Интеграция вебхуков без сбоев: как проверять подпись, делать обработку идемпотентной, защищаться от повторов и быстро находить причины ошибок у клиентов.
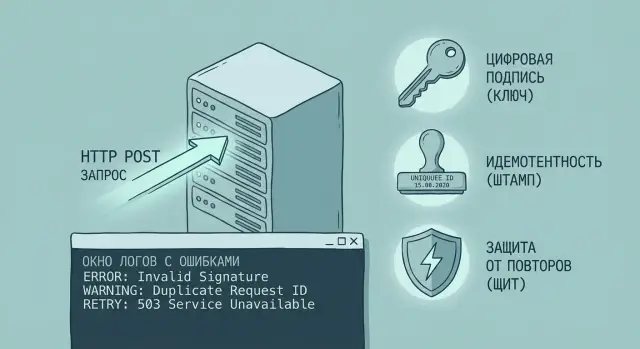
Фраза «вебхуки не ломаются» не означает, что запросы всегда доходят. Она про другое: если что-то пошло не так, система не делает вредных действий. Платеж не списывается дважды, заказ не прыгает между статусами, а причину можно быстро найти по логам.
Обычно ломается самое приземленное: проверка подписи (внезапные 401/403), обработка повторов (появляются дубли), таймауты (провайдер не дождался ответа и повторил доставку), формат данных (переименовали поле, число стало строкой). Иногда «у большинства работает», но падает у части клиентов: другой прокси, другая таймзона в заголовках, более медленный сервер, редкий тип события, который никто не тестировал.
Типичные симптомы:
Надежная интеграция вебхуков держится на четырех вещах: безопасность (подпись и контроль источника), надежность (идемпотентность и корректные ретраи), защита от повторов (окно времени и одноразовые значения) и наблюдаемость (корреляция по request id, понятные логи, сохранение сырого тела запроса). Когда это закрыто, даже «плохие» случаи становятся рутиной, а не пожаром.
Вебхук - это входящий HTTP-запрос, который отправляет провайдер события. Провайдером может быть платежка, CRM, маркетплейс или ваш же сервис. Ваш приемник - это endpoint на вашей стороне, который принимает запрос и возвращает ответ.
Важно разделять доставку и обработку. Доставка заканчивается в момент, когда вы быстро вернули понятный ответ (обычно 200-299). Это как сказать: «принял». Обработка - это то, что вы делаете дальше: сохраняете событие, меняете статус заказа, начисляете доступ, отправляете письмо. Если делать все это прямо внутри запроса и не успеть ответить, провайдер решит, что доставка не удалась, и начнет повторы.
Обычно в вебхуке есть заголовки (тип события, подпись, timestamp), тело запроса (часто JSON), идентификатор события (чтобы отличать повторы от новых) и метаданные (окружение, версия, источник).
Повторы (ретраи) - норма. Сеть падает, сервер бывает занят, время ответа выходит за лимит, балансировщик может вернуть 502. Поэтому провайдеры почти всегда повторяют отправку, часто по нарастающему интервалу.
Практическое правило: отвечайте быстро, а тяжелую работу делайте в фоне. Примите вебхук, проверьте базовые вещи (формат, подпись, обязательные поля), зафиксируйте событие в очереди или таблице и сразу верните 200. Отдельный воркер спокойно выполнит бизнес-логику. Такой подход легко собрать и в TakProsto: приемник на Go пишет событие в PostgreSQL, а фоновая задача обрабатывает его без риска сорвать доставку.
Подпись вебхука нужна, чтобы отличить реальный запрос от подделки. Без нее любой может отправить на ваш endpoint «оплачено» или «заказ отменен», и вы примете это как правду. При интеграции вебхуков подпись - базовая защита от подмены данных и несанкционированных действий.
Секретный ключ храните так же строго, как пароль к базе. Не кладите его в код и не пересылайте в чаты. Лучший вариант - переменные окружения или секрет-хранилище. Отдельный секрет на каждого партнера или клиента упрощает отзыв доступа и расследования.
Важно не только чем подписывать, но и что именно. Подписывайте «сырое» тело запроса (raw body) до JSON-парсинга и любых преобразований. Если подписывать распарсенный объект, подпись часто «ломается» из-за порядка полей, пробелов и кодировок. Нередко в строку подписи добавляют timestamp и путь запроса, чтобы снизить риск повторов и путаницы между разными endpoint.
Типовая схема - HMAC (например, HMAC-SHA256). Подпись передают в заголовке (например, X-Signature), а timestamp - в отдельном заголовке. На вашей стороне вы пересчитываете HMAC и сравниваете подписи.
Чтобы не ловить странные баги:
Идемпотентность простыми словами: одно и то же событие может прийти несколько раз, но результат должен быть таким, как будто оно пришло один раз. Это основа надежной интеграции вебхуков: ретраи, сетевые сбои и таймауты случаются всегда.
Ключ к идемпотентности - стабильный идентификатор события. Лучше всего использовать event_id от провайдера (если он гарантирует уникальность). Иногда встречается delivery_id (уникален для попытки доставки, а не для события) или заголовок Idempotency-Key. Если у вас есть и event_id, и delivery_id, храните оба: первый защищает бизнес-логику, второй помогает в диагностике.
Надежный вариант - отдельная таблица обработанных событий в базе (например, PostgreSQL) с уникальным индексом по event_id. Полезно добавить TTL: хранить записи 7-30 дней, чтобы не раздувать базу, но иметь защиту от повторов и материал для разборов.
Минимальная схема:
event_id.event_id в таблицу (уникальный индекс).Пример: платежный провайдер шлет payment.succeeded, но из-за таймаута повторяет доставку. Без идемпотентности вы дважды пометите заказ как оплаченный и можете дважды начислить бонусы. С идемпотентностью второй запрос получит быстрый 200, а система останется в правильном состоянии.
Replay-атака - это когда кто-то перехватывает валидный запрос вебхука и отправляет его снова позже, чтобы повторить действие (например, снова подтвердить оплату). Это отличается от обычного ретрая провайдера: ретрай идет по правилам доставки (после таймаута или 5xx), обычно в коротком интервале, и его цель - доставить, а не обмануть.
Базовая защита строится на двух полях: timestamp и nonce (или уникальный ID события). Timestamp помогает отсеять «старые» запросы, а nonce не дает принять один и тот же запрос дважды даже внутри допустимого окна.
Добавляйте в подписываемые данные время отправки (например, Unix time) и проверяйте, что запрос пришел в разумном диапазоне. Часто хватает 5-10 минут: этого достаточно для сетевых задержек, но мало для повторной отправки «через час».
Слишком узкое окно дает ложные отказы из-за очередей, ретраев и дрейфа времени. Слишком широкое повышает риск replay.
Nonce - одноразовый идентификатор, уникальный для каждого запроса или события. Храните «виденные» nonce в базе или кеше с TTL чуть больше окна времени (например, 15-30 минут). Если nonce уже был, возвращайте 2xx (чтобы провайдер не ретраил бесконечно), но не выполняйте действие повторно.
Практично хранить: nonce, время получения, тип события, результат обработки.
Когда отклоняете запрос, логируйте минимум:
Главное правило вебхуков простое: отвечайте быстро. Если делать тяжелую работу до ответа 2xx (например, дергать внешние сервисы или выполнять длинные операции с БД), провайдер может не дождаться и отправить событие еще раз. Так появляются дубли и «скачущие» статусы.
Правильный подход: принять запрос, проверить подпись, сохранить факт события и сразу вернуть 2xx. Затем делать остальное отдельно.
Фон можно начать с простого: «вебхук пришел -> записали -> обработали позже». Даже если сначала это таблица в базе и воркер по расписанию, смысл тот же.
Полезная настройка поведения по статусам:
С ретраями работает тот же здравый смысл, что и в любой доставке: провайдер будет повторять с задержкой, часто по экспоненте. Вам важно не надеяться на «один раз», а сделать обработку устойчивой: фиксировать статус обработки, хранить ключи дедупликации достаточно долго, не выполнять одно действие повторно.
Стабильная интеграция вебхуков похожа на прием письма: сначала фиксируем, что пришло, потом проверяем отправителя, и только после этого выполняем действия.
Примите запрос и сохраните сырое тело (raw body) вместе с заголовками, IP, временем, методом и URL. Это главный артефакт для разборов.
До JSON-парсинга проверьте подлинность: подпись (HMAC или аналог) и актуальность времени (timestamp). Если проверка не прошла, верните 401/403 и короткую причину. В логах фиксируйте, что не сошлось.
Распарсьте payload и провалидируйте обязательные поля: тип события, уникальный идентификатор (event_id), время события, объект (например, order_id). Если чего-то нет, верните 400 и укажите, чего не хватает.
Проверьте идемпотентность: заведите таблицу или ключ в хранилище по event_id (или idempotency-key) и пометьте событие как «получено». Если такой event_id уже был, не выполняйте бизнес-операции повторно, но отвечайте 2xx.
Ответьте 2xx как можно быстрее и продолжайте обработку безопасно: положите задачу в очередь/фон, обновляйте статус обработки и делайте ретраи внутри вашей системы.
Когда клиент пишет «вебхук не пришел» или «статус не обновился», задача обычно одна: сопоставить конкретное событие с тем, что увидела ваша система. Для этого заранее нужен минимальный, но стабильный набор логов.
Сохраняйте хотя бы: request_id (или генерируйте свой), event_id (если есть), тип события, время получения и итоговый статус обработки (приняли, отклонили, поставили в очередь, ошибка). Это снимает гадание «примерно по времени».
Хорошо работает корреляция: один идентификатор проходит через все шаги. Например, request_id вы прикрепляете к записи в БД, к задаче в очереди и к логам бизнес-операции (обновление заказа, выдача доступа, создание платежа). Тогда быстро видно, где сломалось: на подписи, парсинге, валидации или в бизнес-логике.
Чтобы воспроизвести проблему, нужно повторить ровно тот же вход: сохраненный raw payload (как пришел, без «красивого форматирования»), заголовки (подпись, timestamp, idempotency key) и точное время. Даже если вы не можете переотправить запрос через провайдера, вы прогоните тот же JSON через обработчик и увидите, где он падает.
У клиента лучше сразу просить конкретику:
event_id или другой идентификаторПрактический пример: клиент сообщает, что заказ не сменил статус. По event_id вы находите запись: запрос пришел, подпись не сошлась, вернули 401. Дальше проверяете секреты (тест/прод), не менялось ли тело запроса до проверки подписи, не теряются ли заголовки на прокси.
Самые болезненные проблемы в интеграции вебхуков обычно не «в коде вообще», а в паре решений, которые выглядят логично, но ломают доставку или делают инциденты неразбираемыми.
Клиент пишет: «вебхук не сработал». В логах проверьте три вещи: был ли запрос вообще, прошла ли подпись (по raw body), и какой код вы вернули. Если запрос был, но ответа нет или он долгий, почти всегда причина в синхронной обработке. Правильнее быстро вернуть 200 после валидации и отправить событие в фон, а идемпотентность завязать на event_id или idempotency-key.
Перед релизом полезно убедиться, что интеграция выдержит повторы, задержки и сетевые сбои. Это занимает 10-15 минут, но экономит часы разборов.
Если хоть один пункт не выполнен, лучше остановиться и доделать. В проде такие мелочи чаще всего и становятся дорогими.
Интернет-магазин подключил платежный сервис. После оплаты клиент видит страницу «Спасибо», но в админке заказ иногда остается в статусе «Ожидает оплату». А иногда происходит обратное: один и тот же заказ получает два чека и два письма «Оплата получена».
Разбор показал типичный сценарий: платежный сервис отправляет payment.succeeded, ваш обработчик отвечает не сразу (например, из-за медленной базы), сервис не дожидается ответа и делает повторную доставку. В результате одно и то же событие прилетает дважды, и без идемпотентности система выполняет действие два раза.
Правильное поведение простое: один заказ, один чек, один переход статуса. Для этого при интеграции вебхуков обработчик должен «узнавать» повтор и спокойно отвечать 200, не выполняя бизнес-логику второй раз.
Как быстро найти причину, когда жалоба уже у клиента:
event_id (или внешним payment_id).event_id), а не на «текущий статус заказа».Исправление обычно сводится к двум вещам. Во-первых, храните ключ идемпотентности и делайте его уникальным на уровне базы (например, уникальный индекс по provider + event_id). Тогда повтор не создаст дубль даже при ошибке в коде. Во-вторых, отвечайте провайдеру быстро: примите событие, запишите его, верните 200, а тяжелую работу выполните в фоне.
Проверка простая: возьмите сохраненный запрос и отправьте его еще раз (или включите тест повторной доставки у провайдера). Если все сделано верно, статус заказа не изменится второй раз, а в логах появится «повторное событие, пропускаю».
Сначала зафиксируйте требования к интеграции как к продукту, а не как к одному endpoint: что проверяете в подписи, где храните секреты, какой ключ идемпотентности используете, как обрабатываете ретраи и какие логи обязательны. Это снимает большую часть споров в стиле «у клиента не работает», когда никто не договорился, что считать нормой.
Дальше соберите минимальный набор артефактов, который позволит воспроизводить проблемы без клиента. Полезно иметь библиотеку сохраненных примеров payload: «успех», «повтор», «просроченный timestamp», «неверная подпись», «сломанный JSON».
Практичный план внедрения на 1-2 дня:
request_id, event_id).Если нужно быстро собрать приемник вебхуков и простую админку для просмотра логов и повторной обработки, это можно сделать в TakProsto (takprosto.ai): собрать сервис через чат, развернуть и хостить, а при необходимости экспортировать исходники и дальше поддерживать их в своем цикле разработки.
Это про безопасное поведение при сбоях. Запрос может не дойти или прийти дважды, но система:
То есть «не ломаются» = не приводят к неправильному состоянию, даже когда сеть и ретраи неизбежны.
Сразу ответить 2xx и обработать в фоне. Внутри HTTP-запроса делайте только минимум:
event_id и записать событие (в таблицу/очередь)Дальше воркер спокойно выполнит бизнес-логику, и таймауты провайдера не будут превращаться в дубли.
Почти всегда потому, что подпись считают не по тому, что подписывал провайдер. Надежное правило:
Если фреймворк «съедает» raw body, подпись будет ломаться даже при правильном секрете.
Храните секрет как пароль к базе:
В логах можно писать, что «секрет не подошел/заголовка нет», но нельзя писать сам секрет и полный payload.
Идемпотентность — это когда одно и то же событие можно получить несколько раз, а итог будет как от одного раза. Делается так:
event_id (лучше от провайдера)Так ретраи и таймауты перестают быть проблемой.
Опирайтесь на event_id, а не на «похоже на то же самое». Практичный минимум:
webhook_events с уникальным индексом по (provider, event_id)полезен для диагностики попыток доставки, но он не заменяет для дедупликации.
Защита от replay нужна на случай, если кто-то повторно отправит валидный запрос позже. Базовый набор:
timestamp в подписываемых данныхnonce или уникальный ID события + хранение «виденных» значений с TTL чуть больше окнаЕсли запрос старый или nonce уже был, действие не выполняйте. Часто лучше вернуть 2xx и просто «пропустить», чтобы не спровоцировать бесконечные ретраи у провайдера.
Это соглашение о смысле ответа. Обычно:
2xx — приняли доставку (провайдер может не повторять)4xx — запрос плохой (часто не повторяют): нет обязательных полей, неверный JSON, не прошла подпись5xx — временная проблема (будут повторы): упала база, таймаут, внутренняя ошибкаВажно: не отдавайте из-за «у нас бизнес-ошибка» (например, заказ не найден). Это создаст ненужные повторы.
Сохраните минимум, который позволит сопоставить жалобу с конкретным запросом:
request_id (полученный или ваш)event_id, тип событияДействуйте по чек-листу, чтобы быстро сузить причину:
event_id.5xx почти гарантирует ретраи.delivery_idevent_id5xxТогда по одному идентификатору можно пройти весь путь: вебхук → запись → воркер → бизнес-действие.
event_id.Если нужен быстрый прототип приемника и фоновой обработки, это можно собрать в TakProsto: endpoint на Go пишет события в PostgreSQL, а воркер обрабатывает их отдельно, что снижает риск таймаутов и дублей.