Пошаговый план: как превратить внутренний веб-инструмент в публичный сервис — безопасность, роли, инфраструктура, UX, документация, поддержка и монетизация.
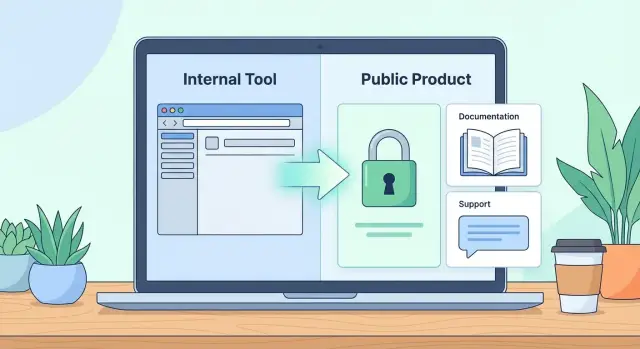
Внутренний инструмент живёт в «тепличных» условиях: понятная аудитория, предсказуемые данные, доступ по корпоративной сети, быстрые договорённости «в коридоре». Когда вы превращаете его в публичный веб‑сервис, меняется не только интерфейс — меняются правила игры. Теперь любой пользователь может прийти без контекста, ошибиться, нагрузить систему неожиданным сценарием и ожидать, что всё будет работать стабильно и безопасно.
Важно и другое: «вынести наружу» — это почти всегда отдельный продуктовый проект, а не просто релиз. Чтобы не утонуть в бесконечном списке «доделаем потом», удобно заранее зафиксировать минимальные требования и порядок работ — как чек‑лист.
Если вы планируете ускорить путь от идеи до работающего сервиса, часть задач можно закрывать быстрее на платформах vibe‑coding. Например, в TakProsto.AI можно собрать прототип публичного приложения через чат (веб на React, бэкенд на Go с PostgreSQL, при необходимости — мобильный клиент на Flutter), а затем экспортировать исходники, развернуть и вести продукт уже как полноценный сервис. Это не заменяет продуктовую дисциплину ниже — но помогает быстрее пройти «первую милю».
Во внутреннем продукте часто допустимы компромиссы: один общий аккаунт, ручная выдача доступов, отсутствие полноценной истории действий, «потом поправим». Публичный веб‑сервис требует формализации: кто пользователь, какие у него права, что он может увидеть, где заканчивается ответственность команды и начинается ответственность клиента.
Ещё одно отличие — доверие. Внутри компании вы доверяете людям и данным по умолчанию. Снаружи доверие нужно заслужить: понятной политикой доступа, защитой данных, прозрачностью статуса сервиса и качественной поддержкой.
Первым ломается доступ: нет регистрации, нет восстановления пароля, нет ролей, нет блокировок, нет защиты от перебора. Вторым — нагрузка: внутренние 50 пользователей внезапно превращаются в сотни или тысячи, а самые тяжёлые отчёты запускаются одновременно.
Третьими ломаются ожидания: внешний пользователь не знает ваших терминов, не читает «инструкцию в вики», не прощает неожиданных ошибок и хочет прогнозируемый результат. Если сервис берёт деньги — к ожиданиям добавляются вопросы про тарифы, возвраты и сроки реакции поддержки.
Материал ориентирован на продуктовых менеджеров, разработчиков, DevOps/инфраструктуру и поддержку — всех, кто участвует в запуске продукта. Цель — дать общий язык и порядок действий, чтобы не «переизобретать очевидное» в последний момент.
Ниже — практичный чек‑лист запуска публичного сервиса: от выбора MVP и границ продукта до аутентификации и ролей, изоляции данных клиентов, безопасности, производительности, наблюдаемости, документации, поддержки, тарифов и первых недель после релиза.
Внутренний инструмент обычно «заточен» под привычки команды: все знают термины, доверяют друг другу и понимают, что где лежит. Публичный веб‑сервис живёт по другим правилам: пользователи приходят с разными задачами, ожидают ясности и не прощают неоднозначностей. Поэтому перед MVP важно зафиксировать: для кого продукт, какую работу он делает и чего в нём пока не будет.
Сформулируйте 1–3 ключевых сегмента. Полезный приём — разделить роли:
Для каждого сегмента запишите контекст: размер компании, тип данных, критичность к безопасности, ограничения по бюджету и закупкам.
Опишите 3–5 «историй», которые показывают путь к ценности. Например: «подключил источник данных → настроил правило → получил отчёт/выгрузку → поделился с командой».
Определите критерии успеха: активация, удержание, время до ценности. Хорошие стартовые метрики:
Отделите «обязательное для всех» от «опций для отдельных клиентов». Обязательное — то, без чего сценарии не работают у большинства. Опции — кастомные поля, специфические интеграции, редкие форматы отчётов.
Чтобы не расползтись, заведите простое правило: всё, что нужно только одному клиенту, попадает в список «позже» до тех пор, пока не появится повторяемость.
Соберите список рисков и ограничений (данные, доступы, бюджет). Примеры: хранение персональных данных, требования к журналированию, ограничения на внешние интеграции, лимиты команды на поддержку.
Итогом этого шага должен стать короткий документ на 1–2 страницы: сегменты, топ‑сценарии, метрики успеха, границы MVP и список рисков. Он станет опорой для следующих решений — от доступов до тарифов.
Когда внутренний инструмент становится продуктом, главная ошибка — пытаться «вынести наружу всё как есть». Начните с короткого, но честного аудита: он покажет, что реально готово к публичному использованию, а что держится на внутренних костылях.
Если вы делаете MVP «с нуля» или быстро пересобираете старое решение, полезно отделить две задачи: (1) проверить ценность и сценарии, (2) довести сервис до надёжного публичного уровня. В TakProsto.AI часто начинают с первого — собирают работающий прототип через чат, валидируют ключевой путь и только затем «упаковывают» безопасность, наблюдаемость и биллинг.
Составьте список всех экранов, кнопок, отчётов, интеграций и админских возможностей. Затем разложите по трём корзинам:
Полезный критерий: если фича не имеет понятного описания в одном абзаце и не влияет на ценность для внешнего пользователя — она почти наверняка не для MVP.
Внутренние инструменты часто опираются на инфраструктуру компании: закрытые базы, VPN, внутренние API, сетевые allowlist, корпоративные учётки. Зафиксируйте зависимости в явном виде:
Эта карта поможет понять, что нужно заменить публичными аналогами, а что — изолировать.
Отдельно оцените, какие данные можно показывать внешним. Частые проблемы: тестовые записи, персональные данные, внутренние комментарии, поля «для бухгалтерии». Выделите минимальный набор полей для отображения и запланируйте очистку/маскирование там, где нужно.
Итог аудита — короткий план на 2–6 недель:
Чтобы зафиксировать ожидания, оформите это как одну страницу в документации продукта и добавьте ссылку из рабочего пространства команды (например, /blog/roadmap-mvp).
Когда внутренний инструмент становится публичным, авторизация перестаёт быть «галочкой». Это входная дверь в продукт, и от того, как она устроена, зависит безопасность, поддержка и даже конверсия.
Начните с ответа на вопрос: кто ваш пользователь — отдельный человек или компания.
Если вы продаёте B2B и ожидаете корпоративных клиентов, логично поддержать SSO (SAML/OIDC): администратор подключает корпоративного провайдера, а пользователи заходят привычным способом.
Для широкой аудитории подойдёт e‑mail/пароль, но делайте его «небольным»: подтверждение e‑mail, восстановление пароля, понятные сообщения об ошибках.
OAuth удобен как быстрый старт и снижает трение на входе, но выбирайте провайдеров, с которыми вам комфортно работать юридически и операционно.
Не пытайтесь угадать все сценарии сразу — достаточно простого RBAC:
Важно отделять «роль» от «доступа к конкретному ресурсу». Например, участник может иметь доступ не ко всем проектам, а только к выбранным.
Публичный сервис почти всегда становится командным. Добавьте:
Подумайте об «одиночных» аккаунтах: пользователь должен понимать, как создать рабочее пространство и как пригласить коллег.
Минимум, который стоит включить сразу:
Если планируете корпоративные продажи, заранее опишите эти механики в документации и на странице безопасности (например, /security).
Когда внутренний инструмент становится публичным сервисом, главная смена парадигмы — вы больше не «работаете с данными компании», вы храните данные разных клиентов рядом. Ошибка в фильтре или настройках доступа превращается в утечку.
Начните с явной модели «клиент → организация → проекты». Важно, чтобы у каждой записи в базе был понятный «владелец» (например, org_id или tenant_id), и чтобы доступ к данным всегда строился через него, а не через случайные условия.
Есть несколько стратегий изоляции, от простых к более строгим:
tenant_id: быстрее внедрить, но требует дисциплины в запросах.Для большинства MVP подходит первый вариант, но с обязательными защитными механизмами: единый слой доступа к данным (репозитории/ORM), автоматические фильтры по tenant_id и тесты, которые проверяют, что «чужие» записи не возвращаются.
Опишите правила заранее: сколько вы храните данные, как выполняете удаление, что происходит после удаления аккаунта/организации. Добавьте понятные пользователю функции экспорта (например, CSV/JSON) и при необходимости импорта, чтобы снизить барьер перехода.
Отдельно продумайте резервные копии: если вы удаляете данные по запросу, убедитесь, что политика бэкапов согласована с этим (например, ограниченный срок хранения).
Сделайте аудит‑лог для ключевых операций: вход, смена ролей, изменение настроек, импорт/экспорт, удаление данных, операции с платежными/интеграционными настройками. В логе фиксируйте «кто, что, когда, откуда (IP/устройство) и в каком контексте (org_id/project_id)». Это помогает разбирать инциденты и спорные ситуации.
Перед публичным запуском проведите ревизию: демо‑аккаунты, тестовые проекты, служебные справочники, «зашитые» токены, старые выгрузки. Надёжное правило: публичная среда не должна содержать ничего, что вы не готовы показать клиенту — даже если это «только названия» или «без персональных данных».
Когда внутренний инструмент становится публичным веб‑сервисом, он перестаёт быть «за периметром». Теперь потенциальный атакующий — любой пользователь интернета, а ошибка в настройке или логике превращается в реальный риск для данных и денег.
Опишите: что защищаем (аккаунты, данные клиентов, платежи), от кого (внешние злоумышленники, недобросовестные пользователи, ошибки сотрудников) и через какие входы (веб‑интерфейс, API, интеграции, админка). Дальше составьте список «минимума»: что будет считаться критичным инцидентом и какие меры обязательны до публичного запуска.
Дайте сервисам и сотрудникам ровно те права, которые нужны.
Для сотрудников: разделите роли (поддержка, биллинг, админ), запретите общий доступ «всем ко всему», включите 2FA для админ‑учёток.
Для сервисов: отдельные учётные записи для БД/очередей/хранилищ, запрет прав на удаление и админские операции там, где они не требуются. Любой токен интеграции должен быть ограничен по скоупам.
Не держите ключи в репозитории и в «общем чате». Используйте переменные окружения и менеджер секретов (или хотя бы защищённое хранилище в CI/CD).
Настройте ротацию ключей: заранее продумайте, как вы поменяете секрет без простоя, и кто имеет право это делать. Логи и дампы не должны содержать токены и пароли.
Обязательно HTTPS везде, перенаправление с HTTP, HSTS.
Добавьте базовые заголовки безопасности (например, CSP, X‑Frame‑Options/Frame‑Ancestors, X‑Content‑Type‑Options), ограничьте CORS.
Закройте типовые уязвимости: валидация входных данных, защита от SQL‑инъекций через параметризацию, экранирование в шаблонах против XSS, CSRF‑токены для форм, rate limiting на логин и чувствительные эндпоинты.
Заранее зафиксируйте «кто и что делает»: контакты ответственных, критерии эскалации, порядок отключения функций/ключей, сбор артефактов (логи, таймлайны), коммуникация с пользователями.
Даже короткий runbook на одну страницу сильно сокращает время простоя и стоимость ошибки.
Пока инструмент живёт внутри компании, его «неидеальности» часто компенсируются: можно попросить коллегу подождать, вручную перезапустить задачу или обойти баг. Публичный веб‑сервис так не прощает: пользователи просто уйдут. Поэтому перед запуском важно проверить, выдержит ли продукт нагрузку и как он поведёт себя при сбоях.
Начните с простого вопроса: что будет, если завтра придёт в 10 раз больше пользователей, чем сегодня? Оцените пиковые сценарии (утренние часы, конец месяца, массовая рассылка) и выделите критичные точки:
Полезно заранее определить целевые метрики: время ответа для ключевых страниц, допустимая задержка для фоновых операций, максимальная длительность выполнения типовых запросов.
Не пытайтесь «ускорить всё». Обычно достаточно закрыть 20% самых частых операций:
Бэкап без проверки восстановления — это надежда, а не план. Настройте резервное копирование данных и конфигураций, определите RPO/RTO (сколько данных можно потерять и как быстро подняться) и регулярно проводите тестовое восстановление на отдельном окружении.
Сформулируйте понятные триггеры роста: при каких метриках вы увеличиваете ресурсы (вертикально) и когда добавляете новые экземпляры приложения или базу‑реплику (горизонтально). Зафиксируйте ограничения: лимиты внешних API, максимальные размеры файлов, таймауты, квоты на фоновые задачи. Такой план снижает хаос в первые недели после релиза и помогает расти предсказуемо.
Внутренний инструмент обычно «прощает» многое: пользователи знают контекст, аббревиатуры и обходные пути. В публичном веб‑сервисе интерфейс должен объяснять себя сам — иначе люди уйдут, не получив ценности.
Начните с терминов. Замените внутренние сокращения на понятные названия, добавьте краткие пояснения прямо в интерфейсе (иконка «?» рядом с полем работает лучше, чем длинные справки).
Навигацию делайте по задачам пользователя, а не по структуре вашей команды. Если у вас «Модуль A → Модуль B», снаружи это часто выглядит как «Создать → Проверить → Отправить».
Хороший онбординг — это не попапы «нажмите сюда», а уверенный маршрут от нуля к ценности:
Цель — чтобы пользователь понял, что сервис делает, за 1–2 минуты и увидел первый результат за 5–10 минут.
Найдите главный сценарий (например, «загрузить данные → получить отчёт») и уберите лишнее:
Если есть регистрация, не заставляйте заполнять профиль до того, как человек попробовал продукт. Дополнительные данные можно запросить позже.
Даже простой сервис выигрывает, если его можно использовать в разных условиях:
В итоге UX становится вашим «молчаливым саппортом»: меньше вопросов, меньше ошибок, выше конверсия в регулярное использование.
Когда внутренний инструмент становится публичным сервисом, «посмотреть в базу» или спросить коллегу уже не работает. Нужны данные, которые быстро отвечают на вопросы: что ломается, у кого, как часто и почему.
Начните с небольшого набора, который напрямую связан с качеством и ростом продукта:
Важно заранее определить несколько SLI/SLO (например, «99,9% успешных запросов к API за 30 дней» и «p95 ответа < 400 мс»), чтобы алерты были привязаны к ожиданиям, а не к случайным цифрам.
Логи должны быть структурированными (JSON), с обязательными полями: timestamp, level, request_id, user_id (если уместно), tenant_id, route, status, latency_ms, error_code. Это упростит поиск инцидентов и поддержку.
Алерты настраивайте по:
Если архитектура состоит из нескольких сервисов, добавьте распределённый трейсинг: он покажет, где теряется время (БД, сеть, конкретный сервис), и поможет быстро локализовать проблему.
Соблюдайте принцип «собираем только то, что нужно»: не логируйте пароли, токены, содержимое документов и лишние персональные данные. Для событий аналитики используйте понятные уведомления в интерфейсе и настройках, а в логах — маскирование и ограниченные сроки хранения.
Если нужно, заранее опишите это в /privacy и в краткой справке внутри продукта.
Когда внутренний инструмент становится публичным, пользователи больше не могут «подойти к разработчику» и уточнить, что имелось в виду. Документация и поддержка — это ваш способ сохранить понятность продукта, снизить число обращений и быстрее находить реальные проблемы.
Начните с короткой «справки для старта» — она важнее длинных мануалов. Хорошая структура выглядит так:
Держите тексты короткими и привязанными к экранным шагам: «нажмите → получите → проверьте здесь». Если есть роли и доступы, добавьте таблицу «роль → что может».
Отдельно опишите:
Важно: ошибки должны иметь «человеческий» текст и ссылку на статью с решением, например: «Не удалось импортировать CSV → проверьте разделители → /docs/import-csv».
Сделайте страницу статуса или хотя бы раздел «Доступность», где честно написано, что вы измеряете и где смотреть инциденты: /status.
Каналы поддержки лучше определить заранее: почта, форма в продукте, тикеты. Укажите ожидаемые сроки ответа, но без обещаний, если не уверены:
Добавьте правила: что прикладывать к обращению (ID проекта, время, шаги, скриншот), и это сразу ускорит разбор.
Внутренний инструмент обычно «окупается» временем команды. Публичный сервис должен окупаться деньгами — и при этом оставаться понятным: за что именно платят, что входит в план, какие есть ограничения и как безболезненно перейти на следующий уровень.
Есть четыре базовые модели, которые можно комбинировать:
Если сомневаетесь, начните с простого: trial + подписка или free + подписка. Главное — чтобы первый результат пользователь получал быстро.
Отдельно стоит заранее продумать «лестницу» планов. Например, в TakProsto.AI она обычно выглядит как free / pro / business / enterprise — такой формат хорошо объясняется пользователю: от знакомства и прототипа до корпоративных требований (доступы, контроль, процессы).
Ограничения должны быть прозрачными и измеримыми:
Важно: когда лимит достигнут, показывайте понятное сообщение — что произошло, что будет дальше, и какая опция решает проблему (апгрейд, докупка объёма, ожидание следующего периода).
Продумайте «бытовые» сценарии заранее: выставление счетов для юрлиц, изменение реквизитов, закрывающие документы (если применимо), автопродление, пауза/отмена подписки, смена плана в середине периода (pro‑rate или по вашему правилу).
По возвратам зафиксируйте политику: например, возврат в течение 7 дней при отсутствии существенного использования или без возвратов, но с возможностью отмены автопродления. Эту логику стоит кратко описать в интерфейсе и в условиях.
Сделайте страницу /pricing максимально прикладной: не перечисление функций, а ответы на вопрос «что я смогу сделать». Для каждого плана добавьте:
Так тарифы перестают быть таблицей ограничений и становятся упаковкой ценности.
Публичный запуск — это не «нажать кнопку», а аккуратно перевести сервис в режим, где пользователи приходят сами, задают вопросы, оплачивают и ожидают предсказуемой работы. Большую часть рисков можно снять простым планом и дисциплиной.
Проверьте базовые вещи, которые чаще всего ломают старт:
Если у вас есть статус‑страница или хотя бы раздел /status — добавьте ссылку на неё в футер и в письма поддержки.
Запускайте с ограниченной группой: по инвайтам, через лист ожидания или отдельный тариф «Бета». Важно заранее определить, что именно вы проверяете (например: онбординг, ключевой сценарий, оплату) и как собираете обратную связь.
Практика, которая работает: короткая форма после первого успешного результата в продукте и возможность написать в поддержку из интерфейса.
Перед открытием доступа подготовьте:
Запланируйте пострелиз заранее: ежедневная сортировка обращений, приоритизация багов по влиянию на оплату и ключевые сценарии, быстрые итерации (не «идеально», а «улучшили — проверили — выкатили»).
Отдельно ведите «долг»: всё, что не мешает пользователям сегодня, но станет проблемой при росте. Это поможет не утонуть в хаотичных правках после первых успехов.
Если вы строите продукт на TakProsto.AI, удобно использовать «снимки» и откат (snapshots/rollback) как страховку на время первых релизов, а также экспорт исходников — чтобы зафиксировать контроль над кодовой базой и дальше развивать сервис в привычном для команды процессе программирования. При этом платформа работает на серверах в России и использует локализованные модели, что часто упрощает обсуждение требований к данным и инфраструктуре на раннем этапе.
Сфокусируйтесь на 1–3 ключевых сегментах и разделите роли:
Дальше опишите 3–5 «историй» от входа до результата и зафиксируйте метрики: активация, время до ценности, удержание.
Сделайте инвентаризацию всех экранов и функций и разложите по трём корзинам:
Практическое правило: если функцию нельзя объяснить в одном абзаце как ценность для внешнего пользователя — это почти наверняка не MVP.
Составьте карту зависимостей:
Затем решите, что заменяете публичными аналогами, а что изолируете/убираете из публичного контура.
Выберите модель под ваш рынок:
В любом варианте обязательно: понятные ошибки, ограничение попыток входа, защита от перебора, и 2FA как минимум для админов и доступа к оплате.
Начните с простого RBAC и не усложняйте раньше времени:
Отдельно разделяйте роль и доступ к ресурсу: один и тот же «участник» может иметь доступ только к части проектов/папок.
Выберите и зафиксируйте модель мультиарендности (multi-tenant):
tenant_id/org_id (быстро для MVP, но нужна дисциплина)Для варианта с tenant_id добавьте защитные механики: единый слой доступа к данным (ORM/репозитории), автоматические фильтры по арендатору и тесты, проверяющие, что «чужие» записи не возвращаются.
Логируйте операции, которые важны для безопасности и разборов:
Фиксируйте минимум полей: кто, что, когда, откуда (IP/устройство), в каком контексте (org_id/project_id). Это резко ускоряет расследование инцидентов и работу поддержки.
Минимальный набор до релиза:
Параллельно — управление секретами: не хранить ключи в репозитории, использовать защищённое хранилище в CI/CD и продумать ротацию без простоя.
Сначала оцените пики и узкие места:
Практичные шаги: кэшировать часто читаемое, выносить тяжёлые операции (отчёты, импорт/экспорт, письма) в фон, использовать очереди для сглаживания пиков. И обязательно проверить восстановление из бэкапа, а не только его наличие.
Соберите «операционный минимум»:
Логи делайте структурированными (JSON) с , (если уместно), , , , , . Алерты привязывайте к SLO (например, доступность и p95), а не к «любым всплескам».
request_iduser_idtenant_idroutestatuslatency_mserror_code