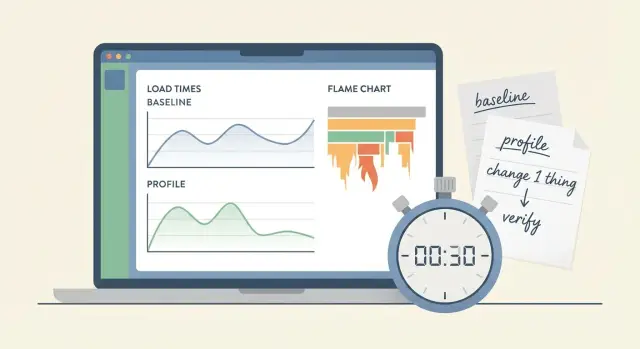
Измерение производительности как привычка: сначала базовая линия, затем профилирование, одно изменение за раз и проверка эффекта без самообмана.
Когда говорят «надо ускорить», часто начинают с любимых приемов: сжать картинки, переписать компонент, убрать анимации. Без данных это похоже на ремонт машины с завязанными глазами. Время уйдет, а пользователь может не почувствовать разницы.
Без измерений легко принять следствие за причину. Страница «тормозит» - значит, виноват React. Или сеть. Или база. Или «тяжелый дизайн». В итоге обсуждение превращается в спор мнений, а не в поиск узкого места. Каждый тянет в сторону того, что лучше знает.
Еще одна ловушка - путать «медленно для разработчика» и «медленно для пользователя». Разработчик смотрит на цифры в консоли или на время сборки, а пользователю важно другое: когда экран стал понятным, когда можно нажать кнопку, когда прокрутка не дергается. Если вы не договорились, что именно измеряете, можно улучшить «красивую» метрику и ухудшить реальный опыт.
Измерения должны быть первым шагом, а не отчетом в конце. Сначала выбирают одну-две метрики, которые отражают боль пользователя, и только потом правят код.
Командная договоренность обычно сводится к простым вопросам: что именно считаем «медленно» (метрика и порог), где меряем (какой экран и сценарий), на каких устройствах и сети, и чем подтверждаем улучшение (одни и те же инструменты и условия).
Даже в быстрых прототипах, которые собирают в TakProsto, это экономит время: вместо «ускорим все» появляется конкретная цель и понятная проверка результата.
Paul Irish много лет повторяет одну мысль: сначала поставьте измерители, и только потом пытайтесь «ускорять». Если вы не видите, где тратится время и память, вы не оптимизируете, а угадываете. И чаще всего угадываете неправильно.
Разница между догадкой и наблюдением очень практичная. Догадка звучит так: «Наверное, медленно из-за картинок». Наблюдение звучит иначе: «90% времени уходит в выполнение скрипта при скролле, а картинки уже давно загружены». Профайлер показывает, что именно заняло время, сколько раз вызвалась функция, где выросла очередь задач и на каком шаге появился лаг.
Важно относиться к этому не как к разовой проверке «перед релизом», а как к привычке. Вы делаете маленькие улучшения, но делаете их безопасно, потому что каждый шаг подтвержден цифрами.
Этот подход снижает риск сломать то, что и так было нормально. Когда вы «ускоряете вслепую», легко получить побочные эффекты: ухудшить первый рендер, увеличить потребление памяти, добавить дрожание интерфейса или сделать поведение непредсказуемым на слабых устройствах. Инструментирование помогает держать фокус на главном: что реально тормозит и что важно пользователю.
Перед любыми правками полезно держать в голове простой порядок действий:
Простой пример: экран «Каталог» кажется медленным, и команда хочет «почистить CSS». Профилирование показывает, что просадки идут из-за лишних пересчетов при каждом вводе в поиск. Одна правка - откладываем фильтрацию на паузу 200 мс или уменьшаем число перерисовок - и лаги исчезают. Без измерений вы бы потратили время не туда.
Если относиться к скорости как к задаче измерения, сначала нужно договориться, что именно считается «быстро». Люди не держат секундомер в голове. Они судят по ощущениям: когда появляется что-то полезное, насколько плавно все движется и как быстро откликаются действия.
Обычно достаточно пяти сигналов:
Смотрите на сигналы «пользовательскими глазами». Например, если страница рисуется за 2 секунды, но кнопка «Купить» начинает работать только через 5 секунд, человек запомнит именно эти 5 секунд. А если прокрутка дергается, то даже быстрые загрузки не спасают впечатление.
Короткий пример: в приложении на React список товаров появляется быстро, но при скролле все начинает подтормаживать. В профайлере видно, что при каждом движении пересчитываются тяжелые компоненты и картинки декодируются на лету. Здесь главная метрика - плавность и длинные задачи в главном потоке, а не только «скорость загрузки».
И не забывайте про сервер. Даже если интерфейс идеален, один медленный запрос (например, сложная выборка в PostgreSQL) может превращать любой клик в ожидание. Поэтому полезно параллельно фиксировать время ответа, самые тяжелые эндпоинты и повторяющиеся запросы.
Если вы собираете продукт через TakProsto, логика та же: сначала выбираете 1-2 сигнала, которые важны для конкретного экрана, и измеряете их до любых правок.
Прежде чем что-то ускорять, договоритесь, что именно вы измеряете. Не «сайт медленный», а один понятный сценарий: например, «открыть каталог и дождаться первой карточки» или «нажать Оплатить и увидеть подтверждение». Одна задача - один baseline.
Дальше зафиксируйте условия. Иначе сравнивать будет нечего. Одно и то же действие на разных устройствах и сетях дает разные цифры, и вы легко «улучшите» результат только потому, что тестировали на другом телефоне.
Минимум, который стоит записать рядом с цифрами: сценарий и точные шаги; устройство и браузер (или модель телефона и версия ОС); сеть (Wi‑Fi/4G и качество); окружение (прод/стейдж/локально) и версия сборки; метрика, по которой судите.
Снимите несколько замеров подряд и берите «типичный» результат, а не лучший и не худший. Удобная привычка - 5 прогонов и медиана. Так вы отделите разовый всплеск (фоновое обновление, случайный скачок сети, прогрев кеша) от повторяющейся проблемы.
Сохраняйте артефакты: скриншот с таймингами, короткую заметку «что считали успехом» и, если возможно, экспорт профиля или лог. Это превращает скорость в проверяемую работу, а не в спор «кажется быстрее».
Профилирование - это не просто «посмотреть логи». Логи отвечают на вопрос «что случилось» и зависят от того, что вы заранее догадались записать. Профилирование отвечает на вопрос «куда ушло время» и показывает картину целиком: CPU, сеть, рендер, запросы к базе, блокировки.
Договоритесь внутри команды о простом принципе: сначала собираем факты, потом спорим про оптимизации. Один и тот же «тормоз» на глаз может оказаться совсем другим. Кажется, что медленный фронтенд, а на деле ждете сеть. Или кажется, что виновата база, а на деле UI делает лишние перерисовки.
Во время сессии профилирования полезно разложить задержку по крупным категориям и понять, какая доминирует: рендер (долгие кадры, частые перерисовки), JavaScript (длинные задачи на главном потоке), сеть (много запросов, ожидание первых байт), сервер и база (медленные эндпоинты, N+1, индексы, блокировки), I/O и сторонние сервисы.
Ключевой принцип - одна основная причина. В каждом замере обычно есть самый большой кусок, который и дает основной выигрыш. Не пытайтесь улучшить все понемногу. Найдите 2-3 главные находки за сессию и остановитесь, иначе утонете в мелочах.
Пример: экран, собранный в TakProsto на React + Go + PostgreSQL, открывается за 3 секунды. Профилирование показывает, что 2.2 секунды уходит на один эндпоинт, а внутри него 40 похожих запросов к таблице. Это уже не «оптимизировать React», а конкретная точка: убрать N+1, собрать данные одним запросом или добавить индекс.
Чтобы вернуться к выводам позже, фиксируйте кратко: какой сценарий мерили, где самый большой кусок, цифры «до», и что подозреваете как причину.
После базовой линии и профилирования появляется соблазн «поправить все сразу». Но подход Paul Irish держится на простом правиле: измеряем, меняем одну конкретную причину и снова измеряем. Иначе вы не поймете, что именно дало эффект (или ухудшило результат).
Сформулируйте гипотезу так, чтобы ее можно было проверить цифрами: что именно меняем, какую метрику ожидаем улучшить и насколько. Например: «Если уберем лишний повторный запрос к базе на этом экране, время ответа API снизится на 20%».
Дальше сознательно ограничьте объем работы одним фактором. Не трогайте соседний код «заодно», не делайте косметический рефакторинг. Маленькое изменение проще оценить и проще откатить.
Перед коммитом полезно зафиксировать три вещи:
Пример: экран грузится медленно, профиль показывает, что 40% времени уходит на тяжелую картинку в шапке. Гипотеза: «Если отложим загрузку этой картинки до первого взаимодействия, LCP улучшится минимум на 300 мс». Меняете только загрузку картинки, ничего больше.
Если вы работаете в TakProsto, удобно делать такие эксперименты через snapshots и rollback: пробуете смело, но не застреваете в «полуработающей» версии.
После изменения самое важное - доказать, что стало лучше, а не просто повезло с одним замером. Смысл подхода в том, что вы сравниваете цифры в одинаковых условиях и принимаете решение по данным.
Сравнивайте «после» строго с baseline: тот же девайс (или тот же эмулятор), тот же браузер, похожая сеть, одинаковая версия сборки. Debug и production тоже дают разные результаты, это важно учитывать.
Сделайте несколько прогонов и смотрите не на один удачный результат, а на разброс. Иногда медиана стала лучше, но хвосты (p95 или редкие «залипания») остались. Для пользователя именно они и болят.
Проверка перед тем, как радоваться:
Запишите простую формулу: «что изменили -> что измеряли -> какой эффект». Например: «убрали лишний ре-рендер компонента списка -> время до интерактива на среднем Android -> стало на 18% быстрее, ошибок нет». Это помогает команде не спорить по памяти.
Если эффекта нет, не стоит дальше «крутить настройки» наугад. Возвращайтесь к профилю: возможно, вы ускорили не тот участок, или узкое место переехало (ускорили CPU, но уперлись в сеть или в базу).
Самая частая причина провальных оптимизаций проста: начинают чинить то, что «кажется» медленным, а не то, что реально тормозит. Без профилирования и нормальных замеров легко потратить день на косметику и не сдвинуть метрику.
Еще одна ловушка - большой пакет правок. Когда вы одновременно уменьшили картинки, переписали компонент, поменяли запросы и добавили кеш, вы не узнаете, что именно помогло, а что добавило проблем. Потом это сложно поддерживать и почти невозможно повторить на других экранах.
Не менее коварны «нечестные» сравнения. Сегодня вы меряете на быстром Wi‑Fi и пустой базе, завтра - на 4G и с реальными данными. Кажется, что стало хуже или лучше, но это просто разные условия. Поэтому важно фиксировать сценарий (те же действия пользователя) и условия (устройство, сеть, объем данных).
Отдельная ошибка - погоня за микросекундами, когда людям больно от другого. Пользователь может злиться не из-за 50 мс в рендере, а из-за того, что кнопка не дает понятной реакции, экран «пустой» или запрос висит 3 секунды. Иногда лучший фикс - скелетон, прогресс и ранний показ данных, а не тонкая настройка анимаций.
Перед тем как радоваться «ускорили», остановитесь на минуту. Хорошая оптимизация почти всегда начинается с измерений, а не с догадок.
Выберите один конкретный сценарий. Не «сайт медленный», а «открытие карточки товара на мобильном интернете» или «первый запуск экрана после логина». Для этого сценария зафиксируйте одну главную метрику, которую хотите улучшить.
Проверьте, что базовые условия выполнены:
После этого останется зафиксировать результат. Запишите «было -> стало», короткий вывод (что сработало или не сработало) и следующий шаг. Например: «время ответа API упало с 900 мс до 420 мс, дальше проверяем вклад сериализации».
Если вы делаете продукт в формате быстрых итераций, как в TakProsto, этот чеклист помогает не теряться: меняете одно, проверяете, откатываете при необходимости и идете дальше без иллюзий.
Представьте страницу на React: каталог, сверху фильтры. Пользователь меняет фильтр, и дальше 2-3 секунды кажется, что все зависло. Запрос вроде уходит быстро, но список появляется поздно, а скролл дергается.
Сначала измеряем, а не «угадываем». Базовую линию можно снять даже без сложных инструментов: на одном и том же устройстве три раза подряд повторить сценарий «изменил фильтр -> вижу обновленный список» и записать цифры.
Например:
Дальше профилируем. В профайлере видно, что сеть занимает всего около 200 мс, а основное время уходит на рендер: список из 400 карточек пересчитывает фильтрацию и сортировку на каждом рендере, плюс тяжелые вычисления по промо-ценам. То есть «тормоз» не запрос, а работа в UI.
Выбираем одно изменение и формулируем гипотезу: «Если мемоизировать вычисления и не пересчитывать список, когда не менялись входные данные, то время до появления списка уменьшится». Фикс простой: вынести фильтрацию и сортировку в memo и убедиться, что зависимости корректные. Если данных очень много, альтернативы тоже понятные: уменьшить объем ответа или показывать первые элементы раньше.
После изменения повторяем ровно тот же тест на том же устройстве:
Субъективно экран перестал «подвисать», и это подтверждается цифрами. Следующий шаг - закрепить правило на будущее. Например, добавить порог (перфоманс-бюджет) на время рендера списка и проверять его при изменениях. В TakProsto это хорошо ложится на привычный цикл правок: снял baseline, посмотрел профиль, поменял одну вещь, проверил эффект.
Если хочется реальных улучшений, превратите замеры в привычку: перед любым «ускорением» тратьте хотя бы 30 минут на измерения. Это время обычно окупается, потому что вы перестаете спорить на ощущениях и начинаете работать по фактам.
Начните с простых правил, которые легко соблюдать. Самое полезное - перфоманс-бюджет для ключевых экранов и сценариев: что считаете нормой по загрузке, плавности и времени ответа. Бюджет нужен не для отчетности, а чтобы команда одинаково понимала, когда стало хуже и почему это важно.
Чтобы процесс не превращался в бесконечную погоню за идеалом, держите короткий цикл:
Отдельно заведите одно место для находок: короткие заметки, скриншоты профиля, выводы. Тогда через месяц вы не будете снова повторять тот же круг.
Если делаете продукт с нуля, заранее заложите сценарии замеров. Определите 5-10 пользовательских действий, которые будут критичны всегда (логин, поиск, оформление, открытие карточки), и привяжите к ним базовые замеры еще до того, как появится много фич.
Если нужен быстрый цикл экспериментов, в takprosto.ai удобно сочетать planning mode для плана работ и snapshots/rollback для аккуратных проверок «до/после». Это помогает сравнивать изменения честно и не смешивать эффект разных правок.
Потому что без цифр вы лечите симптомы наугад. Часто «тормозит React» оказывается ожиданием сети или медленным запросом к базе, а «тяжелый дизайн» — длинными задачами в главном потоке.
Правильный порядок простой: сначала измерить, потом править самый большой кусок задержки, и снова измерить в тех же условиях.
Выберите 1–2 сигнала, которые реально чувствуются пользователем:
Главное — заранее договориться, что именно вы называете «быстро» и какой порог приемлем.
Опишите один конкретный клик-путь, например: «Открыть каталог → дождаться первой карточки» или «Нажать “Оплатить” → увидеть подтверждение».
Одна задача = один baseline. Так проще сравнивать «до/после» и понимать, что именно улучшили.
Минимум, который стоит записать рядом с цифрами:
Без этих условий сравнение почти всегда будет нечестным.
Сделайте несколько повторов и берите типичное значение. Практичный вариант — 5 прогонов и медиана.
Так вы меньше зависите от случайных всплесков: прогрева кеша, фоновых процессов, скачков сети.
Разложите задержку по крупным категориям и ищите доминирующую:
Цель — найти один самый “толстый” участок, а не чинить десять мелочей.
Сформулируйте проверяемую гипотезу: что меняем → какую метрику улучшаем → на сколько.
Например: «Уберем N+1 в PostgreSQL на эндпоинте каталога → p95 времени ответа снизится на 20%».
И меняйте только один фактор. Иначе вы не узнаете, что реально сработало (или что сломало).
Смотрите не только на «стало быстрее», но и на побочные эффекты:
Оптимизация считается успешной, когда улучшение устойчивое и не ломает опыт.
Вернитесь к профилю: скорее всего, вы ускорили не тот участок или узкое место «переехало» (например, CPU стало лучше, но теперь упираетесь в сеть).
Дальше действуйте так:
Не пытайтесь «дожать» эффект настройками наугад.
Используйте короткий цикл экспериментов: baseline → профиль → одна правка → повторный замер.
В TakProsto удобно поддерживать такой процесс за счет:
Так вы быстрее приходите к проверяемым улучшениям, а не к спору «кажется быстрее».