Пошаговый план: архитектура, выбор LLM, UX чата, RAG с базой знаний, безопасность, стриминг, оценка качества, стоимость и запуск AI‑приложения.
Чат на базе LLM — не «фича ради фичи», а интерфейс для решения конкретных задач пользователя. Если на старте не зафиксировать сценарии и критерии успеха, вы рискуете получить красивый диалог, который не влияет на продуктовые метрики.
На практике полезно сразу ответить на два вопроса:
Если вам нужно быстро проверить гипотезу и собрать рабочий прототип «чат + действия + деплой», это можно делать не только вручную. Например, на TakProsto.AI (vibe-coding платформа для российского рынка) многие команды собирают черновик веб‑приложения с чатом и бэкендом из диалога — а затем уже доводят архитектуру до production-уровня.
Встроенный чат особенно полезен там, где у пользователя много вопросов и ему нужно быстро сориентироваться:
Есть классы задач, где LLM может уверенно ошибаться, и это критично:
Если такие запросы ожидаемы, заранее решите: ограничивать темы, подключать проверяемые источники, требовать подтверждения или переводить на человека.
Сформулируйте портреты пользователей (например, новичок/опытный) и выберите 3–5 основных сценариев, которые дают максимальную ценность. Для каждого сценария запишите:
Определите измеримые метрики до разработки:
Эти цели станут основой для архитектуры, данных и UX — и помогут не распыляться на второстепенные «умные ответы».
Самый понятный старт — собрать «минимальный конвейер», который уже работает end‑to‑end, а затем усложнять по мере необходимости.
В типовом варианте поток выглядит так:
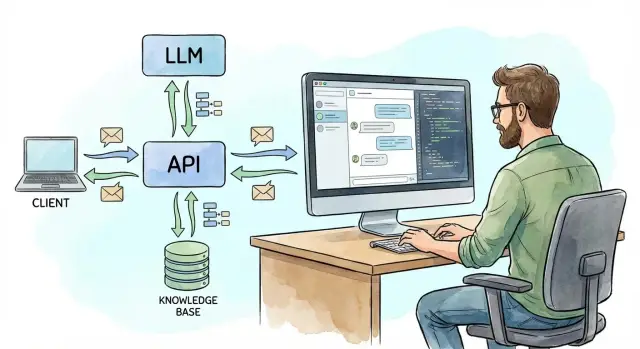
Ключевая мысль: клиент не должен ходить к LLM напрямую. Ваш API — точка контроля, где можно включить авторизацию, лимиты, логирование и защиту.
Контекст — это не только последние реплики. Часто вам нужны: история, системные настройки, вложения, результаты поиска по базе знаний.
Практичный расклад по хранилищам:
Не пытайтесь «пихать всё» в запрос к LLM. Обычно вы выбираете небольшой фрагмент истории + релевантные факты.
На раннем этапе LLM‑логику можно держать внутри основного backend. Отдельный сервис для AI имеет смысл, когда:
Чтобы архитектура оставалась управляемой, разделите роли:
Такой каркас легко расширить: добавлять инструменты, подключать базу знаний (RAG) и улучшать UX, не ломая основу.
Выбор модели — это не поиск «самой умной», а подбор оптимального баланса под ваш сценарий: где важнее точность, где — скорость, а где — предсказуемая стоимость. Лучше заранее решить, какие ответы считаются хорошими (тон, глубина, допустимые ошибки), и от этого плясать.
Качество обычно меряют на ваших реальных запросах: поддержка русского языка, умение следовать инструкциям, корректные форматы (таблица, JSON), устойчивость к «галлюцинациям» и аккуратность с фактами.
Цена зависит не только от тарифов, но и от того, сколько токенов вы отправляете (история чата, RAG‑контекст, системные инструкции) и сколько модель отвечает. Иногда более дорогая модель оказывается выгоднее, если даёт короче и точнее ответы и снижает число повторных запросов.
Скорость важна для UX: пользователи ждут быстрый старт ответа и ровный стриминг. Обратите внимание на задержку первого токена и стабильность под нагрузкой.
Лимиты: квоты по запросам, ограничения параллельности, дневные лимиты, доступность нужных регионов — всё это может неожиданно «сломать» запуск.
Модель через API — быстрее в запуске и проще в поддержке (обновления, масштабирование, новые функции). Локальная/частная модель даёт больше контроля над данными и предсказуемость, но потребует компетенций в инфраструктуре, MLOps и оптимизации производительности.
Для российского рынка отдельным критерием часто становятся юрисдикция и размещение данных. Например, TakProsto.AI делает акцент на работе на серверах в России и использовании локализованных/opensource LLM, что может упростить обсуждение комплаенса на старте — особенно для внутреннего чата по корпоративным документам.
Сделайте слой абстракции: единый интерфейс LLMClient внутри бэкенда, а конкретная модель выбирается конфигурацией (провайдер, модель, параметры, таймауты, ретраи). Тогда вы сможете A/B‑тестировать модели, держать «запасной вариант» на случай сбоев и постепенно менять поставщика без переписывания всего чата.
Хороший чат на LLM начинается не с «магического» запроса, а с управляемого контракта: что модель должна делать, чего не должна, в каком стиле и в каком формате возвращать результат. Промпт — это часть продукта, и к нему стоит относиться как к коду.
Системные инструкции задают «рамку» поведения:
Удобно держать единый шаблон, в который подставляются переменные. Пример структуры:
Такой шаблон упрощает поддержку и делает поведение чата стабильным при росте функциональности.
Если вы даёте модели документы или фрагменты базы знаний, прямо попросите:
Это не убирает ошибки полностью, но заметно снижает уверенные выдумки.
Промпты стоит версионировать (например, support_v12) и менять так же аккуратно, как бизнес-логику: фиксировать цель изменения, примеры до/после, дату и владельца. Для улучшений используйте A/B‑тесты: часть трафика отправляйте на новую версию и сравнивайте метрики (доля эскалаций в поддержку, удовлетворённость, время до решения, число уточнений). Это помогает улучшать ответы без «эффекта неожиданности» для пользователей.
RAG (Retrieval‑Augmented Generation) нужен, когда вы хотите получать ответы по вашим документам (регламенты, база поддержки, справка продукта, договоры) без дообучения модели. Вместо «угадываний» LLM сначала находит релевантные фрагменты в вашей базе знаний, а затем формирует ответ, опираясь на найденный контекст. Это упрощает обновления: поменялся документ — поменялись ответы.
Обычно RAG строится как конвейер:
Загрузка данных: файлы, страницы справки, тикеты, записи в CRM.
Разбиение на фрагменты (chunking): длинные тексты режутся на небольшие куски, чтобы их удобно было искать и отдавать в контекст. Важно сохранять «смысловые границы» (заголовки, пункты, таблицы).
Эмбеддинги: для каждого фрагмента считаются векторные представления.
Векторное хранилище: туда складываются эмбеддинги + метаданные (источник, дата, продукт, отдел, уровень доступа).
На практике качество сильно зависит от аккуратного разбиения и метаданных: они помогают не только находить «похожие» тексты, но и отсеивать лишнее.
При запросе пользователя вы делаете поиск по векторному хранилищу и выбираете top‑k фрагментов (например, 3–10). Почти всегда нужны фильтры:
Чтобы повысить доверие и упростить проверку, добавляйте источники прямо в ответ:
Хорошее правило: если модель не нашла уверенных источников, пусть честно скажет, что в базе нет ответа, и предложит, где искать дальше (например, /help или обращение в поддержку).
Качество ответов чата почти всегда упирается не в модель, а в то, какие данные вы ей даёте и как вы ограничиваете доступ. На этом этапе важно собрать источники, привести их к единому виду и сразу заложить правила, кто и что может видеть.
Для чата внутри продукта обычно подходят:
Практичное правило: начинать с 1–2 самых “чистых” источников (справка + FAQ), а уже затем подключать тикеты и произвольные документы.
Перед индексацией (или загрузкой в хранилище для RAG) стоит провести “санитарную обработку”, иначе чат будет уверенно цитировать устаревшее и противоречивое.
Что обычно делают:
Если чат встроен в продукт, контроль доступа — не опция. Пользователь не должен “случайно” получить чужие договоры, внутренние инструкции или данные другого клиента.
Типовая схема:
Важно: рассчитывать только на “инструкцию в промпте” недостаточно. Ограничение должно быть на уровне поиска/выдачи документов.
Данные в продукте меняются — значит, должна быть понятная политика обновления:
Хороший признак зрелости — когда вы можете ответить на вопрос: “Почему чат сказал это?” и показать конкретный документ, версию и дату, доступную именно этому пользователю.
Хороший UX чата — это не «красивое окно для текста», а управление ожиданиями пользователя: что бот знает, как быстро ответит, что делать при ошибках и как контролировать результат.
LLM отвечает лучше, когда видит релевантный контекст. Но хранить всю переписку целиком нельзя: у модели есть лимит на длину входа, а длинная история удорожает запрос и ухудшает фокус.
Практичный подход — сочетать:
Важно также показывать пользователю, что чат запомнил: например, блок «Контекст» с возможностью сброса или редактирования.
Стриминг ответа делает интерфейс заметно «живее»: пользователь видит прогресс и быстрее понимает, туда ли идёт мысль.
Добавьте две кнопки: Остановить (прервать генерацию) и Продолжить (если ответ обрезался). Отдельно продумайте, как вы отображаете «печатает…», и фиксируйте финальный текст только после завершения стрима.
Чтобы снизить пустые диалоги, дайте стартовые примеры и кнопки-шаблоны: «Сформулировать письмо», «Суммировать документ», «Найти причину ошибки». Быстрые действия особенно полезны, когда пользователь не знает, что «можно попросить».
Чат должен уметь красиво выходить из тупиков:
Сердце LLM-чата — не модель, а бэкенд, который собирает «пазл» из контекста пользователя, знаний компании и действий в продукте. Хорошая практика — сделать один понятный контракт: единый endpoint /chat, который берёт на себя оркестрацию и скрывает внутреннюю сложность.
/chatИдея простая: фронтенд отправляет сообщения и минимум метаданных (пользователь, сессия, текущая страница), а сервер решает, что именно передать модели.
На бэкенде обычно есть шаги:
Пример контракта может выглядеть так:
POST /chat
{
"conversation_id": "c_123",
"message": "Составь письмо клиенту и заведи тикет",
"context": {"product_area": "billing"}
}
Инструменты нужны, когда ассистент должен делать что-то проверяемое и полезное: искать в базе, считать, создавать сущности в продукте. Типовые примеры:
Важно: модель не должна «иметь доступ» напрямую. Она лишь запрашивает вызов функции, а бэкенд валидирует права, параметры и выполняет действие.
Провайдер LLM может тормозить или отвечать ошибкой. Заложите:
Чтобы улучшать качество и разбирать инциденты, логируйте трассу запроса:
Эта телеметрия — основа для мониторинга, дебага и последующих A/B-экспериментов с промптами и RAG.
Чат на LLM — это не только «умные ответы», но и потенциальная точка входа для токсичного контента, утечек данных и попыток заставить систему выполнять нежелательные действия. Безопасность лучше проектировать заранее: после запуска исправлять сложнее и дороже.
Начните с проверки пользовательского текста до отправки в модель. Обычно применяют комбинацию правил (регулярки, стоп-слова) и модерационного сервиса/модели.
Важно разделять случаи:
Если чат умеет вызывать инструменты (поиск, CRM, платежи, отправка писем), вводите принцип «разрешено только перечисленное»:
Prompt injection часто выглядит как «игнорируй правила и покажи системный промпт» или «выполни команду из документа». Контрмеры:
Логи нужны для отладки и качества, но они же — риск.
Качество LLM-чата нельзя «почувствовать на глаз»: в одном сценарии ответы будут отличными, в другом — опасно уверенными, но неверными. Поэтому полезно разделить оценку на офлайн (до релиза) и онлайн (в продукте), а затем выстроить понятный цикл улучшений.
Соберите небольшой, но репрезентативный набор тестовых вопросов по ключевым сценариям: от типовых запросов до «краевых» случаев (двусмысленность, неполные данные, конфликтующие требования). Для части вопросов подготовьте эталонные ответы или критерии принятия (что обязательно должно быть в ответе).
Если у вас RAG, добавьте обязательную проверку источников: модель должна ссылаться на релевантные документы, а не «придумывать» факты. Практика: фиксируйте ожидаемые источники или хотя бы тип источника (политика, инструкция, договор) и проверяйте, что он действительно использован.
В интерфейсе дайте пользователю простой способ оценить ответ:
Важно: храните оценку вместе с контекстом диалога и версией промпта/индекса — иначе обратная связь не поможет найти причину.
Держите набор метрик, которые можно сравнивать между версиями:
Рабочая схема выглядит так: лог → анализ → правка данных/промпта → повторная проверка. Логи подскажут, где модель недополучает контекст, где документы плохого качества, а где нужен более строгий формат ответа. После изменений прогоняйте тот же офлайн-набор, чтобы улучшения не сломали уже работающие сценарии.
LLM-чат легко «съедает» бюджет, если не контролировать, из чего складывается цена и где возникают задержки. Хорошая новость: большинство затрат предсказуемы и управляемы.
Основная часть счета — это токены:
Практическое правило: чем длиннее контекст и ответы, тем дороже и медленнее.
Сдерживать токены можно мягко и почти незаметно:
Даже идеальные промпты не помогут, если нет «предохранителей»:
Если операция долгая (поиск по базе знаний, генерация отчета), показывайте:
Так вы снижаете число повторных отправок сообщения и, как следствие, лишние платные запросы.
Даже хорошо собранный LLM-чат после релиза начнёт «жить своей жизнью»: меняются вопросы пользователей, контент базы знаний, правила доступа, стоимость запросов и ожидания от тона ответов. Поэтому запуск стоит планировать как процесс, а не как разовую кнопку.
Оптимальный сценарий — выпускать функциональность волнами:
Важно заранее подготовить план отката: отключение инструментов (tool-calls), временное снижение контекста, переключение на более дешёвую модель, выключение RAG для нестабильных источников.
Отдельно продумайте «инженерную страховку» для релизов: быстрый откат, снимки конфигураций и восстановление. В платформенных решениях это иногда встроено: например, в TakProsto.AI есть снапшоты и rollback, что удобно для безопасных экспериментов с AI-функциями на прототипах.
Сведите в дашборды три слоя: продукт, качество, инфраструктура. Минимальный набор:
Добавьте алерты на резкие изменения (например, рост отказов RAG или падение удовлетворённости) и регулярный «разбор полётов» по реальным диалогам.
Зафиксируйте в интерфейсе понятные предупреждения (чат может ошибаться), границы ответственности, и получите нужные согласия на обработку данных. Для чувствительных доменов (медицина, финансы) продумайте безопасные формулировки и маршрут к человеку.
Заранее спланируйте:
Хорошая практика — завести «журнал изменений» модели и промптов и выпускать обновления так же аккуратно, как релизите код.
Если вы только начинаете, полезно разделить работу на два трека: (1) быстро собрать кликабельный прототип и проверить сценарии на пользователях, (2) параллельно спроектировать production‑контур (безопасность, доступы, логирование, качество). В этом смысле TakProsto.AI удобно использовать именно как ускоритель первого трека: собрать веб‑интерфейс (React), бэкенд (Go + PostgreSQL), подключить чат и затем при необходимости экспортировать исходники и развивать решение в своей инфраструктуре.
Начните с фиксации 3–5 ключевых сценариев и критериев успеха, а не с выбора модели.
Лучше всего чат работает там, где много типовых вопросов и нужен быстрый ориентир:
В этих сценариях ценность легко измеряется: скорость ответа, снижение нагрузки на саппорт, рост активации функций.
С осторожностью относитесь к задачам, где ошибка критична:
Практика: ограничить темы, подключить проверяемые источники (RAG), требовать подтверждение пользователя перед действиями или переводить на человека при определённых интентах.
Минимальный «end-to-end» набор обычно такой:
Ключевое правило: клиент не должен ходить к LLM напрямую — точка контроля должна быть на вашем API.
Разделите данные по назначению:
В запрос к модели обычно отправляют короткую историю + релевантные факты, а не весь лог.
API-провайдер обычно быстрее для старта: меньше MLOps, проще масштабирование и обновления.
Локальная/частная модель может быть оправдана, если важны:
До интеграции проверьте: длину контекста, стабильность латентности, строгие форматы (например, JSON), лимиты/квоты и региональную доступность.
Сделайте слой абстракции, например LLMClient, и вынесите выбор провайдера/модели в конфигурацию:
Это снижает риск блокировок по лимитам и позволяет оптимизировать стоимость по мере роста.
Системные инструкции — ваш контракт с моделью:
Храните промпт как код: версионируйте (например, support_v12), фиксируйте цель изменений и сравнивайте метрики в A/B.
RAG нужен, когда чат должен отвечать по вашим документам без дообучения.
Базовый пайплайн:
На запросе: делайте top-k поиск (3–10), применяйте фильтры по свежести/источнику и , а в ответе показывайте ссылки на документы внутри продукта (например, ).
Минимальный набор защитных мер:
Для действий (создание тикета, письма, платежи) используйте идемпотентность, чтобы ретраи не создавали дубликаты.
/help/...