Разбираем ранние решения Kubernetes при участии Джо Беды: почему появились поды, контроллеры и декларативный подход, и как это влияет на платформы сегодня.
Джо Беда — один из сооснователей Kubernetes и человек, который помог превратить внутренние практики Google по управлению большими парками сервисов в открытый проект. Позже он продолжил развивать экосистему: участвовал в создании Heptio (компания, сфокусированная на внедрении Kubernetes), а затем работал над продуктами вокруг облачных платформ и контейнерной инфраструктуры.
Его вклад важен не потому, что он «придумал контейнеры», а потому что вместе с командой зафиксировал принципы, сделавшие Kubernetes понятным, расширяемым и применимым в реальных компаниях.
Контейнеры удобно запускать «по одному», но в жизни их десятки и сотни: разные версии, разные окружения, разные нагрузки. Оркестрация контейнеров — это способ автоматически:
Идея в том, чтобы команда управляла не каждым запуском вручную, а правилами и ожиданиями.
Многие ключевые вещи были заложены в первые годы проекта: как описывать «что должно работать», как система проверяет реальность и исправляет отклонения, что считать минимальной единицей размещения и как приложения находят друг друга в кластере.
Эти решения пережили смену облаков, дистрибутивов и «модных» инструментов — потому что они про операционную надёжность и повторяемость, а не про конкретного вендора.
Вы разберётесь, какие архитектурные выборы сделали Kubernetes стандартом де-факто для запуска приложений в кластере — без погружения в программирование и внутренности кода. Станет ясно, почему «магия» Kubernetes на самом деле состоит из нескольких простых идей, аккуратно соединённых в систему, которой можно доверять в продакшене.
До появления Kubernetes контейнеры уже помогали упаковывать приложение «как есть» и переносить его между серверами. Но на практике команды быстро упирались в то, что запуск контейнера — это только начало истории.
Дальше начинается эксплуатация: где именно он должен работать, как переживать сбои, как обновляться без простоя и как масштабироваться под нагрузку.
Типичная картина: у каждой команды — свой набор инструкций, свой формат конфигов и свой «правильный» способ выкатывать релиз. В одном сервисе обновление делали через SSH и пару команд, в другом — через CI-скрипты, в третьем — через самописный веб-интерфейс.
Когда нагрузка росла, масштабирование часто превращалось в ручную операцию: поднять ещё пару экземпляров, добавить их в балансировщик, проверить доступность, потом не забыть откатить назад. Всё это занимало время и зависело от конкретных людей, которые «знают как». В итоге скорость релизов падала, а риск ошибок рос.
Скрипты и runbook’и хорошо работают, пока система небольшая и изменения редкие. Но с ростом числа сервисов появляется комбинаторика: разные версии, разные окружения, разные зависимости.
Скрипты начинают ветвиться, обрастать исключениями и «магическими» таймингами. Runbook’и устаревают быстрее, чем их успевают обновлять, а ночные инциденты превращаются в чтение инструкций под давлением.
Контейнер отвечает на вопрос «как упаковать и запустить», но не отвечает на вопросы:
Без общего механизма управления команды всё равно собирают систему из отдельных деталей — и получают хрупкую конструкцию.
Нужна была единая платформа для приложений, которая:
Именно эти практические боли и ожидания сделали оркестрацию не «приятным дополнением», а необходимостью.
Один из самых сильных ранних ходов Kubernetes — отказаться от управления «по шагам» в пользу описания результата.
Команда не говорит кластеру как именно запустить приложение. Она фиксирует каким оно должно быть в стабильном состоянии: сколько экземпляров нужно, какие порты открыть, какие ресурсы выделить, по каким меткам группировать.
Императивный стиль звучит как чек‑лист: «запусти контейнер», «добавь ещё два», «перенеси на другой узел», «перезапусти».
Декларативный — как договор: «я хочу 3 экземпляра этого приложения; если один упадёт — верни снова до трёх». Kubernetes берёт на себя механику выполнения и последующее поддержание.
Декларативный подход хорошо ложится на командную работу:
В результате снижается число ошибок класса «не то запустили», «вчера было 5, сегодня случайно стало 2», «на одном узле обновили, на другом забыли».
Вместо того чтобы вручную отслеживать текущее количество реплик и добавлять недостающие, вы задаёте цель:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 3
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: web
image: example/web:1.2.3
Если одна реплика исчезнет (сбой узла, падение процесса, эвакуация), система будет стремиться вернуть их снова к трём — без просьб «запусти ещё».
Именно эта ориентация на результат позже стала фундаментом self-healing и автоскейлинга. Но началось всё с простого и смелого решения: управлять целью, а не шагами.
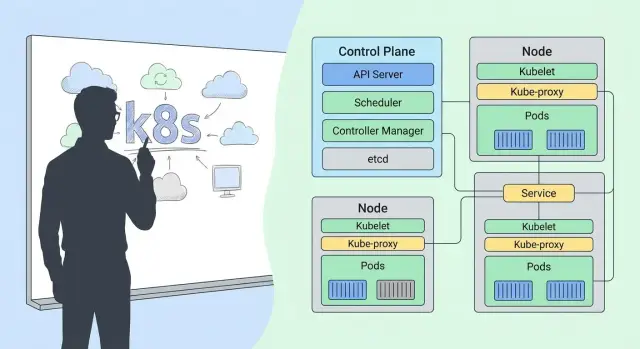
Pod — базовая «единица размещения» в Kubernetes. Важно: pod — не синоним контейнера. Контейнер — это упаковка приложения, а pod — «маленькая группа», которую планировщик размещает на конкретной машине (node) как одно целое.
Ранний Kubernetes сделал ставку на то, что иногда одному приложению нужен не один контейнер, а несколько, стоящих плечом к плечу.
Поэтому внутри одного pod контейнеры считаются неразделимыми: их вместе запускают, вместе переносят и (в случае проблем) вместе пересоздают.
Такой подход упрощает реальную жизнь: вместо того чтобы организовывать сложные связи между «соседними» контейнерами по сети, Kubernetes говорит: если им нужно быть рядом — пусть будут рядом по определению.
Контейнеры внутри pod:
Это означает, что один контейнер может, например, писать файлы логов в общий том, а другой — читать их и отправлять во внешнюю систему. Или один контейнер поднимает приложение, а второй обслуживает сертификаты и кладёт их в общий каталог.
Pod сделал естественными шаблоны вроде sidecar — «контейнера‑спутника», который дополняет основное приложение:
Главная ценность: команда описывает такую связку один раз, и Kubernetes дальше воспринимает её как единый объект размещения — без ручной склейки и хрупких договорённостей между компонентами.
Kubernetes задуман так, чтобы вы описывали «как должно быть», а не вручную подстраивали «как есть». Но одно дело — записать желаемое состояние в манифесте, другое — постоянно поддерживать его в живом кластере, где узлы могут падать, контейнеры — завершаться, а обновления — выкатываться.
Эту работу и берут на себя контроллеры.
Контроллер — это автоматический «наблюдатель и исполнитель». Он смотрит на текущее состояние объектов в кластере и сравнивает его с тем, что вы задали (например: «должно быть 3 экземпляра приложения»). Если есть расхождение, контроллер предпринимает действия, чтобы вернуть систему к ожиданиям.
Важно, что это не разовая проверка. Kubernetes исходит из того, что сбои нормальны, поэтому постоянно перепроверяет реальность.
Если объяснять без терминов из программирования:
На практике чаще всего команда работает именно с Deployment, а ReplicaSet остаётся «механикой под капотом».
Основа поведения контроллеров — цикл согласования (reconciliation loop):
прочитать желаемое состояние из API (что вы указали в YAML/через команды),
прочитать текущее состояние кластера,
вычислить разницу,
выполнить действия (создать/удалить/обновить объекты),
повторять снова.
Этот подход делает систему устойчивой: если действие не удалось с первого раза (временная проблема с узлом, сетью, ресурсами), контроллер продолжит попытки, пока не добьётся нужного результата.
Когда поддержание «как задумано» становится непрерывной автоматикой, у команды меньше ночных ручных операций: кластер сам поднимает замену упавшим экземплярам, доводит количество реплик до нужного и удерживает приложение в рабочем состоянии.
По сути, Kubernetes превращает эксплуатацию из серии разовых тушений пожаров в управляемый процесс, где отклонения — временное явление, а не повод для паники.
Кластер Kubernetes не «запускает контейнеры где придётся». За то, чтобы каждый pod оказался на подходящем узле, отвечает планировщик (Scheduler). Его работа кажется незаметной, пока всё хорошо, но именно она делает кластер предсказуемым: приложения получают ресурсы, не мешают друг другу и переживают сбои отдельных машин.
Когда вы описываете pod (или, чаще, Deployment), вы не указываете конкретный сервер. Вы задаёте требования, а Scheduler подбирает node.
Это важно, потому что в реальной эксплуатации узлы постоянно меняются: часть уходит на обновления, часть перегружается, часть выходит из строя. Если привязываться к конкретным хостам, оркестрация быстро превращается в ручное администрирование.
Планировщик учитывает несколько групп сигналов:
В итоге размещение становится не случайностью, а результатом формализованных правил, которые можно обсуждать и менять вместе с командой.
Вторая часть истории — как Kubernetes связывает компоненты без жёстких привязок.
Labels — это простые пары ключ‑значение (например, app=payments, tier=backend). Selectors — запросы, которые выбирают объекты по этим меткам.
Так Service «находит» нужные pods по селектору, а контроллер ReplicaSet понимает, какие pods считать «своими». Ни IP, ни имена машин, ни список экземпляров не нужно фиксировать вручную.
Метки и селекторы позволяют переименовывать, переносить, масштабировать и обновлять приложение, не ломая связи.
Вы меняете состав pods — а Service продолжает маршрутизировать трафик на «всех, у кого есть нужная метка». Это и есть практическая модульность Kubernetes: слабая связность между частями системы при строгих правилах выбора.
Контейнеры и pod в Kubernetes «живут» динамично: они пересоздаются, переезжают на другие ноды, получают новые IP. Если каждому клиенту нужно знать актуальный адрес каждого pod, система быстро разваливается.
Поэтому Kubernetes вводит Service — стабильную точку доступа к набору pod, которые могут постоянно меняться.
Service даёт постоянное имя и виртуальный IP (ClusterIP) для группы pod, выбранных по label‑селекторам. Приложение внутри кластера обращается к my-service, а не к конкретным pod.
Это отделяет сетевой контракт (куда ходить) от реализации (какие именно экземпляры сейчас живы).
Когда вы создаёте Service, Kubernetes формирует список «конечных точек» — Endpoints (или EndpointSlice) — то есть IP и порты pod, которые подходят под селектор и готовы принимать трафик.
Дальше трафик распределяется между ними на сетевом уровне (через правила kube-proxy или eBPF‑реализацию, в зависимости от настройки кластера).
Обнаружение сервисов (service discovery) решается через DNS: обычно достаточно обратиться к имени my-service (или my-service.my-namespace). Для команд это критично: можно менять количество реплик, выкатывать обновления, чинить аварии — а адрес для клиентов остаётся прежним.
Service в первую очередь про внутреннюю стабильность. А когда нужен доступ извне — появляется Ingress.
Он описывает правила маршрутизации HTTP/HTTPS: на какой Service отправлять запросы по домену и пути, как завершать TLS, как делать виртуальные хосты.
Важно: Ingress — это не «сам по себе балансировщик», а декларация. Реальную работу выполняет Ingress Controller, установленный в кластере.
Представьте, что у вас есть web Deployment и web Service. Вы выкатываете новую версию: старые pod постепенно удаляются, новые создаются с другими IP.
Service автоматически обновляет список Endpoints — и пользователи, которые приходят через Ingress на тот же домен, продолжают работать без смены адресов и ручных правок.
Один из самых практичных ранних выборов Kubernetes — не «запекать» настройки внутрь образа контейнера. Образ должен описывать приложение и его зависимости, а параметры окружения — жить отдельно.
Так один и тот же образ можно безопасно и предсказуемо запускать в dev/stage/prod, меняя только конфигурацию.
Если конфигурация лежит в образе, любая мелочь (URL сервиса, фичефлаг, таймаут) требует пересборки, повторного теста, перезаливки в registry и нового деплоя.
Отделение настроек ускоряет цикл изменений и снижает риск: приложение остаётся тем же, меняется лишь «обвязка».
Дополнительный плюс — единый подход для разных команд: платформа предоставляет правила хранения и доставки настроек, а приложение умеет читать их из стандартных источников (переменных окружения или файлов).
ConfigMap подходит для несекретных данных: конфиги, параметры, адреса, уровни логирования, значения фичефлагов. Его удобно подключать в Pod как переменные окружения или как файлы.
Secret предназначен для чувствительных данных: токены, пароли, ключи, сертификаты. Но важно помнить: Secret — не «магическое шифрование по умолчанию». Риски зависят от настроек кластера: кто имеет доступ к API, включено ли шифрование в etcd, как настроено логирование и бэкапы.
Поэтому Secrets требуют дисциплины доступа и хранения.
Когда параметры вынесены в ConfigMap/Secret, изменения применяются отдельно от релиза кода. Это позволяет:
Минимизируйте права: выдавайте доступ к Secret только тем ServiceAccount, которым он нужен (RBAC по принципу least privilege).
Настройте ротацию: короткоживущие токены, регулярная смена паролей/ключей, понятный процесс перевыпуска и отзыва.
И, по возможности, включайте шифрование Secrets в etcd и контролируйте, где эти данные могут «утечь» (логи, дампы, бэкапы).
Одна из ключевых идей Kubernetes — не «управлять вручную», а получать предсказуемое поведение кластера по умолчанию. Если что-то ломается или нагрузка меняется, система старается вернуть сервис к заявленному состоянию.
Self-healing в Kubernetes — это не магия, а набор автоматических действий:
Важно: Kubernetes не «чинит приложение», он чинит инфраструктурную часть — наличие и размещение экземпляров.
Чтобы отличать «процесс жив» от «сервис реально готов», используются две простые концепции:
Смысл для команды: даже если приложение запускается долго или временно перегружено, readiness позволяет не ломать пользовательские запросы, убирая pod из обслуживания без остановки всего деплоя.
Масштабирование бывает двух типов:
Практическое правило: сначала масштабируют приложение, а когда упираются в ресурсы — масштабируют кластер.
Автоматизация не бесплатна. Больше реплик и запас по ресурсам повышают стабильность, но увеличивают стоимость. Реакция на пик нагрузки тоже не мгновенная: нужно время на запуск новых pod’ов, а иногда и на добавление нод.
И ещё: всё упирается в лимиты и запросы ресурсов. Если они выставлены неверно, автоскейлинг либо не сработает вовремя, либо будет «раздувать» инфраструктуру без реальной пользы.
Ранний Kubernetes задумали не как «готовую платформу на все случаи», а как набор базовых примитивов и механизмов, которые можно наращивать. Это сильно повлияло на то, какими стали современные облачные платформы и внутренние платформы компаний.
У разных организаций разные ограничения: безопасность, сеть, хранение, требования к релизам, регуляторика. Если оркестратор жёстко «вшивает» единственно правильные решения, он быстро перестаёт подходить части пользователей.
Поэтому в Kubernetes ключевым стало разделение: ядро задаёт общие правила (желаемое состояние, контроллеры, планирование), а детали реализуются расширениями — через API, плагины и дополнительные контроллеры.
Концептуально CRD (Custom Resource Definitions) — это возможность сказать кластеру: «у нас есть свой тип ресурса». Например, не только Deployment или Service, но и условный Database или Queue.
Оператор — это контроллер, который понимает этот новый ресурс и приводит реальность к желаемому состоянию: создаёт нужные поды, настраивает доступ, следит за обновлениями и восстановлением. По сути, команды получили способ «упаковать» эксплуатационные знания в механизм, который работает по тем же правилам, что и остальной кластер.
Так появился рынок платформенных продуктов и внутренних платформ: от сервис-мешей и систем хранения до решений для CI/CD, управления секретами и политиками. Многие инструменты не заменяют Kubernetes, а строятся поверх него, используя единый API и привычные паттерны.
Kubernetes оправдан, когда нужна масштабируемость, отказоустойчивость, много сервисов и команд, гибкая интеграция и единые стандарты запуска.
Если же у вас одно‑два приложения, нет требований к сложной сетевой модели и автоматизации, часто быстрее и дешевле выбрать более простой вариант: управляемый PaaS, контейнерный сервис без полного Kubernetes или даже классический деплой на VM.
Ранние решения Kubernetes (к которым приложил руку Джо Беда) ценны тем, что они задают «правила игры»: платформа должна быть предсказуемой, автоматизируемой и управляемой через намерения, а не через ручные действия. Если держать это в голове, внедрение Kubernetes становится намного практичнее.
Отдельно стоит помнить, что сама оркестрация — лишь часть конвейера. Часто параллельно приходится быстро собирать внутренние сервисы: панели для инженеров, бэкенд‑утилиты, интеграции с каталогом сервисов, генераторы манифестов, небольшие API для автоматизации. В таких задачах удобно использовать TakProsto.AI — платформу vibe-coding для российского рынка, где веб/серверные/мобильные приложения можно собирать через чат, а затем экспортировать исходники и деплоить. Так команды быстрее закрывают «обвязку» вокруг Kubernetes, не превращая это в отдельный долгий проект, и при этом могут оставаться в российском контуре (модели и серверы локализованы, данные не отправляются за рубеж).
Декларативное управление и API‑ориентированный подход: описываем, что нужно получить, а не как вручную сделать.
Pod как базовая единица размещения: рядом живущие контейнеры — это одна «капсула» для сети и жизненного цикла.
Контроллеры + цикл согласования: кластер постоянно сравнивает желаемое и фактическое и исправляет отклонения.
Labels/селекторы: простая «таксономия» для связи объектов и автоматизации.
Service (и дальше Ingress/шлюзы): стабильная точка доступа при постоянных пересозданиях pod’ов.
Ресурсы (requests/limits) и планировщик: размещение с учётом CPU/памяти — основа предсказуемости.
Встроенные механики self-healing и масштабирования как поведение «по умолчанию», а не как отдельный проект.
Если часть инфраструктурных инструментов вокруг кластера пока отсутствует (например, внутренний каталог сервисов, формы для безопасных релизов, генерация шаблонов деплоя), их можно быстро прототипировать на TakProsto.AI: собрать веб‑интерфейс на React, бэкенд на Go с PostgreSQL, добавить планирование, снапшоты и откат — и затем при необходимости забрать код в свой репозиторий.
Самая частая — пытаться управлять всем вручную (перезапускать pod’ы, «чинить» руками) вместо правки деклараций.
Вторая — игнорировать requests/limits: без них планировщик работает вслепую, а команда получает нестабильность и спорные инциденты.
Сеть (Service, Ingress/Gateway, NetworkPolicy), безопасность (RBAC, секреты, политики), наблюдаемость (Prometheus‑экосистема, централизованные логи) и GitOps‑подход (см. /blog/gitops-basics).
Оркестрация контейнеров — это набор механизмов, которые автоматически:
Практический критерий: если вам нужно масштабирование, обновления без простоя и восстановление после падений без ручных действий — вам нужна оркестрация, а не «просто контейнеры».
Потому что ранние решения зафиксировали базовые принципы эксплуатации:
Эти идеи слабо зависят от облака и инструментов вокруг — они про повторяемость и надёжность в продакшене.
Декларативный подход — это когда вы задаёте «как должно быть» (например, replicas: 3), а кластер сам приводит фактическое состояние к желаемому.
Практика:
Pod — это не «контейнер», а минимальная единица, которую планировщик размещает на конкретной ноде.
Внутри pod контейнеры:
Используйте несколько контейнеров в одном pod, когда им нужно быть рядом и общаться локально (например, приложение + sidecar для логов/прокси/сертификатов).
Контроллеры постоянно сравнивают желаемое и текущее состояние и делают шаги, чтобы устранить разницу. Это называется reconciliation loop.
Пример:
Практический совет: если вы видите «дрейф» (реплик меньше, чем нужно) — сначала смотрите события/статус Deployment и ReplicaSet, а не пытайтесь вручную пересоздавать pod’ы.
Scheduler выбирает ноду для pod’а, опираясь на правила и ограничения:
Практика:
Labels — метки ключ=значение на объектах (pod, Deployment и т.д.). Selectors — правила выбора по этим меткам.
Это «клей» для связей:
Практика: договоритесь о стандарте меток (например, , , , ) — это упрощает маршрутизацию, мониторинг и политики безопасности.
Pod’ы динамичны: пересоздаются и меняют IP. Service даёт стабильное имя и виртуальный IP для группы pod’ов по селектору.
Снаружи обычно используют Ingress (или альтернативные шлюзы): он задаёт правила HTTP/HTTPS-маршрутизации на Service, а реальную работу делает установленный Ingress Controller.
Практика:
ConfigMap хранит несекретные параметры, Secret — чувствительные данные (токены, пароли, ключи). Их подключают в pod как переменные окружения или файлы.
Важно:
Практика:
Self-healing — это автоматическое поддержание работоспособности инфраструктурной части:
Автоскейлинг бывает:
appcomponentenvversionmy-serviceПрактика: настройте readiness/liveness и корректные requests/limits — без них self-healing и скейлинг работают хуже и менее предсказуемо.