Разбираем, как выбор бэкенд‑фреймворка влияет на структуру проекта, архитектурные решения, тестирование и процессы команды: от онбординга до code review.
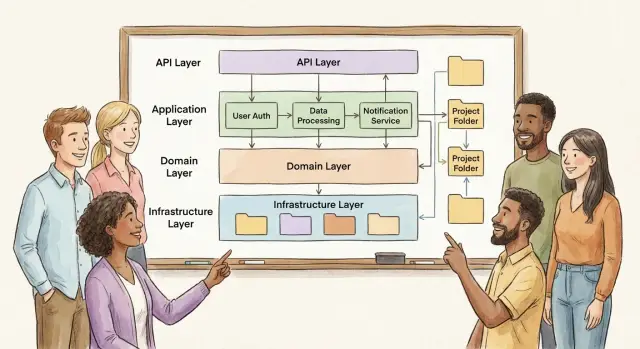
Бэкенд‑фреймворк — это не просто набор библиотек «чтобы поднять сервер». По сути, он предлагает готовый способ собирать приложение: как принимать запросы, где хранить бизнес‑логику, как подключать зависимости, как обрабатывать ошибки и как наблюдать всё это в продакшене.
Практически любой фреймворк закрывает три группы потребностей:
Доставка запроса до кода: HTTP, маршрутизация, сериализация, валидация.
Организация исполнения: жизненный цикл запроса, middleware/фильтры, транзакции, обработка ошибок.
Интеграции: работа с БД, очередями, внешними API, кешем.
Важно, что фреймворк делает это «по умолчанию»: даже если команда не договорилась о правилах, они всё равно появятся — просто будут правилами выбранного инструмента.
Когда говорят про организацию кода, часто имеют в виду структуру папок. Но сильнее фреймворк влияет на «невидимое»: где проходит граница между контроллером и сервисом, кто отвечает за валидацию, куда складываются DTO/схемы, где должна жить работа с БД.
Если эти границы совпадают с моделью мышления команды, код получается предсказуемым. Если нет — появляются компромиссы: бизнес‑логика «просачивается» в контроллеры, инфраструктурные детали тянутся в домен, а тесты начинают зависеть от веб‑слоя.
Фреймворк задаёт ежедневные привычки через конкретные механики:
На поддержке продукта эти решения проявляются особенно заметно: скорость онбординга, качество code review (легко ли понять, «куда положить» новый код), стабильность тестов и стоимость изменений.
Хороший признак — когда большинство технических дискуссий про код сводится к смыслу задачи, а не к поиску того, «как принято в этом проекте».
Фреймворк почти всегда предлагает «правильный путь»: где лежат контроллеры, как именуются модули, как устроены миграции, как писать обработчики ошибок. Это экономит время на старте, но со временем превращается в ежедневный выбор — следовать конвенциям или отступать ради конкретной задачи.
Команде обычно проще договориться там, где фреймворк уже принял решение за вас. Если структура папок и типовые сценарии (CRUD, валидация, обработка запросов) делаются «по умолчанию», меньше вариантов реализации — меньше поводов спорить.
При этом гибкость тоже нужна: продуктовые требования редко укладываются в учебник. Практичный баланс — использовать конвенции как базовый вариант, а отклонения оформлять как осознанное решение с понятными критериями (например: «если интеграция требует очередей и саг — выносим в отдельный модуль и документируем границу»).
Чем жёстче фреймворк, тем дороже становятся нестандартные решения. Они могут выглядеть как «борьба» с инструментом: обходные хуки, кастомные контейнеры, переопределение жизненного цикла. В итоге команда тратит силы не на бизнес‑логику, а на поддержку исключений.
С другой стороны, слишком свободный фреймворк перекладывает архитектурные договорённости на людей: каждый пишет «как привык», и проект быстро теряет единообразие.
Конвенции снижают количество обсуждений в ревью: меньше комментариев про стиль, расположение файлов, именование, обработку ошибок. Ревьюер смотрит на смысл изменений, а не на форму.
Но чрезмерные конвенции могут замедлять продуктовую скорость, если любое отклонение требует сложного согласования или приводит к громоздким «правильным» решениям. Если команда регулярно видит в ревью фразы вроде «так по гайду, но неудобно», это сигнал пересмотреть правила: часть конвенций можно смягчить, часть — заменить шаблонами и автоматическими проверками.
Фреймворк почти всегда подталкивает к «естественной» структуре: где-то это контроллеры и middleware, где-то — обработчики команд/запросов. Смысл один — отделить точки входа от бизнес‑правил и от работы с инфраструктурой.
API / контроллеры — принимают HTTP/сообщения, валидируют формат, извлекают параметры, вызывают прикладной слой. Здесь уместны: авторизация на уровне маршрута, маппинг DTO, коды ответов, обработка ошибок.
Сервисы (прикладной слой) — координируют сценарии: «создать заказ», «пересчитать лимит», «отправить уведомление». Это обычно главный потребитель зависимостей: репозитории, клиенты внешних API, очередь.
Домен — правила и инварианты: что считается корректным состоянием сущности, какие переходы допустимы, как считается итоговая стоимость. Чем сильнее фреймворк «тянет» аннотации/декораторы в модель, тем выше риск размазать доменную логику по контроллерам и ORM‑моделям.
Доступ к данным (репозитории/DAO) — детали хранения: SQL/ORM, транзакции, индексы, миграции. Хорошая граница: сервисы формулируют намерение («найти активные подписки»), а слой данных решает, как именно это сделать.
Модуль — это не папка «для красоты», а контракт.
Простое правило: зависимости направлены снаружи внутрь (API → сервисы → домен), а инфраструктура (БД, внешние клиенты) подключается через интерфейсы/порты. Если фреймворк активно использует DI‑контейнер, он облегчает эту схему, но может и соблазнить «протянуть» что угодно куда угодно — поэтому нужны явные ограничения.
Если фреймворк предоставляет удобные хуки (валидация, фильтры, interceptors), часть логики неизбежно мигрирует в «пограничные» места. Командная договорённость должна удерживать там только техническое: формат, безопасность, наблюдаемость. Бизнес‑правила — в домене/сервисах.
Фреймворк почти всегда подталкивает к «каноничной» раскладке папок — и это хорошо, пока команда осознанно решает, что принять как стандарт, а что адаптировать под продукт.
Главная цель структуры репозитория — ускорять поиск кода и снижать когнитивную нагрузку: новый файл должен «сам проситься» в понятное место.
Есть два популярных подхода.
По слоям (controllers/services/repositories) удобно на старте: всё типизировано по ролям. Минус — бизнес‑контекст размазывается по папкам, и одна фича «разъезжается» на 5–7 мест.
По фичам (modules/users, modules/billing) обычно лучше масштабируется для команды: всё, что относится к домену, рядом. Внутри фичи можно оставить слои, но локально:
Если фреймворк навязывает слой (например, отдельную папку для контроллеров), можно сохранить совместимость, но группировать по доменам внутри слоя: controllers/billing, controllers/users.
Соглашения об именах важнее «идеальной» структуры. Хорошие правила: одинаковые суффиксы (UserService, BillingRepository), единый стиль путей (kebab-case или snake_case), запрет на аббревиатуры без необходимости.
Отдельно стоит решить, где живут конфиги:
Так проще понять: «здесь настройки», а «здесь логика их применения».
Минимальный набор правил, который стоит записать:
Такие договорённости экономят часы на ревью и делают навигацию по репозиторию предсказуемой.
DI (dependency injection) редко ощущается как «отдельная фича» фреймворка — он просто задаёт способ, как в проекте появляются и связываются объекты. Контейнер зависимостей меняет привычки: вместо того чтобы создавать всё руками, команда описывает правила сборки приложения.
Когда зависимости объявляются через конструктор (или явные параметры), компоненты становятся менее связанными: сервис не «знает», как именно создаётся репозиторий или клиент внешнего API.
Практический плюс — тесты. Вы подменяете реализацию на фейк/мок без трюков с глобальными синглтонами.
Но важно помнить: контейнер — это инфраструктура. Если бизнес‑логика начинает зависеть от него напрямую (например, «достать сервис из контейнера внутри метода»), тестируемость обычно ухудшается.
DI оправдан там, где есть вариативность или инфраструктура: доступ к БД, кеш, очереди, внешние клиенты, логирование.
Явные зависимости часто проще для маленьких модулей и чистых функций: утилиты, преобразования данных, доменные правила. Если компонент не имеет состояния и не требует настройки, контейнер может быть избыточным.
Хороший паттерн: интерфейс рядом с доменом (что нужно), реализация — в инфраструктурном слое (как сделано). Тогда замена хранилища или транспорта не приводит к переписыванию бизнес‑кода.
«Сервис‑бог» появляется, когда DI облегчает добавление ещё одной зависимости, и класс разрастается до 10–15 конструкторных параметров. Это сигнал дробить ответственность: выделять отдельные use‑case/handler’ы, фасады для внешних систем, небольшие доменные сервисы.
Циклические зависимости — частый эффект «удобных» автосвязок. Обычно лечится пересмотром границ модулей: выносите общий контракт в отдельный пакет, разделяйте чтение/запись (CQRS-lite) или вводите событийный обмен вместо прямых вызовов.
Middleware (а в некоторых фреймворках — фильтры, интерсепторы, хуки) быстро становится «магистралью», по которой команда тянет общие требования: логирование, аутентификацию, лимиты, метрики, обработку ошибок.
Это удобно: одна точка подключения — и правило действует везде. Но именно здесь чаще всего появляется скрытая сложность и «магия», из‑за которой код начинает вести себя неожиданно.
Хорошее правило: в middleware живёт инфраструктура, а не бизнес‑решения.
Проблема начинается, когда middleware становится длинной цепочкой из 10–15 звеньев, а важные решения принимаются «между делом». Чтобы не потерять управляемость:
Держите middleware тонкими: собирают контекст, валидируют инварианты протокола, прокидывают управление дальше.
Всё, что влияет на бизнес‑результат, оформляйте как явные шаги в контроллерах/хендлерах или в доменных сервисах.
Документируйте порядок выполнения и точки расширения (например, короткой страницей в /docs или в CONTRIBUTING.md), чтобы на code review было понятно, где искать причину поведения.
Итог: middleware помогает стандартизировать кросс‑срезные требования, но команда должна постоянно проверять, не прячутся ли там бизнес‑решения, которые должны быть видны в основном потоке кода.
Фреймворк влияет не только на папки и слои, но и на то, где живут настройки и как система «рассказывает» о себе в продакшене. Если конфигурация и наблюдаемость не встроены в привычный путь разработки, команда быстро скатывается в «магические» переменные, разрозненные логи и ручной поиск проблем.
Хороший фреймворк задаёт стандарт: конфигурация читается централизованно и типизируется (или хотя бы валидируется) при старте приложения. Обычно используются три источника:
Ключевой момент — иметь единый модуль/пакет конфигурации, который выдаёт «готовые» настройки остальным частям кода, а не раздаёт чтение env по всему проекту.
Практика, которую часто закрепляет фреймворк: разделение настроек по окружениям (dev/stage/prod) и запрет небезопасных значений в продакшене. Например: выключенные debug‑страницы, строгие CORS‑правила, обязательные секреты, безопасные значения таймаутов.
Фреймворки нередко дают готовые интеграции с логгерами, Prometheus/OpenTelemetry и трейсингом запросов. Это важно структурно: появляется «место», где подключаются middleware/хуки, и команда не размазывает телеметрию по обработчикам.
Минимальный стандарт, который стоит зафиксировать сразу:
Когда фреймворк делает это «по умолчанию», наблюдаемость становится частью структуры проекта — и поддерживать её проще даже при росте команды.
Фреймворк почти всегда «подсказывает», какие тесты писать и как их запускать. Это удобно: меньше споров в команде, быстрее старт.
Но за удобство часто платят связанностью тестов с внутренностями фреймворка и более дорогими интеграционными проверками.
Обычно проще всего становятся интеграционные тесты: поднять приложение в тестовом режиме, прогнать HTTP‑запросы, проверить ответы и работу middleware, сериализацию, валидацию.
Unit‑тесты тоже возможны, но иногда требуют дополнительных абстракций: если бизнес‑логика живёт внутри контроллеров/хендлеров и сильно завязана на контекст запроса, писать изолированные проверки становится сложнее.
E2E‑тесты (через реальную БД, брокер, внешние сервисы) фреймворк может облегчать готовыми хелперами запуска, но они медленнее и более капризны к окружению.
Фреймворки часто предлагают:
Плюс: тесты читаются как сценарии, легко поднимать «почти прод» окружение.
Минус: фикстуры разрастаются и начинают скрывать важные детали (например, почему именно такие данные нужны). In‑memory реализации ускоряют тесты, но иногда дают ложное чувство безопасности: транзакции, индексы, изоляция и особенности SQL в памяти часто ведут себя не так, как в реальной БД.
Тестовые контейнеры (БД/кеш/брокер в Docker) повышают доверие к результатам, но требуют дисциплины: стабильные версии образов, быстрый прогрев, контроль времени выполнения.
Хрупкость появляется, когда тест проверяет детали реализации вместо поведения. Практичный ориентир: чем ближе тест к границе системы (HTTP, очередь, БД), тем больше он должен проверять контракт, а не внутреннюю структуру.
Хорошо работает разделение:
Тогда unit‑тесты покрывают правила, а интеграционные — склейку компонентов и конфигурацию.
Минимальный «скелет» покрытия обычно включает:
Если команда фиксирует эти правила в документации и шаблонах PR, тестирование перестаёт быть вкусовщиной и становится частью рабочего процесса.
Фреймворк незаметно «подкручивает» то, на что команда смотрит в ревью. Если он задаёт способ подключения зависимостей, структуру обработчиков и правила работы с ошибками, то именно эти места становятся главными источниками замечаний.
И наоборот: часть спорных решений уходит из обсуждений, потому что «так принято в этом стеке».
Хорошее ревью начинается до ревью: автоматические проверки должны снимать рутинные вопросы. Во фреймворках часто есть стандартные пресеты (или де‑факто наборы), которые команда фиксирует как базу.
Обычно договариваются о трёх уровнях:
Важно, что правила привязываются к структуре проекта: например, запрет прямого доступа к базе из контроллеров, ограничения на импорты между модулями, требования к именованию файлов, в которых фреймворк выполняет «магические» обнаружения.
Фреймворк упрощает чек‑лист: он может буквально повторять путь запроса. Типовой шаблон PR включает пункты «где добавлен middleware/валидация», «какие конфиги затронуты», «какие миграции/эндпоинты добавлены», «не нарушена ли структура модулей».
В ревью чаще всего всплывают вопросы не «как написать», а «как правильно встроить»: правильный жизненный цикл зависимостей в DI, корректные scope, единообразная обработка ошибок, соблюдение конвенций роутинга, отсутствие логики в слоях, которые фреймворк ожидает тонкими.
Фреймворки подталкивают к единым правилам API: валидация входа, схемы ответов, единые коды ошибок. Команда фиксирует, как версионируются эндпоинты, как помечаются изменения как breaking, и что считается совместимым.
В ревью это превращается в проверку: «не поменяли ли контракт незаметно» и «есть ли план миграции клиентов».
Фреймворк задаёт новичку «первую карту местности»: где искать обработчик запроса, как устроены зависимости, куда класть новую фичу и как она попадает в прод. Если структура проекта следует конвенциям фреймворка, онбординг ускоряется: человек узнаёт знакомые паттерны (routes/controllers/services, middleware, modules) и быстрее начинает вносить полезные изменения.
Хорошая практика — иметь короткий «путеводитель по запросу» прямо в репозитории: от входной точки (router) до доменной логики и доступа к данным. Новичку важно ответить на три вопроса: где добавлять endpoint, где бизнес‑правила, где интеграции.
Полезно закрепить это в документе формата /docs/request-flow.md и сослаться на него в README.
Чтобы решения не превращались в устные традиции, держите ADR (Architecture Decision Records): короткие заметки «что решили и почему». Это особенно важно, когда фреймворк допускает несколько равноценных подходов (например, как строить модули или где хранить DTO/схемы).
Минимальный набор:
/docs/adr/ с 5–15 записями о ключевых правилахCLI фреймворка и внутренние шаблоны — это способ зафиксировать стандарты без бесконечных замечаний на review. Генератор создаёт папки, заготовки тестов, зашитые соглашения по именованию и минимальную трассировку/логирование.
В этом же направлении работают и современные платформы для vibe‑кодинга. Например, TakProsto.AI помогает собирать веб‑, серверные и мобильные приложения через чат, а затем экспортировать исходники и продолжать развитие уже в репозитории. Практическая ценность здесь именно в «конвенциях по умолчанию»: вы быстрее получаете каркас модулей, типовую обработку ошибок, структуру слоёв и базовую наблюдаемость — а дальше фиксируете правила проекта в README/CONTRIBUTING и выравниваете командные практики.
Сделайте маршрут из 4 шагов: добавить простой endpoint → подключить валидацию/схемы → написать тест → внести изменение в доменную модель и миграции.
Такой путь помогает увидеть не только «как писать обработчики», но и как команда работает со структурой проекта на практике.
Рост обычно ломает не «архитектуру на диаграмме», а повседневные договорённости: куда класть код, как менять контракты, кто владеет модулем. Фреймворк может помогать масштабироваться, но он не отменяет необходимости пересматривать границы.
Большинство бэкенд‑фреймворков отлично чувствуют себя в монолите: единый запуск, единая конфигурация, единая модель наблюдаемости. Когда команда растёт, часто появляется модульный монолит: всё ещё один деплой, но код разделён на доменные модули с явными интерфейсами.
Переход к микросервисам обычно требует не «кнопки во фреймворке», а операционных возможностей: отдельные пайплайны, мониторинг, распределённые трассировки, управление схемами данных и контрактами.
Если фреймворк активно навязывает глобальное состояние, общие синглтоны, «магические» автосканирования — модульный монолит и тем более микросервисы будут даваться дороже.
Типичный анти‑паттерн роста — папка common/shared, куда попадает всё подряд: модели, утилиты, клиенты, исключения. Через полгода это становится серой зоной без владельца.
Практика, которая работает лучше: «общего» кода минимум, а повторяемость решается через явные контракты.
Когда пользователей и интеграций больше, «сломать и быстро починить» нельзя. Версионирование API становится частью структуры: отдельные контроллеры/роуты по версиям или совместимость на уровне схем.
С данными похожая история: миграции должны быть воспроизводимыми, обратимыми (где возможно) и безопасными для выката по этапам. Даже если фреймворк даёт удобные миграции, при росте понадобятся практики: двухфазные изменения схемы, совместимость старого и нового кода, фоновые переносы.
Если замечаете такие симптомы — структура уже мешает:
В этот момент полезнее всего не переписывать всё, а заново договориться о границах модулей и контрактах — и уже под них подстроить использование фреймворка.
Выбор бэкенд‑фреймворка — это не только про синтаксис и производительность. Он фиксирует «нормальный» способ писать код, тестировать, обсуждать изменения и поддерживать сервисы. Поэтому полезно оценивать фреймворк через призму ежедневных командных практик.
Сначала проверьте зрелость экосистемы: насколько легко закрываются типовые задачи (валидация, миграции БД, фоновые задачи, очереди, безопасность), есть ли поддерживаемые библиотеки и понятны ли их границы ответственности.
Документация важна не меньше: наличие официальных гайдов, «рекомендованных путей» и примеров реальных приложений снижает вариативность и экономит время на спорах.
Отдельно оцените тестовый контур: встроенные фикстуры, тестовый клиент, инструменты для интеграционных тестов и удобство моков.
Спросите себя, что фреймворк поощряет:
Также полезно понять, как он отражается на code review: легко ли заметить нарушение конвенций, насколько читаемы типовые изменения, можно ли автоматизировать часть проверок линтерами и генераторами.
Не выбирайте «в вакууме» — сделайте пилот на 1–2 недели. Измеряйте: скорость выполнения задач (lead time), количество дефектов после релиза, сложность поддержки (сколько контекста нужно, чтобы исправить баг), а также стабильность сборки и тестов.
Если вы рассматриваете альтернативы «классическому» программированию и хотите быстрее проверить архитектурные конвенции на практике, пилот можно сделать и на платформе vibe‑кодинга. В TakProsto.AI, например, можно собрать рабочий прототип (фронтенд на React, бэкенд на Go с PostgreSQL, мобильное приложение на Flutter), настроить деплой/хостинг, а затем экспортировать исходники и продолжить развитие уже в привычном процессе с ревью и тестами. Такой пилот хорошо показывает, какие соглашения вам нужны «по умолчанию», а какие придётся явно зафиксировать.
После выбора закрепите решения в коротком документе: структуру папок, правила модульности, стандарты тестов (что обязательно: unit/integration), подход к конфигурации и логированию, а также минимальные требования к PR. Этот чек‑лист лучше держать рядом с проектом (например, в /docs/engineering), чтобы он работал как опора для онбординга и ревью.
Лучший способ понять возможности ТакПросто — попробовать самому.