Поясняем, как шардинг делит данные между серверами и почему это усложняет систему: запросы, транзакции, сбои, переносы и отладка.
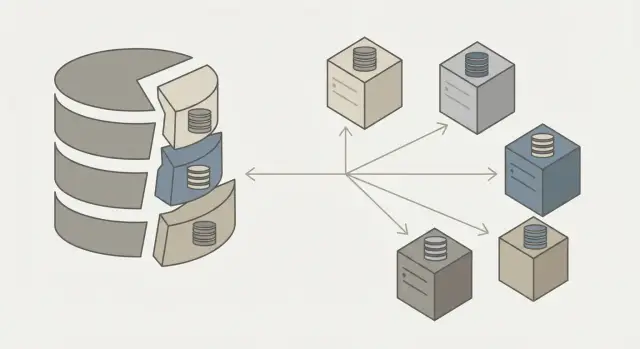
Шардинг — это способ «разрезать» одну большую базу данных на несколько частей (шардов) и хранить эти части на разных серверах. Каждый шард содержит только часть строк (например, пользователей с определёнными ID), но вместе шарды образуют логически одну базу.
Главная идея проста: вместо того чтобы бесконечно «усиливать» один сервер, мы распределяем данные и нагрузку между многими узлами.
Репликация — это копирование одних и тех же данных на несколько узлов. Она помогает с доступностью и чтением, но почти не увеличивает общую ёмкость: данные дублируются.
Партиционирование обычно означает деление данных внутри одного экземпляра/кластера (например, в рамках одной СУБД и одного набора ресурсов). Шардинг — это разделение данных между разными узлами, чтобы система масштабировалась горизонтально.
Ёмкость: когда база перестаёт помещаться на один сервер (диск, память, ограничения по таблицам/индексам).
Нагрузка: когда один сервер не справляется с количеством запросов (CPU, I/O, блокировки, очередь на запись).
Шардинг позволяет добавлять новые узлы и распределять по ним и данные, и запросы.
Плата за горизонтальное масштабирование — необходимость решать, куда положить данные и как до них добраться. Появляются маршрутизация запросов, операции сразу по нескольким шардам, перекосы нагрузки (горячие ключи), более сложные бэкапы и восстановление. И самое важное: становится труднее поддерживать единое понимание «какие данные истинные прямо сейчас» — особенно при сбоях и параллельных обновлениях.
Обычно шардинг появляется не потому, что он «модный», а потому что база упирается в пределы — по объёму данных, по нагрузке или по цене владения. Но прежде чем резать данные на шарды, почти всегда есть более простые и дешёвые шаги.
Вертикальное масштабирование — это «купить холодильник побольше»: тот же один агрегат, но вместительнее и мощнее. Для базы это означает больше CPU, RAM, быстрые диски, более производительный инстанс.
Горизонтальное масштабирование — «поставить второй холодильник и разложить продукты по двум». В базах это и есть шардинг: несколько узлов, каждый хранит часть данных.
Вертикальный путь проще: меньше движущихся частей, проще бэкапы, транзакции и понимание данных. Но у него есть потолок — технический и финансовый.
Признаки обычно накапливаются:
Часто проблему снимают без разделения данных:
Шардинг почти всегда увеличивает операционную сложность: маршрутизация запросов, кросс-шардовые операции, перенос данных и новые классы ошибок. Поэтому практичное правило такое: сначала выжать максимум из «одной базы» и лишь затем платить сложностью за дальнейший рост.
Шардирование часто описывают как «разрезание» базы на части. Важно уточнить: шард — это не только кусок данных, но и кусок нагрузки. Если данные разложены по разным местам, то и чтения/записи распределяются между разными машинами (в идеале — равномерно).
Кластер — это группа серверов (узлов), которые вместе обслуживают одну базу данных.
Узел (node) — конкретная машина/инстанс, где запущена СУБД. Узлов обычно много, потому что каждый шард нужно где-то хранить и обслуживать.
Шард — логическая часть данных (например, «пользователи с id 0…9 999 999») и/или часть нагрузки (запросы к этим пользователям).
Чтобы система была устойчивее к сбоям, каждый шард часто хранится не в одном экземпляре, а в нескольких копиях:
Термины различаются по СУБД, но идея одна: у шарда есть «главный» и «копии», чтобы переживать падения и разгружать чтения.
Главный вопрос на практике: какой узел отвечает за нужный шард. Приложение должно уметь быстро определить маршрут запроса.
Есть два распространённых подхода:
Этот промежуточный слой часто называют роутером или координатором (без привязки к конкретному вендору). Его задачи обычно такие:
На этом уровне появляются и первые ограничения: чем сложнее запрос (особенно если он затрагивает несколько шардов), тем больше работы ложится на координацию и тем выше цена ошибок маршрутизации.
Выбор стратегии распределения определяет, где физически окажется строка и насколько предсказуемо система будет вести себя под нагрузкой. На практике чаще всего встречаются два подхода: по диапазонам (range) и по хэшу (hash).
При range-шардинге вы делите пространство ключей на интервалы и привязываете каждый интервал к конкретному шарду: например, user_id 1–1 000 000 на shard-1, 1 000 001–2 000 000 на shard-2 и т.д.
Главный плюс — локальность и понятность. Запросы вида «покажи пользователей с user_id между X и Y» часто попадают в один или несколько соседних шардов. Это удобно для аналитики по диапазонам, временных срезов (если ключ — дата) и для последовательного чтения.
Минус — риск «горячих» диапазонов. Если новые записи всегда растут (монотонный ключ), то последние значения будут постоянно бить в один и тот же шард. В итоге один узел перегружен, а остальные простаивают.
При hash-шардинге вы берёте ключ (например, user_id), считаете хэш и по нему выбираете шард (часто по модулю числа шардов или через таблицу/кольцо).
Плюс — более равномерная нагрузка и меньше шансов, что «все новые данные» окажутся на одном шарде. Это популярно для OLTP-нагрузки, где много точечных запросов по ключу.
Минус — ухудшается локальность по диапазонам: запрос «user_id между X и Y» почти наверняка потребует обращения ко многим шардам.
Если основная операция — «получить пользователя по user_id», hash по user_id обычно даёт стабильные задержки.
Для заказов по order_id ситуация похожа: hash распределит заказы равномернее. Но если вам часто нужен отчёт «все заказы за неделю», и ключ/индекс завязан на время, range по дате может быть практичнее.
Перекос (skew) — это когда данные или запросы распределяются неравномерно. Он возникает из-за популярных значений (например, один «суперпользователь» генерирует 10% трафика), из-за монотонных ключей (новые id) или из-за корреляции ключа с поведением (в одном диапазоне — самые активные клиенты). Даже при hash это возможно: равномерность по данным не гарантирует равномерность по нагрузке.
Ключ шардинга — это правило, по которому запись «попадает» в конкретный шард. От него зависит почти всё: равномерность нагрузки, скорость запросов, сложность обслуживания и даже то, сможете ли вы потом безболезненно «переехать» на другую схему.
1) Равномерность распределения. Ключ должен делить данные и нагрузку так, чтобы шарды росли примерно одинаково и получали сопоставимое число запросов. Если один шард постоянно «толще» и горячее остальных — вы масштабируете систему, но упираетесь в один узел.
2) Стабильность. Идеальный ключ почти не меняется. Если значение ключа меняется часто, обновление превращается в перенос записи между шардами (фактически delete + insert), а вместе с этим — риск временной несогласованности, усложнение индексов, фоновые миграции и неожиданные пики нагрузки.
Частая ошибка: шардить по полю, которое «жизненно» меняется — например, по статусу, тарифу, региону, текущему менеджеру или любой «категории», которую бизнес любит переопределять.
3) Соответствие типичным запросам. Ключ должен совпадать с тем, как вы чаще всего читаете данные. Если 80% запросов — «покажи данные пользователя», ключ по user_id уменьшит число кросс-шардовых операций. Если же ключ не участвует в фильтрах, система будет постоянно ходить во все шарды (scatter/gather), а это дорого по задержкам и по ресурсам.
4) Понятность и проверяемость. Хороший ключ легко объяснить команде и легко диагностировать: почему запись оказалась на этом шарде, как воспроизвести маршрут запроса, как оценить перекос.
Опасность в том, что «равномерные данные» не равны «равномерной нагрузке». Один популярный пользователь, товар или чат может создать горячий ключ, а иногда целый диапазон значений — горячую партицию. Помогают: добавление случайного суффикса (соль), отдельные шарды под «топов», кэширование, а также продуманная стратегия ограничения всплесков.
Ключ, идеально подходящий для текущих запросов, может усложнить будущий рост: например, когда нужно добавлять шарды или менять схему. Поэтому выбирайте ключ так, чтобы его можно было расширять: предусмотреть место для перебалансировки, понимать, как будут жить вторичные индексы, и заранее принять, где вы готовы платить — в сложности запросов сейчас или в миграциях потом.
Шардирование меняет главный вопрос при выполнении запроса: «где лежат данные?». Пока вы не знаете, в какой шард идти, любая операция становится либо медленнее, либо сложнее в реализации.
Обычно есть три варианта:
user_id) и идёт напрямую. Это самый быстрый путь, но требует дисциплины в API и запросах.Кросс-шардовый запрос — это когда для ответа нужно сходить в несколько шардов. Цена растёт из‑за:
Если JOIN/агрегация не «помещается» в один шард, есть два неприятных сценария: либо вы гоняете данные между шардами, либо выносите вычисления в координатор (router/приложение), который собирает частичные результаты. Оба варианта дороже и сложнее в контроле.
Старайтесь, чтобы ключ шардинга присутствовал в каждом «горячем» запросе и фильтре. Держите вместе данные, которые часто читаются совместно (например, user + его заказы), избегайте глобальных уникальных проверок и «общих» списков без фильтра по ключу. Если нужен общий поиск/аналитика — планируйте отдельные витрины, индексы или асинхронные агрегаты, а не запрос «во все шарды сразу».
Шардинг почти всегда упирается в один вопрос: что считать «атомарной» операцией и как добиться согласованности, когда данные разложены по разным узлам.
Если все нужные записи лежат в одном шарде, вы живёте в привычном мире. Транзакция берёт блокировки локально, фиксируется одним журналом, откатывается предсказуемо, а задержка примерно равна задержке одного узла.
Это не значит, что ошибок нет — но они понятные: таймаут, конфликт блокировок, падение узла. И главное: границы ответственности совпадают с границами шарда.
Как только операция затрагивает два шарда, появляется координация. Нужно решить, кто «главный», как удерживать блокировки на разных узлах и что делать при частичном успехе.
Типичные эффекты:
Классический подход — двухфазная фиксация (2PC): сначала все участники обещают зафиксировать изменения, затем координатор отдаёт команду commit. Это повышает атомарность, но добавляет задержку и делает систему чувствительнее к сбоям координатора.
Поэтому часто выбирают «прикладные» альтернативы: SAGA/компенсации, eventual consistency, вынос единицы согласованности в один шард (например, «всё по одному пользователю»), или построение операций вокруг событий и очередей.
Раз ретраи неизбежны, операции делают идемпотентными: повторный вызов не меняет результат. Практика — генерировать operation_id, хранить факт выполнения и включать дедупликацию на стороне сервиса/БД.
Тогда повтор из‑за таймаута превращается из катастрофы в «шум», который система умеет безопасно переживать.
Когда база на одном сервере, у команды обычно есть простое ожидание: «если я записал значение, то любой следующий запрос увидит ровно его». В шардированной системе это ожидание ломается — не потому что кто-то «плохо сделал», а потому что данные и операции физически разнесены по разным узлам, а связь между ними не мгновенная.
«Истина в данных» — это когда два клиента, обращаясь к системе, видят согласованную картину: один и тот же баланс, один и тот же статус заказа, одно и то же наличие товара.
В распределённой базе приходится выбирать, какую гарантию вы даёте:
Шардирование добавляет к этому ещё одну ось сложности: операция может задевать один шард, а «картинка» для пользователя собирается из нескольких.
Если у шарда есть реплики, запись может сначала попасть на лидера, а чтение уйти на реплику. Тогда пользователь видит старое состояние: заказ уже «оплачен», но в интерфейсе ещё «ожидает оплаты». Это нормально с точки зрения системы, но неожиданно для продукта.
Практический вывод: важно явно решать, какие запросы могут читать с реплик (быстрее/дешевле), а какие обязаны читать с лидера (дороже, но точнее).
Типовые сценарии:
Чем больше операций затрагивают несколько шардов (например, перевод денег между пользователями на разных шардах), тем сложнее не потерять обновления без дополнительных протоколов.
Полезно заранее зафиксировать «контракты»:
Тогда «истина» становится не абстрактным обещанием, а набором понятных правил: где вы платите задержкой и сложностью ради точности, а где — принимаете небольшую рассинхронизацию ради скорости и простоты.
Шардинг почти всегда означает, что «отказ» перестаёт быть бинарным событием. Вместо «база работает/не работает» вы получаете множество состояний: один шард отвечает быстро, другой — с задержкой, третий — недоступен, а маршрутизатор видит противоречивую картину.
Сбой узла обычно заметнее: соединение рвётся, лидер реплики может переключиться, часть запросов сразу падает. Сбой сети (или частичная деградация сети) коварнее: узлы живы, но ответы приходят с задержками или не приходят вовсе. Для приложения оба случая часто выглядят одинаково — как таймаут.
Ключевой нюанс: при сетевой проблеме ваш запрос мог успеть выполниться, но ответ до клиента не дошёл. Это базовый источник «призрачных» ошибок.
Если запрос затрагивает один шард, вы можете продолжать обслуживать часть трафика. Но как только операция требует нескольких шардов (например, отчёт или перевод денег между пользователями на разных шардах), доступность падает до доступности самого слабого звена.
Практический итог:
Ретраи — естественная реакция на таймаут, но они же создают риск дублей: двойное списание, повторное создание заказа, повторная отправка письма. Поэтому любые «денежные» или «создающие» операции стоит проектировать как идемпотентные: с уникальным ключом операции и проверкой «уже выполнено».
Держитесь простого набора правил: ограниченные ретраи с экспоненциальной паузой, единый дедлайн на всю цепочку вызовов и вынесение «долгих» действий в очередь.
Если действие можно выполнить асинхронно, очередь и обработчик с дедупликацией часто дают более предсказуемое поведение, чем попытки «дожать» запрос синхронно во время деградации.
Рано или поздно выбранная схема распределения перестаёт «ложиться» на реальную нагрузку: появляются перекошенные шарды, заканчивается место, меняются паттерны запросов. Тогда возникает решардинг — изменение разбиения данных без простоя сервиса.
На практике решардинг часто выглядит как:
Важно: это не просто «скопировать таблицу». Нужно сохранить корректность чтения/записи, пока данные живут сразу в двух местах.
Перенос данных конкурирует за те же ресурсы, что и продуктовая нагрузка: диск, сеть, CPU, кеши. Даже если миграция идёт «в фоне», она может:
Поэтому миграция почти всегда должна быть ограниченной по скорости и наблюдаемой по метрикам.
Во время решардинга меняется логика: «по какому адресу лежит запись». Обычно есть слой маршрутизации (таблица/служба), который получает новую версию правил. Риски здесь типовые:
Чтобы перенос прошёл без сюрпризов, заранее задают:
Решардинг — это не разовая операция, а управляемый процесс, где главное — предсказуемость и возможность остановиться без потери данных.
Шардинг часто «продают» как способ масштабирования, но реальная цена проявляется в эксплуатации: теперь у вас не одна база, а целый парк однотипных, но не всегда одинаково здоровых частей.
Любое изменение схемы (новое поле, индекс, ограничение) нужно протащить по всем шардам. Если делать это «вручную», вы быстро получите дрейф: на одних шардах индекс уже есть, на других — ещё нет, и одинаковый запрос ведёт себя по‑разному.
На практике помогают:
Важно планировать откат: иногда «откатить миграцию» сложнее, чем выкатить.
Бэкап одного шарда — не то же самое, что восстановление всей системы. Если данные между шардами связаны логикой приложения, вам нужен согласованный срез во времени: иначе после восстановления часть данных окажется «из будущего», а часть — «из прошлого».
Минимальный набор практик:
Мониторинг должен показывать и детали, и картину целиком. Полезно иметь дашборды по каждому шару (нагрузка, латентность, лаг репликации, ошибки) и агрегированные показатели (p95/p99 по всем шардам).
Отдельно следят за перекосами: «горячие ключи» и неравномерное распределение часто видны как один перегруженный шард при нормальных остальных.
На стейдже обычно меньше данных, другая форма распределения ключей и нет реальных перекосов. В проде же проблемы вызывают объём, конкуренция запросов и частичные сбои.
Помогают генерация данных, близких к продовым (включая перекосы), тесты деградации (один шард медленный/недоступен), а также проверки кросс-шардовых сценариев: они чаще всего ломаются первыми.
Шардинг — это не «ускоритель по умолчанию», а обмен простоты на масштабирование. Он почти всегда увеличивает стоимость разработки, эксплуатации и расследования инцидентов. Поэтому решение лучше принимать как продуктово‑техническую инвестицию: какие ограничения вы снимаете и какую сложность покупаете.
Перед тем как резать базу на шарды, ответьте на вопросы:
Более мощный сервер (вертикальное масштабирование) и настройка хранилища.
Индексы, партиционирование, оптимизация запросов, уменьшение «толщины» строк.
Кэш (например, для горячих чтений) и реплики чтения для разгрузки primary.
Перенос аналитики в отдельное хранилище/витрину, чтобы не мучить OLTP.
Если главная боль — «собрать данные из разных мест», иногда эффективнее не шардинг, а пересборка модели: денормализованные представления, материальные агрегаты, событийная модель (outbox/стрим) с построением проекций под конкретные экраны и отчёты. Это снижает число запросов, которым нужен глобальный join.
Сразу договоритесь о метриках: p95/p99 задержек, пропускная способность, доля кросс-шардовых запросов, время восстановления после сбоя, длительность релизов и миграций, число инцидентов и время расследования, стоимость инфраструктуры и on-call. Если выигрывает только нагрузочный тест, а поддержка становится вдвое дороже — это сигнал пересмотреть решение.
Когда вы доходите до шардинга, резко растёт объём «прикладной» работы вокруг базы: роутинг по ключу шардинга, идемпотентность, фоновые миграции, скрипты проверок, сервисы метаданных, а также тесты деградации.
TakProsto.AI (vibe-coding платформа для российского рынка) может ускорить такие задачи на уровне прототипов и внутренних инструментов: вы описываете требования в чате — а платформа помогает собрать веб‑интерфейс (React), бэкенд (Go) и PostgreSQL‑схему для каталога шардов/операций, с поддержкой планирования (planning mode), снапшотов и отката. Важно, что TakProsto.AI работает на серверах в России и использует локализованные и opensource LLM‑модели, не отправляя данные за пределы страны — это отдельно полезно для инфраструктурных проектов, где чувствительны схемы и операционные данные.
Лучший способ понять возможности ТакПросто — попробовать самому.