Разбираем, как «утекают» абстракции фреймворков при росте нагрузки: где появляются узкие места, как их выявлять и что менять в архитектуре.
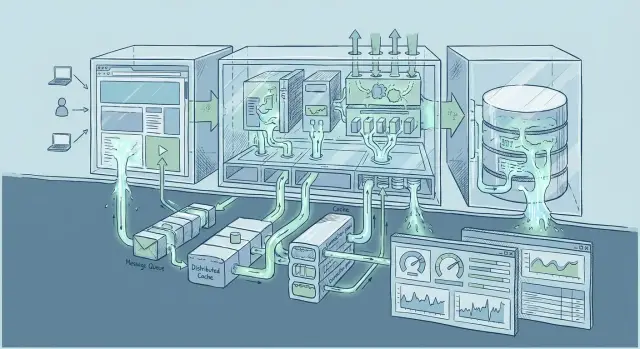
«Утечка абстракции» — это момент, когда удобный слой (фреймворк, библиотека, ORM, «автоматические» ретраи) перестаёт скрывать детали и внезапно заставляет разбираться с тем, что было «под капотом». До определённого момента абстракция помогает двигаться быстрее. После — её скрытые допущения становятся вашими инцидентами.
Абстракция обещает: «Думай о задачах бизнеса, а не о сетевых таймаутах, блокировках в БД и очередях». Но при росте нагрузки реальность начинает просачиваться: появляются ограничения на соединения, конкуренция за ресурсы, задержки сети, непредсказуемые пики. И вы вынуждены принимать решения на более низком уровне, чем планировали.
На небольшом трафике система прощает ошибки архитектуры:
Фреймворк в этот момент действительно кажется магическим: он сглаживает острые углы, потому что углы ещё не острые.
Когда трафик растёт, проблема редко выглядит как «всё стало в 10 раз медленнее». Чаще она проявляется как:
Чаще всего «вскрываются» места, где много скрытых допущений:
Ключевая мысль: при масштабе «удобно» и «предсказуемо» — не одно и то же. И чем больше система, тем важнее знать, какие детали ваша абстракция скрывает — и при каких условиях перестаёт скрывать.
Пока приложение небольшое, многие допущения фреймворка выглядят «естественными»: запросы приходят ровно, данные помещаются в память, сеть почти не ошибается, а редкие сценарии не встречаются неделями. При росте эти допущения перестают быть безопасными — и именно тут проявляются утечки абстракций.
При увеличении числа одновременных запросов становятся видны скрытые очереди: пул соединений к базе, лимиты потоков/воркеров, блокировки, синхронные вызовы. То, что «просто работало», внезапно начинает давать каскад задержек: один медленный ресурс тормозит всех.
С ростом данных меняется стоимость привычных операций. Поиск, сортировка, пагинация, подсчёты — всё это может перейти из «мгновенно» в «секунды», если запросы опирались на неудачные индексы или делали лишние выборки. Кэши тоже меняют характер: промахи становятся дороже, прогрев — заметнее, а объём «горячих» данных может не помещаться в памяти.
Когда появляется больше интеграций, сеть перестаёт быть «прозрачной». Добавляются таймауты, ретраи, частичные отказы, разные версии API. Абстракция «вызов функции» превращается в цепочку удалённых вызовов, где важны лимиты, дедлайны и обратное давление.
На большом трафике редкие ветки становятся ежедневными: необычные входные данные, крайние значения, нестандартные роли пользователей. Вылезают проблемы с форматами данных, миграциями, правами доступа и обработкой ошибок — то, что не попадало в тесты при малом масштабе.
ORM делает работу с базой данных «похожей на работу с объектами», и на малых объёмах это ощущается как чистая победа. Но при росте нагрузки скрытые решения ORM начинают определять стоимость каждого запроса — и вы внезапно платите временем, блокировками и перегревом базы.
Классическая утечка абстракции — N+1: вы загрузили список сущностей, а затем для каждой ORM «незаметно» добирает связанные данные отдельным запросом. На тестовом наборе это 11 запросов и терпимо, на проде — тысячи запросов, очередь в пуле соединений и рост латентности.
Похожая проблема — каскадные загрузки (eager/lazy), когда одно «удобное» обращение к полю приводит к серии JOIN’ов или дополнительных SELECT’ов. В итоге один экран приложения превращается в непредсказуемый запросный шторм.
ORM упрощает транзакции, но легко сделать их слишком широкими: открыть транзакцию, выполнить несколько запросов, пройти бизнес-логику, сходить во внешний сервис — и только потом commit. Под нагрузкой это означает блокировки строк/таблиц, рост конфликтов, «залипание» очереди запросов и каскадные таймауты.
Практика: держите транзакции максимально короткими, отделяйте чтение от записи, не смешивайте внутри транзакции сетевые вызовы.
ORM часто генерирует SQL, который «выглядит нормально», но плохо использует индексы: функции в WHERE, неудачный порядок условий, лишние JOIN’ы. Без привычки смотреть план (EXPLAIN) можно месяцами лечить симптомы на уровне приложения, когда корень — в неправильном индексе или в запросе, который не селективен.
На масштабе ломается наивная пагинация OFFSET/LIMIT: чем дальше страница, тем дороже запрос. Сортировки по неиндексированным полям превращают базу в «сортировочную машину», а фильтры по тексту/JSON без продуманной структуры дают полный скан.
Для массовых операций полезны: keyset-пагинация, явный выбор полей (не SELECT *), батчи для вставок/обновлений и отдельные запросы под отчётные сценарии — даже если это немного «выходит за рамки» ORM.
Фреймворк часто делает сеть «невидимой»: отправили запрос — получили ответ. Под нагрузкой сеть перестаёт быть прозрачной, и абстракции начинают протекать: у каждого вызова появляются ожидания, очереди, повторные попытки и неожиданные блокировки.
Даже если база данных справляется, приложение может упереться в пул соединений. Когда активных запросов больше, чем соединений, новые операции не «работают медленнее» — они встают в очередь ожидания.
Симптомы: скачки времени ответа без роста CPU, таймауты на уровне приложения, «случайные» ошибки при пиках. Важно различать таймаут запроса к БД и таймаут ожидания соединения в пуле — это разные причины и разные решения (увеличить пул, оптимизировать запросы, уменьшить конкуренцию, ввести лимиты на параллелизм).
Keep-alive экономит время на установке соединения, но при неправильной настройке даёт «зависшие» сокеты и долгие ожидания. Таймауты тоже должны быть многослойными: отдельный таймаут на установку соединения, на чтение ответа и общий дедлайн.
Ретраи добавляют устойчивости, но легко превращаются в мультипликатор нагрузки: один сбой → 3 повтора × 1000 запросов = внезапный шторм. Правила: ретраить только идемпотентные операции, добавлять экспоненциальную паузу и джиттер, ограничивать число попыток и всегда иметь общий дедлайн.
Внешние сервисы отвечают не только «быстро/медленно», а с длинным хвостом задержек. Среднее время может выглядеть нормально, но p95/p99 растут — и именно они создают очереди в потоках, воркерах и пулах.
Если есть rate limit, нужна деградация: кэш, очереди, «мягкие» ошибки, частичные ответы. Иначе приложение будет тратить ресурсы на заведомо обречённые вызовы, ухудшая ситуацию для остальных пользователей.
Когда система небольшая, формат данных кажется деталью: «передаём JSON и всё». Под нагрузкой именно (де)сериализация часто становится незаметным потребителем CPU, памяти и времени ответа — и абстракции фреймворка перестают «скрывать» цену.
JSON удобен, но дорог: парсинг текста, преобразование строк, частые аллокации и создание промежуточных объектов. На малых объёмах это не видно, но при росте количества запросов или размеров ответов стоимость умножается.
Бинарные форматы (например, protobuf) обычно быстрее и компактнее, но требуют схем, версионирования и более строгой дисциплины контрактов. Это обмен: меньше CPU/сети — больше внимания к совместимости.
Отдельная проблема — большие payload. «Просто добавить поле» в ответ кажется безопасным, пока этот ответ не начнёт весить сотни килобайт и не станет повторяться тысячи раз в минуту.
Многие фреймворки автоматически валидируют вход, преобразуют DTO в доменные модели и обратно. Каждый такой шаг может:
В итоге вы платите не только за бизнес-логику, но и за «красоту» слоя моделей.
Частая утечка абстракции: фреймворк «удобно» собирает весь запрос/ответ в памяти. Для больших файлов, длинных списков или отчётов это приводит к скачкам потребления памяти и паузам сборщика мусора.
Если сценарий позволяет, выбирайте стриминг (постраничная выдача, chunked-ответ, чтение/запись потоками), чтобы обрабатывать данные по частям.
Под нагрузкой важно не только ускоряться, но и ограничивать ущерб:
Эти меры делают систему предсказуемее: даже если клиент ошибся (или злоупотребляет), сервер не уйдёт в перерасход CPU и памяти из‑за одной слишком «тяжёлой» сериализации.
Кэш часто выглядит как «быстрая кнопка»: добавили Redis или CDN — и нагрузка исчезла. На практике кэш ускоряет только то, что уже хорошо понимаете. Если база данных медленная из‑за неверных запросов, если API нестабильно, если в приложении гонки и блокировки — кэш может лишь замаскировать проблему, а при пике сделать сбой более резким.
Кэш полезен, когда:
Если же обновления частые или требования к актуальности жёсткие, кэш начинает «протекать»: появляются устаревшие значения, сложные правила инвалидации и неожиданные пики нагрузки.
Хороший кэш начинается с ключей. Ключ должен однозначно кодировать контекст: версию схемы/формата, язык, права доступа, параметры запроса. Иначе вы получите неправильные данные «из чужого запроса».
TTL (время жизни) — не универсальное лекарство. Слишком короткий TTL ведёт к постоянным промахам и нагрузке на источник данных; слишком длинный — к устареванию. Инвалидация «по событию» точнее, но требует дисциплины: любое место, которое меняет данные, должно уметь сбрасывать связанные ключи.
Отдельная боль — шторм кэша: когда множество ключей истекает одновременно (или кэш очищен), и тысячи запросов одновременно идут в базу.
CDN хорошо снимает статические и публичные ответы, но плохо подходит для персонализированного контента. Кэш на уровне приложения гибче (можно кэшировать результаты вычислений), но требует контроля памяти и конкурентности. Кэш на стороне БД (план/страницы) помогает «сам по себе», однако не отменяет необходимость оптимизации запросов.
Чтобы избежать stampede, используйте:
Кэш ускоряет систему, но добавляет новые режимы отказа. Его нужно проектировать как часть архитектуры, а не как пластырь поверх боли.
Очередь часто выглядит как простой рычаг: «вынесем тяжёлое в background — и всё полетит». На небольших объёмах так и бывает. Но при росте абстракция очереди начинает «протекать»: всплывают задержки, дубли, перекосы по приоритетам и пределы инфраструктуры.
Правильная роль очереди — сгладить всплески и отделить некритичные действия от пользовательского запроса. Например: отправка писем, генерация отчётов, пересчёт статистики, синхронизация с внешними сервисами.
Но очередь не ускоряет «математику» сама по себе. Она лишь переносит работу в другое место и время. Если потребители (воркеры) в сумме обрабатывают меньше, чем вы производите, вы получите растущую задержку, а пользователи — «вроде всё приняли», но результат появляется через часы.
Под нагрузкой дубли — норма, а не исключение: ретраи, таймауты, повторная доставка, падение воркера после выполнения, но до подтверждения.
Поэтому задача должна быть идемпотентной: повторный запуск не должен ломать данные и создавать лишние побочные эффекты. Практичные приёмы: уникальные ключи операции, таблица выполненных задач (dedup), условные обновления («обнови, если версия совпадает»), «вставь, если не существует».
Когда очередь раздувается, «магия» заканчивается и нужен контроль потока:
Важно измерять не только длину очереди, но и «возраст» сообщений (сколько ждут до старта).
Синхронно оставляйте то, без чего нельзя завершить запрос корректно (проверка прав, запись заказа, резервирование). Асинхронно — всё, что можно «догнать» позже: уведомления, аналитика, обогащение данных.
Ключевой критерий: можно ли безопасно показать пользователю промежуточный статус («принято в обработку») и гарантировать завершение через надёжную цепочку ретраев и мониторинга.
Когда нагрузка растёт, «фреймворк сам разрулит» перестаёт быть правдой: у рантайма есть конкретные физические границы — ядра CPU, пропускная способность памяти, лимиты планировщика и стоимость сборки мусора. Абстракции скрывают эти детали ровно до момента, когда вы упираетесь в них одновременно.
Пулы создают иллюзию бесконечной параллельности: вы «просто» запускаете задачи, а дальше всё работает. На масштабе проявляется обратная сторона — очередь задач растёт, латентность скачет, а воркеры начинают конкурировать за:
Симптом: средняя загрузка CPU высокая, но полезная работа не увеличивается; p95/p99 резко хуже среднего.
Сборщик мусора и аллокатор незаметны, пока объёмы небольшие. Под нагрузкой любые «мелочи» — лишние временные объекты, сериализация в промежуточные структуры, копирование строк — превращаются в постоянный шум. Итог: чаще запускается GC, появляются паузы (иногда краткие, но частые), а задержки запросов становятся рваными.
Практический маркер: рост времени в GC, увеличение RSS/heap, «пила» по памяти и деградация p99 при стабильном трафике.
Даже если фреймворк обещает асинхронность, один блокирующий вызов в горячем пути (файловая система, DNS, внешний HTTP, медленный драйвер) может остановить целый пул. На малой нагрузке это незаметно, на большой — превращается в цепочку: блокировка → очередь → таймауты → ретраи → ещё больше блокировок.
Чтобы поймать утечки абстракций, нужны не догадки, а профили:
Если профили показывают, что значимая доля времени уходит в GC, синхронизацию или обвязку фреймворка, это прямой сигнал: пора упрощать горячий путь и возвращать контроль над ресурсами приложению.
Фреймворки часто создают ощущение «страховки»: если сервис упал или база ответила медленно, «оно само повторит запрос» или «как‑то переживёт пик». На небольших объёмах это может выглядеть правдой. Но при росте нагрузки скрытые решения «по умолчанию» превращаются в ускоритель аварии: ретраи множат трафик, очереди растут, потоки ждут, а сбой из одной зависимости разъезжается по всей системе.
Автоматические механизмы полезны, пока вы явно контролируете границы: сколько запросов можно выполнять одновременно, сколько времени ждать, что считать ошибкой и когда прекращать попытки. Без этих границ система ведёт себя как «слишком вежливый» клиент: терпеливо ждёт и пробует снова, пока не закончится память, соединения или терпение пользователей.
Circuit breaker нужен, чтобы быстро перестать стучаться в явно больную зависимость и дать ей восстановиться.
Bulkheads (переборки) — чтобы проблема в одном компоненте не «затопила» остальные: отдельные пулы соединений, отдельные лимиты конкурентности, отдельные очереди.
Лимиты должны сопровождаться деградацией функциональности: временно отключить второстепенные функции (поиск, рекомендации, отчёты), вернуть упрощённый ответ, показать кэшированную версию. Важно заранее решить, что именно можно «урезать», а что нельзя.
Хорошее правило: таймауты короче, чем ожидание пользователя, и согласованы между слоями (клиент → сервис → база). Ретраи — только для безопасных операций, с джиттером и ограничением попыток; лучше один контролируемый повтор, чем пять синхронных, которые добьют и без того перегруженную систему.
Команде достаточно 4–5 регулярных упражнений:
Такие проверки превращают отказоустойчивость из веры в поведение «по умолчанию» в управляемую характеристику системы.
Когда абстракция «протекает», проблема редко выглядит как «виноват фреймворк». Чаще вы видите странные таймауты, скачки задержек или рост ошибок — и без наблюдаемости это превращается в гадание. Хорошая новость: утечки почти всегда оставляют измеримые следы.
Не ограничивайтесь средними значениями. Для пользовательского опыта важнее хвосты распределения:
Когда p99 растёт, а среднее «в порядке», это часто означает скрытую очередь: пул соединений, блокировки, синхронные вызовы, сериализация.
Распределённый трейсинг помогает увидеть, где именно «удобный вызов» превращается в цепочку дорогих операций. Важно:
Логи должны быть структурированными (JSON-поля), чтобы фильтровать по request_id, пользователю, endpoint, ошибке. Отдельно считайте объём и цену логов: под нагрузкой «безобидный» debug может съесть I/O и бюджет.
Алёрт должен отвечать на вопрос «пользователям плохо?». Задайте SLO (например, 99% запросов быстрее X и ошибок меньше Y) и алёртите по нарушению бюджета ошибок, а не по единичным всплескам. Пороговые алёрты по насыщению (очереди, пул соединений, память) ставьте как ранние сигналы, но с подавлением шума и чёткой приоритизацией. Сводный чек-лист можно держать в /runbook/observability.
Когда «протекла» абстракция, хочется срочно переписать половину сервиса. Лучше действовать как инженер-диагност: сначала измерить, затем сузить гипотезы, и только потом менять.
Начните с формулировки цели: что именно должно выдержать приложение — RPS, количество параллельных пользователей, время ответа для ключевых сценариев, скорость обработки очереди.
Соберите профиль трафика, близкий к реальности: соотношение чтение/запись, «тяжёлые» эндпоинты, распределение по времени, размеры payload. Заранее задайте критерии успеха: p95/p99 латентности, допустимый процент ошибок, потолок CPU/памяти, стабильность при прогреве кэша.
Ищите не «всё сразу», а главный ограничитель. Обычно он один: база, пул соединений, сериализация, блокировки, GC, внешние API.
Выберите один показатель, который улучшаете, и один способ проверки. После изменения обязательно фиксируйте эффект тем же тестом и тем же трафиком — иначе легко принять шум за прогресс. Если прироста нет, откатывайте и возвращайтесь к гипотезам.
Выкатывайте оптимизации постепенно: 1–5% трафика на новую версию, сравнение метрик со «старой» (латентность, ошибки, saturation ресурсов). Держите быстрый план отката.
Добавьте производительные «сигналки» в CI/CD: бюджет латентности, алерты на рост p99 и на увеличение количества ретраев/таймаутов.
Записывайте решения коротко и предметно: симптом → причина → как измеряли → что изменили → какой эффект получили → какие риски остались. Это снижает повторение ошибок и помогает выбирать правильный уровень абстракции в следующих задачах.
Небольшая ремарка для команд, которые активно ускоряют разработку через LLM-инструменты: быстрый старт (особенно в формате vibe-coding) не отменяет инженерных границ под нагрузкой. Например, в TakProsto.AI можно собрать веб/серверное/мобильное приложение через чат (React на фронте, Go + PostgreSQL на бэкенде, Flutter для мобайла) — и именно поэтому полезно заранее «вшивать» в проект базовые лимиты, таймауты, ретраи, метрики и сценарии деградации, чтобы абстракции не начали протекать в самый неподходящий момент.
Рост нагрузки редко требует «переписывать всё». Чаще он заставляет честно ответить на вопрос: какие части системы можно оставлять под «зонтиком» фреймворка, а где нужна более явная инженерия.
Оставайтесь на стандартных абстракциях, если узкие места не в «горячем пути» и их можно закрыть практиками:
Это выгодно, когда важнее скорость разработки и единые правила, чем выжимание последней миллисекунды.
Выносите части системы из общих абстракций, если:
Практичный подход: сначала отделите модуль внутри монолита (чёткий интерфейс), и только затем — сервис, если выигрыш подтверждён измерениями.
Обычно явных решений требуют три зоны: база данных (пулы, транзакции, конкретные запросы), кэш (инвалидация, TTL, защита от stampede) и очередь (идемпотентность, дедупликация, ретраи, DLQ). Здесь «по умолчанию» часто работает до первой серьёзной нагрузки.
Смотрите связанные разборы и чек-листы в /blog. Если вы выбираете между «дожать текущий стек» и выделять отдельные компоненты, ориентиры по подходам и стоимости можно сравнить на /pricing.
Лучший способ понять возможности ТакПросто — попробовать самому.