Разбираем, как Datadog эволюционирует от мониторинга к платформе: единая телеметрия, интеграции и встроенные workflows для команд DevOps и SRE.
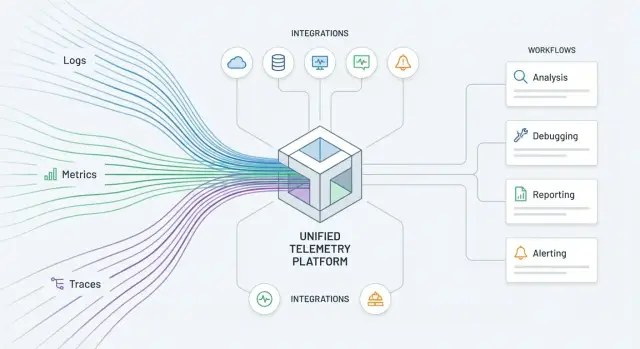
Раньше «мониторинг» часто означал набор разрозненных экранов: графики по инфраструктуре, отдельный APM, где-то ещё логи, а инциденты — в чате. Это работало, пока системы были относительно простыми. Но когда сервисов десятки, а релизы происходят постоянно, ценность смещается: важно не столько «увидеть график», сколько быстро понять причину и выполнить нужное действие.
Набор инструментов отвечает на вопрос «что происходит?» — но в разных местах и разными способами.
Платформа наблюдаемости (вроде Datadog) делает три вещи одновременно:
Именно связность и возможность действовать превращают наблюдаемость в платформу, а не в «зоопарк».
График сам по себе редко решает проблему. Решает её цепочка: сигнал → объяснение → решение. Поэтому «продуктом» становятся:
Когда эти элементы живут в одной системе и не требуют ручной «склейки», команды начинают воспринимать обсервабилити как рабочую среду, а не витрину.
Дальше разберём практические критерии: как оценить, вы строите платформу или коллекцию инструментов, какие интеграции дают максимальный эффект, как управлять стоимостью и шумом, и как выстраивать workflows так, чтобы наблюдаемость приводила к конкретным решениям. Если хотите сразу перейти к практической части — смотрите раздел про /blog/plan-vnedreniya-datadog.
Мониторинг обычно отвечает на вопрос «что сломалось?»: красный график, превышен порог, сервис недоступен. Обсервабилити отвечает на более практичный вопрос: «почему это произошло и что делать дальше?» Разница не в модном термине, а в том, как быстро команда переходит от сигнала к конкретному решению.
В основе — метрики, логи и трассировки. В мониторинге их часто собирают разрозненно: метрики живут в одной системе, логи — в другой, трассы — «когда-нибудь подключим». Из-за этого возникает знакомый сценарий: алерт пришёл по CPU, инженер уходит в логи, потом пытается вручную сопоставить это с конкретным запросом и релизом.
В обсервабилити эти три источника должны «склеиваться» вокруг одного контекста: конкретного сервиса, эндпоинта, версии, пользователя, региона. Тогда Datadog становится не витриной графиков, а местом, где путь от симптома до причины сокращается за счёт связей между сигналами.
Когда у команд разные инструменты и разные определения «нормы», появляется несколько источников правды:
В итоге спорят не о причине инцидента, а о данных. Цена такой задержки — время: пока вы ищете первопричину, сервис продолжает деградировать. Часто восстановление (mitigation) возможно быстрее, чем идеальный RCA, но без единого контекста даже временное решение находится медленно.
Обсервабилити — это переход от пассивного «наблюдаем» к активному «управляем»: алерт не просто сообщает, что стало плохо, а помогает выбрать действие. Хорошая практика — строить сигналы вокруг пользовательского опыта (латентность, ошибки, насыщение) и привязывать их к понятным шагам: кто отвечает, что проверить, как откатить, где посмотреть связанный лог/трейс.
Так система наблюдаемости становится операционным инструментом, а не набором разрозненных датчиков.
Когда вы выбираете Datadog, вы на самом деле «покупаете» не только интерфейс и красивые графики. Главная ценность — телеметрия, которая постоянно поступает в систему и помогает отвечать на вопросы о работе сервиса. Если относиться к ней как к побочному эффекту мониторинга, быстро появляются слепые зоны, спорные цифры и лишние расходы.
«Телеметрия как продукт» означает, что у данных есть владелец, требования к качеству и понятные правила потребления.
Сбор — это не просто поставить агент. Важно, чтобы данные были полными (покрывали ключевые компоненты), регулярными (без провалов) и сопоставимыми между командами.
Качество — это корректные таймстемпы, понятные единицы измерения, отсутствие дублей и предсказуемая задержка доставки. Иначе алерты «прыгают», а расследование инцидента превращается в угадывание.
Контекст — это то, что делает метрику или лог полезными: к какому сервису относится, в каком окружении случилось, какая версия была развёрнута, какой пользовательский путь затронут.
Доступность — это возможность быстро находить и использовать данные: единые названия, стабильные теги, понятные права доступа и отсутствие сюрпризов в стоимости запросов.
Чтобы данные «склеивались», договоритесь о словаре. Что такое service — приложение, микросервис или команда? Что считается environment: prod/stage или отдельные регионы? Как обозначаете version: git sha, semver, номер релиза?
Хорошая практика — закрепить эти определения и следить, чтобы они одинаково попадали в метрики, логи и трейсы. В Datadog это часто реализуют через стандартизированные теги и атрибуты, которые команда воспринимает как контракт.
Связность строится вокруг нескольких обязательных полей: service, env, version, region/zone, team, а для запросов — request_id/trace_id. Тогда вы можете провалиться из алерта по SLO в конкретные трейсы и тут же увидеть связанные логи без ручного «сопоставления по времени».
Если отправлять всё подряд, вы получите шум: тысячи малозначимых сигналов, которые скрывают важные.
Кардинальность (слишком много уникальных значений тегов, например user_id или полный URL) быстро увеличивает стоимость хранения и усложняет запросы.
Отдельный риск — приватность: персональные данные и секреты не должны попадать в логи и атрибуты. Нужны фильтры, маскирование и понятные правила, что разрешено отправлять в телеметрию, а что — нет.
Главная ценность единой модели данных в Datadog — корреляция. Она превращает «сработал алерт» в цепочку ответов: какой сервис деградировал, какой endpoint или конкретный запрос дал всплеск, какие логи подтвердят причину, и что изменилось в релизе за последние 30–60 минут. Без этой связности обсервабилити остаётся набором разрозненных экранов.
Когда метрика, трейс и лог описывают одну и ту же реальность одинаковыми идентификаторами (сервис, окружение, версия, хост/контейнер), Datadog может «проваливать» вас по контексту: от графика latency к медленным trace-спанам и дальше к логам именно того запроса.
Допустим, алерт по росту p95 latency на API в prod. Дальше рабочий путь выглядит так:
Открываете график и видите, что проблема локализуется на одном сервисе и конкретном ресурсе (endpoint).
Переходите в APM и находите трейсы с аномальной длительностью: например, узкое место в запросе к базе или внешнем API.
По тому же trace_id/корреляционным тегам открываете логи запроса и видите конкретную ошибку (таймаут, ретраи, лимиты) и параметры, которые её воспроизводят.
Сверяете временную точку с деплоем и понимаете, связано ли ухудшение с изменениями кода или конфигурации.
Единая модель данных позволяет строить сервисные карты и dependency-графы, где видно не только «что упало», но и «кого потянуло за собой». Отдельно полезна привязка к релизам: вклад версий в ошибки и задержки становится наблюдаемым, а не предметом догадок.
Чтобы корреляция работала стабильно, договоритесь о стандартах:
Эти базовые правила обычно дают больший эффект, чем добавление ещё одного дашборда.
Интеграции — это то, что превращает Datadog из «ещё одной панели с графиками» в платформу, которую реально удобно разворачивать и масштабировать. Когда новые команды, сервисы и инфраструктурные компоненты подключаются за часы, а не за недели, вы получаете не только видимость, но и охват: меньше слепых зон, быстрее поиск причин, легче стандартизация.
Один идеально сделанный дашборд не решает проблему, если половина критичных систем не шлёт телеметрию, а метки (теги) не совпадают. Хорошая интеграция сразу даёт «скелет» наблюдаемости: правильные метрики/логи/трейсы, базовые дашборды, типовые алерты и общую схему тегирования. Это снижает порог входа для команд и делает данные сопоставимыми между сервисами.
На практике ценность быстрее всего дают интеграции с:
Важно не количество подключений, а то, насколько они закрывают ключевые точки отказа и цепочки зависимостей.
Частая ошибка — ставить «по агенту на каждую задачу» или тянуть одни и те же метрики из двух систем. Итог: разные названия показателей, несовпадающие теги, двойная стоимость хранения и море шума в алертах. Лучше заранее определить один основной путь сбора (агент/интеграция/шлюз), а всё остальное подключать только при явной пользе.
Перед тем как считать интеграцию «готовой», проверьте четыре вещи: поддерживаются ли единые теги (service/env/region/team), есть ли автодашборды, есть ли рекомендованные алерты, и можно ли связать данные с остальными сигналами (например, метрики с логами по одинаковым тегам). Тогда интеграции действительно умножают ценность платформы, а не добавляют ещё один источник разрозненных данных.
Когда обсервабилити становится платформой, «данные» перестают быть побочным продуктом мониторинга. Их нужно сознательно формировать: снижать шум, контролировать стоимость и обеспечивать правильный доступ. Иначе вы быстро получите дорогую свалку логов и метрик, где трудно найти причину инцидента.
Практика, которая окупается почти сразу — настроить обработку на входе. В Datadog это обычно делается через пайплайны:
Важно: правила лучше делать «по умолчанию безопасными» — проще разрешить нужное, чем потом вычищать лишнее.
Главный скрытый драйвер стоимости — кардинальность (количество уникальных комбинаций тегов). Один невинный тег вроде user_id в метриках может «взорвать» объём.
Полезный подход: заранее определить бюджет телеметрии по командам/сервисам (что собираем, с какой частотой, какие теги разрешены) и закрепить это в стандартах. Для метрик — ограничивайте высококардинальные теги, для логов — используйте семплирование там, где допустимо.
Не все данные должны жить одинаково долго. Обычно лучше хранить:
Платформа наблюдаемости — это ещё и система контроля. Разделяйте доступ по окружениям (prod/dev), по командам и по типам данных. Это снижает риск утечек, упрощает аудит и помогает не «раздавать всем всё», сохраняя при этом удобство работы инженеров и SRE.
Обсервабилити становится платформой в тот момент, когда она помогает не только «увидеть проблему», но и провести вас по цепочке «заметил → понял → сделал». Workflows — это встроенные сценарии действий, которые соединяют сигналы (алерты, аномалии, события деплоя) с конкретными шагами реагирования. Тогда наблюдаемость перестаёт быть витриной графиков и превращается в операционный инструмент.
Сильный workflow начинается с контекста: алерт сразу показывает, какой сервис затронут, что поменялось (релиз, конфиг, рост нагрузки), какие зависимости могли повлиять и какие симптомы уже видны в метриках/логах/трейсах. Следующий шаг — действие, причём максимально близко к месту, где человек уже работает.
Типовые примеры, которые хорошо «приземляются» в платформе наблюдаемости:
Когда повторяющиеся действия автоматизированы, уменьшается время на «поиск входа» в инцидент: меньше ручных переключений между инструментами, меньше ошибок от усталости, быстрее первые осмысленные шаги. Итог — снижение MTTR не за счёт героизма, а за счёт процесса.
Workflows не «чинят» хаос сами по себе. Нужны чёткое владение сервисом (owner), правила эскалации, критерии критичности и договорённости: какие алерты считаются actionable, какие — информационные, кто обновляет runbook после инцидента. Без этой дисциплины автоматизация лишь ускорит шум, а не восстановление.
Наблюдаемость становится управляемой, когда сигналы приводят к решению: «что делать и кому». В Datadog это обычно сводится к трём опорам — алерты, SLO и дашборды — и к дисциплине их настройки.
Главный источник шума — алерты, которые ловят «всё подряд» и не отвечают на вопрос, есть ли реальная проблема для пользователя.
Практика: сначала ставьте алерты на симптомы (и/или на SLO burn rate), а «причины» держите как диагностические сигналы в дашборде и в привязанных runbook.
SLI — измерение (например, доля успешных запросов), SLO — цель (например, 99.9% успешных запросов за 30 дней). Когда SLO согласованы, разговор «плохо/хорошо» превращается в управление риском.
В Datadog удобно вести SLO на основе метрик и использовать их для:
Один и тот же сервис нужен разным людям по‑разному:
Для ключевого user journey определите SLI (успех/латентность) и цель SLO.
Создайте 2–3 алерта на симптомы: 5xx, p95 latency, отказ критической транзакции.
Добавьте алерт на burn rate SLO (короткое и длинное окно).
В дашборд диагностики включите «причины»: saturation, ошибки зависимостей, очереди, БД.
Для каждого алерта прикрепите краткий runbook: что проверить в первую минуту и как эскалировать.
Инцидент-менеджмент — это не «что-то сломалось, починили». Если обсервабилити становится платформой, то инцидент превращается в управляемый процесс с понятными входами (сигналы), выходами (восстановление сервиса) и измеримой эффективностью. В Datadog это особенно заметно, когда мониторинги, логи и трейсы не живут отдельно, а поддерживают единый сценарий работы команды.
Предсказуемость появляется, когда у инцидента есть стандартные этапы:
Важно: если шаги повторяемы, их можно улучшать — если каждый раз импровизация, улучшать нечего.
Runbook (плейбук) нужен не для «новичков», а чтобы даже опытные инженеры не тратили время на вспоминание. Хорошая практика — привязывать runbook прямо к сигналу: в тексте алерта указывать ссылку на плейбук, владельца сервиса, ожидаемый эффект и первый безопасный шаг.
Runbook становится частью платформы, когда в нём есть:
Постмортем — это не «поиск виноватого», а настройка системы на будущее. Помимо технических метрик, полезно собирать метрики процесса: MTTD/MTTR, долю ложных алертов, количество эскалаций, время до первого обновления статуса, процент выполненных action items и частоту повторных инцидентов по той же причине.
«Героизм» выглядит эффективно, но делает результат случайным. Помогают роли (инцидент-командир, коммуникации, технический лидер), смены и стандарты качества сигналов. Цель — чтобы инцидент решался не «тем самым человеком», а предсказуемо любой дежурной командой по понятным правилам.
Если обсервабилити включается только «когда уже горит», вы теряете половину ценности. Платформенный подход в Datadog проявляется тогда, когда телеметрия сопровождает фичу от первого теста до реального трафика — и помогает принимать решения о качестве релиза, а не просто фиксировать симптомы.
Начните с того, чтобы в dev/stage окружениях были те же базовые сигналы, что и в production: метрики сервисов, логи, трейсы, ошибки. Это позволяет ловить проблемы раньше, но без «шума» продакшена.
Практика, которая хорошо работает: одинаковые теги (service, env, version) во всех средах и минимальный набор дашбордов «здоровья» на каждую команду. Тогда графики и трейсы сравнимы, а регрессии видны сразу.
Связывайте деплой с телеметрией: version и git SHA в трейсы/метрики, событие деплоя на таймлайне, а также привязка к фичефлагам (через интеграции). После выката можно быстро ответить на вопросы:
Комбинация APM и RUM позволяет связать «медленно на сервере» с «плохо у пользователя»: например, рост TTFB в браузере можно подтвердить ростом времени в конкретном span в бэкенде. Это превращает оптимизацию в управляемый процесс: выбираете топ-страницы/сценарии, находите узкое место, проверяете эффект после релиза.
Когда Datadog подключён к CI/CD (например, через CI Visibility, синтетические тесты или API), обсервабилити становится частью релизных «гейтов». Типовые критерии: SLO-ошибки, рост p95 latency, всплеск Error Tracking, ухудшение ключевых RUM-метрик. Если порог превышен — автоматический стоп релиза или откат по заранее согласованному правилу.
Если вы быстро запускаете новые сервисы (в том числе через vibe-coding, когда приложение собирается из диалога, а не вручную через долгий цикл разработки), требования к «телеметрии по умолчанию» становятся ещё жёстче: единые теги, базовые SLO и стандартные пайплайны логов нужны сразу, иначе скорость релизов превращается в скорость накопления хаоса.
В этом смысле TakProsto.AI удобно использовать как точку стандартизации: вы создаёте веб/серверные/мобильные приложения через чат, а затем фиксируете в шаблонах проекта обязательные поля (service/env/version/team), типовые алерты и базовые интеграции. При этом важно, что платформа ориентирована на российский рынок: данные и инфраструктура остаются в России, что упрощает требования по хранению и доступу к телеметрии.
Самая частая ошибка при старте с Datadog — пытаться «подключить всё» за неделю. В итоге команда тонет в алертах, тегах и полуготовых дашбордах, а ценность для бизнеса не появляется. Гораздо эффективнее — идти как с продуктом: короткими итерациями, с измеримыми результатами.
Цель первых 30–60 дней — не идеальная наблюдаемость, а работающий базовый контур.
Что обычно стоит внедрить в первую очередь:
Выберите 3–5 сервисов, которые реально определяют опыт клиента: авторизация, оплата, поиск, оформление заказа — зависит от продукта. Хороший критерий: если этот компонент падает, вы теряете деньги или доверие.
Далее зафиксируйте 2–3 критичных пользовательских пути и стройте наблюдаемость вокруг них: метрики успеха (конверсия/успешные запросы), задержки, доля ошибок. Так Datadog становится инструментом управления продуктом, а не только «графиками для инженеров».
Без стандартов вы быстро получите «зоопарк»: разные названия одного и того же, невозможность фильтровать и сравнивать.
Минимальный набор стандартов:
Зафиксируйте это в коротком гиде и добавьте в чек-лист релиза.
Чтобы не спорить на уровне ощущений, договоритесь о метриках прогресса:
Если через 60 дней MTTR снижается, а команда реже «вслепую» ищет причину — вы внедряете платформу, а не очередной инструмент.
Платформа наблюдаемости — это не «ещё один интерфейс для графиков», а единый способ видеть систему, договариваться о качестве и быстро выполнять действия. Проверить, в какую сторону вы движетесь, можно по практическим признакам.
Если наблюдаемость стала платформой, это заметно не по числу интеграций, а по снижению трения в ежедневной работе:
Чаще всего деградация начинается с трёх установок:
Чтобы понять, потянет ли система роль платформы, задайте себе (и вендору) несколько вопросов:
Начните с аудита текущей телеметрии (что действительно используется в инцидентах, а что лежит мёртвым грузом), затем сделайте пилот на одном сервисе: минимальный набор SLO, алертов с действиями, единые теги и короткий runbook. Если после пилота время диагностики и число «пустых» срабатываний заметно снизились — вы строите платформу, а не коллекцию инструментов.
Платформа связывает метрики, логи и трассировки в один контекст (service/env/version/region) и ведёт от сигнала к действию.
У «набора инструментов» обычно:
Потому что график редко отвечает на вопрос «что делать дальше». Ценность появляется, когда данные:
Начните со словаря и «контракта» тегов.
Минимальный обязательный набор:
serviceenv (prod/stage и т.п.)versionregion/zoneСамые частые причины:
trace_id/span_id в логах;version не проставляется при деплое;Проверка: от алерта по latency вы должны за 1–2 клика открыть связанные трейсы и логи запроса.
Кардинальность — это слишком много уникальных значений тегов (например, user_id, полный URL, случайные параметры).
Практика:
Так вы снижаете стоимость и сохраняете запросы быстрыми.
Настройте обработку «на входе», чтобы не платить за мусор и не плодить риск.
Обычно достаточно трёх шагов:
Правило: безопасные настройки по умолчанию, точечные исключения — осознанно.
Делайте алерты в два слоя:
Хороший старт — алерты на симптомы + burn rate по SLO, а причины привязать ссылками в описание алерта.
SLO — общий язык продукта и инженеров: вы управляете не «страшными графиками», а бюджетом ошибок.
Практичные применения:
Потому что цель — сократить путь «заметил → понял → сделал».
Полезные элементы workflow:
Без дисциплины владения и критериев actionable-алертов автоматизация лишь ускорит шум.
Идите итерациями, а не «подключить всё сразу».
Типовой план:
Если нужна опора на шаги, используйте практический раздел: /blog/plan-vnedreniya-datadog.
team/ownerИ добейтесь, чтобы те же значения попадали и в метрики, и в логи, и в трейсы — тогда корреляция будет работать стабильно.