Пошаговый план веб‑приложения для контроля покрытия автоматизацией: модель данных, метрики, интеграции, дашборды, роли, качество данных и запуск в эксплуатацию.
Мониторинг покрытия автоматизацией нужен не «ради отчёта», а чтобы управлять портфелем улучшений на основе фактов. Когда у компании десятки команд и сотни процессов, быстро теряется понимание: что уже автоматизировано, где есть дубли, какие участки дают эффект, а какие годами остаются ручными. Единая витрина покрытия превращает разрозненные сведения в понятную картину.
Во‑первых, это прозрачность: любой заинтересованный сотрудник видит, какие процессы автоматизированы, кем и в каком статусе.
Во‑вторых, приоритизация: можно сравнивать участки между собой и выбирать следующие кандидаты на автоматизацию — не по ощущению, а по критериям (масштаб процесса, критичность, доля ручных операций).
В‑третьих, контроль эффекта: даже если приложение не считает экономию в деньгах, оно позволяет отслеживать динамику — рост доли автоматизированных шагов, снижение числа ручных операций, стабильность выполнения.
Чтобы метрика была честной, заранее фиксируют, какие решения попадают в учёт. Обычно это:
Важно зафиксировать, чем приложение не занимается: расчётом финансовой выгоды и ROI, разработкой и сопровождением роботов/скриптов, управлением релизами и тестированием, а также выбором инструментов автоматизации.
Его задача — аккуратно хранить и показывать факты об автоматизации и покрытии, чтобы решения принимались быстрее и точнее.
Ключевой вопрос для веб‑приложения мониторинга звучит просто: «какая доля работы/операций покрыта автоматизацией?» Но «доля» бывает разной — и если выбрать не те метрики, дашборд KPI начнёт поощрять неправильные решения (например, автоматизировать редкие операции ради «процента»).
1) Доля автоматизированных операций
Это базовая метрика покрытия автоматизацией: сколько выполнения процесса проходит через автоматизацию (RPA/скрипт/интеграцию), а сколько — вручную. Важно заранее договориться, что считать «операцией»: заявку, платёж, строку реестра, кейс в поддержке.
2) Оценочная экономия времени
Показывает эффект понятным языком: часы/дни, которые высвобождаются. В каталоге процессов стоит хранить допущения (например, «ручное время 6 минут, автоматизация 1 минута») и дату пересмотра оценки — иначе витрина данных быстро устареет.
3) SLA и ошибки
Покрытие — не самоцель. Если после автоматизации SLA улучшился, а ошибки снизились, это подтверждает качество. Если наоборот — сигнал, что автоматизация «есть», но пользы нет.
Для учёта автоматизированных процессов полезно различать:
Эти метрики стоит трактовать в связке: высокая доля покрытия при низкой успешности означает «формально автоматизировано», но операционно нестабильно.
Чтобы дашборд не превращался в перечень «скриптов без хозяина», добавьте признаки зрелости:
Практика: выводить покрытие рядом с индексом зрелости. Тогда пользователи видят не только «сколько процентов», но и насколько устойчиво это покрытие.
Если вы ведёте задачи автоматизации в трекере (например, интеграция с Jira), полезно связывать метрики с источником работ: так проще объяснять, почему покрытие выросло или просело между релизами.
Основа приложения для контроля покрытия — единая «карта» того, что делается в бизнесе и как это автоматизировано. Если модель данных спроектирована аккуратно, дальше проще и расчёты, и дашборды, и аудит.
Сразу договоритесь о минимальном наборе сущностей и уровне детализации. На практике удобно фиксировать иерархию:
Важно: покрытие часто считают не на уровне «процесса целиком», а на уровне задач/шагов — иначе теряется частичная автоматизация.
Справочники позволяют избежать «зоопарка» названий и поддерживать фильтры на дашбордах:
Держите справочники управляемыми: один ответственный, понятные правила добавления и, по возможности, синхронизация с HR/ИТ‑справочниками.
Ключевые связи лучше сделать явными, а не «зашивать» в текстовые поля:
Так вы сможете отвечать на вопросы вроде: «какие критичные процессы зависят от одной команды?» или «где нет владельца и риск выше?».
Без истории приложение быстро превращается в «снимок на вчера». Добавьте версионирование:
История изменений нужна не только для аудита, но и для честной динамики покрытия по месяцам.
Система контроля покрытия автоматизацией живёт только тогда, когда данные попадают в неё регулярно и без ручных «добавьте, пожалуйста». Поэтому на старте важно описать источники, договориться о владельцах и выбрать минимально достаточные интеграции.
Обычно нужны четыре класса данных:
Если в компании уже есть BI/хранилище, полезно сразу планировать выгрузку в «витрину данных», чтобы дашборды строились на согласованной модели и не дублировали расчёты.
Выбор зависит от зрелости систем и требований безопасности:
Чтобы метрики не «плавали», заложите правила сразу:
Оптимальный компромисс по свежести и нагрузке:
Такой подход снижает ручной труд и делает дашборды достоверными: пользователи видят не «отчёт раз в квартал», а актуальное состояние автоматизации.
Чтобы метрика покрытия не превращалась в «процент ради процента», заранее договоритесь, что именно вы считаете покрытым и как сравниваете процессы между собой. На практике удобно поддерживать несколько формул — под разные управленческие вопросы.
Покрытие процесса = (автоматизированные шаги / все шаги) × 100%
Покрытие процесса = (время, выполняемое автоматизацией / общее время выполнения) × 100%
Покрытие процесса = (транзакции, обработанные автоматически / все транзакции) × 100%
Важно: фиксируйте период расчёта (например, последние 30 дней) и источник данных (лог робота, отчётность, оценки владельца) — иначе «прыжки» процента будет трудно объяснить.
Два процесса с одинаковым покрытием могут иметь разную ценность. Поэтому вводят веса и считают взвешенное покрытие портфеля.
Пример факторов:
На уровне приложения это выглядит так: каждому процессу задаётся итоговый вес (например, 1–5), а портфельный KPI считается как средневзвешенное по выбранной формуле.
Редко автоматизируется 100%: бывают ручные проверки, нестандартные кейсы, зависимость от внешних ответов. Чтобы не завышать покрытие:
Покрытие невозможно посчитать без связи «процесс → автоматизация». Практичный подход:
Так вы снижаете ручной труд, но сохраняете качество данных — и процент покрытия становится управляемым показателем, а не предметом спора на совещании.
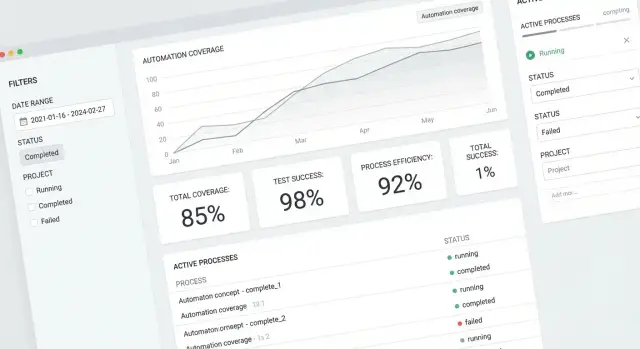
Интерфейс в приложении про покрытие автоматизацией должен отвечать на два вопроса: «где мы сейчас» и «что делать дальше». Пользователям важны не только аккуратные графики, но и быстрый переход от общего KPI к конкретному процессу или автоматизации, которая «тянет вниз» показатель.
На главной панели покажите общий процент покрытия (с оговоркой о методике расчёта) и динамику за период: неделя/месяц/квартал. Рядом — «топ‑пробелы»: процессы с высокой критичностью и низким покрытием, а также зоны, где покрытие падает из‑за выключенных/нестабильных автоматизаций.
Полезный приём — сопровождать KPI поясняющими индикаторами: сколько процессов без владельца, сколько автоматизаций в статусе «на поддержке», сколько запусков завершилось ошибкой. Это помогает не спорить о цифрах, а видеть причины.
Сделайте быстрые срезы:
Важно, чтобы фильтры работали одинаково на всех виджетах: пользователь выбирает «Подразделение = Финансы» — и весь экран пересчитывается.
Карточка процесса должна быть «точкой правды»: краткая схема/описание, текущий статус, владелец, связанные автоматизации и их вклад в покрытие. Добавьте историю изменений и понятный блок «что мешает» (например: нет данных о частоте, не подтверждён владелец, автоматизация отключена).
Здесь нужны статус, среда (prod/test), частота запусков, последние ошибки и ссылки на артефакты: тикет в Jira, репозиторий, документация, мониторинг. Пользователь должен за 30 секунд понять: автоматизация реально работает или только «числится».
Если вы планируете расширение, заранее предусмотрите страницу /dashboard с сохранёнными представлениями (например, «Мой портфель процессов») — это снижает ручную работу и ускоряет еженедельные обзоры.
Когда приложение показывает «покрытие автоматизацией» и влияет на приоритизацию работ, доверие к данным становится таким же важным, как сами формулы расчёта. Это доверие обеспечивают чёткие роли, минимально необходимые права и прозрачный аудит.
Удобно начать с четырёх ролей, которые закрывают типовые сценарии:
Даже при небольшом составе пользователей стоит разделять действия по уровням:
Логирование должно быть не «для галочки», а пригодным для разбора инцидентов и спорных ситуаций. Минимальный набор полей: кто изменил, когда, что именно (старое/новое значение), контекст (процесс/автоматизация), основание (комментарий, ссылка на задачу в Jira).
Отдельно фиксируйте изменения связей «процесс ↔ автоматизация» и пересчётов метрик: пользователи должны видеть, почему цифра изменилась.
Подключайте SSO (SAML/OIDC) и стройте доступ по принципу минимально необходимого. Практичный подход — сегментация по оргструктуре: пользователь видит «своё» подразделение и агрегированные итоги выше по иерархии, но не детальные данные соседних команд. Это снижает риск утечек и упрощает согласование доступа с безопасностью.
Хороший учёт покрытия держится не на «табличке», а на понятном жизненном цикле записей: кто и когда обязан обновить данные, что считается актуальным, и какие сигналы система отправляет при отклонениях. Workflow должен быть простым, но дисциплинирующим.
Для карточки процесса достаточно четырёх состояний:
Важно: перевод в «Актуален» должен быть возможен только через явное подтверждение (кнопка, электронная подпись или согласование в задаче), а не через простое редактирование.
Для привязанной автоматизации (бот, скрипт, интеграция) удобно вести отдельный статус:
Ключевые сценарии:
Добавление процесса → черновик «В работе» → назначение владельца.
Привязка автоматизации → указание типа, охвата, ссылок на артефакты (репозиторий/задача) → расчёт влияния на покрытие.
Подтверждение владельцем → перевод в «Актуален», фиксация даты и автора.
Оповещения должны попадать тем, кто может действовать:
Правило простое: уведомление всегда содержит причину, ссылку на карточку и следующий шаг (что нужно обновить и до какого срока).
Хорошая архитектура здесь — про предсказуемость: данные собираются регулярно, считаются одинаково, а пользователи видят актуальную картину без «ручных магических правок». Удобно мыслить системой как четырьмя слоями: интерфейс, API, хранилища и фоновые задачи.
Для интерфейса чаще всего достаточно SPA (React/Vue/Angular): быстро, удобно для дашбордов и фильтров. Если важны скорость первого открытия и индексация внутренним поиском, можно выбрать SSR (например, Next.js/Nuxt).
Серверная часть — REST или GraphQL API (стек может быть разным), плюс отдельный воркер для фоновых работ. Очередь задач (RabbitMQ/Kafka/SQS и аналоги) нужна для интеграций, перерасчётов и «тяжёлых» отчётов без тормозов в интерфейсе.
Если важна скорость запуска и вы хотите быстро собрать MVP без долгого цикла «ТЗ → разработка → согласования», можно использовать TakProsto.AI: это vibe‑coding платформа для российского рынка, которая позволяет в диалоге собрать веб‑интерфейс, API и базовую модель данных, а затем выгрузить исходники. Типовой стек (React на фронте, Go + PostgreSQL на бэкенде) хорошо совпадает с задачей реестра, витрин и расчётов покрытия, а размещение на серверах в России упрощает вопросы локализации и контуров данных.
API лучше проектировать вокруг основных сущностей и операций:
Важно сразу заложить версионирование (/api/v1/…) и единый подход к фильтрам, сортировкам и пагинации.
Для реестра процессов и автоматизаций подходит реляционная БД (PostgreSQL/MySQL): связи, ограничения, история изменений. Если нужно хранить «сырые» события (логи запусков роботов, результаты джоб, статусы интеграций), их удобно вынести отдельно: time‑series/логовое хранилище или объектное хранилище + индексация.
Чтобы система не «падала» из‑за одного источника данных, используйте кэш для справочников и тяжёлых дашбордов, лимиты запросов на API, ретраи интеграций с экспоненциальной задержкой и дедупликацию задач в очереди. Резервное копирование БД и регулярные тесты восстановления — обязательны: реестр без истории и целостности быстро теряет доверие.
Система, которая считает покрытие автоматизацией, быстро становится «точкой правды» для руководителей и аудиторов. Поэтому безопасность и наблюдаемость лучше заложить сразу: исправлять архитектурные решения после пилота обычно больнее, чем добавить фичу.
Главное правило — хранить минимум. Для расчёта покрытия чаще всего достаточно идентификаторов процессов, статусов, ссылок на артефакты (например, тикеты в Jira) и агрегированных метрик.
Персональные данные и чувствительные поля (ФИО, телефоны, e‑mail, номера документов, реквизиты) не сохраняйте вообще. Если без них не обойтись — применяйте маскирование/псевдонимизацию и храните отдельно с более жёсткими доступами.
Секреты интеграций (API‑ключи, токены доступа, клиентские секреты) нельзя класть в базу «как есть» или в конфиги репозитория. Используйте секрет‑хранилище и короткоживущие токены, ротацию и принцип наименьших привилегий.
Наблюдаемость должна отвечать на два вопроса: «сервис жив?» и «данные не испортились?». Минимальный набор:
При логировании не пишите PII и секреты; используйте редактирование (redaction) и уровни логов.
Включите сильную авторизацию (SSO/OAuth2), проверку ролей на уровне эндпоинтов и объектов (кто может видеть конкретный процесс/подразделение). Добавьте rate limit и защиту от подмены данных: подпись вебхуков, проверку источника, идемпотентность обновлений и контроль версий записей.
Определите сроки хранения: сырые события интеграций — коротко, агрегаты и аудит — дольше. Доступ к данным — по заявкам с фиксацией основания, а все изменения в каталоге процессов и автоматизаций — протоколируйте (кто/что/когда/почему), чтобы можно было восстановить картину при разборе инцидентов.
Чтобы приложение действительно прижилось, внедряйте его поэтапно: сначала — полезный минимум, затем — проверка на реальных командах, и только после этого — автоматизация «вглубь».
На старте цель не в идеальной точности, а в прозрачности.
MVP обычно включает:
Важно сразу договориться о правилах: что считается «процессом», как фиксируется «автоматизирован/частично/не автоматизирован», кто обновляет записи.
Практический вариант для ускорения старта: собрать прототип реестра и дашбордов в TakProsto.AI, быстро согласовать структуру карточек и фильтров с бизнесом, а затем либо развивать решение дальше в платформе (с развёртыванием и хостингом), либо выгрузить исходники и продолжить в корпоративном контуре.
Выберите команды с разным профилем (например, операционный блок и поддержка), чтобы проверить универсальность модели.
Критерии успеха пилота:
В конце пилота соберите обратную связь: какие поля лишние, каких отчётов не хватает, где возникают споры по трактовкам.
После пилота подключайте интеграции и автоматический расчёт покрытия (например, подтягивание статусов задач из Jira), расширяйте роли и права доступа.
Параллельно настройте управление изменениями:
Так вы получите не «витрину ради витрины», а рабочий инструмент контроля покрытия автоматизацией.
Даже хорошо спроектированная витрина данных быстро «поплывёт», если не договориться о правилах и не встроить контроль качества в повседневную работу. Ниже — ошибки, которые встречаются почти всегда, и практики, которые помогают удерживать данные живыми.
Самая частая — неполный реестр процессов: часть операций живёт в почте и чатах, часть — в локальных таблицах, а часть — у подрядчиков.
Вторая — разные определения «покрытия»: для одних это наличие бота, для других — доля шагов, выполняемых без участия человека.
Третья — конфликт владельцев и ответственности: «владелец процесса» и «владелец автоматизации» не совпадают, и никто не считает себя обязанным обновлять карточку процесса, статусы и фактические объёмы.
Начните с единого глоссария и закрепите его в продукте: что такое процесс, подпроцесс, автоматизация, частичное покрытие, исключения. Хорошая практика — хранить правила расчёта прямо рядом с метрикой (подсказка в интерфейсе и ссылка на /docs/coverage-rules).
Далее — процесс утверждения изменений: кто может менять формулу, веса, границы процесса, владельца. Важно, чтобы такие изменения проходили через простой workflow (черновик → на согласовании → утверждено) и оставляли след в аудите.
Работают три механики: выборочные проверки (например, 10 процессов в неделю), отчёты по аномалиям (резкий рост/падение покрытия, нулевые объёмы, «вечные черновики») и метрики свежести (когда последний раз подтверждали данные владельцы).
Отслеживайте долю подтверждённых процессов, медианный «возраст» данных, количество процессов без владельца и размер «серых зон» — процессов, по которым нет ни объёмов, ни статуса автоматизации. Если эти показатели улучшаются, приложение становится не просто витриной, а управленческим инструментом.
Лучший способ понять возможности ТакПросто — попробовать самому.