Пошаговый план веб-приложения для комплаенса: роли, события, неизменяемые журналы, отчёты, хранение доказательств и безопасность для проверок.
Комплаенс‑приложение с audit trail — это не «ещё один лог». Его цель — сделать действия и изменения доказуемыми, управляемыми и удобными для проверки: кто и что сделал, когда, из какого контекста, по чьему запросу и с каким результатом.
Если в компании уже есть логирование, комплаенс‑система добавляет то, чего обычно не хватает «техническим» логам: единые правила фиксации, контроль доступа к журналам, целостность записей и способность быстро собрать комплект доказательств под аудит.
Самые «проверяемые» случаи обычно не про технические ошибки, а про управленческие действия:
Важно фиксировать не только факт, но и контекст: объект изменения, прежнее/новое значение (где допустимо), основание, связанный тикет или документ.
Комплаенс‑система снижает четыре ключевых риска: несанкционированные действия, отсутствие следов, подмена или «чистка» журналов, а также невозможность быстро доказать соблюдение процедур. Поэтому такие приложения строят вокруг прозрачности и неизменяемости audit trail, а не вокруг «красивых отчётов».
Первый шаг — договориться, какие требования вы закрываете и где проходит граница системы. Комплаенс редко бывает «про всё сразу»: часть требований задают внутренние политики (например, правила доступа и утверждений), часть — отраслевые нормы и договорные обязательства (если применимо).
Зафиксируйте перечень требований в виде короткой матрицы: требование → какой контроль → какие события/доказательства подтверждают выполнение. Это простая конструкция, но она сильно экономит время на согласованиях и будущих проверках.
Одинаковые слова часто означают разное для ИБ, юристов и бизнеса. В спецификации прямо определите:
Эта терминология затем напрямую ляжет в схему аудита и в шаблоны отчётов.
Комплаенс‑продукт ценят не за факт наличия логов, а за способность быстро ответить на вопрос аудитора. Поэтому заранее зафиксируйте SLA:
Сформируйте перечень того, что вы обязаны уметь показать: отчёты по доступам, историю изменений политик, выгрузки по инцидентам, неизменяемые журналы (audit trail) и подтверждения ретенции.
Такой список становится «контрактом» между продуктом и комплаенсом — и защищает от расползания требований в бесконечность.
Контроль доступа — ядро комплаенс‑приложения: он определяет, кто может видеть доказательства, кто управляет политиками, а кто лишь фиксирует события.
Ошибка в правах обычно опаснее, чем ошибка в интерфейсе: лишний доступ разрушает доверие к журналу аудита и усложняет проверку.
Минимальный набор ролей удобно закрепить в RBAC и дополнить правилами ABAC:
RBAC отвечает за «что в целом можно», ABAC — за «в каких условиях». Примеры ABAC‑атрибутов: подразделение, проект, уровень чувствительности данных, регион, статус инцидента.
Это помогает реализовать принцип наименьших привилегий и разделение обязанностей (SoD): например, тот, кто утверждает контроль, не должен быть тем же человеком, кто добавляет доказательства к нему.
Для сервисных аккаунтов задайте: ротацию ключей, срок жизни (TTL), ограничения по IP/сети и разрешённым действиям (scopes). Ключи должны выдаваться под конкретную интеграцию, а их использование — логироваться как отдельный субъект, чтобы в журнале было видно «кто сделал» даже для машинных операций.
Модель событий — это «словарь» вашего audit trail: какие действия считаются значимыми, как они называются и какие поля всегда записываются.
Чем стабильнее и понятнее схема, тем проще проводить расследования, строить отчёты и готовиться к проверкам.
Фокусируйтесь на событиях, которые меняют доступ, данные или состояние системы:
Удобно стандартизировать поля по принципу кто / что / когда / где / результат / контекст:
{
"event_id": "uuid",
"ts": "2025-12-26T10:12:45Z",
"actor": {"user_id": "u_123", "role": "admin"},
"action": "policy.update",
"target": {"type": "policy", "id": "p_77"},
"result": "success",
"where": {"ip": "203.0.113.10", "user_agent": "..."},
"context": {"trace_id": "...", "request_id": "..."}
}
Чтобы собрать историю «от клика до изменения», добавляйте trace‑id/request‑id и, при необходимости, transaction_id для группировки нескольких шагов в одну бизнес‑операцию (например, «импорт пользователей»: загрузка файла → валидация → создание записей).
Персональные данные в логах лучше минимизировать: хранить идентификаторы вместо содержимого, маскировать поля (например, последние 4 цифры), а для отладки — отдельно управляемые технические логи.
Если нужно фиксировать «что изменилось», логируйте дельту и/или хэши, а не полные значения.
Если журнал аудита можно «подчистить», он теряет ценность как доказательство. Поэтому задача не только в том, чтобы собирать события, но и в том, чтобы гарантировать: записи нельзя незаметно удалить, переписать или вставить задним числом.
Минимальный набор требований обычно включает:
Append‑only модель. На уровне БД это достигается раздельными правами (вставка разрешена, обновление/удаление — запрещены), триггерами, отдельной схемой/инстансом для аудита и процедурой записи только через сервис аудита.
WORM‑хранилище (Write Once Read Many). Для критичных кейсов (финансы, персональные данные, расследования) полезно дублировать журнал в WORM‑режим: объектное хранилище с неизменяемостью и retention‑lock. Тогда даже при компрометации приложения злоумышленнику сложно физически удалить следы.
Хеш‑цепочки. Каждая запись содержит хеш предыдущей записи (или «батча») + собственный хеш. Любое изменение в середине цепочки «сломает» проверку. Важно хранить якорные значения (например, ежедневный корневой хеш) отдельно от основной БД.
Криптоподпись записей/батчей. Подпись закрытым ключом сервиса аудита добавляет доказательность происхождения. Ключи лучше держать в HSM/KMS и регулярно ротировать.
Разделите роли: операторы приложения видят аудит через интерфейс, но не имеют доступа к «сырому» хранилищу; админы инфраструктуры управляют storage, но не могут подменять события без следов.
Дополнительно полезен принцип «двух ключей» для опасных операций (изменение политик хранения, отключение экспорта).
При ротации по времени/объёму сохраняйте непрерывность: последний хеш предыдущего сегмента становится «prev_hash» нового. Архивы подписывайте и фиксируйте контрольные суммы в отдельном реестре.
Так перенос в холодное хранилище и удаление «горячих» данных не нарушат доказуемость целостности.
Журнал аудита ценен только тогда, когда его можно быстро найти «здесь и сейчас» и при этом сохранить на годы без потери целостности. Поэтому почти всегда выгодна двухуровневая схема хранения: горячее и холодное.
Горячее хранилище держит последние недели/месяцы событий для оперативного поиска, фильтров и расследований. Его оптимизируют под чтение: быстрые индексы, удобные поля для фильтрации, прогнозируемые задержки.
Холодное хранилище рассчитано на длительные сроки и низкую стоимость. Туда уезжают «старые» партиции, которые редко поднимают, но по запросу аудитора или юристов должны быстро выгружаться.
Чтобы не превратить поиск в «сканирование всего», сразу закладывайте:
Индексы держите только на полях, которые реально используются в интерфейсе аудита, иначе стоимость хранения и время записи начнут «съедать» производительность.
Ретенция — это не просто «храним 5 лет», а набор правил: сроки по категориям событий, автоматическое архивирование, и обязательная заморозка (legal hold) для конкретных пользователей/дел/инцидентов.
Удаление по истечении срока должно быть контролируемым и воспроизводимым: фиксируйте факт удаления как событие, с причиной и ссылкой на политику.
Определите отдельные цели RPO/RTO для журналов и метаданных (схемы, ключи целостности, каталоги архивов). Проверяйте восстановление регулярно: «бэкап есть» не равно «восстановится».
Для деталей можно вынести практику в /blog/backup-rpo-rto-audit-logs.
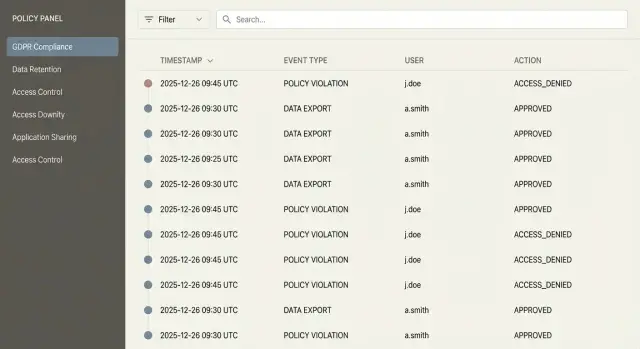
Audit trail бесполезен, если его сложно читать. Интерфейс аудита — это рабочее место для комплаенса, безопасности и внутренних расследований, поэтому он должен отвечать на вопрос «что произошло?» за минуты, а не часы.
Сделайте поиск и фильтрацию быстрыми и предсказуемыми: строка поиска с подсказками по полям (например, user:, resource:, ip:), мгновенная валидация вводимых дат, понятные названия колонок.
В карточке события показывайте ключевые поля без «криптографии»: кто, что сделал, над чем, когда, откуда, чем закончилось.
Полезная деталь — сохранённые запросы (например, «все неудачные входы за сутки», «изменения ролей пользователей», «экспорт данных»). Для команды комплаенса это превращается в набор повторяемых проверок.
Базовый набор фильтров обычно закрывает 80% задач:
Хорошая практика — показывать активные фильтры «чипами» и давать возможность быстро сбросить любой из них.
Экспорт делайте в CSV/JSON/PDF, но важно не только «выгрузить», а подтвердить подлинность:
Частые причины «пропавших событий» — разная таймзона и некорректная пагинация. Показывайте время и в UTC, и в локальной зоне пользователя, явно подписывайте формат даты/времени и учитывайте локали.
Для выдачи используйте стабильную сортировку и курсорную пагинацию (или «search after»), чтобы при обновлении списка и подгрузке страниц события не дублировались и не выпадали из выборки.
Этот модуль превращает «логирование ради логирования» в понятную систему комплаенса: что именно нужно делать, кто отвечает, как часто проверять, и где лежат доказательства выполнения.
Чем проще поддерживать порядок здесь, тем меньше хаоса перед проверкой.
Начните с единого каталога, где каждая политика/контроль — это отдельная сущность с понятными атрибутами: краткое описание, владелец (ответственный), периодичность проверки, область действия и критерии «выполнено/не выполнено».
Полезно сразу предусмотреть привязки:
Чтобы политики не превращались в «файлы без версии», задайте жизненный цикл: черновик → на согласовании → утверждена → архив.
Важные детали:
Контроль должен разложиться в конкретные действия. Для этого подойдут чек‑листы и задачи: кто выполняет, сроки, статус, комментарии, а также напоминания (например, за 7 дней до дедлайна).
Связка «контроль → задачи → доказательства» помогает не только вовремя закрывать проверки, но и быстро объяснять аудитору, как процесс работает на практике.
Доказательства лучше хранить как управляемые объекты: документы, ссылки на события, скриншоты, протоколы. У каждого доказательства должны быть метаданные: период, к какому контролю относится, кто загрузил, откуда получено, и срок хранения.
Отдельно стоит сделать удобную привязку к audit trail: например, задача «проверка выдачи прав» автоматически подтягивает релевантные события из журнала аудита за нужный период — это снижает ручной труд и риск «потерять» подтверждения.
Audit trail полезен не только «после факта». Если система умеет вовремя сигнализировать о подозрительных событиях, вы сокращаете ущерб и одновременно укрепляете соответствие требованиям: можно показать, что контроль работает в реальном времени.
Начните с системных алертов, которые чаще всего интересуют проверяющих и службу безопасности: подозрительные действия пользователя, всплески отказов в доступе, изменения ролей и прав, отключение обязательных контролей, неудачные попытки входа.
Важно, чтобы каждое уведомление содержало контекст: кто, что сделал, где (IP/устройство), в какой системе, к каким данным был доступ, и ссылку на первичное событие в журнале аудита.
Одиночное событие не всегда означает инцидент. Поэтому используйте комбинации:
Корреляции лучше настраивать через понятные правила и пороги, чтобы комплаенс‑специалист мог подтвердить логику контроля без чтения кода.
Определите, кому уходит алерт и как быстро: первая линия (дежурный/поддержка), затем владелец системы, комплаенс, ИБ. Укажите каналы (почта, мессенджер, тикет), SLA реакции и минимальный набор данных для разбора.
Полезно добавлять «рекомендуемое действие» и короткий чек‑лист.
Алерты тоже должны попадать в журнал: факт срабатывания правила, кто подтвердил/закрыл, какие комментарии и меры приняты.
Это превращает мониторинг в доказательство контролей и упрощает подготовку к проверкам. Для удобства свяжите алерт с карточкой инцидента и экспортом в /blog/audit-trail-export.
Безопасность — фундамент для комплаенса: если журналы или доказательства можно прочитать, подменить или украсть, ценность audit trail резко падает.
Поэтому меры защиты нужно закладывать сразу в архитектуру, а не «докручивать» перед проверкой.
Минимальный стандарт — шифрование в транзите (TLS для веб‑интерфейса и API) и на диске (шифрование БД, объектов в хранилище, резервных копий).
Отдельное внимание — ключам: храните их в специализированном хранилище (KMS/HSM), ограничивайте доступ по принципу «минимально необходимого», ведите аудит операций с ключами (создание, ротация, использование, отзыв).
Практика «ключ в конфиге приложения» — частая причина утечек и нарушений требований.
Секреты (API‑токены, ключи интеграций, пароли сервисных аккаунтов) не должны попадать в логи, тикеты и экспортные файлы. Введите технический запрет на логирование секретов: маскирование чувствительных полей, фильтры на уровне логирования и ревью.
Обязательны: централизованное хранение секретов (vault), ротация по расписанию и при инцидентах, раздельные секреты для сред (prod/stage), короткоживущие токены там, где возможно.
API — частая точка атаки, особенно в комплаенс‑продуктах. Нужны:
Сформируйте простую модель угроз: что является активом (журналы, доказательства, ключи), кто атакующий и какие векторы (API, права доступа, экспорт).
Затем добавьте проверки в тест‑план: тесты прав (RBAC/ABAC), отрицательные сценарии (доступ «без прав»), попытки изменить события, проверка утечек секретов в логах. Это помогает обнаружить проблемы до того, как их найдут аудиторы или злоумышленники.
Когда журнал аудита становится «системой записи», к нему предъявляются ожидания уровня финансовых систем: события не должны теряться, а продукт — «зависать» из‑за пиков нагрузки.
Важно заранее спроектировать путь события от приложения до хранилища и понять, как он ведёт себя при сбоях.
Если база/хранилище аудита недоступны, приложение не должно молча «проглатывать» события.
Практика: писать события в очередь (или локальный буфер) и фиксировать технические ошибки отдельно: причина, время, количество потерянных/задержанных сообщений, идентификаторы пачек.
Повторные попытки — с экспоненциальной задержкой и ограничением по времени, плюс «dead‑letter queue» для сообщений, которые не удаётся записать после N ретраев.
Синхронная запись в журнал на каждом клике пользователя быстро станет узким местом. Асинхронная схема (API → очередь → воркеры → хранилище) позволяет переживать всплески.
Для гарантий доставки обычно достаточно модели at‑least‑once: событие может записаться дважды, но не должно потеряться. Это означает, что потребители и хранилище должны поддерживать идемпотентность.
Заложите уникальный event_id (UUID) и, при необходимости, idempotency_key на уровне бизнес‑действия.
В хранилище — уникальный индекс по event_id, чтобы повторная доставка не создавала дублей.
Порядок событий в распределённых системах относителен. Если важна последовательность внутри объекта (например, «договор №123»), используйте партиционирование очереди по entity_id или храните монотонный sequence_number, выдаваемый одним компонентом для конкретной сущности.
Тестируйте отдельно запись, поиск и экспорт. Задайте целевые метрики: пропускная способность записи (events/sec), задержка записи (p95/p99), время поиска по типовым фильтрам, скорость экспорта (строк/сек), рост очереди (backlog) под пиковой нагрузкой и время «догоняния» после пика.
Это быстро покажет, где нужен батчинг, шардирование или оптимизация индексов.
Проверка почти всегда упирается не в то, «есть ли журнал аудита», а в то, можете ли вы быстро объяснить, как система работает, кто за что отвечает, и показать воспроизводимые доказательства.
Поэтому документацию лучше строить как набор коротких, обновляемых артефактов, а не как один большой документ.
Минимальный набор:
Соберите «аудиторский пакет», который можно отдать без долгих переписок:
Опишите, кто выдаёт доступ, как заявка фиксируется (тикет/заявка), как проходит пересмотр, и как выполняется отзыв (включая экстренный).
Добавьте чек‑лист «audit‑ready»: актуальность политик, тест восстановления выгрузок, доступность архивов, регулярность пересмотра ролей.
Если у продукта есть тарифы и ограничения по хранению/экспорту — держите ссылку на /pricing. Дополнительные материалы и разборы кейсов удобно собирать в /blog.
План лучше строить итерациями: сначала закрыть обязательные потребности (аудит и выгрузки), затем добавить гарантии целостности и автоматизацию, и только потом — «витрину» комплаенса (контроли, задачи, доказательства).
Так вы снижаете риски, быстрее получаете пользу и меньше зависите от «идеальной» архитектуры с первого дня.
Цель MVP — сделать систему пригодной для базовых проверок и внутреннего контроля.
В состав MVP обычно входят: фиксация ключевых событий (логин, изменения прав, CRUD критичных сущностей, экспорт/импорт, админ‑действия), базовый поиск и фильтры по пользователю/времени/объекту, экспорт (CSV/JSON/PDF по требованиям), RBAC для доступа к журналам, и ретенция (например, 90/180/365 дней) с понятной политикой.
Если задача стоит «быстро собрать рабочий прототип» и параллельно не потерять управляемость, можно рассмотреть TakProsto.AI: это vibe‑coding платформа, где веб‑приложения собираются из диалога, а под капотом используются типовые технологии (React для фронтенда, Go + PostgreSQL для бэкенда). Такой подход удобен, когда нужно в короткий срок поднять MVP комплаенса (поиск, экспорт, RBAC, каталог контролей), а затем итеративно расширять функциональность. Плюс важный для многих организаций момент: TakProsto.AI работает на серверах в России и использует локализованные/opensource LLM‑модели, не отправляя данные за пределы страны.
Добавьте неизменяемость: хеш‑цепочки или подпись записей, контроль разрывов, периодическую «якорную» фиксацию хеша.
Подключите алерты по комплаенс‑событиям (например, массовые удаления, изменения ролей, необычные выгрузки). Введите legal hold — заморозку данных по конкретному делу/проверке независимо от ретенции.
Сформируйте каталог контролей, связку контролей с событиями и доказательствами, задачи на сбор подтверждений, и отчётность по готовности (что закрыто, что просрочено, где пробелы).
Проверяйте:
Комплаенс-приложение с audit trail делает действия доказуемыми: фиксирует кто/что/когда/где/результат/контекст и помогает быстро собрать артефакты для проверки.
Обычные логи чаще разрознены, не имеют единых правил, не гарантируют целостность и не дают удобного поиска/экспорта под аудит.
Начните с матрицы: требование → контроль → события/доказательства.
Практично выделить категории:
Граница системы должна быть явной: что фиксируете внутри приложения, а что — на уровне инфраструктуры/других систем.
Зафиксируйте термины прямо в спецификации:
Минимально полезный каркас:
Логируйте не «всё подряд», а то, что меняет доступ, данные или состояние:
Для расследований важен контекст: объект, основание (тикет), канал (UI/API), результат.
Комбинируйте RBAC и ABAC:
Отдельно заложите разделение обязанностей (SoD): например, тот, кто утверждает контроль, не должен быть тем же, кто подгружает доказательства.
Нужны меры, чтобы записи нельзя было незаметно переписать или удалить:
Обычно работает двухуровневая схема:
Обязательные элементы:
Чтобы выгрузка была доказательством, а не просто файлом:
Форматы обычно: CSV/JSON для машинной обработки и PDF для прикладывания к пакету проверки.
Практичная схема: API → очередь → воркеры → хранилище.
Ключевые решения:
event_id + уникальный индекс в хранилище;Это снижает споры на проверке и помогает стабилизировать схему событий и отчёты.
event_id, ts (в UTC);actor (user_id/service_id, роль/атрибуты);action (стабильный event type);target (тип и id объекта);result (success/error + код/тип ошибки);where (ip, user_agent, источник UI/API);context (request_id/trace_id, ticket_id/документ-основание).Если нужно показать «что изменилось», логируйте дельту или хэши, а не полные значения.
Верификацию целостности сделайте воспроизводимой: понятная процедура и пример проверки.
Бэкапы проверяйте восстановлением и задайте отдельные RPO/RTO для журналов и метаданных.
Нагрузочные тесты меряйте отдельно на запись, поиск и экспорт (p95/p99, backlog очереди, скорость выгрузки).