Разбираем, как ИИ подбирает технологический стек по ограничениям: масштаб, скорость, бюджет и навыки команды. Логика, шаги, примеры и типичные ошибки.
Технологический стек — это набор технологий и решений, из которых складывается продукт: как он работает «снаружи» (интерфейс), как устроен «внутри» (серверная логика), где и как хранятся данные, как всё разворачивается и поддерживается.
Важно понимать: «выбрать стек» — это не назвать пару модных инструментов. Это принять ряд конкретных решений, которые напрямую влияют на сроки, бюджет и риски.
Обычно в него попадают:
Потому что «одинаковый продукт» почти никогда не бывает одинаковым по условиям. Интернет‑магазин для локального бизнеса и маркетплейс на несколько стран выглядят похоже пользователю, но отличаются по нагрузке, требованиям к доступности, числу интеграций и скорости изменений. Поэтому и технологические решения могут быть разными — и оба варианта будут правильными в своём контексте.
Технология становится удачным выбором не потому, что о ней много говорят, а потому что она закрывает ограничения проекта: сроки запуска, компетенции команды, требования по безопасности, бюджет на поддержку, планы по росту.
Почти всегда приходится балансировать. Быстрый запуск MVP часто означает более простую архитектуру и меньший «запас прочности». Архитектура «на вырост» может замедлить разработку и увеличить стоимость владения.
Хороший стек — тот, где эти компромиссы осознаны, зафиксированы и подходят именно вашему проекту.
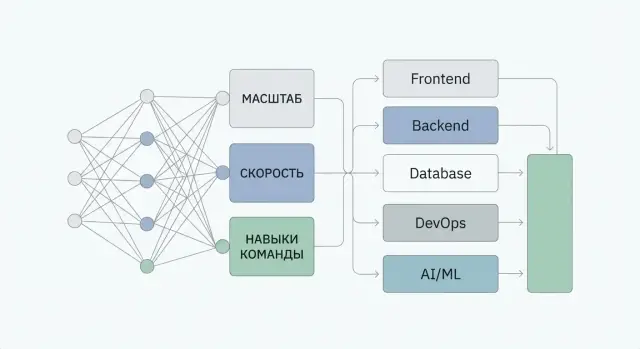
ИИ подбирает технологический стек не «из любимых технологий», а как задачу оптимизации под ограничения. Чем точнее вы опишете контекст, тем меньше будет случайных рекомендаций и тем легче проверить результат.
На практике это особенно заметно в продуктах, где разработка идёт через чат‑интерфейс: например, в TakProsto.AI вы фактически «формулируете требования словами», а система помогает быстро собрать прототип и опорный стек под реалии рынка РФ. Это не отменяет инженерных решений, но резко ускоряет первый цикл: уточнение требований → сборка MVP → проверка гипотез.
На практике ИИ собирает картину из четырех групп сигналов:
Полезный прием: просить ИИ сначала оформить ввод в виде анкеты и уточняющих вопросов. Это экономит время и снижает риск «подставить» неверные допущения.
Хороший результат — это не просто список технологий, а связанный набор артефактов:
Рекомендованный стек (язык, фреймворк, БД, кеш, очереди, хостинг, мониторинг).
Причины выбора: какие ограничения закрывает каждый компонент и какие компромиссы приняты.
Риски и “тонкие места”: где могут быть проблемы по найму, стоимости владения, масштабированию, поддержке.
Обычно удобно получать 2–3 сценария:
Так проще сравнивать и принимать решения, а не спорить вокруг единственного «правильного» ответа.
ИИ может предложить варианты и аргументацию, но не принимает финальное решение и не несет ответственности за последствия. Проверка на реальных ограничениях (прототип, нагрузочное тестирование, оценка затрат) остаётся за командой.
Когда ИИ «подбирает стек», он сопоставляет ограничения проекта с типовыми архитектурными подходами и оценивает риски: где вы упрётесь в потолок, что будет дорого поддерживать, а что — не пройти по требованиям.
Первая группа — ключевые пользовательские сценарии и бизнес‑функции. Для ИИ это ответ на вопрос «какие блоки системы вообще нужны»: личные кабинеты, платежи, загрузка файлов, поиск, рекомендации, чат, офлайн‑режим, интеграции с 1С и т. п.
Чем яснее сформулированы сценарии (кто, что делает, как часто, что считается успехом), тем точнее можно выбрать компоненты: например, нужен ли отдельный поисковый движок или хватит возможностей базы данных.
Дальше идут требования, которые «ломают» архитектуру сильнее всего:
Если эти параметры не заданы, ИИ будет вынужден гадать — и легко предложит либо слишком «тяжёлое», либо слишком хрупкое решение.
ИИ учитывает практику: что команда уже умеет, кого реально нанять, сколько времени есть на MVP и сколько — на поддержку после релиза. Один и тот же стек может быть «лучшим» на бумаге и провальным в компании, где некому его сопровождать.
Наконец, среда исполнения: облако или on‑premise, требования регулятора, корпоративные стандарты, существующая инфраструктура и обязательные интеграции.
В российском контуре это часто включает требования к размещению и обработке данных. Например, TakProsto.AI ориентируется на рынок РФ: работает на серверах в России, использует локализованные и open source LLM‑модели и не отправляет данные за пределы страны — и это сразу меняет «пространство допустимых вариантов» при выборе компонентов и поставщиков.
Пока продукт маленький, почти любой стек «держится на честном слове». Но как только появляется рост, нагрузка перестает быть абстракцией — она превращается в конкретные числа, которые ломают узкие места. ИИ в подборе стека начинает с попытки перевести ваши ожидания в измеримые параметры.
Обычно он уточняет (или аккуратно предполагает по типу продукта) несколько метрик: MAU/DAU, пиковые RPS, долю «тяжелых» операций (поиск, генерация отчетов), объем хранимых данных и темпы роста. Важно также распределение нагрузки: равномерно в течение дня или «залпами» (распродажи, старт уроков, открытие регистрации).
Эти входы превращаются в требования к компонентам: сколько одновременных соединений держит API, какой объем данных придется индексировать, сколько фоновых задач будет в очереди, и где возникнет конкуренция за ресурсы.
Если ожидается рост, ИИ почти всегда тянет архитектуру к горизонтальному масштабированию: stateless‑сервисы, чтобы можно было просто добавить инстансы; кеширование, чтобы разгрузить базу; очереди для фоновых задач, чтобы пики не «роняли» пользовательские запросы.
На практике это означает: разделять веб‑запросы и тяжёлую обработку, избегать хранения состояния в памяти одного сервиса, а сессии/права/лимиты хранить во внешних хранилищах.
Чаще всего первыми упираются:
ИИ учитывает это и предлагает усиления не «на всякий случай», а в местах, где вероятность упора максимальна для вашего профиля нагрузки.
Хорошая рекомендация — это минимальный набор компонентов, который дает понятный путь роста. ИИ обычно избегает преждевременной сложности (например, многокластерных схем), но закладывает возможности: read‑replica для БД, выделенный кеш, очереди с контролем ретраев, и наблюдаемость, чтобы видеть момент, когда пора усложнять архитектуру.
Запрос «сделайте быстро» для ИИ недостаточно конкретен. Чтобы подобрать стек, модель уточняет, что именно должно стать быстрее: обработка большего числа операций или сокращение времени отклика для одного пользователя. Это разные задачи — и решения у них разные.
Пропускная способность (throughput) — сколько запросов/заказов/событий система переваривает за минуту или час.
Задержка (latency) — сколько времени проходит от клика до результата.
ИИ обычно связывает пропускную способность с параллелизмом, очередями и масштабированием, а задержку — с кэшированием, оптимизацией запросов к БД, географией (CDN) и «тяжестью» бизнес‑логики.
Если продукт на этапе MVP, команда небольшая, а требования к SLA умеренные, монолит часто выигрывает: меньше сетевых вызовов, проще отладка, быстрее релизы, ниже цена эксплуатации.
Микросервисы начинают «окупаться», когда:
ИИ в таких случаях будет предлагать микросервисы не ради моды, а если видит ограничения по росту, надежности или скорости разработки.
Почти любое ускорение добавляет компоненты: кеш, брокер сообщений, поиск, отдельные сервисы. ИИ обычно балансирует это так: пока прирост скорости не критичен для метрик продукта, предпочтение отдается более простому решению. Когда скорость напрямую влияет на конверсию, SLA или стоимость инфраструктуры — усложнение становится оправданным.
Даже идеально подходящая архитектура может провалиться, если команда не умеет её поддерживать. Поэтому ИИ в подборе стека старается минимизировать риск срыва сроков и роста стоимости разработки из‑за обучения, ошибок и текучки.
На практике полезно мыслить «матрицей навыков»: какие технологии уже уверенно используются, какие знакомы поверхностно, а какие придётся осваивать с нуля. ИИ обычно учитывает не только “кто умеет”, но и цену переучивания:
Если входные данные содержат, например, «2 backend‑разработчика уверенно на Node.js, DevOps на базовом уровне», то рекомендации будут смещаться к решениям, которые не требуют редких компетенций и сложной эксплуатации.
ИИ часто «наказывает» экзотические инструменты не потому, что они плохие, а потому что у них выше операционный риск: сложнее нанимать, дольше онбординг, меньше готовых практик. В результате поддержка (и исправление инцидентов) может обходиться дороже, чем выигрыш от технических преимуществ.
Если цель — выпустить MVP быстро, то знакомый стек нередко объективно лучше: меньше неопределённости, проще планировать, выше скорость итераций. ИИ обычно рекомендует «знакомое + проверенное», когда сроки жёсткие, команда небольшая, а требования по нагрузке пока умеренные.
Важно, что ИИ учитывает не только языки и фреймворки, но и зрелость инженерных практик: есть ли тесты, CI/CD, code review, мониторинг. Например, сложная микросервисная схема при слабом CI/CD увеличит хаос, поэтому ИИ может предложить более простой стек и архитектуру, пока процессы не подтянутся.
Сжатые сроки почти всегда означают одно: сначала нужно проверить гипотезу, а не строить «идеальную» систему. Поэтому ИИ при подборе стека начинает с вопроса: что именно должно заработать в MVP, чтобы команда получила валидный сигнал от пользователей — и что можно отложить.
Для MVP ИИ обычно предлагает стек с меньшим числом движущихся частей: один основной сервис, одна база данных, простая схема деплоя, минимальный мониторинг. Цель — уменьшить время на инфраструктуру и согласования.
Типичный принцип: «меньше компонентов — меньше точек отказа и меньше времени на поддержку». Если функциональность можно закрыть стандартными возможностями фреймворка и БД — так и делаем.
Хорошая рекомендация ИИ — сразу продумать, какие решения обратимы. Например, относительно безболезненно меняются:
А вот выбор модели данных и границ доменов менять сложнее — поэтому ИИ старается «сэкономить время», но не за счет фундаментальных ошибок.
ИИ не должен обещать «без долга». Вместо этого он предлагает осознанный долг: что именно упрощаем сейчас, какие риски принимаем и когда вернемся. Полезный формат — короткий список долгов с условиями погашения: «если метрика X превысит порог Y — делаем Z».
Усложнение имеет смысл, когда есть факты. ИИ обычно опирается на триггеры: рост p95/p99 задержек, регулярные инциденты, увеличение нагрузки/данных, стоимость поддержки (время на релизы, ручные операции) и нарушение целевых SLA. До этого момента выгоднее инвестировать в наблюдаемость и стабильный процесс релизов, чем в преждевременное масштабирование.
Цена технологии — это не только «сколько стоит разработка». ИИ, подбирая стек, смотрит на полную стоимость владения (TCO): сколько продукт будет стоить компании в работе, поддержке и росте, а не в моменте.
Условно затраты делятся на разовые (CapEx) и регулярные (OpEx). CapEx — миграции, покупка оборудования, разовая настройка CI/CD, стартовая разработка. OpEx — ежемесячные счета за облако, зарплаты поддержки, инциденты, простои, подписки на инструменты.
ИИ часто начинает с вопроса: что для вас критичнее — минимальный стартовый бюджет или предсказуемые ежемесячные расходы? Например, on‑premise может выглядеть «дешевле» по счетам, но дороже по времени и рискам.
Даже бесплатный open source может стать дорогим, если его нужно постоянно обслуживать. В оценку обычно добавляют:
Если команда маленькая, ИИ чаще склоняется к управляемым сервисам: меньше ручной работы, быстрее реакция на инциденты.
Платные лицензии и SaaS/managed‑решения имеют смысл, когда экономят часы специалистов или снижают риск простоя. ИИ сравнивает не «цена лицензии против нуля», а «лицензия против зарплат/времени на поддержку и потерь от сбоев».
На горизонте 6–24 месяцев ИИ обычно строит несколько сценариев (MVP, умеренный рост, быстрый рост) и прикидывает: инфраструктурные счета, требуемые роли (DevOps/SRE, DBA), стоимость отказов (в привязке к вашему SLA), и цену будущих миграций. В итоге «дорого» — это не высокий чек сегодня, а дорогие изменения и эксплуатация завтра.
Требования к надежности — это не «приятный бонус», а набор чисел, которые заставляют менять компоненты и процессы. Когда ИИ подбирает стек, он пытается понять, какую цену проект готов платить за простой и потерю данных: деньгами, сложностью, скоростью разработки.
Если вы называете доступность 99,9% или 99,99%, ИИ будет предлагать решения, где отказ одного узла не останавливает сервис. SLO (внутренняя цель) влияет на дизайн: например, нужен ли active‑active, или достаточно active‑passive. SLA (внешнее обещание) почти всегда тянет за собой формализацию мониторинга, дежурств и процедуры инцидентов.
ИИ обычно проверяет, нет ли критичных SPOF:
Если SPOF неизбежен, он должен быть сознательным и краткоживущим (например, на этапе MVP).
Высокая доступность — это не только репликация. ИИ будет спрашивать про RPO/RTO: сколько данных можно потерять и как быстро восстановиться. От ответов зависит выбор: управляемая БД с автоматическими бэкапами, multi‑AZ/region, стратегия миграций, регулярные тесты восстановления.
Чтобы SLO были реальными, в стек почти неизбежно добавляются логи, метрики и трассировки. ИИ будет рекомендовать единый контур наблюдаемости (корреляция по trace_id), алерты по пользовательским симптомам (ошибки, задержки), а не только по загрузке CPU. Без этого надежность остается «на словах».
Когда ИИ подбирает стек, он почти всегда начинает с вопроса: «какие данные и как они будут жить в продукте». Ошибка здесь дорого стоит, потому что смена БД или модели хранения обычно тянет за собой переписывание логики, миграции и риск простоя.
ИИ сопоставляет типы операций и требования к целостности с подходящей моделью:
ИИ предлагает кеш не «для ускорения вообще», а под конкретный паттерн:
Ключевой вопрос: что делать при промахе кеша, как ограничивать TTL, и какие данные можно кешировать без риска ошибок.
Когда появляются сложные фильтры, полнотекстовый поиск и агрегации, ИИ часто рекомендует вынести поиск и аналитику в отдельные инструменты, чтобы не «убивать» транзакционную БД тяжелыми запросами. При росте это обычно означает разделение: OLTP — для операций продукта, OLAP — для отчетов, витрин и аналитики.
ИИ оценивает, как часто будет меняться схема и сколько стоит ошибка:
Итоговая рекомендация должна включать не только «какую БД выбрать», но и как безопасно развивать схему без простоев.
Безопасность — это не «дополнительная опция» к стеку, а набор ограничений, которые резко сужают выбор технологий. ИИ обычно начинает с вопроса: какой уровень защиты нужен и чем он подтверждается (внутренними политиками, договором, регуляторикой, требованиями заказчика).
Для базового уровня часто достаточно стандартных практик: HTTPS везде, регулярные обновления, резервные копии, минимальные права. Повышенный уровень добавляет обязательные вещи: изоляция сред, сегментация сети, более строгий контроль доступа, журналирование действий и постоянный мониторинг.
ИИ может предложить «популярный» стек, но если у вас требования к хранению персональных данных, запрет на передачу данных за пределы контура или необходимость аттестации, выбор сразу смещается в сторону конкретных провайдеров, on‑premise/частного облака и проверенных компонентов.
Обычно рекомендации сводятся к проверенным схемам: OAuth 2.0 / OpenID Connect для входа, роли и права (RBAC) для доступа, иногда — политики (ABAC) для сложных правил.
Типовые ошибки, которые ИИ старается «отловить» по входным данным:
Хорошая рекомендация по стеку почти всегда включает: менеджер секретов (вместо переменных в CI и файлов), шифрование данных «в пути» и «на диске», ротацию ключей, разделение доступов между средами (dev/stage/prod), а также аудит действий администраторов и сервисов.
Если среда ограничена (например, только on‑premise, закрытая сеть, запрет внешних SaaS), ИИ будет отдавать предпочтение технологиям, которые можно развернуть самостоятельно и контролировать: свои очереди, свои хранилища, свои инструменты мониторинга.
Практика: фиксируйте требования безопасности как чек‑лист до выбора стека и сверяйте каждую рекомендацию ИИ с этим чек‑листом. Это быстрее, чем «переделывать безопасность» после запуска.
ИИ хорошо подсказывает варианты, но легко «съезжает» в общие советы или придумывает детали. Ваша задача — превратить рекомендацию в проверяемую гипотезу и зафиксировать допущения.
Первый сигнал — уверенные утверждения без привязки к вашим вводным: «это лучший выбор», «идеально подходит всем». Второй — нестыковки (например, предлагает on‑premise, хотя вы указали только облако; или рекомендует инструмент, который не работает в РФ/не доступен по лицензии). Третий — ссылки на «встроенные» функции, которых нет в продукте, или путаница версий.
Проверка простая: попросите ИИ перечислить предпосылки (что он считает правдой о нагрузке, бюджете, SLA, компетенциях), а затем подтвердите их фактами.
Спросите:
Сведите проверку к минимальному набору действий:
Прототип ключевого пути (самый «тяжелый» запрос/операция).
Нагрузочное тестирование с реалистичными данными и профилем пользователей.
Черновые расчеты: стоимость владения, хранение, трафик, резервирование, трудозатраты.
План отката: что делаем, если компонент не тянет или недоступен.
Оформляйте выбор через ADR (Architecture Decision Record): контекст, решение, альтернативы, последствия.
Обязательно приложите список допущений (например, «до 5k RPS», «команда знает X», «SLA 99.9%») и триггеры пересмотра. Это защитит вас от ситуации, когда ИИ «угадал», но проект изменился.
Если вы используете платформы, где продукт собирается через чат (например, TakProsto.AI), ADR полезно вести параллельно с «planning mode»: фиксируйте, какие ограничения вы сообщили системе, какие решения она предложила, и какие из них вы приняли. Так вы сохраняете управляемость — даже при высокой скорости итераций, экспорте исходников и последующем деплое/хостинге с возможностью снапшотов и отката.
Технологический стек — это согласованный набор решений для клиентской части, сервера, данных, инфраструктуры и интеграций.
Его нельзя выбирать «по вкусу», потому что каждое решение меняет:
Дайте контекст в виде краткой анкеты:
Полезно попросить ИИ сначала задать уточняющие вопросы и перечислить свои допущения.
Хорошая рекомендация — это не список модных инструментов, а пакет:
Сформулируйте требования как «кто/что/как часто/что считается успехом». Например:
И отдельно зафиксируйте нефункциональные требования:
Чем меньше расплывчатых фраз вроде «быстро» и «надежно», тем меньше случайных советов.
Обычно удобно просить 2–3 сценария:
Так вы сравниваете решения по стоимости/рискам, а не спорите о единственном «правильном» варианте.
Монолит чаще выигрывает на ранней стадии, если:
Микросервисы обычно оправданы, когда:
Первыми обычно становятся узкими местами:
Попросите ИИ явно перечислить предполагаемые узкие места и предложить 1–2 меры наблюдаемости (метрики/алерты), которые покажут момент, когда пора усложнять архитектуру.
Начинайте с данных и операций:
Отдельно уточните:
Зафиксируйте чек-лист до выбора стека:
Затем проверьте каждую рекомендацию ИИ по этому чек-листу: если компонент не проходит ограничения среды, его лучше исключить сразу.
Проверяйте рекомендации как гипотезы:
Для фиксации решения используйте ADR: контекст → решение → альтернативы → последствия → триггеры пересмотра.
Практика: начинайте проще и планируйте «путь эволюции», а не сразу максимальную сложность.
Попросите ИИ добавить план миграций и отката — без него выбор БД обычно неполный.