он снижает точность моделей и «устаревает» правила.
Дополнительно есть adversarial‑техники: злоумышленники подстраиваются под детекты, имитируют легитимную активность, дробят действия на мелкие шаги или используют «жизнь за счёт встроенных средств» (LOLBins), чтобы выглядеть привычно.
Даже хорошие детекты могут создать перегруз, если алертов много, контекста мало, а настройка политик требует постоянного внимания. Риск — выгорание аналитиков, рост MTTR и пропуск реальных атак из‑за «усталости от уведомлений».
Критично заранее оценивать: сколько алертов будет приходить на типичный парк устройств, какие есть механизмы подавления шума, насколько прозрачны причины срабатываний и сколько ручной работы требуется для поддержания качества на дистанции.
Проверять «платформенность» endpoint‑решения лучше не по числу модулей в прайсе, а по тому, как оно обращается с данными: что собирает, как нормализует, насколько прозрачно объясняет выводы и насколько удобно масштабируется в эксплуатации.
Единая модель событий: телеметрия приводится к понятным типам (процессы, сеть, файлы, учётные записи), есть стабильные поля и версии схемы.
Связность контекста: можно быстро ответить «кто инициировал», «на какой машине», «какой родительский процесс», «какие последующие действия».
Облачная аналитика “по умолчанию”: обновления детектов и корреляций приходят без тяжёлых апгрейдов на стороне заказчика.
Прозрачные детекты: для каждого срабатывания видно, какие сигналы использованы, какие артефакты подтянулись, какие допущения сделаны.
Поиск и ретроспектива: есть быстрый «охотничий» поиск по событиям и ретроспективный анализ (что происходило до/после), а не только алерты.
API и экспорт: понятные API, контроль лимитов, документированные поля, удобный экспорт в SIEM/SOAR и хранилища.
Управление стоимостью данных: механизмы фильтрации/семплирования, классы хранения, прогнозирование объёмов.
Сведите результаты к нескольким метрикам, чтобы сравнение было честным:
Подход «данные и конвейер важнее отдельных функций» хорошо виден и в разработке ПО. Например, в TakProsto.AI (vibe‑coding платформа для российского рынка) скорость и качество результата зависят не только от интерфейса чата, но и от того, насколько выстроены процессы: планирование, итерации, снимки и откат (rollback), экспорт исходников, развертывание и хостинг. По сути, это тот же принцип платформы: стабильный «конвейер» превращает поток входных требований в предсказуемый продукт.
Отдельно для российских компаний внятная «локальность» (серверы в России, использование локализованных и открытых моделей, отсутствие передачи данных за рубеж) становится таким же архитектурным требованием, как ретеншн, контроль доступа и аудит — ровно те вещи, о которых вы думаете при выборе платформы телеметрии в ИБ.
Телеметрия + облачная аналитика меняют рынок ИБ, потому что качество защиты начинает зависеть от качества данных и скорости их превращения в понятные действия. «Платформенность» — это не витрина модулей, а способность стабильно собирать нужную телеметрию, связывать контекст, прозрачно детектировать и удобно встраиваться в ваши процессы через API и интеграции.
Это переход от «инструмента на конечной точке» к модели, где ключевая ценность — непрерывный поток телеметрии и облачный слой, который превращает её в:
Функции становятся «модулями» над одной и той же базой данных и идентичностей.
Потому что endpoint — место, где сходятся процессы, файлы, сеть и действия пользователя. Это даёт:
Наиболее прикладные категории обычно такие:
Максимальную ценность дают не отдельные события, а связанная цепочка из нескольких типов сигналов.
Больше событий не равно лучше. Смотрите на три вещи:
Если хотя бы один пункт слабый, вы либо пропускаете атаки, либо получаете слишком много шума.
Нормализация приводит события разных ОС и источников к общей схеме полей и типов, например:
device_id, user, process_name, parent_process;Практический эффект: одно правило или модель можно применять шире, а расследования становятся быстрее, потому что данные «говорят на одном языке».
Ключевые практики на стороне агента:
На стороне доставки важны повторы при ошибках, отправка пачками и приоритизация критичных событий, чтобы не возникали «окна слепоты».
Идентификация нужна, чтобы события не превращались в шум. Обычно закрепляют:
Это помогает не «склеивать» разные машины в одну сущность и не дробить один endpoint на десятки сущностей из-за смены сети.
Потому что «отправлять всё» дорого и часто бесполезно. Типовая компромиссная схема:
Критерий качества баланса: по данным должно быть возможно не только поднять алерт, но и быстро объяснить причинно-следственную цепочку.
В реальном времени ловят то, где важны секунды:
Пакетные расчёты (раз в час/день) применяют для тяжёлой аналитики:
На практике сильная платформа сочетает оба режима.
Проверяйте по измеримым признакам на пилоте:
И фиксируйте метрики: FP на 1000 узлов, MTTA/MTTR по сценариям, часы на triage и настройку исключений, плюс общий TCO.