Разбираем идею хранимой программы фон Неймана: хранение инструкций в памяти сделало возможны компиляторы, ОС и универсальные компьютеры — и где её пределы.
Главный поворот, о котором пойдёт речь, звучит почти буднично: программа стала такими же данными, как числа, и начала храниться в общей памяти компьютера. Раньше «что делать машине» часто задавалось проводами, переключателями, перфокартами или отдельными блоками логики. После появления идеи хранимой программы инструкции стало можно записать в память, изменить, скопировать, передать и выполнить — без переделки самой машины.
Когда инструкции и данные живут в одном месте и представлены в одном «языке» для железа, компьютер превращается из устройства «под задачу» в универсальную платформу. Сегодня это кажется очевидным: один и тот же ноутбук запускает браузер, редактор, игру и бухгалтерию. Но исторически это был переломный момент: стало возможно быстро переключаться между задачами, создавать библиотеки, компиляторы и операционные системы, а позже — обновлять программы так же легко, как заменять файл.
Есть и второе важное следствие: если программа — это данные, то программы могут работать с программами. Отсюда растут автоматизация, компиляция, интерпретация, загрузчики, а также привычная нам разработка, где изменения — это правка текста, а не перепайка схем.
Сначала посмотрим на вычислительные машины 1940-х и разберём, почему переход к хранимой программе был неочевидным. Затем простыми словами объясним сам принцип и роль Джона фон Неймана в его формализации и распространении. После этого пройдёмся по устройству компьютера (память, процессор, ввод-вывод) и по тому, как выполняется программа через цикл «выборка–декодирование–исполнение». В финале обсудим преимущества, ограничение в виде «узкого места фон Неймана» и способы, которыми индустрия научилась его обходить, а также соберём всё в наглядную простую модель.
Вычисления задолго до электронных ЭВМ были прежде всего организацией труда и механикой. В компаниях и госучреждениях работали табуляторы и сортировщики на перфокартах: данные «жили» на карточках с отверстиями, а сама обработка часто сводилась к последовательности операций вроде подсчёта, группировки и печати отчётов. Это уже было автоматизацией, но «алгоритм» понимался как заранее заданный маршрут прохождения карточек через устройства и набор фиксированных режимов.
Параллельно развивались релейные и ранние электронные машины для научных и военных задач. Они могли считать гораздо быстрее, но цена этой скорости — сложность управления. Чтобы заставить такую машину решать другую задачу, недостаточно было просто подготовить новый набор входных данных: требовалось менять сам способ работы системы.
Главная проблема ранних машин заключалась в том, что смена задачи требовала физической перенастройки. Это могло выглядеть по-разному:
Даже если вычисления занимали минуты, подготовка могла занимать часы или дни. В результате дорогая машина простаивала, а успех проекта зависел не только от математики, но и от того, насколько быстро команда могла «пересобрать» алгоритм в железе.
Пока алгоритм был привязан к проводам и панелям, развитие вычислительной техники тормозилось не столько скоростью счёта, сколько удобством постановки задачи. Любая новая идея означала новую схему, а значит — риск ошибок при сборке, долгие проверки и узкий круг специалистов, способных обслуживать систему. Нужно было решение, при котором алгоритм можно менять так же легко, как данные — без физического вмешательства в машину. Именно этот запрос и подготовил почву для принципа хранимой программы.
Идея хранимой программы — это простое правило организации компьютера: и инструкции, и данные лежат в одной и той же памяти. Процессор обращается к памяти и читает оттуда то, что ему нужно: иногда это числа для вычислений, а иногда — команды, что именно делать дальше.
Если говорить максимально приземлённо, программа — это последовательность “слов”, которые можно хранить, как обычные значения. Эти слова кодируют инструкции: например, «возьми число из ячейки 100», «сложи с числом из ячейки 101», «результат запиши в ячейку 102». Для человека это выглядит как текст на языке программирования, но для машины в конечном счёте это набор значений в памяти.
Отсюда важное следствие: программу можно загрузить в память так же, как данные. Не нужно перекраивать устройство под каждую задачу — достаточно положить в память другой набор команд.
Когда программа хранится как данные, появляются операции, которые раньше были либо невозможны, либо крайне неудобны:
Хранимая программа — это не «модель одного конкретного компьютера» и не бренд. Это принцип организации: как разделить роли памяти и процессора и как представить программу так, чтобы её можно было хранить, передавать и запускать на одном и том же устройстве. Именно эта простота открыла дорогу универсальным компьютерам и массовому программированию.
Джона фон Неймана часто связывают с принципом хранимой программы не потому, что он «в одиночку изобрёл» эту идею, а потому что он помог ей стать понятной, обсуждаемой и воспроизводимой в инженерной практике.
В середине 1940-х фон Нейман участвовал в работах вокруг проекта EDVAC и подготовил текст, который обычно называют First Draft of a Report on the EDVAC. Важность таких материалов — не в громком авторстве, а в том, что они:
Когда идея получает аккуратное описание, её проще повторить в других лабораториях и проектах. По сути, фон Нейман помог превратить набор инженерных решений и интуиций в переносимую модель, которую можно преподавать, обсуждать в отчётах, сравнивать и улучшать.
Важно помнить: это была коллективная работа. Вокруг EDVAC и других проектов работали сильные инженеры и исследователи, и похожие мысли развивались параллельно в разных местах. В те годы многие уже видели ограниченность «переключаемых» программ и искали путь к более универсальным машинам.
Фон Нейман здесь выступил как мощный «усилитель»: он формализовал и широко распространил схему, которая затем стала стандартной точкой отсчёта. Поэтому, говоря «архитектура фон Неймана», обычно имеют в виду не персональную монополию на изобретение, а удачную формулировку и популяризацию общих принципов, на которых выросла массовая вычислительная техника.
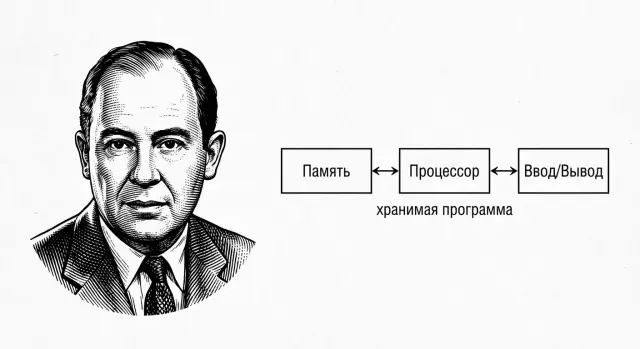
Архитектура фон Неймана — это понятная «сборка» компьютера из нескольких крупных блоков, которые вместе позволяют хранить программу в памяти и выполнять её шаг за шагом.
В классической схеме выделяют четыре части:
Между процессором (АЛУ+УУ) и памятью есть важный практический элемент — регистры. Это крошечные, очень быстрые «ячейки» внутри процессора.
Зачем они нужны:
Часто выделяют, например, счётчик команд (PC) — регистр с адресом следующей инструкции, и регистр(ы) для данных/результатов.
Ключевой механизм — адресация: каждая ячейка памяти имеет номер (адрес). Инструкция обычно содержит:
код операции (что сделать),
адрес(а), где взять данные и куда положить результат.
Из-за этого программа может не только считать числа, но и «ходить» по памяти: брать данные из разных мест, переходить к другим инструкциям, организовывать циклы и ветвления.
[Ввод/вывод]
|
v
+-------------------+
| Память | (ячейки с адресами)
| данные + команды |
+-------------------+
^ |
| v
+-------------------+
| Процессор |
| УУ <-> АЛУ |
| регистры (PC, ...)|
+-------------------+
Эта схема не описывает все современные детали, но хорошо показывает «скелет» компьютера, на котором выросли универсальные вычисления.
Чтобы компьютер с хранимой программой «понимал», что делать дальше, он работает по повторяющемуся шаблону: выборка (fetch) → декодирование (decode) → исполнение (execute). Это и есть базовый ритм работы процессора.
Процессор хранит специальное число — счётчик команд (PC, program counter). PC указывает адрес в памяти, где лежит следующая инструкция.
На шаге fetch процессор читает из памяти команду по адресу PC и обычно увеличивает PC (например, на 1), чтобы тот указывал на следующую команду.
PC критичен, потому что без него процессор не знал бы, какую инструкцию выполнять следующей, а значит не смог бы двигаться по программе — ни вперёд, ни «прыгать» по веткам.
Считанную команду нужно «разобрать»: что за операция (сложить, загрузить, перейти) и какие операнды у неё есть (адреса, регистры, константы). Это превращает набор битов в понятный для железа план действий.
На этом шаге процессор выполняет операцию: читает/пишет память, считает в арифметическом блоке, меняет регистры — и иногда меняет PC особым образом.
Допустим, в памяти лежит программа из 5 инструкций (условный псевдокод):
0: LOAD [10]1: ADD [11]2: STORE [12]3: JZ 5 (если результат равен нулю — перейти на адрес 5)4: JMP 0 (безусловный переход на 0)И данные: mem[10]=2, mem[11]=-2, mem[12]=0.
Ход выполнения:
PC=0 → fetch LOAD [10] → execute: в регистр попадает 2 → PC становится 1.
PC=1 → ADD [11] → execute: 2 + (-2) = 0 → PC становится 2.
PC=2 → STORE [12] → execute: mem[12] становится 0 → PC становится 3.
PC=3 → JZ 5 → execute: так как результат 0, PC устанавливается в 5, а не просто увеличивается.
Именно здесь «живут» условные переходы и циклы: команда перехода может изменить PC так, чтобы повторять участок (цикл через JMP 0) или выбирать ветку (через JZ 5).
До хранимой программы «программа» часто была не текстом и не файлом, а физической настройкой машины: переключатели, кабели, панели соединений. Это требовало времени, редких специалистов и делало каждую задачу почти отдельным проектом.
С хранимой программой всё перевернулось: инструкции стали храниться в той же памяти, что и данные. Значит, программу можно записать, скопировать, загрузить, исправить и запустить заново — так же, как таблицу чисел.
В современном смысле программирование — не «переподключить провода», а описать шаги алгоритма в виде инструкций, которые машина прочитает из памяти. Как только это описание стало переносимым (сначала на ленте и карте, затем в файле), появилась привычная нам практика: версионирование, исправления, повторные запуски, обмен программами между людьми и организациями.
Когда программа — это набор команд в памяти, её можно разбить на части и переиспользовать. Возникают:
Это резко снижает стоимость разработки: один раз написанное начинает работать на десятках проектов.
Хранимая программа сделала возможными инструменты, которые сами являются программами: ассемблеры (перевод мнемоник в машинный код), компиляторы и языки высокого уровня. Если инструкции можно хранить и обрабатывать как данные, то их можно автоматически преобразовывать, оптимизировать, проверять — и тем самым вовлечь в программирование больше людей, не заставляя каждого думать битами.
Раз инструкции лежат в памяти, компьютер может сначала выполнить небольшой загрузчик, который читает программу с внешнего носителя и размещает её в памяти. А дальше подключается линковка: отдельные модули и библиотеки «склеиваются» в один исполняемый образ, адреса и переходы настраиваются автоматически. Так возникла цепочка, без которой трудно представить современную разработку: исходник → сборка → линковка → запуск.
Главная практическая победа идеи хранимой программы — универсальность. Универсальный компьютер — это не «особо мощная машина», а устройство, которое может решать разные задачи, просто выполняя разные программы на одном и том же железе. Меняется содержимое памяти (инструкции и данные) — меняется поведение машины.
До универсальности вычислительные устройства часто делались «под функцию»: отдельная схема для расчётов, отдельная — для управления, отдельная — для обработки сигналов. С хранимой программой логика работы стала настраиваться софтом.
На одном и том же компьютере можно запускать целые классы задач:
Важно, что базовая «механика» для всего одна: процессор берёт инструкции из памяти, интерпретирует их и выполняет.
Когда у многих машин появляется похожая модель выполнения программ (память, процессор, команды, ввод-вывод), вокруг неё проще строить инструменты: компиляторы, библиотеки, отладчики, операционные системы. Разработчики начинают думать не о том, «как перепаять устройство под новую задачу», а о том, как написать и собрать программу.
Отсюда вырастает понятие совместимости: если два компьютера поддерживают одну и ту же архитектуру команд, то один и тот же исполняемый файл (или исходный код при наличии компилятора) можно перенести между ними. Полной переносимости «вообще везде» это не гарантирует, но внутри одной архитектуры и семейства систем перенос программ становится реальной, массовой практикой.
Архитектура фон Неймана дала компьютерам простоту и универсальность: и инструкции, и данные лежат в одной памяти и обычно идут к процессору по одной и той же «дороге» (шине/каналу доступа). Но у этой элегантности есть цена — то самое «узкое место фон Неймана».
Процессору нужно постоянно подвозить два типа «груза»:
Если и то и другое читается из одной и той же памяти через общий канал, возникает конкуренция. В каждый момент времени по этой «полосе движения» может проехать ограниченное число байтов. Когда запросов больше, чем пропускная способность, процессор вынужден простаивать.
Представьте кухню: повар (процессор) работает очень быстро, но продукты и рецепты хранятся в одном шкафу (память), а ключ от шкафа один (общая шина). Повар то и дело останавливается, чтобы сходить к шкафу: взял шаг рецепта, вернулся к столу; пошёл за ингредиентом, снова вернулся. Чем быстрее повар, тем заметнее, что его тормозит не умение готовить, а походы к шкафу.
С ростом частот и числа ядер процессоры научились выполнять больше операций за секунду, чем память успевает «кормить» их инструкциями и данными. Параллельно растут объёмы данных: изображения, видео, модели машинного обучения, большие базы. В результате разрыв между скоростью вычислений и скоростью доступа к памяти ощущается сильнее.
Фон-неймановская схема — не просчёт, а практичный выбор: единая память и единый механизм доступа упрощают устройство компьютера и делают его универсальным. Именно эта простота позволила масштабировать идею массово — а ограничения стали стимулом для дальнейших улучшений.
«Узкое место фон Неймана» обычно формулируют просто: процессору приходится по одному и тому же «коридору» таскать и инструкции, и данные. Если коридор узкий (медленная память, ограниченная шина), ядро простаивает.
Один очевидный обход — гарвардская архитектура: инструкции и данные хранятся отдельно и читаются по разным путям. Это снижает конкуренцию за пропускную способность: можно одновременно подтягивать следующую команду и обрабатывать данные.
Важно, что в массовых компьютерах «чистый Гарвард» встречается реже, но идея активно используется внутри: многие современные CPU внешне выглядят как классическая модель (одна память в адресном пространстве программы), но физически разделяют потоки.
Индустрия пошла по пути «расширить коридор», не ломая совместимость:
В результате современные процессоры часто сочетают подходы: логически они совместимы с архитектурой фон Неймана (программы пишутся «как обычно»), но физически используют элементы, похожие на Гарвард — например, отдельные кэши инструкций и данных на первом уровне.
GPU и другие ускорители нередко делают иные компромиссы: им важнее высокая параллельность и пропускная способность для потоков данных, поэтому организация памяти и исполнения может заметно отличаться от привычной «центральной» модели CPU.
Чтобы «прочувствовать» принцип хранимой программы, удобно представить компьютер как очень простой интерпретатор, который читает команды из памяти и исполняет их. Главное: и данные, и инструкции лежат в одной памяти, а процессор лишь последовательно их обрабатывает.
Пусть память — это массив ячеек MEM[0..N-1]. В ячейке может храниться число (данные) или структура инструкции.
Инструкцию представим как:
op — операция (например, LOAD, ADD, STORE)a, b — операнды (адреса в памяти или константы — для простоты возьмём адреса)Процессор хранит минимум состояния: PC (счётчик команд) и один регистр ACC (аккумулятор).
PC <- 0
ACC <- 0
while true:
IR <- MEM[PC] # instruction register
PC <- PC + 1
if IR.op == HALT:
break
if IR.op == LOAD:
ACC <- MEM[IR.a]
else if IR.op == ADD:
ACC <- ACC + MEM[IR.a]
else if IR.op == STORE:
MEM[IR.a] <- ACC
else if IR.op == JMP:
PC <- IR.a
Смысл прост: PC указывает на следующую команду в памяти, команда читается, «понимается» по op и меняет регистры/память. Эта схема и есть практическая форма цикла «выборка–декодирование–исполнение».
Добавим всего одну команду, например JZ addr (прыжок, если ACC == 0). Тогда появляются условия и циклы: можно делать «повторяй, пока не ноль», искать элемент, ветвиться по результату сравнения. Без условного перехода машина почти всегда сводится к прямой последовательности действий.
Попробуйте реализовать 3–5 инструкций в любом удобном виде (таблица команд, словарь, классы): LOAD, ADD, STORE, JMP, JZ.
Затем напишите программу «сумма массива»: в памяти лежат элементы A[0..k-1], а также адреса/счётчик. Задача — пройти по массиву, накопить сумму в ACC и сохранить результат в отдельную ячейку. Это упражнение быстро превращает абстрактную «хранимую программу» в понятный механизм.
Историческая идея «инструкции хранятся в памяти так же, как данные» неожиданно хорошо рифмуется с тем, как сегодня устроена разработка: программа — это артефакт, который можно генерировать, проверять, собирать, откатывать и разворачивать почти так же технологично, как и «обычные данные».
Например, в TakProsto.AI (vibe-coding платформа для российского рынка) многие шаги разработки делаются через диалог: вы описываете поведение приложения, а система помогает собрать решение на привычном стеке (веб на React, бэкенд на Go с PostgreSQL, мобильные приложения на Flutter). По смыслу это продолжение той же линии: меняя «описание» и состояние проекта, вы меняете поведение системы — без ручной перенастройки инфраструктуры.
Полезно и то, что в TakProsto.AI есть planning mode, снапшоты и откат (rollback), экспорт исходников, развёртывание и хостинг с кастомными доменами. Это делает работу с программой как с управляемым объектом ещё ближе к исходной интуиции хранимой программы: «положили в память/хранилище — поменяли — проверили — запустили снова», только на уровне современных проектов и окружений. Дополнительный практический бонус для авторов — возможность получить кредиты за контент про платформу или по реферальной ссылке, а по тарифам доступны уровни free, pro, business и enterprise.
Отдельно стоит отметить, что платформа работает на серверах в России и использует локализованные и открытые LLM-модели, что важно для проектов, где критичны требования к размещению и обработке данных.