Kafka и event streaming помогают строить системы, где изменения записываются как события. Разберем очередь vs лог, критерии выбора и практические шаги.
Пока сервисов немного, обмен сообщениями выглядит просто: один сервис отправил, другой получил, задача решена. Но со временем появляется больше команд, больше функций и больше систем вокруг (аналитика, поддержка, биллинг, антифрод). Каждой из них нужны данные быстро и регулярно.
В этот момент интеграции начинают расти как паутина. Вчера у вас было 3-4 соединения между сервисами, а сегодня - десятки. Каждое новое подключение требует договориться о формате, обработке ошибок, повторах (ретраях), порядке доставки и версиях схемы. Чем больше точек связи, тем чаще изменения в одном месте неожиданно ломают другое.
Обычный обмен сообщениями со временем превращается в хаос по одной причине: в системе нет понятного общего места, где фиксируются изменения. Сообщение "улетело" и исчезло. А когда нужно восстановить картину, выясняется, что история живет кусками: в логах приложений, в таблицах, в отдельных очередях и в памяти людей.
Обычно всплывают одни и те же вопросы:
Чтобы не путаться в терминах, событие - это факт, который уже произошел и не меняется: "заказ создан", "платеж подтвержден", "адрес доставки изменен". Это не команда "сделай", а запись "сделано".
Когда нет единого места, где такие факты аккуратно складываются и хранятся, система начинает терять память. Например, вы подключили новый сервис аналитики и вдруг понимаете: ему нужно не только то, что происходит с этого момента, но и все за прошлый год. Если события были разосланы по разным очередям, а часть ходила напрямую через API, восстановить историю становится сложно или дорого.
Именно из этой боли выросли подходы вроде распределенного лога и то, что позже стали называть Kafka и event streaming: хранить поток фактов так, чтобы разные потребители читали его в своем темпе, а история оставалась доступной.
Jay Kreps работал над большими распределенными системами, где десятки сервисов и команд должны обмениваться данными быстро и без постоянных ручных интеграций. Проблема была не в том, чтобы один раз передать сообщение, а в том, чтобы сделать это предсказуемо: чтобы каждый новый потребитель мог получить те же данные, что и предыдущие, и чтобы можно было точно разобраться, что случилось вчера в 03:17.
Отсюда выросла простая идея: вместо того чтобы думать об обмене как о разовой доставке, нужно сначала зафиксировать факт в общем журнале, а уже потом читать его сколько угодно раз.
Вы записали событие (например, "заказ создан") и дальше любые сервисы читают его в своем темпе: расчет скидок, склад, доставка, аналитика.
Лог удобен тем, что дает единую историю изменений. Это снижает количество точечных интеграций "сервис к сервису" и позволяет подключать новые системы без просьб "а отправьте нам еще одно уведомление". Если сервис упал, он не теряет смысл происходящего: он догоняет поток, перечитав события с нужного места.
Kafka выросла из этой инженерной практики в инфраструктурный слой: распределенный, устойчивый, способный держать большой поток событий, хранить их заданное время и отдавать многим потребителям. Это не просто "очередь побыстрее", а основа, на которой можно строить аудит, перерасчет и восстановление состояния.
При этом важно не ждать от Kafka чудес. Она не придумывает за вас хорошие события и не заменяет продуманную модель данных.
Сложность обычно появляется в практических вещах: нужно договориться о смысле событий и их схеме, жить с повторами доставки, продумать версионирование, ретеншн и поддержку кластера.
Если воспринимать лог как источник правды и историю фактов, Kafka начинает окупаться. Если ждать, что она сама уберет хаос в данных, разочарование почти гарантировано.
Представьте доставку писем.
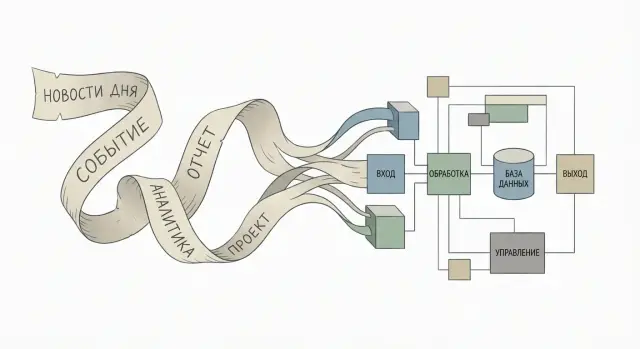
Очередь сообщений похожа на почтовый ящик для одного адресата: письмо попало в ящик, курьер забрал, доставил, и оно больше никому не нужно. В типичном сценарии после успешной обработки сообщение "исчезает": его удаляют из очереди, чтобы не обработать второй раз.
Лог (распределенный лог) больше похож на журнал событий: каждая запись остается, а читатели сами решают, где они остановились. Сегодня вы читаете с середины, завтра перечитываете сначала, а через неделю подключаете нового читателя, который догоняет всю историю.
Главная разница ощущается у потребителей.
В очереди логика обычно такая: "есть работа, ее надо выполнить". Если потребителей несколько, они делят сообщения между собой ради скорости, но смысл остается прежним: одно сообщение - одна обработка.
В логе может быть много независимых потребителей, и каждый получает одни и те же события, но для своей цели.
Повторная обработка - самый практичный водораздел:
Это меняет мышление: вместо передачи команд ("сделай скидку", "спиши со склада") вы фиксируете факты ("скидка применена", "товар списан"). Факт можно проверить, воспроизвести и использовать повторно.
Простой пример: есть событие "Заказ оплачен". В очереди его обычно заберет один обработчик, например сервис доставки, и после успеха сообщение исчезнет. А если завтра вы захотите добавить аналитику, антифрод и уведомления, придется разветвлять доставку или дублировать данные.
В логовом подходе этот же факт читают несколько сервисов независимо: доставка планирует отгрузку, аналитика считает выручку, антифрод оценивает риск, уведомления отправляют чек. Если затем нашли ошибку в расчетах, можно заново "проиграть" события и исправить результат без ручной охоты за потерянными сообщениями.
Очередь сообщений хороша там, где нужно передать задачу "сделай это позже" и не превращать обмен сообщениями в отдельный продукт внутри компании. Если цель - снять нагрузку с основного сервиса и не блокировать пользователя, message queue часто закрывает вопрос быстрее и дешевле, чем Kafka и event streaming.
Типичный пример - фоновая обработка. Пользователь нажал кнопку "Скачать отчет", система ставит задачу в очередь и возвращает "Отчет готовится". Дальше воркер берет задачу, генерирует файл, кладет результат в хранилище и отправляет письмо или пуш.
Очередь особенно уместна, когда маршрут сообщения простой и потребителей мало: один продюсер и один-два воркера. Вам не нужно, чтобы разные команды независимо подписывались на один и тот же поток и придумывали новые сценарии использования данных.
Еще один важный признак: вам не нужна длинная история и "переигрывание" прошлого. Если задачу можно безопасно выполнить один раз (или повторить без вреда), а через день она уже не имеет ценности, хранить события месяцами нет смысла.
Практический ориентир: если вы все чаще обсуждаете "что будет, если завтра появится 10 новых подписчиков на эти данные?" или "как восстановить состояние на вчерашний вечер?", то вы уже рядом с логовым подходом. Если же речь про надежную доставку задач воркерам и контроль повторов, очередь часто будет самым разумным выбором.
Логовый подход становится выгодным, когда события превращаются из "сигналов для одного обработчика" в общие факты о бизнесе. Не просто "отправить письмо", а "заказ создан", "оплата подтверждена", "посылка передана в доставку". Такие факты нужны разным командам и сервисам, и почти всегда в разное время.
Первый явный признак: один и тот же поток читают несколько потребителей. Например, продукту нужны триггеры для коммуникаций, аналитике - метрики, антифроду - правила, поддержке - история действий пользователя. На точечных интеграциях каждый новый потребитель добавляет связку, настройки и риски рассинхрона.
Второй признак: важна воспроизводимость. Ошиблись в логике начисления бонусов или изменили правила антифрода и хотите переиграть месяц событий заново. В очереди сообщение обычно исчезает после обработки, а в распределенном логе события сохраняются.
Ситуации, где Kafka и event streaming начинают окупаться:
Когда вы на этом этапе, лог становится не "еще одним транспортом", а общей памятью системы. Тогда стоимость внедрения часто окупается снижением связности и возможностью спокойно расти.
Переход обычно ломается не на Kafka, а на смыслах: что считать событием, кто его читает и как жить с изменениями формата. Если держать фокус на простых правилах, event streaming превращается в обычную инженерную практику.
Начните с событий, которые важны бизнесу как факты, а не как команды: "Заказ создан", "Оплата получена", "Заказ отменен".
Дальше договоритесь о языке. Одно событие = один факт. Название и поля должны исключать двусмысленность. Если "Оплата получена", то что именно считается оплатой: полная, частичная, авторизация? Лучше потратить час на словарь, чем потом месяц разбирать инциденты.
Порядок важен не везде, но там, где он критичен, его нужно защищать ключами. Например, по ключу order_id вы добиваетесь того, что события конкретного заказа читаются в правильной последовательности, даже при масштабировании.
Рабочий план пилота обычно выглядит так:
Ретеншн стоит выбирать осознанно. Недели часто хватает для отладки и повторной обработки. Месяцы нужны, если вы строите аналитику или хотите уметь переигрывать расчеты.
Отдельная тема - версионирование. События почти неизбежно меняются, и это нормально, если заранее заложены правила совместимости:
Представьте интернет-магазин, где заказ проходит через несколько стадий. В традиционной интеграции каждый сервис дергает следующий, и со временем это превращается в цепочку зависимостей: поменяли один шаг - нужно трогать многих.
В event streaming логика проще: есть поток событий заказа, а сервисы подписываются на то, что им нужно. Так Kafka и event streaming часто становятся основой, когда вокруг заказа появляется много "слушателей".
Жизненный цикл заказа в виде событий (каждое событие - факт, который уже случился): заказ создан, заказ оплачен, заказ собран, заказ отправлен, заказ доставлен, заказ возвращен.
Дальше каждый потребитель берет события из лога и делает свою работу: склад, доставка, бухгалтерия, уведомления, аналитика. Это разные команды и разные темпы изменений, и именно здесь логовый подход начинает выигрывать.
Главный плюс распределенного лога: вы можете подключить нового потребителя без переделки старых сервисов. Например, вы решили добавить антифрод или программу лояльности. Вместо того чтобы встраивать вызовы во все места, новый сервис читает события "заказ оплачен" и "заказ возвращен" и строит свою логику, не ломая остальные.
Еще один практичный сценарий - переобработка истории. Допустим, вы нашли ошибку в расчете скидок. Если события хранятся в логе, можно поднять новую версию сервиса цен, заново проиграть события за период и пересчитать итог (или выпустить корректирующие события), не собирая данные по кускам из разных баз.
При этом очереди никуда не исчезают. Для тяжелых действий, которые нужно выполнить как задачу (сгенерировать PDF-счет, обработать изображения, отправить пакет запросов во внешнюю службу), удобнее держать отдельную очередь задач для воркеров. Так вы не перегружаете поток событий и проще контролируете повторы и лимиты.
Проблемы в event-driven подходе редко начинаются с технологий. Обычно ошибки появляются из-за того, как команда формулирует события, что в них кладет и какие ожидания переносит из мира баз данных и классических интеграций.
Самая частая путаница - смешивать события и команды. Команда звучит как просьба: "сделай скидку", "отправь письмо". Событие фиксирует факт: "скидка применена", "письмо отправлено", "заказ оплачен". Если в поток попадают команды, сервисы становятся зависимыми друг от друга: кто-то должен выполнить просьбу прямо сейчас, в нужном порядке, без права на задержку.
Вторая ловушка - неправильный размер и смысл событий. Иногда их слишком много, и тогда потребителям трудно разобраться, а хранение и обработка дорожают. Иногда события слишком крупные (например, вся карточка заказа целиком), и они тянут за собой лишние поля, лишние изменения и лишние риски. Хорошее событие отвечает на простой вопрос: что произошло и зачем это тем, кто слушает.
Третья боль - версии и схемы. Без дисциплины изменения ломают потребителей тихо и внезапно. Простое правило: добавлять поля обычно безопаснее, чем менять смысл существующих или удалять их.
Четвертая ловушка - ждать транзакций "как в базе" и строить хрупкие цепочки. В распределенной системе события приходят с задержкой, могут дублироваться и приходить не в том порядке, который вы ожидали. Если архитектура держится на предположении "все всегда сразу согласовано", она будет ломаться.
Отдельный класс ошибок связан с безопасностью данных. Часто в события по привычке кладут персональные данные, хотя потребителям нужен только идентификатор или агрегат. Чем больше лишнего в распределенном логе, тем сложнее доступы, аудит и сроки хранения.
Наконец, многие забывают про повторную обработку и идемпотентность. В Kafka и event streaming это не редкий крайний случай, а обычный режим эксплуатации.
Короткая самопроверка:
Если вы выбираете между обычной очередью сообщений и логовым подходом (как в Kafka и event streaming), начните с нескольких вопросов. Они быстро показывают, станет ли событийная архитектура опорой системы или добавит лишнюю сложность.
Если на 3 и более вопросов ответ "да", логовый подход обычно начинает окупаться. Если почти везде "нет", чаще всего достаточно простой очереди.
Еще один тест на реальности: представьте, что через месяц вы нашли ошибку в расчете скидки и хотите пересчитать ее для всех заказов за квартал. Если это звучит как ручная боль, вам пригодятся лог и возможность воспроизведения событий.
Самый надежный способ начать - не трогать весь продукт, а выбрать небольшой кусок, где вы точно понимаете входы и выходы. Частая ошибка: попытаться сразу перевести все интеграции на Kafka и утонуть в договоренностях.
Выберите 1-2 процесса, которые уже "болят": много ручных синхронизаций, несколько систем спорят о статусе, или постоянно нужно подключать новых потребителей (аналитика, уведомления, антифрод). Для старта достаточно 5-15 событий.
Соберите прототип: один поток событий и один потребитель. Например, OrderPaid и потребитель, который отправляет чек или пуш. Это быстро отвечает на базовые вопросы: как делать повторы, что происходит при сбое потребителя, как вы наблюдаете поток.
Если вы параллельно быстро собираете прототип продукта, удобно зафиксировать список событий и контракты заранее, а затем реализовать минимальный сервис и UI. В TakProsto (takprosto.ai) это часто делают в planning mode: сначала описывают события и границы, а потом уже поднимают реализацию и проверяют, что поток реально читается и переживает сбои.
Лучший способ понять возможности ТакПросто — попробовать самому.