Разбираем, как LLM выводят требования продукта и рекомендуют СУБД, где эти выводы ломаются и как проверять советы через вопросы, критерии и тесты.
Когда говорят, что «LLM выбрала базу данных», обычно речь не о полноценном инженерном выборе, а о быстрой гипотезе, собранной из описания: «у нас маркетплейс, будут заказы, поиск, рекомендации». Модель сопоставляет эти слова с типовыми паттернами (транзакции → SQL, события → time-series, поиск → search engine, связи → graph DB) и предлагает один‑два знакомых варианта.
LLM не измеряет вашу нагрузку и не читает ваш код. Она:
По сути это ближе к консультации «по симптомам», чем к проектированию архитектуры данных.
Они быстрые и дешёвые: за минуту можно получить обзор вариантов, терминов и компромиссов, а также стартовый список вопросов для команды. На ранней стадии продукта это полезно — как способ расширить кругозор и не забыть про альтернативы.
Ответственность за решение остаётся у команды, потому что «правильная СУБД» зависит от деталей, которых модель обычно не видит: профиля запросов, требований к восстановлению, стоимости хранения, навыков эксплуатации, ограничений по комплаенсу.
Разберём, как LLM выводят требования из описания продукта, какие сигналы сильнее всего влияют на рекомендации, где модели ошибаются и как проверять советы: через вопросы, матрицу критериев и тесты (включая нагрузочные).
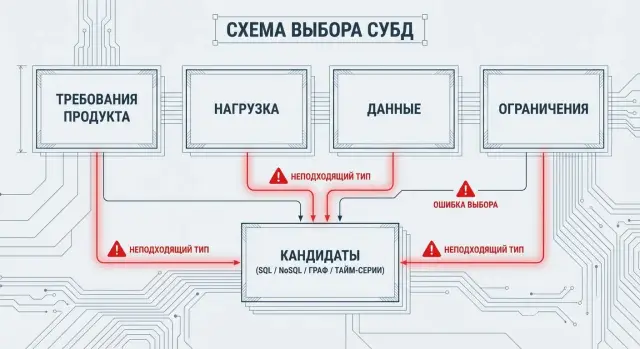
LLM почти никогда не «выбирают СУБД» напрямую. Сначала модель пытается восстановить требования к данным из того, что вы написали про продукт, а уже потом сопоставляет их с классом хранилища (SQL/NoSQL и т. п.) и конкретными решениями.
Чаще всего это 5–15 строк: что за сервис, ключевые функции (поиск, лента, корзина), примерные объёмы, иногда ограничения по бюджету или стеку. Если чего-то нет (например, «пиковая нагрузка»), модель всё равно продолжит рассуждать — и начнёт заполнять пробелы предположениями.
Модель опирается на шаблоны из обучающих данных: «чат = много записей + быстрые вставки», «аналитика = колоночное», «каталог товаров = реляционная схема». Это полезно для черновика, но опасно, когда ваш продукт не похож на типовой пример (например, лента без строгой персонализации или поиск без сложной фильтрации).
Из описания LLM обычно извлекает (или домысливает) такие параметры:
Требования → класс СУБД (OLTP SQL, документная, key-value, графовая, колоночная) → паттерны (CQRS, кэш, события) → конкретные продукты.
Чтобы этот шаг работал точнее, полезно заранее дать модели цифры и примеры запросов; чек‑лист можно вынести в отдельный промпт (см. /blog/kak-pravilno-prosit-llm-o-vybore-subd).
Когда вы просите LLM «подобрать базу данных», она по сути пытается восстановить картину продукта по нескольким типам сигналов. Чем точнее вы их описали, тем ближе будет рекомендация к реальности — и тем меньше риск получить «популярный, но не ваш» вариант.
Самый сильный фактор — структура данных: сущности, связи и то, насколько они «жёсткие».
Если в описании звучит много отношений (пользователи → заказы → позиции → платежи), важны целостность и транзакции, а схема относительно стабильна — LLM почти всегда тянется к реляционным СУБД.
Если же подчёркнута разнородность объектов, частые изменения полей, необходимость хранить документы «как есть» и быстро добавлять атрибуты — модель склоняется к документным хранилищам.
Отдельный сигнал — кардинальности и «болезненные места»: много-ко-многим, иерархии, графовые связи, версионирование и история изменений. Чем явнее вы это называете, тем легче LLM отличит «таблицы с джойнами» от кейса, где действительно нужен граф или журнал событий.
LLM сильно реагирует на формулировки про запросы:
Важная деталь: если вы не описали запросы (какие поля фильтруются, какие сортировки, какие агрегаты, какие top‑N), модель часто «додумает» типичный сценарий и промахнётся.
Триггерные слова для LLM — «миллионы событий в минуту», «пики», «сезонность», «многорегиональность», «низкая задержка». По ним она делает выводы о шардинге, репликации и том, выдержит ли система рост.
Но если вы не даёте чисел (RPS, объём данных, рост в месяц, допустимая задержка), LLM склонна либо переоценивать масштаб и рекомендовать слишком сложные распределённые системы, либо недооценить и оставить вас на одной ноде.
Даже идеальная по модели данных СУБД может быть плохим выбором, если её некому поддерживать.
LLM обычно учитывает такие сигналы:
Если эти ограничения не проговорены, рекомендация часто будет «технически красивая», но дорогая или тяжёлая в сопровождении.
Эта «карта» помогает перевести требования продукта на язык архитектуры данных. LLM часто делает такой перевод автоматически, но полезно держать под рукой простые ориентиры: какой класс СУБД лучше закрывает ключевые сценарии и какие компромиссы обычно скрываются.
Подходят, когда важны транзакции, целостность данных и сложные запросы: заказы и оплаты, учёт остатков, биллинг, права доступа. Если в требованиях много «должно быть строго согласовано» и «нельзя потерять связь между сущностями», SQL обычно базовый выбор.
Хороши для гибкой схемы и быстрых простых операций чтения/записи: профили пользователей, корзины, кэш сессий, каталоги с часто меняющимся набором полей. Сигнал: данные «разные от объекта к объекту», запросы простые, а скорость разработки важнее строгой нормализации.
Выбор для отчётов и аналитики: большие сканы, агрегации, витрины данных, поведенческие события. Если продукт спрашивает «посчитать по миллиардам строк» и «строить дешёвые отчёты», транзакционная СУБД часто будет дорогой и медленной.
Нужны, когда ядро — связи и обходы: рекомендации, выявление сообществ, поиск путей, антифрод по цепочкам. Сигнал: запросы вида «найди через 3–5 связей» и «влияние соседей» важнее, чем табличные отчёты.
Оптимальны для метрик, телеметрии и событий со временем: высокая частота записи, ретеншн, downsampling, запросы по окнам времени. Сигнал: «миллионы точек в минуту», «хранить 30/90/365 дней», «быстро строить графики по времени».
Если LLM предлагает один тип СУБД «на всё», проверьте: у продукта обычно минимум два контура — транзакционный (OLTP) и аналитический (OLAP).
LLM нередко «угадывают» постановку задачи по короткому описанию продукта — и именно на этом этапе рождаются системные ошибки. Модель заполняет пробелы типовыми предположениями, которые могут не совпасть с реальностью: как именно будут читать данные, что важнее — согласованность или скорость, какие ограничения есть у команды и инфраструктуры.
Если вы пишете «нужна база для приложения с пользователями и заказами», LLM часто дорисует усреднённый интернет‑магазин: умеренная нагрузка, простые отчёты, стандартные CRUD‑операции. Но один пропущенный нюанс (например, «много фильтров и сортировок по нескольким полям» или «нужны строгие транзакции при списании баланса») меняет класс подходящих СУБД.
Модель может сместить фокус с критериев на популярность технологий: предложить «трендовую» NoSQL‑СУБД или графовую базу, хотя реальная потребность — надёжные транзакции, SQL‑аналитика и предсказуемые джойны. Это особенно заметно, когда в запросе звучат слова «масштабирование», «реалтайм», «большие данные» без чисел и сценариев.
LLM часто недооценивает, что «тип данных» менее важен, чем «тип запросов». Разница между:
может радикально изменить выбор.
Ещё одна ошибка — рекомендация одной СУБД «на всё»: и для транзакционного ядра, и для аналитики, и для полнотекстового поиска. В реальных системах часто выигрывают комбинации, но их нельзя предлагать без оговорок про границы ответственности каждого хранилища.
Практическая проверка: попросите LLM сначала перечислить неизвестные параметры (нагрузка, SLA, типы запросов, модель данных), и только потом делать рекомендацию — иначе она неизбежно будет про «средний продукт».
LLM часто звучат уверенно, даже когда дают слабую рекомендацию по СУБД. Причина не в «плохой логике», а в том, как устроено обучение: модель хорошо продолжает знакомые шаблоны текста, но не всегда проверяет факты и не знает ваших реальных ограничений.
В обучающих данных непропорционально много статей, гайдов и ответов про самые обсуждаемые варианты. Поэтому модель склонна предлагать «дефолт»: популярную SQL‑СУБД для всего или модный NoSQL для всего — даже если у вас специфичные требования по задержкам, стоимости, географии, лицензиям или операционным навыкам команды.
Это смещение усиливается, когда вы описываете продукт общими словами («высокая нагрузка», «масштабируемость»). Модель подставляет распространённые примеры вместо того, чтобы уточнять параметры.
LLM не живёт в реальном времени: часть знаний про версии, ограничения, типы репликации, managed‑опции и ценовые модели может быть устаревшей. Из‑за этого в рекомендации могут попасть:
На уровне текста это выглядит правдоподобно, но в реальном проекте приводит к неверным ожиданиям по бюджету и срокам.
Модель может уверенно «придумать» режимы, гарантии или ограничения: например, заявить про строгую консистентность в сценарии, где фактически она настраиваемая или ограничена; назвать несуществующий предел размера таблицы; приписать автоматический failover там, где он требует ручной настройки.
Практический сигнал: если ответ содержит точные цифры и обещания без ссылки на условия (версия, конфигурация, провайдер), вероятность галлюцинации повышается.
LLM часто путает консистентность, доступность и задержку, или говорит о них как о независимых «галочках». В результате появляются рекомендации вида «и строго консистентно, и без задержек, и всегда доступно», без обсуждения компромиссов и того, что именно важнее для ваших операций чтения/записи.
Чтобы снизить риск, формулируйте требования измеримо (RPS, p95/p99, RPO/RTO, регионы, объём данных) и просите модель явно перечислять допущения, а не только итоговый выбор.
LLM часто выбирают СУБД по «витринным» признакам: модель данных, скорость чтения/записи, наличие JSON, «подходит ли NoSQL». Но в реальном продукте выбор быстро упирается в эксплуатацию. И тут рекомендации нередко проваливаются: система может быть быстрой на демо и при этом дорогой, неудобной в поддержке или плохо восстанавливаемой после инцидента.
Для бизнеса важны два числа: RPO (сколько данных можно потерять) и RTO (как быстро сервис должен вернуться). LLM может предложить «делать бэкап раз в день», не спросив, что для платежей потеря 12 часов данных недопустима.
Практический минимум, который стоит проговорить:
LLM любит советовать «мультизонность, кворум, несколько реплик» — иногда это правильно, но часто это «на всякий случай». Цена такой перестраховки: сложнее схемы развёртывания, выше задержки, больше стоимость и выше шанс ошибок в операционных процедурах.
Полезнее начать с вопросов: какой простой допустим (минуты/часы), что должно работать при падении зоны, какие операции важнее (чтение или запись), есть ли ручной режим обслуживания.
Если СУБД нельзя нормально наблюдать, вы будете чинить инциденты «вслепую». Проверяйте, что в стеке есть:
Цена — это не только лицензия или размер диска. В TCO обычно прячутся: время администрирования, стоимость хранения бэкапов, сетевой трафик между зонами/регионами, требования к железу, а ещё обучение команды и найм специалистов.
Хорошая проверка рекомендации от LLM: попросите её прикинуть, сколько это будет стоить и кем поддерживаться при росте в 10 раз — по пользователям, данным и пиковым запросам.
LLM нередко «угадывают» СУБД по функциональности (транзакции, поиск, аналитика), но пропускают то, что потом ломает проект на проде: доступы, аудит, регуляторику и утечки через операционные артефакты. В итоге рекомендация может быть технически подходящей, но неприемлемой по требованиям безопасности и комплаенса.
Спросите у команды не только «сколько пользователей», а как именно устроен доступ:
LLM часто советует «просто включить RBAC», не уточняя, есть ли в выбранной СУБД/сервисе детализированные политики, имперсонация, row‑level security, неизменяемые audit trails.
Уточняйте заранее:
Выбор СУБД меняется, если нужно клиентское шифрование, BYOK/HYOK или строгая ротация ключей.
LLM может не спросить про:
Если требуется гарантированное удаление, важны механизмы TTL/retention, политика бэкапов и процесс «забывания» данных.
Даже правильная СУБД не спасёт, если данные уходят в:
Это влияет на конфигурацию (редактирование логов, маскирование, запрет дампов на проде), а иногда и на выбор: нужен ли встроенный data masking, тонкая настройка аудита и «безопасные» инструменты экспорта.
Одна СУБД редко идеально закрывает весь продукт: у разных частей системы разные «законы физики» — задержки, объёмы, тип запросов, требования к согласованности. Поэтому в зрелых продуктах часто появляется связка из нескольких хранилищ, где каждое отвечает за свой класс задач.
Частая реакция LLM: «нужен отдельный поисковый движок». Иногда да — но не всегда.
Если поиск простой (фильтры, сортировки, префиксы, полнотекст по коротким полям) и объёмы умеренные, его можно закрыть:
Отдельная система поиска оправдана, когда нужны сложная релевантность, подсветка, морфология, «фасеты» на больших данных, высокая скорость переиндексации и независимое масштабирование. Важно помнить: «поиск» почти всегда живёт рядом с основной БД, а не вместо неё — нужно продумать обновление индекса, задержки и обработку удалений.
Транзакции (заказы, платежи, статусы) обычно требуют строгой целостности и понятной модели — это зона OLTP.
События (клики, просмотры, телеметрия) — это поток, большие объёмы и аналитические запросы. Часто выгоднее разделить:
Типовая связка выглядит так: OLTP‑БД хранит первичные данные, кэш ускоряет горячие чтения, очередь/стриминг буферизует события и развязывает сервисы по времени, а OLAP отвечает за отчёты и агрегаты.
Критично зафиксировать, что является источником истины и где допустима «устаревшая» информация (например, кэш может отставать на секунды, а отчёты — на минуты/часы).
Больше систем — больше отказов и операций: мониторинг, бэкапы, миграции, права доступа, инциденты, стоимость. Комбинацию стоит вводить только при явной боли (нагрузка, SLA, функциональность) и с планом синхронизации данных; иначе «архитектура из кубиков» начнёт съедать команду быстрее, чем принесёт пользу.
Рекомендация LLM по СУБД — это гипотеза, а не решение. Проверка должна быстро выявлять, какие требования модель не спросила и какие компромиссы она «спрятала». Ниже — практичный набор шагов, который можно выполнить за 1–3 дня до того, как команда «залипнет» в выбранную технологию.
Сделайте таблицу: критерии (транзакции, запросы, масштабирование, стоимость, операционная сложность, безопасность) → веса (например, 1–5) → кандидаты (2–4 СУБД) → явные компромиссы. Важно фиксировать почему поставили вес и какой риск принимаете.
Соберите минимальный стенд: 3–7 критичных запросов, примерные данные (хотя бы 1–10% от годового объёма), индексы и типовые обновления.
В тестах измеряйте: p95/p99 задержек, пропускную способность, блокировки/конфликты, рост индексов и размер хранилища, время восстановления/репликации, поведение при деградации.
Ведите «журнал допущений»: какие условия должны быть верны (нагрузка, консистентность, бюджет, RPO/RTO) и триггеры пересмотра (рост данных, новые отчёты, требования комплаенса). Это превращает выбор СУБД из мнения в управляемое решение.
Главная ошибка промпта — попросить «какую СУБД выбрать» и получить одно название без контекста. Гораздо полезнее требовать от LLM структуру: критерии → кандидаты → риски → план проверки. Тогда ответ становится проверяемым, а места с допущениями — видимыми.
Включите в запрос явное требование: «сначала перечисли критерии выбора, затем предложи 2–4 варианта, для каждого — ограничения и риски». Это снижает шанс, что модель подберёт популярную технологию «по инерции».
Попросите модель для каждого вывода указывать, на какой факт из вводных она опирается, а параметры, которых не хватает, помечать как unknown и превращать в вопросы. Например: объём данных, RPO/RTO, пики нагрузки, география, требования к транзакциям, срок хранения, бюджет на эксплуатацию.
Добавьте пункт: «Для выбранного варианта опиши 3 сценария, где он провалится, и что делать (шардирование, кэш, смена движка, вынос поиска/аналитики)». Это помогает увидеть, что именно ломается: латентность, блокировки, стоимость, сложность бэкапов.
Отдельным запросом попросите: «Опровергни предыдущую рекомендацию. Предложи, почему она неверна при других реалистичных допущениях». Сравните аргументы и уточните вводные.
Попросите выдавать результат в форме:
Типичная рекомендация LLM: «берите одну реляционную СУБД, она всё потянет». Ошибка в том, что транзакционная часть (заказы, оплаты, статусы) и аналитика (срезы по периодам, когортам, менеджерам) создают разные профили нагрузки. Одно хранилище часто превращается в компромисс: либо отчёты мешают транзакциям, либо транзакции ограничивают аналитические запросы.
Вопросы, которые стоило задать:
Тест, который подтвердит выбор:
LLM нередко предлагает «временные ряды» или «документы» без уточнения: сколько хранить, как удалять и что именно ищут пользователи. В результате выбирают хранилище, где ретеншн реализуется неудобно, а нужные запросы (по нескольким полям, с фильтрами и группировками) оказываются дорогими.
Вопросы:
Тест:
Слово «отношения» часто приводит LLM к графовой СУБД, хотя «отношения» могут быть обычными связями в реляционной модели. Граф оправдан, когда ключевая ценность продукта — многоскачковые обходы (2–6 переходов), поиск путей, рекомендации по связям. Если же связи в основном укладываются в один‑два JOIN’а, граф добавит сложность без заметной выгоды.
Вопросы:
Тест:
Главная ценность советов LLM — быстро собрать гипотезы и список уточняющих вопросов. Дальше важнее не «спорить про названия СУБД», а быстро пройти цикл требования → прототип → измерения → решение.
В этом месте удобно подключать TakProsto.AI: на платформе можно в режиме чата собрать рабочий скелет веб‑сервиса (React + Go + PostgreSQL), набросать ключевые сценарии чтения/записи, подготовить минимальные API и быстро получить основу для мини‑прототипов и нагрузочных прогонов. Если гипотеза по данным меняется, помогают снапшоты и откат, а при успешном результате — экспорт исходников и развёртывание/хостинг. Это особенно практично, когда есть требования по локализации и размещению: TakProsto.AI работает на серверах в России и не отправляет данные за пределы страны.
По стоимости можно начать с бесплатного тарифа, а для команды и процессов — перейти на pro/business/enterprise. Дополнительно у платформы есть реферальная программа и earn credits за контент — полезно, если вы всё равно планируете делиться результатами экспериментов и сравнений.
LLM обычно не делает инженерный расчёт. Она:
Результат — гипотеза, которую команда должна проверить цифрами и тестами.
Потому что это быстрый способ получить черновик вариантов и список компромиссов. Полезно на ранней стадии, чтобы:
Но это не заменяет нагрузочные тесты и оценку эксплуатации.
Дайте измеримые вводные и примеры:
Чем меньше «общих слов», тем меньше модель будет додумывать.
Чаще всего:
Если вы не описали запросы и SLA, модель почти неизбежно попадёт в «средний сценарий».
Проверьте, какой класс задач доминирует:
Самые типовые промахи:
Практика: сначала попросите LLM перечислить неизвестные параметры, и только потом — варианты.
Признаки повышенного риска:
Хорошее правило: любые «конкретные обещания» проверять документацией и прототипом.
Попросите LLM оценить не только функциональность, но и эксплуатацию:
Если ответ этого не покрывает — это «витринная» рекомендация.
Часто один контур не закрывает всё. Типовые комбинации:
Цена — рост сложности (мониторинг, права, миграции). Добавляйте второе хранилище только при явной боли.
Сделайте проверяемый процесс:
Чек-лист вопросов: сценарии нагрузки, запросы, транзакции, RPO/RTO, безопасность, бюджет.
Если LLM предлагает «одну СУБД на всё», это повод уточнить контуры OLTP и OLAP.
Матрица выбора: критерии → веса (1–5) → 2–4 кандидата → явные риски.
Мини‑прототип: 3–7 критичных запросов, реалистичные индексы, данные 1–10% годового объёма.
Нагрузочные тесты: p95/p99, конфликты/блокировки, рост индексов, восстановление.
Фиксируйте «журнал допущений» и триггеры пересмотра решения.