Разбираем идеи Джеффри Ульмана: реляционная алгебра, переписывание запросов, оценка стоимости, планы выполнения и связь с компиляторами и масштабированием.
Имя Джеффри Ульмана чаще звучит в контексте учебников и университетских курсов, но его идеи давно «живут» внутри промышленных СУБД. Когда вы пишете обычный SQL‑запрос, а система вдруг выполняет его за миллисекунды (или, наоборот, неожиданно медленно), за кулисами работает набор принципов, которые Ульман помог сформулировать: как представлять запрос формально, как преобразовывать его, как оценивать варианты исполнения и выбирать лучший.
Ульман — один из ключевых авторов классической теории баз данных и формальных моделей запросов. Его вклад заметен не в «фичах интерфейса», а в основе: в том, как СУБД приводит ваш запрос к плану выполнения. Оптимизатор не «угадывает» решение — он опирается на строгие правила эквивалентности, математические модели и алгоритмы, которые можно проверять, улучшать и переносить между системами.
Под теорией здесь понимаются не абстракции ради абстракций, а язык точных гарантий:
Эта база делает оптимизацию предсказуемой: она объясняет, почему индексы помогают не всегда, почему порядок соединений меняет всё и почему небольшое переписывание запроса иногда даёт кратный выигрыш.
Дальше разберём, как СУБД «понимает» SQL через реляционную алгебру, как работает переписывание запросов, как строится модель стоимости и выбирается план выполнения, почему соединения — главный источник сложности и как эти идеи продолжают работать при масштабировании от одного сервера к распределённым системам.
Реляционная модель — это договор о том, как мы описываем данные и как задаём вопросы к ним. Данные представлены в виде таблиц (отношений): каждая строка — это запись (кортеж), а каждый атрибут — столбец с конкретным смыслом (например, customer_id, status, created_at). Важно, что модель говорит о значениях и связях, а не о том, как именно они лежат на диске.
SQL выглядит как язык для людей, но внутри СУБД стремится перевести его в более строгую форму — набор операций, похожих на конструктор: выборка (σ), проекция (π), соединение (⨝), группировка и т.д. Это и есть реляционная алгебра — «язык смысла» запроса.
Например, запрос «взять активных клиентов и их заказы за декабрь» на уровне смысла — это:
status = 'active';customer_id;Ключевая идея Ульмана (и всей школы оптимизации): логический запрос описывает что нужно получить, а физическое выполнение — как это сделать.
Два выражения могут быть эквивалентны по смыслу, но радикально отличаться по скорости. Причина простая: порядок операций меняет объём промежуточных данных.
Если сначала соединить две большие таблицы, а фильтр применить потом, СУБД может «таскать» миллионы лишних строк. Если же фильтр протолкнуть раньше, соединение станет меньше и дешевле. Формально результат тот же — но путь к нему разный. Именно на этом различии и строится оптимизация запросов.
SQL выглядит простым: вы описываете, какие строки хотите получить, а не как именно их доставать. Это и есть ключ к оптимизации: между вашим SELECT ... и реальным чтением данных лежит слой «понимания» запроса.
Когда вы пишете SQL, вы задаёте условия (фильтры), нужные поля и связи между таблицами. Но вы не выбираете порядок действий: сначала соединять таблицы или сначала отфильтровать, какой индекс использовать, где делать сортировку. Эти решения принимает оптимизатор.
Чтобы принимать их не на глазок, СУБД переводит SQL в более строгую форму — обычно в представление, близкое к реляционной алгебре.
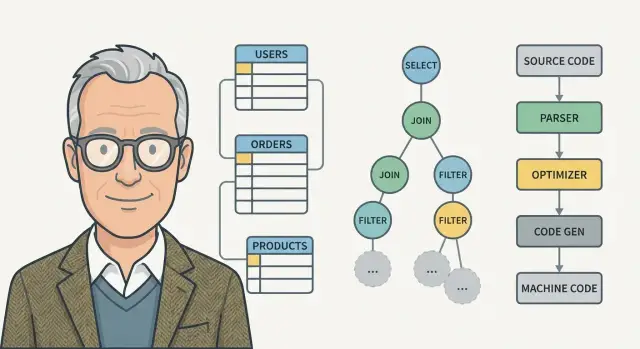
Реляционная алгебра — это набор операций над отношениями (таблицами), из которых можно собрать запрос как выражение. На практике это выражение хранится как дерево:
WHERE);SELECT без агрегатов);JOIN ... ON).Например, запрос «взять имена клиентов, у которых есть заказы за декабрь» можно представить как цепочку: сначала соединение клиентов с заказами, затем фильтр по дате, затем проекция по имени. Важно, что это логическое дерево: оно описывает смысл, но ещё не говорит, каким алгоритмом всё будет выполнено.
Как только запрос стал деревом, оптимизатор может безопасно менять его форму:
Два запроса эквивалентны, если при любых данных они возвращают один и тот же результат (с учётом оговорок про порядок строк, NULL и т. п.). Оптимизация на базе алгебры как раз про это: мы меняем выражение, но сохраняем смысл.
Именно поэтому идеи, популяризованные Ульманом, так практичны: алгебра задаёт «правила игры», позволяя ускорять запросы без изменения того, что пользователь попросил в SQL.
Переписывание запросов — это набор формальных преобразований, которые меняют форму запроса, но сохраняют его смысл. Идея проста: прежде чем считать стоимость планов, полезно привести запрос к виду, где «лишняя работа» отсекается заранее. Это улучшает результат даже без знания конкретных индексов и железа.
Самое практичное правило: применять условия WHERE как можно раньше — до соединений и агрегаций.
Если отфильтровать таблицу до JOIN, то промежуточных строк становится меньше, а значит дешевле и сортировки, и хеш-таблицы, и чтение с диска. В терминах реляционной алгебры это перемещение операции selection ближе к источнику данных.
Соединения можно переупорядочивать, не меняя результат (для внутреннего INNER JOIN). Это не «хитрость оптимизатора», а свойство операции.
A ⋈ B эквивалентно B ⋈ A(A ⋈ B) ⋈ C эквивалентно A ⋈ (B ⋈ C)Переписывание на этом уровне позволяет подставить «маленькие» таблицы или уже отфильтрованные наборы раньше, резко сокращая объём промежуточных данных.
Проекция (выбор нужных колонок) тоже выгодна как можно раньше. Если запросу в итоге нужны 3 поля, нет смысла тащить 30 колонок через все этапы соединений и группировок.
Аналогично с вычислениями: выражения, которые можно не считать на миллионах строк (или можно посчитать после фильтра), лучше отложить.
Иногда подзапрос выгодно материализовать: один раз посчитать результат и переиспользовать, особенно если он используется многократно или сильно сокращает данные.
Но материализация может навредить, если «замораживает» большой промежуточный набор, который мог бы быть оптимизирован дальше (например, фильтры не протолкнулись внутрь).
Переписывания уменьшают пространство вариантов для оптимизатора и улучшают входные данные для оценки стоимости: меньше строк, меньше «ширина» строк, проще статистика. Уже затем оптимизатор выбирает индексы, методы соединений и конкретный план выполнения — но делает это на существенно более удобной формулировке запроса.
Оптимизатор запросов почти никогда не «угадывает» лучший план на глаз. Он сравнивает альтернативы с помощью модели стоимости — приближённой оценки того, сколько ресурсов потратит каждый вариант.
Интуитивно хочется выбрать план с меньшим числом шагов. Но один «шаг» может означать совсем разное: от чтения пары страниц из памяти до полного сканирования таблицы на диске и большой сортировки. План с большим числом операций иногда выигрывает, если он лучше использует индексы, избегает сортировки или сокращает промежуточные результаты.
Обычно оптимизатор считает несколько компонентов:
В разных СУБД веса компонентов отличаются, но логика одна: оценить «сколько данных будет прочитано и обработано».
Ключевые числа в оценках — селективность (какая доля строк пройдёт фильтр) и кардинальность (сколько строк получится на каждом этапе). От них зависит выбор: использовать индекс или сканирование, какой алгоритм соединения применить, когда выполнять фильтры.
Чтобы не гадать, СУБД хранит статистику: число строк, распределения значений, частоты. Гистограммы помогают понять, что значения распределены неравномерно (например, один регион встречается в 80% строк), и точнее оценить селективность.
Типовые источники промахов:
Эти ошибки важны: неверная кардинальность на раннем шаге способна увести оптимизатор к плану, который формально «дешевле» на бумаге, но медленнее в реальности.
Когда в запросе несколько таблиц, СУБД почти всегда тратит больше всего «интеллектуальных усилий» на выбор порядка соединений (join order). Формально результат соединения ассоциативен: можно соединять A с B, а потом с C — или сначала B с C. Но по затратам эти варианты могут отличаться в разы, потому что промежуточные результаты бывают либо маленькими и «дешёвыми», либо огромными и дорогими по памяти и вводу‑выводу.
Join order — это последовательность, в которой оптимизатор строит цепочку соединений. Важность в том, что каждое раннее решение влияет на размер следующих шагов: удачный первый join резко уменьшает число строк, а неудачный может «раздуть» результат, и дальше любой алгоритм соединения будет страдать.
Классический подход из учебников Ульмана: рассматривать не «один план целиком», а лучший план для каждого подмножества таблиц. СУБД как бы собирает решение снизу вверх: нашла лучший способ соединить (A,B), лучший для (B,C), затем пробует расширять эти кусочки третьей таблицей и выбирает минимальную стоимость. Это даёт качество, близкое к оптимальному, но дорого при большом числе таблиц.
Если таблиц много, оптимизатор часто включает эвристики: раньше применять самые селективные фильтры, предпочитать соединения, которые быстро уменьшают данные, ограничивать число рассматриваемых альтернатив, использовать «жадные» стратегии. Цена — иногда план не лучший, зато время оптимизации остаётся разумным.
Ключи и внешние ключи помогают не только проверять целостность, но и оптимизировать:
Чем лучше СУБД знает ограничения и статистику, тем меньше «слепых» вариантов join order ей приходится перебрать.
Оптимизатор не просто «выбирает порядок таблиц», он выбирает конкретные алгоритмы, которыми движок будет читать строки, сопоставлять ключи, сортировать и считать агрегаты. Эти решения напрямую влияют на время ответа и нагрузку на диск/память.
Nested loop join уместен, когда внешняя таблица маленькая, а по внутренней есть хороший индекс по ключу соединения: тогда для каждой строки делается быстрый точечный поиск. Если индекса нет или внешняя сторона велика, nested loop быстро превращается в «миллионы мелких обращений» и тормозит.
Hash join обычно выигрывает на больших объёмах при равенстве ключей. СУБД строит хеш-таблицу по одной стороне (build), затем пробегает вторую (probe). Важно, помещается ли хеш-таблица в память: при нехватке памяти появятся разбиения/сбросы на диск.
Sort-merge join хорош, когда данные уже отсортированы (например, благодаря индексу) или сортировка всё равно нужна дальше по плану. Он устойчив на больших наборах, но может быть дорогим из‑за сортировки.
Индекс ускоряет не только WHERE, но и соединения (по ключу) и иногда ORDER BY — если порядок совпадает. Агрегаты и GROUP BY могут выполняться как Hash Aggregate (быстро, если помещается в память) или Group Aggregate после сортировки (дороже, но иногда неизбежно).
Выбор алгоритма завязан на оценку кардинальности: сколько строк пройдет фильтр, сколько совпадений даст join, насколько «раздуются» промежуточные результаты. Ошибка в оценках часто приводит к неправильному выбору (например, nested loop вместо hash join).
Смотрите не на «красоту SQL», а на фактические узлы плана и расхождения оценок с реальностью:
Seq Scan) и можно ли сузить их предикатом;Sort/Hash и признаки spill на диск;Идея Ульмана, которая особенно хорошо «цепляется» у тех, кто хоть раз видел устройство компилятора: SQL‑запрос — это не просто строка, а программа над данными. СУБД проходит похожий путь: от текста к структуре, от структуры к оптимизированному «исполняемому плану».
Сначала движок разбивает текст на токены (лексинг), затем строит синтаксическое дерево (парсинг) и проверяет семантику: существуют ли таблицы и поля, совместимы ли типы, корректны ли агрегаты.
Дальше дерево обычно преобразуется в более удобную внутреннюю форму — логический план (аналог AST/IR в компиляторах). В этой форме видно, какие операции нужны: фильтрации, проекции, соединения, группировки.
Как и в компиляторах, оптимизация — это серия проходов над представлением программы:
Важный момент: многие «умные» ускорения получаются не за счёт магии, а за счёт систематических правил, похожих на компиляторные преобразования.
Компилятор выдаёт машинный код, а СУБД — план выполнения: последовательность операторов (сканирование, соединение, сортировка и т. п.) с конкретными методами доступа (например, через индекс). Это тоже своего рода «код», только исполняемый интерпретатором запросов или JIT‑модулем.
Оптимизатор может гарантировать корректность преобразований (эквивалентность результата), но не может гарантировать идеальную скорость всегда. Причины практические: неполная статистика, корреляции в данных, параметризованные запросы, конкуренция за ресурсы. Поэтому оптимизация — это поиск лучшего плана по модели, а не абсолютное доказательство оптимальности в реальном времени.
Оптимизация запроса почти всегда упирается не в «скорость CPU», а в то, как часто СУБД вынуждена ходить на диск и сколько данных тащит через память. Идеи Ульмана полезны тем, что учат мыслить планом выполнения как потоком данных с ограниченными ресурсами.
Операция может выглядеть дорогой на бумаге, но оказаться дешёвой, если нужные страницы уже в буферном пуле. И наоборот: запрос «вдруг» тормозит после роста таблицы, потому что рабочий набор перестал помещаться в память, и чтения превратились в постоянные вытеснения страниц. Поэтому реальная стоимость — это не только количество строк, но и вероятность попадания в кэш.
Скан таблицы часто выигрывает у «умного» плана, если он читает данные последовательно большими блоками. Случайные чтения (например, по индексу с множеством обращений к разным страницам) могут стать узким местом, особенно на холодном кэше. Отсюда практическое правило: индексы полезны, но при низкой селективности и большом объёме выборки они иногда хуже полного скана.
Пайплайнинг передаёт строки дальше по конвейеру без записи промежуточных результатов — это экономит ввод‑вывод и ускоряет ответ.
Материализация сохраняет промежуточный набор (в памяти или на диск): она помогает переиспользовать результат, отсортировать, дедуплицировать, но может «раздуть» потребление памяти и вызвать spill на диск.
Пользователь влияет на план сильнее, чем кажется:
JOIN и DISTINCT).Если коротко: хороший план — это план, который минимизирует дорогие обращения к данным и держит промежуточные результаты под контролем.
Когда база данных перестаёт помещаться на одном сервере, меняется не только железо — меняется сама цена ошибок в плане выполнения. Идеи, которые Ульман формулировал для оптимизации запросов на одной машине (модель стоимости, эквивалентные преобразования, выбор порядка соединений), остаются верными, но «стоимость» начинает определять сеть и пересылка данных.
Партиционирование (делим таблицу на части по ключу/диапазону) и шардинг (раскладываем части по разным узлам) — это по сути продолжение реляционной модели на несколько хранилищ. Для оптимизатора важно понимать: где лежат строки, какие фрагменты нужны запросу и можно ли выполнить операции локально.
На одном сервере соединение — это «почитать два набора данных и сопоставить». В кластере часто появляется третий шаг: переместить данные так, чтобы их вообще можно было сопоставить. Пересылка миллионов строк по сети легко оказывается дороже, чем сортировки и хеш-таблицы вместе взятые. Поэтому выбор порядка соединений и ключей распределения становится критичным: удачное решение превращает распределённое соединение в набор локальных.
Одна из самых практичных идей — «проталкивать» фильтры, проекции и частичные агрегации туда, где данные находятся. Чем меньше строк и столбцов уедет по сети, тем дешевле план. Это прямое продолжение классических правил переписывания запросов, только выигрыш теперь измеряется не только в CPU, но и в мегабайтах трафика.
Модель стоимости добавляет новые компоненты: задержки сети, пропускную способность, перекосы данных (skew), возможные повторные выполнения при сбоях. «Простая» теория помогает задавать правильные вопросы: какие операции можно сделать локально, где появится обмен данными и какой компромисс между временем ответа и стоимостью ресурсов вы выбираете.
Теория Ульмана ценна тем, что переводится в простые действия: уменьшить объём данных как можно раньше, выбрать удачный порядок соединений и понимать, какой алгоритм стоит за операцией. Ниже — несколько типовых кейсов, которые часто дают заметный прирост без «героизма».
Если запрос сначала «раздувает» промежуточный результат, а фильтрует в конце, СУБД тратит время на лишние чтения (а в распределённых системах — ещё и на лишнюю пересылку строк).
Практика: переносить условия из WHERE как можно ближе к чтению таблицы и выбирать только нужные столбцы — особенно перед JOIN и GROUP BY.
Реляционная алгебра разрешает переупорядочивать соединения (ассоциативность/коммутативность), и результат будет тем же. Но стоимость — разная.
Практика: сначала соединять/фильтровать «самые селективные» таблицы (те, что сильнее уменьшают количество строк), а уже потом подтягивать большие справочники. Иногда достаточно уточнить предикат, чтобы оптимизатор увидел селективность; иногда — обновить статистику.
Группировка может выполняться через сортировку (Sort + Group) или через хеширование (Hash Aggregate). Хэш обычно выигрывает на больших объёмах без подходящего порядка, а сортировка может быть быстрее, если данные уже идут в нужной последовательности (например, по индексу) или если требуется упорядоченная выдача.
Оптимизатор выбирает план по оценкам. Если статистика устарела или распределение данных «нестандартное», он может ошибиться. Поэтому один и тот же совет может ускорить запрос в тесте и замедлить в проде: проверяйте изменения через план выполнения и реальные метрики.
Ульман ценен не «формулами ради формул», а тем, что даёт понятную рамку: запрос — это выражение, у которого есть смысл (семантика), много эквивалентных форм и разные способы выполнения с разной ценой. Если держать в голове эту тройку, оптимизация перестаёт быть гаданием.
Во‑первых, реляционная алгебра: она объясняет, почему СУБД может переставлять операции (например, проталкивать фильтры ближе к данным) и всё равно получать тот же результат.
Во‑вторых, эквивалентность преобразований: оптимизатор не «ускоряет запрос», а ищет другую, равнозначную форму, которая лучше исполняется.
В‑третьих, стоимость и планы выполнения: СУБД выбирает не «самый умный», а «самый дешёвый по модели» план. Отсюда главный практический вывод: модель ошибается, когда ошибаются оценки кардинальности.
Сделайте привычкой начинать не с переписывания SQL, а с проверки плана:
EXPLAIN/EXPLAIN ANALYZE и фиксируйте, где тратится время: join, сортировка, чтение с диска, агрегация;Часто самые ощутимые улучшения дают простые действия: убрать ненужный JOIN, добавить явный предикат, изменить порядок вычислений через подзапрос/CTE (с учётом особенностей вашей СУБД), добавить подходящий индекс или обновить статистику.
Если вы делаете продукт, где база данных — часть типового стека (например, backend на Go и PostgreSQL), удобно закладывать эти проверки прямо в процесс разработки. В TakProsto.AI, где приложения собираются через чат в режиме vibe‑coding и можно быстро получать рабочие инкременты, особенно полезно фиксировать требования к запросам и нагрузке в planning mode, а затем безопасно проверять изменения схемы и индексов с помощью snapshots и rollback.
Дальше полезно чередовать теорию и «железо» конкретной СУБД: документацию по оптимизатору, статистике и типам join, а также материалы по внутреннему устройству исполнителя. Хорошая цель — уметь объяснить любой узел плана человеческими словами.
Возьмите 10–20 самых частых или самых дорогих запросов из логов и проведите мини‑аудит: план, кардинальности, узкие места, гипотезы, изменения, повторное измерение. Это самый быстрый способ превратить идеи Ульмана в измеримое ускорение.
Джеффри Ульман помог сформулировать строгий подход к тому, как СУБД преобразует SQL в исполняемый план: через формальные модели (реляционная алгебра), правила эквивалентности и алгоритмы поиска лучшего плана.
Практический эффект: оптимизатор может ускорять запросы без изменения результата, системно сравнивая альтернативы по стоимости (I/O, CPU, память).
Реляционная алгебра — это внутренний «язык смысла», в который СУБД переводит SQL: выборка (фильтры), проекция (столбцы), соединения, группировки.
Она полезна тем, что даёт:
Потому что логически эквивалентные запросы могут требовать радикально разный объём работы.
Чаще всего скорость меняется из‑за:
JOIN);Переписывание (rewriting) — это преобразования, которые сохраняют смысл, но уменьшают «лишнюю работу» ещё до выбора индексов и алгоритмов.
Типовые действия:
INNER JOIN, если это безопасно.Join order — это последовательность, в которой СУБД соединяет таблицы. Он критичен, потому что ранние соединения формируют размер промежуточных наборов, а значит — стоимость всех следующих шагов.
Практика: старайтесь, чтобы самые селективные условия (сильно уменьшающие строки) применялись как можно раньше — через явные предикаты, корректные JOIN-условия и актуальную статистику.
Оптимизатор выбирает план по модели стоимости: приблизительно оценивает, сколько ресурсов потребует каждый вариант.
Обычно учитываются:
Вывод: «короткий план» не обязан быть быстрым — важнее, сколько данных реально прочитали и переработали.
Кардинальность — сколько строк ожидается на каждом этапе плана. От неё зависят:
JOIN (nested loop/hash/sort-merge);Если оценки кардинальности сильно ошибаются, оптимизатор часто выбирает неверную стратегию — поэтому так важны статистика и реалистичные условия фильтрации.
Частые причины:
Практический шаг: если показывает сильный разрыв между и , начните с обновления статистики и проверки предикатов.
Смотрите на узлы, которые дают максимум времени/строк, и на расхождения оценок.
Мини‑чек‑лист:
Sort/Hash и признаки spill на диск;В распределённых системах к стоимости добавляется сеть: пересылка данных часто дороже локальных вычислений.
Поэтому особенно важны:
JOIN становился локальным;Идея та же, что и на одном сервере: , но теперь это ещё и трафик.
EXPLAIN ANALYZEJOIN;Дальше действуйте точечно: индекс, переписывание предиката, обновление статистики, упрощение JOIN-цепочки.