Пошаговый план, как спроектировать и собрать веб-приложение для учёта внутренних SLA: модели данных, статусы, таймеры, эскалации, отчёты и безопасность.
Внутренний SLA — это договорённость между командами о сроках реакции и выполнения запросов: от «починить доступ к VPN» до «подготовить выгрузку для бухгалтерии». Пока такие обещания живут в чатах и почте, ими сложно управлять: сроки теряются, приоритеты становятся предметом споров, а причины просрочек превращаются во взаимные претензии.
Трекер SLA полезен всем внутренним сервисным командам: службе поддержки, ИТ, HR-операциям, безопасности, бэк-офису и любым «внутренним поставщикам» услуг. Когда запросов много, а исполнителей несколько, ручной контроль быстро превращается в постоянное тушение пожаров.
Обычно достаточно трёх типов обещаний:
Важно помнить: SLA — это не «магия ускорения», а прозрачные правила. Нужно заранее определить, когда таймер идёт, когда ставится на паузу (ожидание информации от заявителя, смежной команды, подрядчика) и кто вправе менять приоритет.
Внутренние договорённости обычно гибче: приоритет может зависеть от влияния на бизнес-процесс, а правила — меняться по согласованию руководителей. Здесь важна не юридическая формулировка, а управляемость и справедливость по отношению к очереди.
Хороший трекер SLA даёт три результата: прозрачные сроки по каждой заявке, меньше просрочек за счёт ранних сигналов, понятные причины срывов (где пауза была оправдана, а где сроки «съели» переключения и очереди). Это снижает конфликтность и помогает командам договариваться на фактах, а не на ощущениях.
Прежде чем рисовать интерфейсы и продумывать расчёты, важно договориться о смысле SLA именно в вашем контуре: что считается обязательством, где начинается отсчёт и в какой момент вы считаете обещание выполненным или нарушенным. Хороший трекер SLA не «угадывает» правила — он фиксирует их в явном виде.
Начните с перечня сущностей, между которыми возникают обязательства. Обычно это:
Сразу решите, что является «клиентом» в отчётах: конкретный отдел, филиал, продуктовая команда или, например, юридическое лицо внутри группы.
Согласуйте минимальный набор атрибутов заявки, влияющих на SLA: приоритет, категория/тип, статус, ответственный/команда, метки, а также вычисляемые поля: SLA-дедлайн, оставшееся время, факт нарушения.
Отдельно уточните правила изменения приоритета: пересчитывается ли дедлайн «задним числом» или только с момента изменения.
Сформулируйте события, которые должны менять ход SLA-таймеров: создание, первичное назначение, переход в “ожидание”, возврат в работу, закрытие/решение. Для каждого события зафиксируйте: какой таймер стартует/останавливается и какая дата считается контрольной.
Сразу договоритесь, как выбирается политика: по услуге, приоритету, подразделению клиента (иногда — по сочетанию). И обязательно внесите требования к аудиту: кто и когда менял статус/приоритет/исполнителя, какие были значения до/после, и по какой причине (хотя бы опциональный комментарий). Без этого спорные случаи и «ручные исправления» будут разрушать доверие к отчётам.
Дальше стоит договориться, какие таймеры вы измеряете и по каким правилам они «тикают». Внутренний SLA редко сводится к одной цифре: обычно нужно разложить путь заявки на несколько измеримых этапов.
Чаще всего достаточно трёх показателей:
Заранее определите, что считается нарушением: просрочка первой реакции, просрочка решения или оба условия (и как считать, если одно выполнено, а второе — нет).
SLA почти всегда считается в рабочем времени, иначе ночные часы и выходные будут давать ложные просрочки.
Заложите модель:
Определите статусы, которые ставят таймер на паузу: «ожидание клиента/согласования», «на удержании», «заблокировано». Для паузы нужны правила: кто может поставить, что является выходом из паузы, и нужно ли оставлять комментарий.
Два популярных подхода:
Выберите один подход для каждого таймера и зафиксируйте, какие события считаются «значимыми», чтобы дедлайны не «прыгали» неожиданно.
Правильная схема данных — основа трекера внутреннего SLA: от неё зависит, можно ли быстро понять, где «сгорело» время и какие обязательства команда реально выполняет. Ниже — минимальный набор сущностей и правил, которые стоит заложить сразу.
Ticket (Заявка) — центр модели: идентификатор, услуга/категория, приоритет, текущий статус, команда и ответственный, даты создания/закрытия.
SLA Policy (Политика SLA) — правила для конкретной услуги и приоритета: целевое время первого ответа, время до решения, условия эскалации.
SLA Timer/Clock (Таймеры) — конкретные обязательства, привязанные к заявке: «Response», «Resolve» и др. У каждого таймера — старт, паузы, дедлайн, факт выполнения и признак просрочки.
Дополняющие сущности: Team, User, Calendar (рабочие часы/праздники), Comment, Attachment.
Политику удобно связывать с заявкой через комбинацию «услуга + приоритет» (или «услуга + уровень поддержки»). При создании заявки фиксируйте снимок применённой политики, чтобы изменения правил не переписывали прошлые расчёты.
Для таймеров важна история изменений: переходы статусов, смена приоритета, переназначение, ручные паузы. Это события, которые должны объяснять, почему дедлайн сдвинулся.
Храните все timestamps в UTC, а отображение переводите в локальную зону пользователя/команды.
Отдельно держите поля «план/факт»: deadline_at (план), fulfilled_at (факт). Производные значения (например, «оставшееся время» или «сколько минут в паузе») лучше вычислять на чтении или кэшировать по необходимости, чтобы не плодить несогласованные данные.
Типовые выборки в SLA-трекере: по статусу, дедлайну, ответственному, списки просроченных. Значит, понадобятся индексы по status, assignee_id, deadline_at, а также составные (например, team_id + status + deadline_at) для очередей команд.
Критичные события (создание/закрытие, смена политики, старт/пауза/возобновление таймера, эскалация) пишите в неизменяемый журнал (append-only). Это упрощает разбор инцидентов и делает отчётность по SLA доверенной: данные можно объяснить и подтвердить.
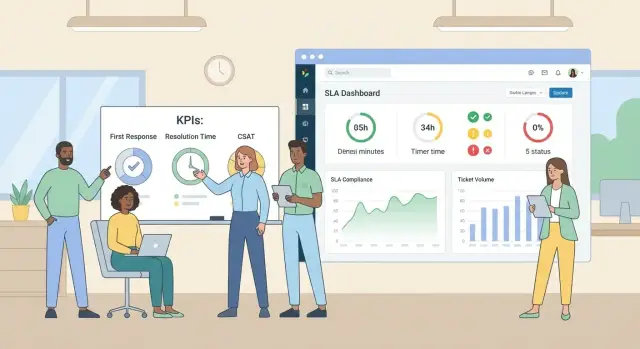
Хороший трекер внутреннего SLA выигрывает не количеством экранов, а тем, насколько быстро пользователь понимает: что горит, почему и что сделать прямо сейчас. Поэтому первые версии интерфейса стоит строить вокруг трёх сценариев: найти проблемные заявки, принять решение в конкретной заявке, увидеть картину по команде.
Список должен отвечать на вопрос «что делать следующим». Минимальный набор колонок: очередь/услуга, приоритет, текущий статус, владелец, ближайший SLA‑дедлайн, остаток времени и признак просрочки.
Ключевые фильтры:
Добавьте быстрые действия прямо из списка: назначить на себя, сменить статус, поставить на паузу (если политика позволяет), эскалировать. Чем меньше переходов — тем меньше ручных ошибок.
В карточке главное — видимый «компас SLA»:
Полезный приём: рядом с дедлайном показывать подсказку «почему так посчитано» (рабочие часы, исключённые паузы). Это снижает споры и обращения к администраторам.
Дашборд нужен, чтобы видеть тенденции, а не отдельные случаи:
Настройки SLA лучше делать «конструктором»: политика → условия (очередь/тип/приоритет) → целевые времена → рабочие часы → правила пауз/исключений. Минимизируйте свободный ввод: больше выпадающих списков и валидации, меньше текстовых полей.
Понятные статусы, единые цвета для «норма/риск/просрочка», автозаполнение по умолчаниям и быстрые кнопки «назначить/эскалировать/поставить на паузу» дают больше эффекта для первой версии, чем «красивые графики».
Чтобы SLA‑трекер действительно помогал, в нём должны быть чётко определены роли, права и жизненный цикл заявки. Иначе система превращается в чат с таймерами: ответственность размыта, а изменение дедлайнов выглядит как «подгонка» показателей.
Минимальный набор ролей обычно покрывает 90% сценариев:
Хорошая практика — разделить «операционные» действия и «управленческие»:
Базовый набор статусов, который удобно связать с таймерами:
Эскалации должны быть предсказуемыми и одинаковыми для всех:
Для стабильной нагрузки нужны шаблоны маршрутизации: очереди по категориям (например, «Доступы», «Инциденты», «Закупки») и автоназначение по правилам (команда, дежурный, навыки, часовой пояс). Это уменьшает ручную сортировку и ускоряет старт работы — а значит, помогает выполнять внутренний SLA без героизма.
Хорошая архитектура SLA‑сервиса начинается с простого принципа: все расчёты времени и дедлайнов делает сервер, а клиентские интерфейсы получают уже готовые значения (дедлайн, «осталось времени», признак просрочки). Так вы снижаете риск расхождений из‑за часовых поясов, разного времени на устройствах и «творчества» фронтенда.
Если вы хотите быстро проверить гипотезу и собрать рабочий прототип, часть команд делает это на vibe‑coding платформах. Например, в TakProsto.AI можно в формате чата описать сущности (тикеты, политики, календари), роли и ключевые сценарии — и получить каркас веб‑приложения с React‑интерфейсом и серверной частью на Go с PostgreSQL. При необходимости исходники можно экспортировать и развивать продукт внутри компании.
Держите модель «бизнес‑сущности + вычисления рядом», чтобы правила не расползались:
Практично также иметь единый endpoint событий (например, /events) или журнал изменений (аудит) как отдельный ресурс — так проще разбирать спорные случаи.
API должно запрещать некорректные переходы статусов (например, нельзя «закрыть» заявку, минуя обязательную стадию), а также защищать от «прыжков времени»: все отметки времени — только серверные. Операции с таймерами делайте идемпотентными (повторный запрос не ломает состояние).
В /tickets и /timers заложите фильтры, которые реально используются в работе:
Добавьте стабильную пагинацию (limit/offset или cursor) и сортировки по дедлайну/приоритету.
Чтобы сроки не терялись, проектируйте события как продуктовую часть: вебхуки/очередь событий на изменения статуса, назначение исполнителя, наступление порогов эскалации. Эти события питают уведомления и синхронизацию с другими системами — без жёсткой связки «интерфейс ↔ уведомления».
Сердце трекера внутреннего SLA — корректные таймеры: когда стартуем отсчёт, когда ставим на паузу, когда останавливаем и как получаем дедлайн с учётом рабочих часов. В интерфейсе пользователь видит простую дату/время, но за ней обычно стоит несколько фоновых процессов.
Минимальный набор задач, который почти всегда нужен:
Разделяйте «источник истины» и «витрины»: точные расчёты фиксируйте в событиях/записях, а агрегаты обновляйте асинхронно.
Есть две базовые стратегии:
Периодический джоб (каждую минуту/5 минут) — проще в реализации и наблюдаемости: джоб находит заявки в зоне риска, проверяет дедлайны, создаёт задачи на уведомления. Минус — лишняя работа и задержка до следующего тика.
Событийная (event-driven) — пересчитывать и планировать действия сразу при изменениях (создали заявку, сменили статус, изменили календарь). Плюс — меньше лишних проверок, минус — выше требования к дисциплине событий.
Практичный компромисс для MVP: событийная обработка для «срочных» пересчётов + периодический джоб как страховка, который вылавливает пропуски и сверяет «что должно быть запланировано».
Дубли обычно возникают при ретраях, параллельных воркерах или повторной доставке события. Решение — идемпотентность:
(ticket_id, sla_timer_id, type, threshold);Самый тяжёлый сценарий — изменение календаря рабочих часов или политики SLA, когда нужно обновить дедлайны у тысяч заявок.
Подход: ставьте пересчёт в очередь батчами, фиксируйте прогресс, ограничивайте конкуренцию, а в интерфейсе показывайте статус операции («пересчёт в процессе»). Для критичных отчётов полезно хранить версию политики, по которой рассчитан дедлайн, чтобы понимать, что именно нужно обновлять.
Чтобы быстро диагностировать ошибки, логируйте ключевые переходы: старт/пауза/стоп, итоговые дедлайны, причину перерасчёта и идентификатор события. Добавьте корреляционный ID на заявку и фоновые задачи — тогда по одной заявке можно восстановить цепочку: какое событие сработало, какой воркер обработал и почему было принято решение не останавливать таймер.
Уведомления — «нервная система» внутреннего SLA: таймеры могут быть настроены идеально, но без своевременных сигналов команда всё равно узнает о просрочке постфактум. Правильная схема уведомлений не спамит, а подсказывает следующий шаг и делает нарушение SLA редким исключением.
Обычно хватает нескольких каналов, чтобы покрыть разные сценарии:
Один и тот же сигнал не обязан идти во все каналы. Лучше задать «канал по умолчанию» и резервный канал для эскалаций.
Базовый набор событий обычно включает: назначение ответственного, смену приоритета, приближение дедлайна (например, за 30/10 минут), нарушение SLA, запуск эскалации (переход на следующую линию/менеджеру).
Для приближения дедлайна задавайте несколько порогов: ранний (чтобы успеть перестроить очередь) и критический (чтобы принять решение — переназначить, привлечь помощь, согласовать исключение).
Сообщение должно быть коротким: что случилось, что делать и куда перейти. Обязательны ссылка на карточку заявки (например, /tickets/123) и текущие сроки: «до дедлайна 12 мин», «просрочено на 7 мин», а также приоритет и ответственный.
Подписки лучше делать гибкими: по команде, по категории, а также индивидуальные настройки (например, «получать только критические»).
Храните историю уведомлений: кому отправили, когда, по какому событию, через какой канал, с каким статусом доставки/ошибкой и с каким текстом (или ссылкой на шаблон и параметры). Это помогает разбирать спорные случаи, доказывать факт оповещения и улучшать правила эскалации без догадок.
Руководителям важны не отдельные таймеры по заявкам, а управляемая картина: где SLA выполняется, где регулярно «горит», и что именно нужно менять — правила, нагрузку или процессы.
Соблюдение SLA по командам и услугам: доля заявок в SLA, доля просрочек, среднее/медиана времени до реакции и до решения. Такой отчёт помогает сравнивать команды и понимать, где проблема системная.
Динамика по неделям/месяцам: тренды по выполнению SLA и объёму поступления заявок. Руководитель видит, ухудшение — это всплеск нагрузки, сезонность или накопившийся backlog.
Причины просрочек: топ-3–5 причин (например, ожидание заказчика, нехватка исполнителей, неверный приоритет, частые переоткрытия). Важно, чтобы причины были не «текстом в комментарии», а выбранными из справочника.
Добавьте срезы по приоритету, категории, подразделению-заказчику, исполнителю и очереди. Один и тот же показатель «90% в SLA» может скрывать провал по критическим заявкам или в конкретной очереди.
Поддержите CSV/XLSX и настройку расписания отправки отчётов руководителям (например, каждое утро по понедельникам). Полезно давать ссылку на тот же отчёт в интерфейсе с применёнными фильтрами (без домена, например: /reports/sla?team=it).
Отчётность разваливается, если данные «грязные». Введите обязательные поля (приоритет, услуга, заказчик), проверки на некорректные статусы и мониторинг «зависших» заявок (нет движения N часов, нет последнего комментария, не назначен ответственный).
Параллельно со SLA показывайте: время до назначения, долю заявок без ответственного, backlog по очередям и его изменение. Эти метрики объясняют, почему SLA начал проседать, ещё до массовых просрочек.
Внутренний трекер SLA почти всегда работает с чувствительными данными: персональные данные сотрудников, детали инцидентов, переписка, вложения. Поэтому безопасность нужно закладывать в дизайн продукта сразу, а не «прикручивать» после запуска.
Если в компании есть единый контур входа, лучше опираться на SSO/LDAP: меньше паролей, проще отключать доступ при увольнении, ниже риск «общих» учёток.
Если SSO пока нет, используйте стандартную аутентификацию с понятной политикой паролей: минимальная длина, запрет популярных паролей, ограничение попыток входа, опционально — 2FA для админов. В любом варианте ведите журнал сессий и поддерживайте принудительный выход при смене пароля.
Базовый подход — RBAC (роли и права) плюс сегментация данных:
Проверяйте права не только в интерфейсе, но и на уровне API и запросов к данным (например, через фильтры по подразделению и владельцу очереди).
Для полей с персональными данными добавьте маскирование (показывать частично или по повышенным правам), а для вложений — ограничения типов/размера и антивирусную проверку. Заранее определите сроки хранения: сколько держать заявки, комментарии и файлы, как выполнять удаление/архивацию и кто может запускать эти операции.
Аудит должен отвечать на вопросы «кто видел» и «кто менял»:
Для API заложите rate limit, защиту от CSRF/XSS, строгую валидацию входных данных и контроль загрузок файлов (лимиты, типы, сканирование). Это снижает риск утечек и повышает соответствие внутренним требованиям комплаенса.
Внутренний трекер SLA лучше внедрять поэтапно: сначала доказать ценность на ограниченном периметре, затем масштабировать и унифицировать правила. Это снижает риск «залипнуть» в бесконечной доработке и помогает быстрее получить доверие команды.
Минимальная версия должна закрывать ежедневную боль, а не все возможные сценарии.
В MVP обычно входят:
Обязательно заложите журнал изменений по статусам и исполнителям — он пригодится и для разбора инцидентов, и для улучшения процессов.
Пилот на одной команде (1–2 очереди). Настройте 1–2 политики SLA и короткий список статусов.
Расширение на соседние команды. Добавьте роли и права, несколько календарей (если нужно), аккуратные исключения.
Унификация политик. Зафиксируйте единый словарь статусов и подход к паузам/ожиданиям, чтобы отчёты были сопоставимы.
Проверяйте не только «счастливый путь», но и крайние случаи:
Если данные живут в таблицах или текущей системе, начните с маппинга статусов и приоритетов: это главный источник перекосов в SLA. Сначала импортируйте «скелет» (тикеты, даты, текущие статусы), затем — историю и комментарии (если она нужна для аналитики).
Перед публикацией подберите релевантные ссылки на ваши материалы в /blog, а информацию о тарифах и вариантах внедрения держите в /pricing.
Внутренний SLA превращает устные ожидания в прозрачные правила: когда команда должна отреагировать, когда — довести до результата, и что считается паузой.
Практическая польза:
Если у вас много запросов и несколько исполнителей, ручной контроль перестаёт работать. Особенно быстро эффект появляется у:
Критерий «пора внедрять»: вы регулярно узнаёте о просрочке постфактум.
Для большинства контуров хватает трёх обязательств:
Дальше добавляйте усложнения только по боли: эскалации, разные правила по подразделениям, исключения.
Нужно заранее договориться, какие события запускают/останавливают таймеры, например:
Зафиксируйте определения письменно, иначе метрики будут «гулять» при каждом споре.
У внутреннего SLA важнее управляемость, чем юридическая точность:
Главное правило: любые изменения приоритета/политики должны оставлять след в аудите, иначе доверие к отчётам исчезнет.
Чтобы расчёты были корректными, в заявке обычно нужны:
Из вычисляемого — deadline_at, «оставшееся время», факт выполнения/нарушения. Также важно правило: пересчитывается ли дедлайн при смене приоритета (и с какого момента).
Две практики, которые почти всегда окупаются:
Если у вас распределённые команды, заранее решите: временная зона фиксирована для команды или определяется по заявке (регион заказчика).
Пауза нужна, чтобы SLA отражал реальную управляемость, а не зависимость от внешних ожиданий.
Рекомендации:
Так вы отделите «не успели» от «ждали входные данные».
Для доверенных метрик нужен неизменяемый след:
Практичный подход — append-only журнал событий и «снимок» применённой SLA‑политики в момент создания заявки, чтобы последующие изменения правил не переписывали историю.
Для MVP достаточно:
Важные требования к реализации:
Для углубления можно вынести события в отдельный ресурс (/events) и связать уведомления с вебхуками.