Пошагово разбираем, как ИИ уточняет требования из промпта, формулирует допущения, выбирает компоненты и оценивает компромиссы до production-ready архитектуры.
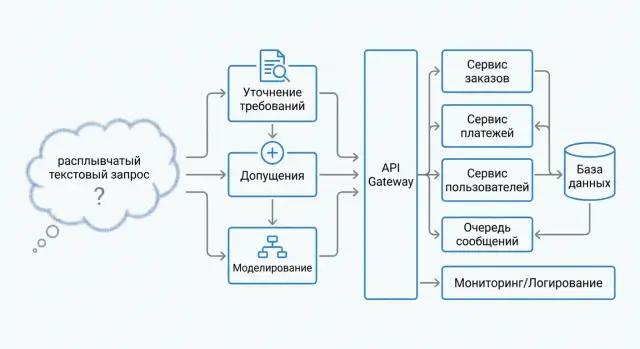
«Сделайте приложение для записи к врачу» — типичный расплывчатый промпт. Он описывает желание, но почти ничего не говорит о реальных требованиях: кто пользователи, какие клиники, как подтверждаются записи, что делать при отменах, какие данные считать персональными, какие сроки и бюджеты допустимы. Архитектура не строится из желания напрямую — ей нужны границы и проверяемые критерии.
Результат работы над архитектурой — не абстрактная «схема микросервисов», а комплект артефактов, который помогает команде одинаково понимать продукт и принимать решения:
ИИ хорошо ускоряет старт: помогает задавать уточняющие вопросы, предлагает варианты типовых решений, напоминает про нефункциональные требования (доступность, безопасность, стоимость), формирует черновики документов.
Прикладной вариант — использовать платформу, где эти шаги встроены в процесс. Например, в TakProsto.AI удобно вести диалог в «режиме планирования»: прогонять чек‑листы по требованиям, фиксировать допущения и разбирать варианты архитектуры до того, как команда начнёт реализовывать решение.
Но ответственность остаётся на людях. ИИ не знает вашей реальности: договоров, ограничений регулятора, политик безопасности, фактических нагрузок и бюджета. Поэтому любая рекомендация требует проверки — через интервью со стейкхолдерами, быстрые прототипы, расчёты и согласование с эксплуатацией.
Чтобы «расплывчатое» постепенно стало управляемым, удобно вести:
Эти артефакты лучше собирать «по дороге», а не пытаться сделать идеальный документ одним заходом. В следующих шагах мы будем превращать заготовки в решения, которые можно реализовать и поддерживать в продакшене.
На этом шаге ИИ полезен не тем, что «придумывает архитектуру», а тем, что быстро превращает расплывчатый запрос в набор уточняющих вопросов. Цель — договориться о контексте: для кого делаем продукт, какую проблему решаем и где заканчивается ответственность системы.
Начните с формулы: «пользователь → действие → ожидаемый результат → зачем». ИИ может помочь разложить фразу вроде «нужен сервис для заявок» на конкретные сценарии:
Важно сразу отметить «нецелевых» пользователей и сценарии, чтобы они не «просочились» в требования позже.
Чёткие границы защищают от бесконечных ожиданий. Зафиксируйте:
Удобная проверка: если внешний сервис упал, что обязано работать всё равно?
Успех — это измеримые метрики. Примеры:
ИИ часто выявляет разночтения в терминах. Составьте мини-словарь: «заявка», «статус», «клиент», «заказ», «верификация», «черновик/отправлено». Одно и то же слово должно означать одно и то же — иначе дальше начнётся спор не про архитектуру, а про значения.
На этом шаге ИИ переводит «хочу сервис для X» в набор проверяемых требований. Цель — не написать ТЗ на 100 страниц, а получить минимально достаточную спецификацию, которая позволит выбрать компоненты, оценить риски и не переделывать архитектуру после первых пользователей.
Функциональные требования лучше формулировать через роли и сценарии. ИИ помогает разложить исходный запрос на:
Хороший результат — 5–10 ключевых пользовательских сценариев (use cases) с ожидаемым результатом и ошибками «что если».
Нефункциональные требования определяют форму архитектуры сильнее, чем функциональные. ИИ уточняет:
ИИ фиксирует внешние рамки: сроки релиза, размер и опыт команды, выбранный стек и совместимость, лицензии, требования безопасности и регуляторики (например, где можно хранить данные и как их удалять).
После этого шага расплывчатый запрос превращается в набор требований, из которых уже можно выводить доменную модель и компоненты.
На этом шаге мы честно признаём: часть данных о продукте ещё не определена, а часть — может быть неверной. ИИ полезен тем, что заставляет формализовать «пустоты» в виде явных допущений и рисков, чтобы архитектура не строилась на догадках.
Хорошее допущение — это не туманное «скорее всего», а проверяемая связка причины и последствия:
Такой формат сразу показывает, какие решения «условные», и что именно нужно подтвердить.
Практика простая: помечайте утверждения метками Факт / Предположение / Вопрос.
Если данных не хватает, ИИ должен предложить минимальный набор уточняющих вопросов и временную «заглушку» (safe default), которую можно поменять без переписывания системы.
Заведите короткий реестр (таблица в документе или тикетах): риск → вероятность → влияние → меры → владелец → дедлайн проверки. Пример: «нестабильность внешней интеграции» (средняя/высокое) → «кэш, очередь, деградация функциональности, лимиты и алёрты».
Стоп-сигналы:
В этот момент лучше зафиксировать варианты и вынести 2–5 конкретных вопросов стейкхолдеру, чем «достраивать» архитектуру догадками.
На этом шаге ИИ помогает превратить «хочу сервис Х» в понятную карту предметной области: что является “вещами” (сущностями), какие у них состояния, кто за что отвечает и где проходят границы.
Удобный приём — сначала выделить поддомены, а уже потом думать про микросервисы или модули. Границы стоит проводить там, где меняются правила и владельцы данных.
Пример логики разбиения:
ИИ обычно предлагает 2–3 варианта декомпозиции (по процессам, по данным, по командам) и задаёт вопросы, чтобы выбрать наиболее устойчивый к изменениям.
Далее фиксируем ключевые сущности и их состояния: например, Заказ: черновик → подтверждён → оплачен → исполнен → закрыт/отменён. Важно отметить, кто имеет право переводить сущность между состояниями и какие проверки обязательны.
Для каждой подсистемы полезно перечислить операции и их свойства:
Эта информация напрямую влияет на выбор компонентов и на то, где допустима eventual consistency.
Финал шага — грубая схема потоков данных и событий, чтобы видеть систему “в движении”:
Клиент → API → (Доменные сервисы) → БД
↘ событие → Очередь → Уведомления/Интеграции
Такой черновик быстро выявляет «узкие места»: где нужны очереди, где — синхронный ответ, а где — фоновые процессы.
На этом шаге ИИ помогает превратить абстрактное «синхронизируйте данные между сервисами» в конкретные правила: как именно сервисы общаются, что считается источником истины и что делать, если связь или внешняя система подвела.
Синхронный вызов API хорош, когда пользователю нужен мгновенный ответ (например, «проверить доступность»). Но цепочка из нескольких API-зависимостей повышает риск таймаутов и «эффекта домино».
Асинхронный обмен через очередь или события подходит для фоновых операций: начисления, уведомления, экспорт, обновление витрин. Практичное правило: всё, что не обязано завершиться в рамках одного пользовательского запроса, лучше уводить в асинхронный контур.
Сильная согласованность нужна там, где ошибка недопустима (например, списание денег или выдача уникального ресурса). Во многих продуктовых сценариях достаточно итоговой согласованности: данные могут «догнать» через секунды или минуты, если это не ломает пользовательский опыт.
Полезный приём: явно перечислить поля/операции, где задержка допустима (статусы, аналитика, рекомендации), и где нет (баланс, лимиты, права доступа).
Интеграции почти всегда сталкиваются с повторами: клиент нажал дважды, сеть моргнула, воркер перезапустился. Поэтому нужен слой защиты от «двойной обработки»:
Чтобы изменения не превращались в аварии, ИИ помогает зафиксировать «контракт»: форматы сообщений, обязательные поля, допустимые значения, коды ошибок.
Обычно рекомендуются:
Итог этого шага — набор чётких решений: где синхронно, где асинхронно, какой уровень согласованности приемлем, и какие механизмы гарантируют корректность при сбоях.
На этом шаге ИИ помогает превратить «нужно хранить данные и быстро отвечать» в конкретные решения: какие типы хранилищ нужны, что кэшировать, а где лучше добавить отдельный поисковый контур. Важно не выбирать технологии «по моде», а привязать выбор к нагрузке и сценариям запросов.
Один продукт часто использует несколько хранилищ одновременно. База «по умолчанию» подходит не всегда.
Ключевые вопросы:
Практика: транзакционные данные чаще живут в реляционной БД; «событийные» потоки — в журнале/очереди и отдельном хранилище для аналитики; документы и файлы — в объектном хранилище.
Кэш ускоряет и удешевляет чтения, но добавляет риск ошибок.
Полезно кэшировать:
Опасные зоны:
Базовые стратегии: TTL для нестрогих данных, инвалидация по событию для критичных, и запрет кэширования там, где цена ошибки высока.
Если продукту нужен полнотекст, релевантность, подсказки, быстрые фильтры по множеству полей или аналитика по большим объёмам, выгодно вынести это в отдельный слой.
Важный момент: поисковый индекс почти всегда асинхронный. Значит, нужно заранее принять компромисс «поиск обновляется с задержкой» и описать, как обрабатываются расхождения между источником истины и индексом.
Техническое решение без политики хранения — половина архитектуры.
Минимальный набор:
Если нужно, этот шаг можно закрепить в виде короткой матрицы «тип данных → хранилище → кэш → поиск → политика бэкапа» и использовать как приложение к архитектурному документу.
Безопасность в архитектуре — это не «отдельный проект», а набор простых решений, которые вы принимаете заранее, чтобы не ловить утечки и инциденты на проде. Задача ИИ на этом шаге — помочь быстро перечислить базовые угрозы и превратить их в понятные правила доступа и хранения секретов.
Отдельно проговорите требования к локализации данных и моделей: где физически находятся серверы, какие LLM используются, уходит ли что‑то во внешние контуры. В этом смысле TakProsto.AI часто выбирают как инструмент для ранней проработки и прототипирования, потому что платформа ориентирована на российский рынок и работает на инфраструктуре в России, не отправляя данные за пределы страны.
Начните с короткого списка рисков, которые встречаются чаще всего:
ИИ может предложить «матрицу угроз» по компонентам (API, база, очереди, админка, интеграции) и сразу указать, какие меры минимальны, а какие — опциональны.
Зафиксируйте: кто входит (пользователь, сервис, оператор) и что ему разрешено. Практичный минимум:
Правило номер один: секреты не должны «жить» в коде и конфигурациях. Договоритесь о:
Чтобы разбирать инциденты, нужны аудит-логи: кто, что и когда сделал (вход, смена ролей, операции с данными, критичные настройки). Сразу определите срок хранения и доступ к аудит-логам — обычно он строже, чем к обычным логам приложения.
Наблюдаемость — это «приборная панель» продукта: по ней команда понимает, что сервис жив, что он делает и где именно он «болит». ИИ помогает здесь не магией, а структурой: превратить расплывчатое «чтобы всё работало» в измеримые показатели, связать сигналы между собой и заранее описать, как искать причину.
Начните с небольшого набора SLI (измерения) и SLO (цели), которые отражают пользовательский опыт:
SLO формулируйте как договор: например, «p95 < 400 мс при N RPS» и «ошибки 5xx < 0,1%». Это база для релизных решений и алёртов.
Собирайте три слоя сигналов и связывайте их одним correlation/request id:
Главное правило: лог без идентификатора запроса и трассировки часто превращается в «поиск иголки».
Алёрт должен означать действие. Хорошие кандидаты:
Не алёртите на «всё, что движется»: одиночные ошибки, временные всплески без влияния на пользователей, метрики без владельца.
Заранее опишите короткие runbook’и: «симптом → проверка → гипотеза → действие». Примеры:
Так наблюдаемость перестаёт быть «сбором данных ради данных» и становится инструментом, который ускоряет восстановление и снижает риск повторения инцидентов.
На этом шаге важно договориться не «как сделать быстро», а как система будет вести себя при росте и сбоях. ИИ помогает структурировать разговор: какие нагрузки считаем нормой, что считаем инцидентом, и какие деградации допустимы.
Обычно начинают с вертикального масштабирования (больше CPU/RAM на одном узле), потому что это проще и дешевле в поддержке. Переход к горизонтальному (больше экземпляров) оправдан, когда упираемся в:
Метрики, по которым принимают решения: p95/p99 latency, RPS, длина очередей, время выполнения фоновых задач, доля ошибок (5xx/таймауты).
Чтобы один пользователь или интеграция не «съела» систему, фиксируем лимиты: rate limiting на API, квоты по токенам/операциям, ограничение размера запросов, таймауты на внешние вызовы. Для платных тарифов — отдельные лимиты и приоритеты. Важно описать поведение при превышении: 429, очередь или упрощённый ответ.
Определяем критические зависимости (БД, кэш, внешние API) и стратегию: ретраи с джиттером, circuit breaker, fallback-кэш, частичная функциональность вместо полного отказа. Резервирование: минимум 2 экземпляра критичных сервисов, бэкапы и проверка восстановления (RPO/RTO).
Перед релизом задаём пороги: p95 < X мс при Y RPS, error rate < Z%, время восстановления < N минут. Нагрузочные тесты должны включать «плохие дни»: всплеск трафика, деградацию внешнего сервиса, медленную БД. Это превращает масштабирование из догадок в управляемый процесс.
На этом шаге ИИ помогает превратить «сделайте, чтобы работало» в понятный план: как доставлять изменения быстро, но без сюрпризов для пользователей и команды. Хорошая архитектура в продакшене — это не только компоненты, но и повторяемый процесс.
Минимальный “конвейер” стоит описать сразу: сборка артефактов, прогон автотестов, статические проверки, сканирование зависимостей, упаковка и выкладка.
ИИ удобно использовать как чек-лист: какие проверки обязательны перед мерджем, какие — перед релизом, где нужны ручные шаги (например, подтверждение выкладки). Полезная практика — отделить «быстрый контур» (проверки за минуты) от «глубокого» (нагрузка, интеграционные тесты), чтобы команда не обходила процесс из-за медлительности.
Если вы делаете продукт в формате vibe-coding, часть этих задач может закрываться платформой. Например, TakProsto.AI поддерживает развёртывание и хостинг, экспорт исходников, а также снапшоты и откат — это помогает безопаснее проходить первые итерации MVP, когда архитектура ещё «донастраивается» по фактическим данным.
Важно зафиксировать назначение окружений и правила доступа. Dev — для ежедневной разработки, stage — для проверки релиз-кандидата в условиях, максимально близких к продакшену, prod — только для реальных пользователей.
Отдельный вопрос — тестовые данные. Безопасный вариант: синтетические наборы или обезличенные копии, плюс ограничения на экспорт и срок хранения. Для доступов — принцип «минимально необходимого» и понятные роли.
Изменения схемы данных чаще всего ломают релизы. Базовая стратегия: сначала добавить новое (колонки/таблицы), затем научить приложение писать/читать в двух форматах, потом постепенно переключить чтение, и только после этого удалить старое. Для крупных изменений — фоновые миграции и возможность отката.
Описываются “будни”: как катим релиз (окна, ответственные, критерии готовности), как откатываем (версия, флаги, база), как работаем с инцидентами (канал связи, таймлайн, постмортем), и нужен ли дежурный график. Чем чётче эти правила, тем меньше героизма и ночных сюрпризов.
На этом шаге ИИ перестаёт «рисовать идеал» и фиксирует осознанные компромиссы. Итог — не набор модных компонентов, а пакет решений с объяснениями, рисками и планом внедрения, чтобы команда могла согласовать ожидания и двигаться без скрытых сюрпризов.
| Решение | Скорость разработки | Стоимость | Надёжность | Когда подходит | Когда опасно |
|---|---|---|---|---|---|
| Монолит + модульная структура | высокая | низкая/средняя | средняя | MVP, 1 команда, понятный домен | разные команды, частые релизы, тяжёлые интеграции |
| Микросервисы | низкая/средняя | высокая | высокая (при зрелости) | масштаб, независимые команды, разные SLA | нет SRE/DevOps, слабая наблюдаемость, мало опыта |
| Managed-сервисы (очереди/БД) | высокая | средняя/высокая | высокая | быстрый старт, нужна доступность | жёсткие требования к on-prem, риск vendor lock-in |
| Сильная консистентность везде | средняя | средняя | высокая | финансы, склад, критичные транзакции | высокая нагрузка, распределённые интеграции |
ИИ часто «по умолчанию» предлагает микросервисы, event-driven, CQRS и несколько кэшей. Это полезно, но не всегда оправдано. Хороший тест: есть ли измеримые причины (нагрузка, автономные команды, разные домены, требования к задержкам) и готовы ли вы платить за сложность эксплуатации. Если нет — фиксируйте упрощённый вариант как осознанный выбор.
Чтобы решения не растворились в чатах, оформите 5–10 ADR (Architecture Decision Records): контекст, варианты, решение, последствия, как откатываем. Рядом — короткий список «почему так, а не иначе»: что отвергли и по каким причинам (стоимость, сроки, риски, компетенции).
ИИ должен разложить архитектуру на этапы: скелет (каркас), критический путь, интеграции, наблюдаемость, безопасность, нагрузочное тестирование. Для каждого этапа — зависимости, критерии готовности и грубые оценки (t-shirt sizing или человеко-недели), чтобы продукт и инженерия говорили на одном языке.
Финальный пакет удобно собирать в одном документе:
Так архитектура превращается из «красивой схемы» в управляемый набор решений, который реально можно реализовать и поддерживать.
Хороший итог — не «схема сервисов», а набор артефактов, с которыми команда может работать:
Попросите ИИ сначала не «строить архитектуру», а выдать список уточняющих вопросов по четырём блокам:
Дальше фиксируйте ответы как требования и допущения, а не как «идеи».
Начните с минимального словаря на 10–20 терминов и договоритесь о единственных определениях.
Практика:
черновик → подтверждён → закрыт);Это снижает риск, что команда будет обсуждать разные смыслы под одним словом.
Соберите минимальный набор нефункциональных требований, которые реально влияют на выбор компонентов:
Если метрик нет, зафиксируйте временные «safe default» и отметьте это как предположение.
Ведите таблицу «Если…, то…», чтобы решения были условными и проверяемыми.
Пример:
Обязательно отмечайте каждую запись меткой Факт / Предположение / Вопрос и добавляйте способ проверки (интервью, метрики, прототип).
ADR — короткие записи решений, которые помогают не спорить заново через месяц.
Минимальный формат:
Достаточно 5–10 ADR на MVP, дальше — по мере появления новых «точек невозврата».
Правило практичное: всё, что не обязано завершиться в рамках одного пользовательского запроса, уводите в асинхронный контур.
Для критичных цепочек добавляйте таймауты, деградацию и понятное поведение при падении зависимостей.
Чтобы переживать повторы и сбои, закладывайте базовую «защиту от двойной обработки»:
Это особенно важно на границах: внешние интеграции, воркеры, вебхуки.
Кэш полезен там, где ошибка не критична или легко исправима, и опасен там, где «цена устаревания» высока.
Практические правила:
Если нет ясной стратегии инвалидации — лучше начать без кэша.
Минимальный набор для продакшена:
Это дешевле сделать в MVP, чем добавлять после первого серьёзного инцидента.