Разбираем, как ORM ускоряют разработку и снижают порог входа, но могут скрывать проблемы: N+1, лишние запросы, миграции, сложную отладку.
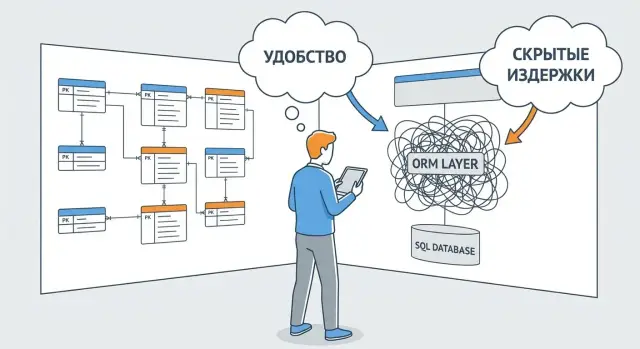
ORM (Object-Relational Mapping) — это прослойка между кодом приложения и реляционной базой данных. Вместо того чтобы писать SQL-запросы руками, вы работаете с привычными объектами и методами: «создай пользователя», «найди заказ», «обнови статус». ORM берёт на себя перевод этих действий в SQL и обратно, обещая меньше рутины и выше темп разработки.
Это особенно заметно, когда нужно быстро собрать рабочий бэкенд под продуктовую гипотезу. Например, в vibe-coding платформе TakProsto.AI вы можете в чате описать сущности и сценарии, а затем получить приложение (веб/сервер/мобильное) на типовом стеке — React на фронтенде, Go + PostgreSQL на бэкенде. В таких сценариях ORM и миграции помогают быстрее дойти до результата, но их «магия» всё равно требует понимания того, что реально выполняется в базе.
Главное обещание звучит просто: «пусть база данных будет деталью реализации». Команда пишет бизнес-логику, а ORM:
В итоге новичкам проще войти в проект, а код выглядит чище: меньше строк с SQL и меньше повторяющихся шаблонов.
ORM особенно хороши там, где много «обычного» CRUD и стандартных фильтров. Нужно быстро собрать админку, API для каталога, личный кабинет — и вы не хотите каждый раз вручную писать однотипные запросы, думать о параметрах, маппинге полей и преобразовании типов.
Ещё один плюс — единые практики: общий подход к транзакциям, валидации, стилю запросов и тестированию. Это уменьшает хаос в команде, где каждый «пишет SQL по-своему».
Цена удобства — в скрытой сложности. ORM добавляет абстракцию, а абстракции иногда прячут важные детали: сколько запросов реально уходит в БД, какие индексы используются, почему внезапно выросло время ответа. «Просто достать объект» может неожиданно потянуть за собой серию дополнительных запросов, лишнюю загрузку данных или блокировки.
Поэтому полезно относиться к ORM как к ускорителю разработки, а не как к замене понимания базы данных и SQL.
Чтобы осознанно пользоваться ORM (и предсказывать её поведение), важно понимать два внутренних механизма: как данные маппятся в объекты и как ORM отслеживает изменения.
В основе ORM — правила, по которым строки из таблиц становятся объектами в приложении.
Например: таблица users превращается в модель User, колонка email — в поле user.email, а связи вроде «у пользователя много заказов» описываются как user.orders. В этот момент ORM решает, какие таблицы соединять, какие ключи использовать и как восстановить объектный граф (объекты и их связи) из результата SQL-запроса.
Identity Map — это «список уже загруженных объектов». Если в рамках одного запроса к ORM вы дважды обращаетесь к одному и тому же пользователю по ID, ORM старается вернуть один и тот же объект в памяти, а не создавать копии и не обращаться к базе лишний раз.
Unit of Work — это «учёт изменений». ORM запоминает, какие объекты вы создали, изменили или пометили на удаление, а затем при save()/commit() превращает это в набор SQL-команд (INSERT, UPDATE, DELETE) и выполняет их транзакционно (в зависимости от настроек и паттерна работы).
Во многих проектах поверх ORM используют репозитории — слой, который прячет детали запросов и даёт методы уровня предметной области (например, findActiveUsers() вместо ручного SQL).
Обычно «из коробки» ORM покрывает:
Этот комфорт достигается ценой дополнительных решений «за вас» — и важно понимать, когда эти решения становятся невыгодными.
ORM сильнее всего окупается там, где в приложении много типовых операций с данными и важна скорость изменений. Он не отменяет знание SQL, но снимает значительную часть рутины — и это заметно уже на первых спринтах.
Создание, чтение, обновление и удаление сущностей — основная масса запросов в большинстве бизнес‑систем. ORM позволяет описать модель один раз и дальше работать с ней одинаково во всех частях кода: валидировать поля, сохранять изменения, поднимать связанные данные.
Это особенно удобно для:
В результате разработчик тратит меньше времени на однообразный SQL и преобразование результатов в объекты.
ORM задаёт общие правила: как называются поля, где лежат репозитории/модели, как строятся фильтры, как оформляются транзакции. Это снижает «зоопарк» подходов, когда каждый пишет SQL по‑своему.
Единообразие помогает быстрее:
Связи «один‑ко‑многим», «многие‑ко‑многим» и т. п. в ORM часто выражаются как понятные свойства и методы. Вместо ручного составления JOIN и аккуратного маппинга полей вы переходите по объектам: от заказа — к клиенту, от клиента — к адресам.
Это экономит время, когда нужно быстро собрать экран или API‑ответ из нескольких таблиц, а бизнес‑логика меняется часто. Важно лишь помнить: удобная навигация не гарантирует оптимальное число запросов — эту цену разберём дальше.
Проблема N+1 — один из самых частых «невидимых» счетов, которые выставляет ORM. Суть проста: вы делаете один запрос, чтобы получить список сущностей (это «1»), а затем ORM выполняет ещё N запросов, чтобы подтянуть связанные данные для каждой сущности по отдельности.
В коде это выглядит безобидно: цикл по списку и обращение к полю связи. На ревью читают бизнес-логику, а не мысленно «исполняют» ORM. К тому же тестовые данные обычно маленькие: 5–10 записей не показывают катастрофы, которая произойдёт на 5 000.
Типичный симптом — «вроде бы простой экран» внезапно тормозит в продакшене, а в логах/трейсах сотни одинаковых SELECT.
Ленивая загрузка (lazy loading) удобна: связь подгружается только когда вы к ней обратились. Но именно это и создаёт каскад.
Пример сценария: вы получили список заказов, а в шаблоне выводите имя клиента. Каждое обращение order.customer.name может триггерить отдельный запрос к таблице клиентов. Если дальше вы выводите позиции заказа, начинается «N+1 на N+1».
Eager loading (предзагрузка): просите ORM сразу загрузить нужные связи (через include/select_related/join fetch). Это превращает N+1 в 1–2 запроса.
Батчинг (batch loading): если JOIN раздувает результат, используйте загрузку связей пачкой: сначала список заказов, затем один запрос WHERE id IN (...) по всем клиентам.
Явные JOIN и проекции: для отчётов и списков часто выгоднее явно указать JOIN и выбрать только нужные поля, а не тянуть целые объекты.
Полезное правило: если код проходит по коллекции и внутри обращается к связям — сразу задайте себе вопрос «сколько запросов это сделает?» и проверьте это в логах SQL.
ORM часто создаёт ощущение, что работа с базой — это просто цепочка методов. Проблема в том, что реальный SQL остаётся «за кадром»: вы читаете аккуратный код, а внизу уезжает тяжёлый запрос с ненужными JOIN, подзапросами и сортировками. И заметить это легко слишком поздно — когда страница стала «тормозить» под нагрузкой.
ORM стремится быть универсальным: подтянуть связи, учесть фильтры, добавить безопасность. В итоге один невинный вызов может превратиться в запрос, который читает больше строк, чем нужно, и выполняет сложные операции на стороне БД.
Типичный симптом: локально всё быстро, а на продакшене — медленно. Данные растут, планы выполнения меняются, и неочевидные места начинают доминировать по времени.
Самые частые источники проблем — «удобные» конструкторы запросов:
LOWER(name)), фильтрация по вычисляемым свойствам.ORDER BY по полю без индекса или сортировка по полю из связанной таблицы, из-за чего БД вынуждена делать дорогие операции.OFFSET на больших таблицах, когда база всё равно просматривает много строк, чтобы пропустить первые N.Возвращать контроль нужно системно:
EXPLAIN/EXPLAIN ANALYZE) для медленных запросов — он быстро показывает, где узкое место.И важное правило: для критичных мест не бойтесь опускаться ниже ORM — использовать явные SQL-запросы или оптимизированные выборки, если так вы получаете предсказуемую производительность.
ORM часто обещает «чистую» объектную модель, но на практике модель быстро раздувается: сущности обрастают навигационными свойствами, атрибутами маппинга, аннотациями валидации и правилами загрузки связей. В итоге доменные классы становятся одновременно и бизнес-объектами, и схемой хранения, и конфигурацией доступа к данным.
Когда один и тот же класс отвечает за всё, появляются типичные симптомы: трудно понять, где заканчивается доменная логика и начинается инфраструктура; любое изменение таблицы тянет за собой правки «в бизнесе»; тесты начинают требовать реальной БД или сложных моков.
Ещё одна ловушка — чрезмерная «объектизация» данных. Например, желание выразить каждую связь как коллекцию объектов удобно в коде, но делает модель хрупкой: меняется кардинальность (1:N → M:N), добавляется промежуточная таблица с атрибутами — и половина кода переписывается.
С ORM вы рефакторите не только базу, но и граф объектов, правила загрузки, каскады, ограничения, а иногда и поведение сериализации (например, в API). Самое неприятное — скрытые зависимости: изменение одной связи может неожиданно влиять на сохранение сущности, порядок обновлений и обработку удалений.
Практичный подход — держать доменную модель «тонкой» и независимой от ORM:
Так вы снижаете связанность с конкретной схемой и упрощаете рефакторинг, не превращая ORM в центральную ось всей архитектуры.
ORM почти всегда приносит с собой миграции — «историю» изменений схемы, которую можно применить на любой среде одинаково: локально, на тесте и в продакшене. Это избавляет от ручных SQL-скриптов «в столе» и снижает риск, что у двух окружений окажутся разные таблицы и индексы.
Главный плюс миграций — воспроизводимость: вы видите, какая версия схемы соответствует версии приложения, и можете откатить изменения (если миграция действительно обратима).
Подводный камень в том, что миграция — это не только «изменить схему», но и поведение конкретной СУБД под нагрузкой. То, что проходит за секунды на тестовой базе, на продакшене может вызвать блокировки, рост задержек или даже падение по таймаутам.
Самые рискованные изменения обычно связаны со временем выполнения и блокировками:
NOT NULL без дефолта, когда нужно обновить существующие строки;Даже «простая» операция вроде переименования может превратиться в копирование данных — зависит от СУБД и конкретного SQL, который генерирует инструмент миграций.
Практика, которая чаще всего спасает нервы:
Если миграции — часть CI/CD, полезно держать чек-лист и короткую инструкцию для релизов в /docs/deploy, чтобы критичные изменения не проходили «на автопилоте».
ORM часто создаёт ощущение, что транзакции «просто работают»: открыл сессию, сохранил сущность — и всё надёжно. На практике ORM лишь оборачивает возможности СУБД, а ошибки возникают там, где границы транзакции неочевидны или конкуренция выше, чем предполагалось.
Обычно ORM предоставляет два режима: автокоммит (каждая операция — отдельная транзакция) и явные транзакции (begin/commit/rollback). Автокоммит удобен, но опасен: несколько связанных изменений могут «разъехаться» по времени и частично сохраниться.
Важно понимать, где именно ORM делает flush (отправляет SQL в БД) — это может произойти не только на commit, но и перед выполнением запросов. Неожиданный flush иногда приводит к блокировкам, нарушению уникальности или ошибкам в середине логики.
Распространённый подход — «транзакция на запрос». Он упрощает согласованность: либо весь запрос успешен, либо откат. Но если внутри запроса есть сетевые вызовы, отправка писем или обращение к внешним сервисам, транзакция становится слишком длинной и удерживает блокировки дольше нужного.
Для фоновых задач проблема обратная: ретраи. Если задача упала после частичного коммита, повтор может создать дубли. Здесь помогают идемпотентность, уникальные ключи и аккуратное разделение: «сделать изменения» в короткой транзакции, а «побочные эффекты» — после коммита.
Уровень изоляции (например, READ COMMITTED vs REPEATABLE READ) влияет на «видимость» данных и аномалии чтения. ORM может скрыть это за настройкой, но эффект проявится в неожиданных расхождениях отчётов или проверок «перед записью».
Пессимистические блокировки (SELECT ... FOR UPDATE) полезны, когда конфликт вероятен, но они снижают параллелизм и требуют коротких транзакций.
Оптимистическая блокировка (версионное поле/row_version) часто лучше для веб-нагрузки: при конфликте обновление не затирает чужие изменения, а падает с ошибкой конкуренции — и вы решаете, как корректно повторить операцию или показать пользователю конфликт.
Кэш в ORM часто даёт «бесплатное» ускорение: меньше походов в базу, быстрее ответы, ниже нагрузка. Но кэш — это не только скорость, а ещё и обязательства по согласованности данных. Если их не учитывать, вы получите загадочные баги: пользователи видят старые значения, отчёты «прыгают», а исправления в базе не отражаются в приложении.
Почти во всех ORM есть кэш на уровне сессии/единицы работы (например, на время запроса или транзакции). В нём хранятся уже загруженные сущности: если вы второй раз запросите тот же объект по ключу в рамках одной сессии, ORM часто вернёт его из памяти, не делая SQL.
Важно понимать границы:
clear/evict;Вторичный кэш (на уровне приложения) или внешний (Redis/Memcached) работает между запросами и даже между экземплярами сервиса. Риск здесь главный: устаревшие данные.
Типичные причины:
Ключевой вопрос: когда и как инвалидировать кэш. Простое TTL снижает боль, но не гарантирует актуальность.
Практики, которые помогают:
Кэширование в ORM стоит включать осознанно: заранее определите, где важнее скорость, а где — строгая актуальность.
ORM создаёт ощущение «всё под контролем»: вы пишете запросы на языке объектов, а SQL как будто «сам» получается правильным. Проблема в том, что реальные ошибки и замедления происходят именно на уровне сгенерированного SQL — и без инструментов наблюдаемости вы видите только верхушку айсберга.
Когда запрос написан вручную, вы сразу видите текст SQL, параметры, план выполнения и можете воспроизвести проблему в консоли БД. В ORM между вашим кодом и БД появляется слой преобразований: ленивые связи, автоматические JOIN’ы, подзапросы, пагинация, фильтры по умолчанию, «мягкое удаление» и т. п.
В итоге ошибка может выглядеть как «не найдено поле» или «таймаут», но корень будет в неожиданном SQL: лишний JOIN, неправильная группировка, сортировка по неиндексированному полю или десятки запросов вместо одного.
Минимум, который стоит логировать в dev/stage:
Чтобы логи не превратились в мусор, включайте их точечно: по уровню (только медленные запросы), по маршруту (например, /checkout), по пользователю/корреляционному ID или на ограниченное время.
Один из самых полезных сигналов — «сколько SQL-запросов выполняется на один HTTP-запрос». Резкий рост почти всегда означает N+1 или неожиданную ленивую загрузку.
Добавьте метрики: p95/p99 времени запросов к БД, суммарное время в БД на запрос пользователя, число запросов, число соединений/ожиданий пула. А для сложных сценариев подключите распределённую трассировку: так вы увидите цепочку «запрос → ORM → конкретные SQL», где именно теряется время и какие вызовы порождают лишние обращения к БД.
Практический момент для платформенной разработки: если вы быстро поднимаете сервисы и окружения (например, через TakProsto.AI с деплоем и хостингом), полезно закрепить базовые SLO и метрики по БД «по умолчанию». Тогда регресс (вроде внезапного N+1) ловится не на глаз, а по наблюдаемости, а откатить неудачное изменение помогает механизм снапшотов и rollback.
ORM часто воспринимают как «щит» от проблем безопасности, но он работает только при правильном использовании. По умолчанию многие ORM действительно снижают риск SQL-инъекций за счёт параметризации и безопасной сборки запросов. Однако стоит сделать шаг в сторону — и вы снова на территории ручного SQL со всеми его ловушками.
Помогает: когда вы строите запросы через API ORM (фильтры, условия, сортировки), значения обычно передаются как параметры, а не как часть строки SQL. Это значительно усложняет инъекции.
Мешает: когда вы начинаете вставлять «сырой» SQL, использовать нестандартные выражения или динамически формировать куски запроса. Частая проблема — желание «гибкости», из‑за которой разработчик склеивает фрагменты SQL из пользовательского ввода.
Правило простое: пользовательские данные — только параметрами. Опасный паттерн — конкатенация:
WHERE name = '" + userInput + "' — даже если вы «экранируете», это легко сломать.ORDER BY ${field}) — это не про значения, а про структуру запроса; параметризация тут не спасает.Если нужно динамическое условие, лучше:
ORM не заменяет модель прав. Если приложение подключается к БД под суперпользователем, никакой ORM не спасёт от ошибок логики.
Практики, которые реально снижают риск:
update/delete без фильтра;Итог: ORM снижает вероятность инъекций, но безопасность всё равно держится на дисциплине построения запросов и продуманной модели прав.
ORM отлично закрывает повседневный CRUD, но не обязана быть единственным способом работы с данными. Важно заранее определить границы: где ORM ускоряет разработку, а где начинает мешать — либо по производительности, либо по прозрачности.
Если вы регулярно сталкиваетесь с ситуациями ниже, стоит вынести часть запросов из ORM:
При этом «чистый SQL» не означает отказ от ORM целиком: часто достаточно query builder или параметризованных SQL-шаблонов для конкретных эндпоинтов.
Практичный вариант — разделить сценарии:
Чтобы уменьшить скрытые издержки, полезно стандартизировать: заранее определите «точки выхода» из ORM, где команда имеет право писать SQL, и оформляйте это как отдельные репозитории/методы с понятными контрактами.
Так ORM остаётся ускорителем разработки, а не источником сюрпризов в производительности и сопровождении.
Если вы строите продукт в условиях ограниченного времени, удобно сочетать дисциплину работы с ORM и быстрый цикл поставки. В TakProsto.AI это поддерживается «планированием» (planning mode), экспортом исходников, деплоем и хостингом, а также снапшотами и откатом — но принципы выше всё равно остаются ключевыми: проверяйте фактический SQL, считайте запросы, держите миграции безопасными и отделяйте домен от инфраструктуры.
ORM — это слой, который маппит таблицы и строки БД на объекты/модели в коде и обратно. Вы вызываете методы уровня домена (создать/найти/обновить), а ORM генерирует SQL и выполняет его, ведя учёт загруженных объектов и изменений.
Используйте ORM, когда в проекте много типового CRUD и стандартных фильтров: админки, личные кабинеты, каталоги, простые API. Он ускоряет разработку за счёт единообразия кода, готовых миграций и удобной работы со связями.
Если запросы в основном «обычные» и часто меняются требования — ORM обычно окупается.
Типовой «комплект»:
SELECT/INSERT/UPDATE/DELETE без ручного SQLНо за это вы платите «магией» и риском не заметить неэффективный SQL.
Identity Map возвращает один и тот же объект для одной записи (по ключу) в рамках сессии/запроса, чтобы не плодить дубликаты и не ходить в БД лишний раз.
Unit of Work отслеживает, какие объекты вы изменили/создали/удалили, и на commit() формирует пакет SQL-команд, часто в одной транзакции. Практика: явно понимайте, когда происходит flush — он может случиться раньше commit().
N+1 — это когда вы делаете 1 запрос за списком сущностей и ещё N запросов за связанными данными для каждой сущности.
Минимальный набор мер:
include/select_related/join fetch)WHERE id IN (...)), если JOIN раздувает результатИ всегда проверяйте факт: сколько SQL ушло на один HTTP-запрос.
Потому что «красивый» код на ORM может скрывать тяжёлый SQL: лишние JOIN, сортировки без индексов, OFFSET на больших таблицах, фильтры по вычисляемым выражениям.
Чтобы вернуть контроль:
EXPLAIN/EXPLAIN ANALYZE для медленных запросовОпасны операции, которые блокируют таблицы или требуют переписывать много данных:
NOT NULL без дефолта с обновлением существующих строкБезопасный подход — пошаговые обратно-совместимые миграции: сначала добавить новое, развернуть код, затем удалить старое. Долгие backfill-обновления выносите в отдельные батчи.
Частые ловушки:
flush посреди логикиПрактика:
First-level кэш (кэш сессии) живёт недолго и может скрывать проблемы: в рамках одной сессии объект берётся из памяти, а не из БД.
Вторичный/внешний кэш ускоряет сильнее, но требует стратегии согласованности:
Если данные часто меняются и важна строгая актуальность — кэшируйте выборочно.
Пишите SQL (или используйте query builder), когда нужны:
Компромисс работает лучше всего: ORM для записи и простого чтения, SQL — для витрин, аналитики и тяжёлых списков. В команде полезно заранее закрепить «точки выхода» из ORM отдельными методами/репозиториями.
SELECT ... FOR UPDATE — только там, где конфликт действительно вероятен