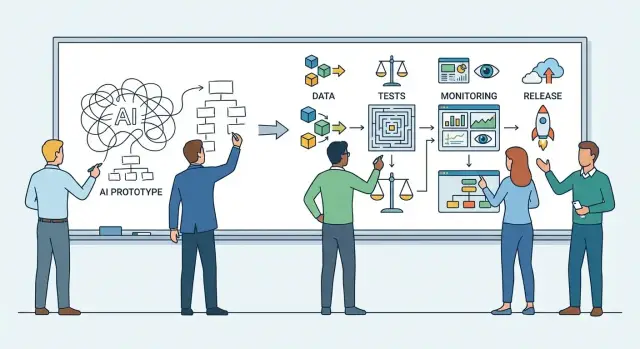
Практический план: как превратить AI‑прототип в продакшен‑систему — требования, данные, архитектура, MLOps, тесты, безопасность, мониторинг и поэтапный релиз.
Прототип AI‑решения обычно отвечает на вопрос «в принципе работает?». Его задача — быстро показать ценность: демо на ограниченных данных, ручные проверки, минимум интеграций.
Продакшен‑решение отвечает на другой вопрос: «можно ли на это полагаться каждый день?». Здесь важны не только ответы модели, но и обязательства перед бизнесом и пользователями: SLA по доступности и времени ответа, поддержка, управление инцидентами, юридические риски и понятные правила изменения системы.
Перед переносом стоит зафиксировать цель в терминах результата, а не технологии: какую задачу решаем, кому помогает система и как измеряем пользу. Например: снизить нагрузку на поддержку на 20%, ускорить обработку заявок до X минут, повысить конверсию в целевое действие.
Если цель не определена, прототип легко «перепрыгивает» между сценариями, а команда начинает оптимизировать то, что красиво выглядит в демо, но не влияет на ключевые метрики.
У продакшен‑готовности всегда несколько осей:
Важно договориться, какие пороги считаются достаточными, и кто принимает решение «выпускаем».
Типичные причины — не «плохая модель», а разрыв между ожиданиями и операционной реальностью:
Если заранее принять, что продакшен — это дисциплина измерений, поддержки и управления рисками, переход становится проектом с понятными этапами, а не «героическим релизом».
Перед тем как «усиливать» прототип, важно понять, что именно у вас уже есть. Аудит — это не бюрократия, а способ быстро отделить работающие части от случайных удач демо и оценить, сколько усилий реально нужно до продакшена.
Составьте полный список компонентов, из которых складывается результат:
Если уже есть репозиторий, зафиксируйте, что является «истиной»: код, конфиги, параметры запуска, секреты. Цель — чтобы любой член команды мог воспроизвести текущий результат без личных подсказок.
Отдельно выпишите всё, что делалось вручную и потому работало в демо, но не масштабируется: ручной подбор примеров, перезапуск до «удачного» ответа, копирование данных, разовые правки промпта под конкретного клиента.
Также оцените долю ручной разметки/проверки: где без человека нельзя (юридически значимые ответы, финансовые операции), а где это временная подпорка. Это поможет заранее спроектировать контур human‑in‑the‑loop.
Соберите список пробелов, которые в прототипе обычно отсутствуют: логи запросов и ответов, тесты, версионирование промптов и данных, минимальная документация (что делает система, ограничения, известные ошибки). Именно этот долг чаще всего превращает «почти готово» в месяцы работы.
Переход от демо к продакшен‑готовой системе начинается не с выбора модели, а с фиксации того, что именно считается «работает» — и что считается провалом. Чем точнее требования, тем проще принять решения по данным, архитектуре, тестированию и мониторингу.
Опишите ключевые сценарии: кто пользователь, какая задача, какой контекст, какой ожидаемый результат. Отдельно зафиксируйте критические ошибки — то, что недопустимо даже при высокой средней точности.
Примеры недопустимого:
Определите измеримые SLI и целевые SLO по нескольким осям:
Важно заранее договориться, что считается «успешной задачей» и как собирается разметка (пользовательская оценка, экспертная, бизнес‑метрика).
Уточните ограничения: поддерживаемые языки, регионы, устройства, каналы (веб, мобильное приложение, API), требования к хранению данных и логов.
Затем опишите режимы: онлайн‑ответы, батч‑обработка, ассистент оператору (человек подтверждает), автодействия (модель инициирует действие). Для каждого режима задайте отдельные SLO и правила безопасности — особенно там, где ошибки приводят к реальному ущербу.
AI‑прототип часто живёт на «удобной» выгрузке и ручных правках. В продакшене же данные становятся продуктом: у них есть владельцы, правила использования, качество и понятный путь от источника до модели.
Сначала перечислите все источники и зафиксируйте, на каких основаниях вы их используете:
Хорошая практика — завести короткий «паспорт источника»: владелец, назначение, юридические ограничения, частота обновления.
Для продакшена нужны измеримые правила качества. Проверьте:
Определите, где хранятся сырые данные и где — подготовленные наборы:
Параллельно настройте права доступа по ролям и аудит обращений к чувствительным данным.
Если требуется разметка (классы, правильные ответы, оценка качества), заранее договоритесь:
Когда эти правила оформлены, данные перестают быть узким местом — и становятся устойчивым фундаментом продакшен‑системы.
Продакшен‑архитектура начинается не с выбора модели, а с ответа на вопрос: какую часть работы делает AI, а какую — система вокруг него. Чем чётче границы, тем легче масштабировать, тестировать и объяснять результаты бизнесу.
Обычно есть четыре рабочих сценария:
Стратегию выбирают от требований: точность, объяснимость, стоимость, скорость обновления знаний.
Типовая продакшен‑сборка выглядит так:
Важно разделять: модель отвечает за генерацию/ранжирование, а бизнес‑логика и проверки (валидация, политики, расчёты, дедупликация) — за пределами модели.
AI‑компоненты должны «падать красиво». Продумайте уровни деградации: снижение контекста, переключение на более дешёвую модель, фолбэк на правила/поиск, либо эскалация на оператора.
Отдельно зафиксируйте, какие ошибки допустимы (например, «не уверен — уточняю»), а какие блокируются (галлюцинации в финансовых цифрах, PII в ответе). Это архитектурное решение, а не настройка промпта.
Прототип часто «работает на ноутбуке», потому что много решений остаётся в голове автора: какие данные брались, какой промпт оказался удачным, какие параметры стояли в конфиге. В продакшене это превращается в риски: качество внезапно меняется, а команда не может быстро объяснить — почему и что именно поменялось.
Версионируйте не только код, но и:
Практика: у каждого релиза должен быть «чек‑лист воспроизводимости» — по одному идентификатору на данные, модель, промпт и образ.
Пайплайн CI/CD для AI обычно включает: сборку окружения, статические проверки, тесты качества (см. раздел про тестирование), публикацию артефактов и быстрый откат. Откат — это не «починим позже», а заранее подготовленный путь вернуть предыдущую связку model + prompt + config.
Разведите dev / stage / prod и зафиксируйте правила: что можно менять без ревью, что требует ручного подтверждения, какие метрики должны пройти порог в stage перед продом. Это дисциплинирует эксперименты и снижает шанс «тихих» регрессий.
Контейнеры и lock‑файлы зависимостей делают окружение предсказуемым. Дополнительно фиксируйте seed (где применимо), параметры рантайма и конфигурацию запросов к LLM (temperature/top_p/max_tokens). В итоге любой инцидент можно разобрать по цепочке: какой релиз, какие данные, какие настройки — и воспроизвести поведение локально или в stage.
Прототип часто «выглядит хорошо» на нескольких демо‑запросах. В продакшене же система встречает тысячи разных формулировок, шумные данные и неожиданные контексты. Поэтому тестирование AI‑решения нужно строить не как один отчёт по метрикам, а как набор слоёв, которые ловят разные классы ошибок.
Начните с базовой пирамиды:
Так вы сможете быстро понять, «сломалась логика» или просело именно качество генерации.
Соберите набор эталонных кейсов (golden set): реальные запросы пользователей, типовые сценарии поддержки, внутренние бизнес‑кейсы. Для каждого — ожидаемый результат или критерии оценки (например, обязательные факты, допустимый тон, формат). На основе golden set строится регрессия: каждый релиз (модель, промпт, фильтры, retrieval) прогоняется одинаково, а результаты сравниваются с базовой версией.
Отдельно тестируйте «опасные» запросы: провокации на токсичность, попытки вытащить персональные данные, ввод с конфиденциальными фрагментами, вопросы, где модель склонна галлюцинировать. Эти тесты должны быть обязательными, а не «по желанию».
Определите пороги прохождения: например, не ниже X по качеству на golden set и ноль блокирующих нарушений (PII, токсичность). Зафиксируйте процесс «стоп‑линии»: если метрики падают или растёт доля критических ошибок, релиз не идёт дальше, пока причина не найдена и не подтверждена повторным прогоном.
Прототип часто живёт в «песочнице»: ограниченный доступ, минимум логов, ручные проверки. В продакшене AI‑система становится частью бизнес‑процесса — значит, к ней применяются правила безопасности, юридические требования и внутренние политики.
Начните с инвентаризации входов и выходов модели и разделите данные по категориям: персональные (PII), коммерческие (условия договоров, цены), конфиденциальные (внутренние документы, финансы), а также «публичные». Для каждой категории определите:
Это решение сильно влияет на архитектуру: например, для конфиденциальных данных может понадобиться изоляция окружений или строгая политика «не логировать содержимое».
У продакшен‑готовой системы должен быть понятный контроль доступа: роли (кто может запускать, администрировать, просматривать логи), ротация ключей API, хранение секретов в секрет‑хранилище, а не в переменных окружения «на сервере».
Обязательно включите аудит действий: кто и когда менял промпты, настройки фильтров, источники данных, лимиты. Это ускоряет расследования и упрощает соответствие требованиям.
AI может «утечь» данными или выполнить вредный инструктаж. Введите защитные меры на уровне вывода: фильтры токсичности/PII, ограничения на типы ответов, проверку ссылок и команд.
Отдельно продумайте защиту от prompt injection: не доверяйте тексту пользователя как инструкциям, разделяйте системные и пользовательские контексты, и валидируйте доступ к данным при использовании RAG (по принципу «минимально необходимого»).
Согласуйте требования (GDPR/152‑ФЗ, отраслевые нормы, корпоративные политики). Зафиксируйте сроки хранения логов, правила маскирования, процедуру удаления по запросу и список сотрудников с доступом.
Если нужно — опишите это во внутреннем документе и свяжите с релизным процессом (например, чек‑лист перед запуском) — так безопасность не станет «разовой задачей».
Прототип часто выглядит «быстрым и дешёвым» просто потому, что им пользуются несколько человек и нерегулярно. В продакшене важнее другое: предсказуемая скорость ответа, контролируемая стоимость запроса и способность выдерживать рост нагрузки без сюрпризов.
Начните с измерений не «на ноутбуке», а в окружении, максимально близком к боевому. Снимайте показатели на типичных сценариях и на хвостах распределения (P95/P99), потому что именно они формируют ощущение качества у пользователей.
Ключевые метрики:
Самые практичные способы снизить стоимость и ускорить ответ:
Опишите «правила движения» заранее: лимиты на пользователя/клиента, rate limiting, очереди для тяжёлых задач, автоскейлинг по загрузке и по длине очереди. Отдельно продумайте изоляцию: чтобы один шумный клиент не ухудшал сервис всем.
В пиковые моменты система должна ухудшаться предсказуемо:
Так вы удержите SLA, не «сжигая» бюджет и не ломая пользовательский опыт.
Когда AI‑прототип попадает к реальным пользователям, без наблюдаемости он быстро превращается в «чёрный ящик»: непонятно, почему просело качество, где растёт стоимость и какие запросы ломают сценарии. Мониторинг нужно проектировать заранее — как часть продукта, а не как «после релиза посмотрим».
Логи должны отвечать на три вопроса: что пришло, что модель/система вернула и в каком контексте это произошло.
Логируйте:
Важно: храните сырые тексты только там, где это оправдано политикой данных; чаще достаточно безопасных «срезов» и выборок для разборов.
Качество падает не только из‑за багов. Отслеживайте дрейф данных (тематика, язык, длина запросов), дрейф метрик (например, точность/полнота по проверочным наборам), аномалии (всплеск отказов, «пустые» ответы), а также жалобы пользователей и ручные теги «плохой ответ». Это даёт раннее предупреждение до массовых инцидентов.
Соберите дашборды вокруг SLO: доступность, p95 latency, доля фолбэков, rate ошибок, стоимость на 1k запросов, показатели качества. Настройте алерты с порогами и «окнами», чтобы не утонуть в шуме.
Дальше — дисциплина: разбор инцидентов, пополнение датасета реальными кейсами, ретест и повторный прогон регрессии перед выкладкой. Так мониторинг становится механизмом постоянного улучшения, а не просто витриной метрик.
Запуск — это не «включили и забыли», а управляемый эксперимент с чёткими границами риска. Хороший rollout снижает вероятность массовых инцидентов, а план отката делает проблему неприятной, но не катастрофической.
Самый безопасный вариант — поэтапное включение:
Важно заранее определить «ворота» перехода на следующий этап: какие метрики должны быть не хуже baseline и сколько времени наблюдения достаточно.
План отката должен быть простым и быстрым: переключение на предыдущую модель/промпт/индекс или на деградированный режим (например, без генерации — только поиск).
Добавьте kill switch — явный механизм мгновенно отключить рискованную функциональность без релиза (фича‑флаг, конфиг). Пропишите триггеры: рост жалоб, всплеск ошибок, ухудшение качества, подозрение на утечку данных.
Заранее подготовьте короткое описание: что меняется, какие новые ограничения, как выглядит «правильный» результат и что считать багом. Поддержке нужен шаблон ответов и сценарий эскалации (кому и за сколько минут).
Перед первым процентом трафика проверьте:
Если чек‑лист не закрыт — rollout откладывается. Это дешевле, чем чинить инцидент на всей аудитории.
Переход от демонстрационного AI‑прототипа к продакшен‑готовой системе — это в первую очередь организационная задача. Даже сильная модель «ломается» в реальности, если не ясно, кто принимает решения, как вносятся изменения и что делать при инциденте.
Соберите минимальный кросс‑функциональный состав и закрепите ответственность письменно (например, в RACI‑матрице):
Важно заранее определить единого ответственного (DRI) за продакшен‑сервис: кто принимает финальные решения при конфликте приоритетов.
Опишите простой, повторяемый поток:
Запрос на изменение (feature/фикс/обновление модели) с ожидаемым эффектом и метриками.
Оценка риска: влияние на пользователей, безопасность, стоимость, деградацию качества.
Ревью: техническое (код/инфра), ML‑ревью (данные/метрики), безопасность.
Релиз: запуск по чек‑листу, коммуникации, план отката.
Пост‑анализ: что пошло не так/хорошо, какие действия закрепляем в процессах.
Держите в актуальном виде: схему архитектуры, описание API и версий, ограничения (что система не делает), известные риски и обходные пути, инструкции для дежурных.
Сделайте дорожную карту на 1–2 квартала с бюджетом и зависимостями. Отдельно зафиксируйте критерии остановки/замены: например, если стоимость запроса превышает порог, качество не растёт после N итераций, или требования комплаенса становятся невыполнимыми. Это защищает команду от бесконечной «полировки» решения без бизнес‑эффекта.
Если вы в российском контуре и хотите сократить путь от «работает в демо» до управляемого сервиса, удобно использовать платформу, которая закрывает не только генерацию, но и часть инженерных задач вокруг неё. TakProsto.AI — vibe‑coding платформа для российского рынка: вы описываете продукт в чате, а дальше собираете веб‑, серверное или мобильное приложение с возможностью экспорта исходников, деплоя и хостинга.
В контексте шагов из статьи это особенно полезно там, где прототип обычно разваливается: быстрые итерации по архитектуре (React на фронтенде, Go + PostgreSQL на бэкенде, Flutter для мобильных клиентов), окружения и откаты через снапшоты, а также планирование изменений в planning mode. Для команд важны и операционные детали: кастомные домены, понятные тарифы (free/pro/business/enterprise) и возможность масштабировать проект без ручной сборки инфраструктуры.
Отдельный плюс для продакшена в РФ — данные не «уезжают» за границу: платформа работает на серверах в России и использует локализованные и opensource LLM‑модели. А если вы делитесь опытом внедрения, можно получить кредиты через earn‑credits программу или пригласить коллег по реферальной ссылке — это помогает финансировать пилоты и первые продакшен‑итерации.
Зафиксируйте цель в терминах результата: какую метрику вы улучшаете и для кого. Примеры:
Если цель не определена, команда начинает оптимизировать «красоту демо», а не бизнес-эффект.
Обычно критерии лежат в нескольких осях и должны быть согласованы заранее:
Важно назначить, кто принимает финальное решение «выпускаем».
Сделайте инвентарь всего, что влияет на результат:
Цель — чтобы любой член команды мог воспроизвести результат без «магических» подсказок автора.
Потому что в демо часто скрыты ручные действия и «подгонка»:
Выявите ручные шаги и решите, где нужен human-in-the-loop, а где — автоматизация и проверки.
Опишите SLI и целевые SLO по ключевым осям:
Отдельно определите, что считается «успешной задачей» и как вы собираете разметку/оценку.
Начните с «паспорта источника» для каждого набора данных:
Без этого данные становятся источником риска: от блокировки проекта до утечек и нарушений комплаенса.
Выбор делайте от требований, а не от «модности»:
Если нужны свежие знания и проверяемость, чаще выигрывает RAG с хорошими политиками доступа и логированием retrieval.
Спроектируйте «красивое падение» заранее:
Для запуска добавьте kill switch (фича-флаг/конфиг), чтобы отключать опасную функциональность без нового релиза.
Версионируйте всё, что меняет результат:
Хорошая практика — один идентификатор релиза, который однозначно связывает model + prompt + data + config и позволяет быстро откатиться.
Соберите golden set из реальных запросов и кейсов и гоняйте регрессию на каждом релизе. Дополнительно обязательны тесты на:
Задайте пороги и «стоп-линию»: при падении метрик или критических нарушениях релиз не продвигается дальше.