Единый формат ошибок API: шаблон полей code, message, details, trace_id, правила для валидации и авторизации, и примеры ответов для фронтенда.
Когда API возвращает ошибки как попало, фронтенд начинает "угадывать": смотреть на текст, ловить разные статусы, искать куски строк вроде "not found". Это быстро превращается в хрупкую систему: одно новое слово в сообщении, и пользователь вместо понятной подсказки видит пустую форму или общий "что-то пошло не так".
Страдает не только интерфейс. Формы не могут подсветить конкретные поля, уведомления становятся случайными, аналитика смешивает разные причины в одну, а поддержке сложно понять, что именно произошло у пользователя. В итоге одна и та же ошибка выглядит по-разному на разных экранах, а исправлять это приходится по всему приложению.
Единый формат ошибок API решает проблему одним договором между фронтендом и бэкендом: любая ручка и любой сервис возвращают ошибку одной и той же формы. Тогда фронтенд опирается на стабильные поля (например, code и details), а текст message остается для человека, а не для парсинга.
Хороший формат сразу отвечает на четыре практичных вопроса: что случилось, где именно случилось, можно ли повторить, и что делать пользователю.
Простой пример: пользователь отправляет форму регистрации. Один раз бэкенд вернул "Email invalid", другой раз "Некорректный адрес", третий раз 400 без тела. Без контракта фронтенд не сможет стабильно подсветить поле email и показать понятную подсказку. С единым форматом бэкенд всегда сообщает: это валидация, ошибка в поле email, причина такая-то, и ее можно исправить вводом.
Такой договор особенно помогает, когда приложение растет, появляются микросервисы, несколько команд или генерация кода (например, в vibe-coding сценариях): единые правила снижают число сюрпризов на всех слоях.
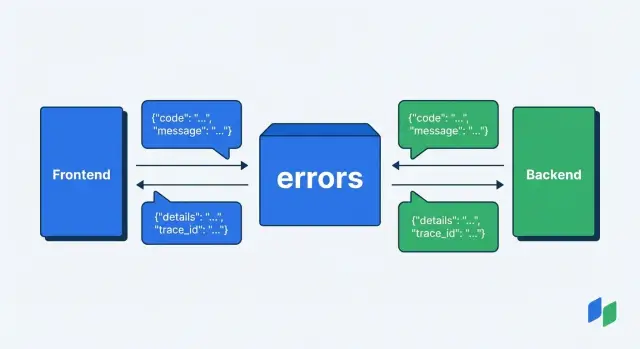
Чтобы фронтенд не "угадывал", что случилось, договоритесь: любая ошибка приходит в одном и том же JSON-формате, независимо от эндпоинта и статуса. Тогда UI одинаково показывает уведомления, подсвечивает поля формы и может передать в поддержку идентификатор запроса.
Минимальный конверт ошибки можно держать таким:
code (обязательное): короткий машинный код для логики на фронтенде и аналитики. Например: validation_failed, unauthorized, forbidden, rate_limited.message (обязательное): понятный текст для человека. Его можно показывать в интерфейсе (иногда в более мягкой форме).details (опциональное): структурированные подробности. Формат зависит от типа ошибки, но он должен быть предсказуемым внутри каждого code.trace_id (обязательное): строка, которая связывает ответ, логи и обращения пользователей.Правило простое: code читает программа, message читает человек. Не кодируйте логику в тексте message и не делайте code из длинных предложений.
Вот базовый пример, который подходит почти везде и хорошо расширяется:
{
"error": {
"code": "validation_failed",
"message": "Проверьте введенные данные",
"details": {
"fields": [
{"name": "email", "reason": "invalid_format"},
{"name": "password", "reason": "too_short", "min": 8}
]
},
"trace_id": "8f3c2a1b7c9a4d2e"
}
}
Обязательные поля лучше всегда возвращать одинаково, даже если details пустой. Например, для неизвестной ошибки details может быть {} или null, но ключ остается. Так единый формат ошибок API становится настоящим контрактом, а не набором исключений.
Отдельно стоит договориться про "обертку" (например, error: {...}): используйте ее везде или нигде. Смешанный подход усложняет типизацию и обработку на клиенте.
HTTP-статус говорит о типе проблемы на уровне протокола, а поле code (в теле JSON) уточняет бизнес-смысл. Когда команда один раз фиксирует эту связку, фронтенд перестает "угадывать" и показывает понятные сообщения.
Удобно держать короткую карту статусов, которые вы реально используете:
400 Bad Request - запрос в целом некорректен (не тот формат JSON, обязательный заголовок отсутствует, неверный тип данных)401 Unauthorized - пользователь не аутентифицирован (нет токена, токен просрочен, подпись не сходится)403 Forbidden - пользователь аутентифицирован, но прав не хватает404 Not Found - ресурс не найден (или скрыт, если вы не хотите подтверждать существование)409 Conflict - конфликт состояния (например, дубль уникального значения)422 Unprocessable Entity - ошибки ввода по правилам домена/валидации полей429 Too Many Requests - превышен лимит запросов500 Internal Server Error - неожиданная ошибка на сервереСамая частая путаница - 400 против 422. Простое правило: 400 для "не могу разобрать/понять запрос", 422 для "запрос понятен, но данные не проходят проверку". Например, сломан JSON или вместо массива пришла строка - это 400. А "email не похож на email", "пароль слишком короткий", "дата окончания раньше даты начала" - это 422.
401 и 403 нельзя смешивать, иначе фронтенд не знает, что делать: показать экран логина или сообщение "нет доступа". 401 почти всегда ведет к переавторизации. 403 - к объяснению прав (и, возможно, скрытию кнопок).
Для 500 держите единый подход: не раскрывать детали пользователю, но всегда возвращать trace_id, чтобы быстро найти ошибку в логах.
{ "error": { "code": "VALIDATION_ERROR", "message": "Проверьте введенные данные", "details": { "fields": { "email": "Неверный формат" } }, "trace_id": "7f3a..." } }
{ "error": { "code": "INTERNAL_ERROR", "message": "Что-то пошло не так", "details": null, "trace_id": "7f3a..." } }
Такой контракт (статус + code) и есть практический единый формат ошибок API: он предсказуемый, расширяемый и удобный для фронтенда и поддержки.
Валидация - главный источник "предсказаний" на фронтенде: какое поле подсветить, какой текст показать, можно ли повторить запрос. Единый формат ошибок API здесь особенно важен: бэкенд один раз описывает, что именно не так, а фронтенд просто отображает.
Для валидационных ошибок удобно отдавать HTTP 422 и заполнять details списком объектов. Список важен: пользователь часто ошибается сразу в нескольких местах, и лучше показать все проблемы одним ответом.
Чтобы это работало годами, полезно договориться о стабильных полях в details. Обычно хватает пути до поля (например, profile.age), короткой причины и, при необходимости, ожидаемого значения. Причина (например, invalid_format или too_short) должна быть стабильным идентификатором, а не свободным текстом: фронтенд сможет маппить ее на локализованные подсказки.
Пример: форма регистрации с несколькими ошибками в одном ответе.
{
"code": "VALIDATION_ERROR",
"message": "Некоторые поля заполнены неверно",
"details": [
{"field": "email", "issue": "invalid_format", "expected": "email", "received": "ivan@"},
{"field": "password", "issue": "too_short", "expected": ">= 8", "received": "12345"},
{"field": "terms", "issue": "required", "expected": true, "received": false}
],
"trace_id": "c2b6f4b9c4b14f3e"
}
Пример: фильтры в списке. Здесь удобно возвращать ошибки на уровне конкретного фильтра, чтобы интерфейс показал подсказку рядом с полем.
{
"code": "VALIDATION_ERROR",
"message": "Некорректные параметры фильтра",
"details": [
{"field": "filters.date_from", "issue": "invalid_format", "expected": "YYYY-MM-DD", "received": "01/31/2026"},
{"field": "filters.limit", "issue": "out_of_range", "expected": "1..100", "received": 1000}
],
"trace_id": "7a1d0fe3e2b047a1"
}
Такой подход делает ошибки предсказуемыми: фронтенд подсвечивает поля по field, выбирает текст по issue, а message остается общим и понятным для пользователя.
401 и 403 часто путают, и из-за этого фронтенд начинает гадать, что именно делать: показывать форму входа, обновлять токен или просто спрятать кнопку. Правило простое: 401 - пользователь не аутентифицирован (нет валидного токена), 403 - аутентифицирован, но доступа нет.
401 возвращайте, когда запрос нельзя связать с активной сессией: отсутствует токен, он просрочен или подпись не проходит проверку. В message пишите кратко и одинаково, без лишних деталей, чтобы не помогать атакующему.
Имеет смысл завести разные code для типовых сценариев, потому что реакция клиента отличается: где-то нужно показать логин, где-то попробовать обновление сессии, а где-то принудительно разлогинить пользователя.
Пример 401 (просрочено):
{
"code": "TOKEN_EXPIRED",
"message": "Сессия истекла. Войдите снова.",
"details": {
"action": "reauth"
},
"trace_id": "c2f0b2b0d5f74f0e"
}
403 используйте, когда токен валиден, но проверка прав не проходит. Тут полезно различать причины на уровне code, но не расписывать их в тексте.
Например, в TakProsto пользователь может быть залогинен, но функция недоступна из-за тарифа или роли в рабочем пространстве. Для фронтенда это разные сценарии: одно дело - объяснить, что прав не хватает, другое - показать, что нужно другое право или другой тариф.
Пример 403 (тариф):
{
"code": "FORBIDDEN_PLAN",
"message": "Недостаточно прав для выполнения операции.",
"details": {
"required_plan": "business"
},
"trace_id": "7a1b91e6f1b2411b"
}
Не пишите в message и details вещи вроде "токен неверный, потому что подпись не совпала" или "у пользователя нет роли admin в проекте X". Максимум: что сделать клиенту (перелогиниться, запросить доступ, сменить тариф) и безопасный минимум для интерфейса.
trace_id - это короткий идентификатор запроса, который помогает быстро найти нужные записи в логах и понять, что произошло. Он снимает вечную проблему: пользователь видит "Ошибка сервера", фронтенд не знает деталей, а бэкенду приходится угадывать по времени и контексту.
Важно договориться: trace_id создается на входе (API gateway или первый сервис), добавляется в каждый лог и прокидывается дальше по цепочке вызовов. Если запрос идет через несколько сервисов, все они должны писать один и тот же trace_id, чтобы расследование занимало минуты, а не часы.
На практике trace_id полезен в саппорте (пользователь прислал код, вы сразу находите запрос), в логах и трассировке (фильтр по одному значению вместо поиска "похожих" ошибок), в алертах и в аналитике.
Стек-трейс клиенту обычно отдавать нельзя. Это лишняя информация, иногда с деталями окружения. Вместо него лучше вернуть безопасный message для пользователя и структурированный details для интерфейса, а всю техническую глубину оставить в логах по trace_id.
Фронтенду нужен простой сценарий: показывать trace_id без паники. Например: "Не получилось выполнить действие. Попробуйте еще раз. Если ошибка повторяется, сообщите в поддержку код: 8f3c1a2b". В интерфейсе можно прятать его под "Подробнее" или показывать мелким текстом.
Пример ответа:
{
"code": "INTERNAL_ERROR",
"message": "Не удалось завершить запрос",
"details": null,
"trace_id": "8f3c1a2b"
}
Так фронтенд перестает гадать, а бэкенд получает точную точку входа в расследование.
Чтобы единый формат ошибок API не остался красивой схемой в документе, внедряйте его по частям. Цель простая: фронтенд перестает угадывать, что пришло, а бэкенд всегда отвечает предсказуемо.
Начните со словаря кодов. Это не про "все на свете", а про самые частые случаи: валидация, авторизация, доступ, не найдено, конфликт, внутренняя ошибка. Зафиксируйте правила именования и что точно означает каждый code.
Дальше добавьте общий обработчик ошибок на бэкенде. В Go это обычно middleware + единая функция, которая превращает любую ошибку в JSON с полями code, message, details, trace_id. Важно: даже неожиданные падения должны отдавать такой же "конверт", иначе фронтенду снова придется делать исключения.
Практичный порядок работ:
code и тексты message (короткие и понятные);trace_id: генерировать на входе запроса, прокидывать в логи и в ответ;Небольшой пример: если вы собираете React-фронтенд и Go-бэкенд, фронту достаточно один раз научиться читать единый формат и подсвечивать поля из details. Поддержке проще подключаться к задаче по trace_id, не переспрашивая "а что именно сломалось?".
Чтобы не переписывать все сразу, начните с одного-двух эндпоинтов и добавьте автотесты, которые проверяют форму ответа при ошибках. Потом расширяйте покрытие по мере правок.
Еще один практичный момент: подумайте о совместимости. Если формат уже используется клиентами, меняйте его либо через версионирование API, либо через добавление новых полей без удаления старых. Контракт ошибок ломается так же болезненно, как контракт успешных ответов.
Хаос обычно появляется, когда бэкенд и фронтенд "договариваются по ходу". В итоге единый формат существует только на словах: один эндпоинт отдает одно, второй - другое, а UI снова начинает угадывать.
Типичные проблемы, которые почти всегда возвращаются болью в поддержке и типизации:
message, а поле code оставляют пустым или "для галочки". Это ломает локализацию и аналитику: message должен быть понятен человеку и меняться под язык, а code должен быть стабильным ключом для логики и переводов;details разным в каждой ручке: то строка, то массив, то объект с произвольными ключами. Фронтенду приходится писать кучу проверок;200 OK и прячут ошибку внутри {\"error\": ...}. Кажется удобным, но ломает кеши, ретраи и мониторинг, а клиент вынуждает парсить тело даже при успехе;trace_id. Когда пользователь пишет "не работает", вы не можете быстро найти запрос в логах, особенно если ошибка редкая и не воспроизводится.Небольшой пример из жизни: пользователь отправляет форму регистрации, фронтенд ждет ошибки валидации по полям. Но API отвечает 400 с текстом "email invalid" в message и без details. В итоге UI не понимает, какое поле подсветить, показывает общий текст, а поддержка не может найти запрос, потому что нет trace_id.
Хорошее правило простое: code для логики, message для человека, details с предсказуемой структурой, trace_id для поиска. Если хотя бы одно из них "плывет", клиент начинает угадывать, и ошибка становится продуктовой проблемой.
Перед релизом полезно проходиться по ошибкам так же внимательно, как по успешным ответам. Если у вас есть единый формат ошибок API, этот чеклист помогает быстро поймать места, где фронтенду снова придется угадывать, что произошло.
Проверьте это на ревью и закрепите автотестами (хотя бы для самых частых ручек):
code и message, даже для 404 или 500;trace_id, он не пустой и выглядит одинаково по типу (строка/UUID), чтобы его можно было логировать и показывать в саппорт;details есть предсказуемая структура ошибок по полям (список или объект - но один выбранный вариант), и "причина" не меняется от версии к версии без необходимости;message и trace_id.Мини-сценарий для проверки: отправьте форму с ошибкой валидации, потом запрос без токена, потом запрос с обычным пользователем туда, где нужен админ, и в конце искусственно вызовите 500 на тестовом стенде. Если фронтенд в каждом случае может показать понятный текст, подсветить поле, предложить повторить, а саппорт может найти проблему по trace_id, контракт ошибок работает.
Представьте: пользователь редактирует профиль в веб-приложении. Он нажимает "Сохранить", а фронтенду нужно быстро понять, что произошло, и что показать на экране.
Сначала срабатывает валидация. API отвечает 422, и фронтенд не гадает по тексту, а берет детали по полям: подсвечивает email, показывает короткую подсказку и оставляет остальные поля как есть.
Пользователь исправляет email, нажимает "Сохранить" еще раз, но сессия уже истекла. API возвращает 401. Фронтенд сохраняет черновик (например, в памяти или локально), показывает экран входа и после успешного логина отправляет форму повторно.
После входа выясняется, что у пользователя нет прав менять часть настроек (например, только админ может менять роль). API возвращает 403, а фронтенд показывает понятное объяснение и предлагает доступное действие: "обратитесь к администратору" или "запросите доступ".
И наконец, бывает 500: база недоступна или сервис упал. Тут важно не пугать пользователя, а показать нейтральное сообщение "попробуйте позже" и дать trace_id, чтобы поддержка быстро нашла ошибку в логах.
// 422 Validation Error
{ "code": "VALIDATION_ERROR", "message": "Проверьте поля формы", "details": { "fields": { "email": "Некорректный формат" } }, "trace_id": "c3f1..." }
// 401 Unauthorized (token expired)
{ "code": "UNAUTHORIZED", "message": "Нужно войти заново", "details": { "reason": "token_expired" }, "trace_id": "a91b..." }
// 403 Forbidden
{ "code": "FORBIDDEN", "message": "Недостаточно прав для этого действия", "details": { "required_role": "admin" }, "trace_id": "b0d2..." }
// 500 Internal Server Error
{ "code": "INTERNAL_ERROR", "message": "Ошибка сервера. Попробуйте позже", "details": {}, "trace_id": "e77a..." }
В таком сценарии фронтенд ведет себя предсказуемо: где можно, помогает исправить данные, где нельзя, объясняет причину, а при сбоях дает trace_id, чтобы разбор занял минуты, а не часы.
Единый формат ошибок начинает приносить пользу, когда он становится правилом по умолчанию, а не "как получилось в этом эндпоинте". Следующий шаг - закрепить контракт так, чтобы новые ручки автоматически ему соответствовали.
Соберите один короткий реестр: для ключевых сценариев запишите HTTP-статус, внутренний code, пример message и форму details. Лучше, если это будут не "идеальные" формулировки, а те, что реально увидит пользователь.
Минимальный состав реестра: сценарий (что делал пользователь), статус + code (строго из оговоренного набора), пример message, схема details (какие поля и типы обязательны), и пример trace_id вместе с тем, где он ищется в логах.
После этого выберите одно место, где контракт живет всегда: спецификация (например, OpenAPI), отдельный документ с версионированием, или общий модуль ошибок в репозитории. Изменение формата ошибки должно быть таким же заметным, как изменение успешного ответа.
Добавьте автотесты, которые падают, если формат ошибки "поплыл". Достаточно покрыть ключевые ручки (логин, регистрация, оформление, поиск) и типовые сценарии (валидация, 401/403, 500).
Минимальный набор проверок:
code, message, trace_id, и они не пустые;details либо отсутствует, либо соответствует схеме для данного code;code и разные сценарии на фронтенде;trace_id находится запись об ошибке.Если вы собираете сервисы на TakProsto, удобно заложить это в шаблон проекта: единый handler ошибок в бэкенде (одна точка, где формируется JSON), и автоматическое добавление trace_id в каждый ответ. TakProsto (takprosto.ai) как платформа для разработки через чат помогает быстрее дойти до одинаковых практик в разных сервисах, особенно когда команда растет и появляется несколько приложений.
Чтобы не откатываться назад, добавьте простой ритуал: на код-ревью задавать вопрос "какой code вернем и как это обработает фронт", а изменения формата фиксировать как отдельную, заметную правку с примерами до/после.
Единый формат убирает необходимость «угадывать» по тексту и разным статусам. Фронтенд начинает опираться на стабильные поля, формы могут подсвечивать конкретные ошибки, аналитика не смешивает причины, а поддержка быстрее находит запрос по идентификатору.
Минимум, который стоит вернуть всегда: машинный code, человеческий message, опциональный details со структурой, и trace_id для поиска в логах. Важно, чтобы эти ключи приходили одинаково во всех ручках, даже когда details пустой.
code должен быть коротким и стабильным, чтобы клиент мог по нему принимать решения и строить аналитику. Хорошая практика — именовать коды по смыслу (validation_failed, unauthorized, rate_limited) и не менять их при правках текста message.
Используйте 400, когда сервер не может корректно разобрать запрос: сломанный JSON, неверные типы, обязательный заголовок отсутствует. Используйте 422, когда запрос понятен, но данные не проходят валидацию домена: неверный email, слишком короткий пароль, дата окончания раньше даты начала.
401 — когда нет валидной аутентификации: токен отсутствует, просрочен или не проходит проверку; клиент обычно должен переавторизоваться или обновить сессию. 403 — когда пользователь залогинен, но права не позволяют действие; клиенту нужно показать «нет доступа» или подсказку, что требуется роль/права/тариф.
Отдавайте одну предсказуемую структуру, чтобы UI мог подсветить несколько полей за один ответ. Обычно достаточно массива ошибок с field и стабильной причиной (issue), а в message оставить общее «проверьте данные», без попыток кодировать логику в тексте.
Пусть message будет безопасным и пригодным для показа пользователю, а вся логика живет в code и details. Если нужен перевод и разные формулировки, меняйте message, но не меняйте смысл code, иначе сломаются обработчики на фронтенде и отчеты.
trace_id связывает ответ API с логами и цепочкой вызовов сервисов, чтобы проблему можно было найти за минуту по одному значению. Клиенту достаточно показать этот код в экране ошибки или в детали, чтобы пользователь мог передать его в поддержку.
Для 500 возвращайте тот же «конверт» ошибки, но без внутренних деталей: нейтральный message, понятный code, и обязательно trace_id. Не отправляйте клиенту стектрейсы и текст исключений, иначе вы ухудшаете безопасность и все равно не помогаете пользователю исправить действие.
Начните с малого: согласуйте словарь кодов и добавьте единый обработчик ошибок, который формирует одинаковый JSON для всех эндпоинтов. Затем переведите в этот формат валидацию и авторизацию и добавьте тесты, которые проверяют наличие code, message, trace_id и ожидаемую структуру details для ключевых сценариев.