Практичный план: как спроектировать техблог, настроить генерацию программных страниц, шаблоны, SEO, перелинковку, скорость и деплой для роста.
Техблог — это не просто лента статей. Чаще всего он решает одну (или несколько) практических задач: привлекает поисковый трафик, превращается в базу знаний для команды и пользователей, а ещё работает как «витрина» вашей экспертизы — когда читатель видит, что вы действительно разбираетесь в теме.
Прежде чем выбирать инструменты, зафиксируйте, какие сущности будут на сайте. Обычно это:
Важно: если заранее не договориться о типах страниц, дальше будет сложно сделать понятную навигацию, перелинковку и единый стиль.
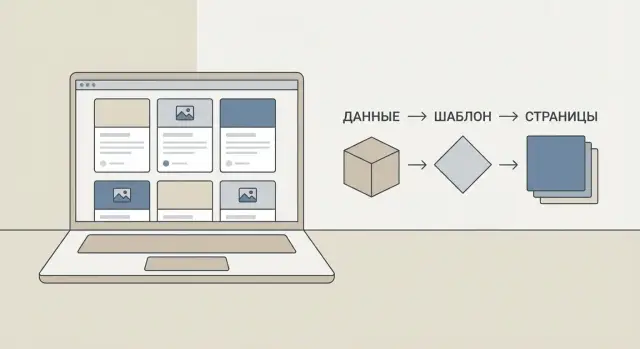
Программные (programmatic) страницы — это когда вы делаете один шаблон, а затем генерируете много страниц из данных.
Пример: у вас есть список тегов, авторов и статей. По одному шаблону собираются страницы /tags/devops, /authors/ivan-petrov, /series/observability и т. д. Вы не верстаете каждую из них вручную — вы описываете правила и структуру, а сайт создаёт страницы автоматически.
Чтобы проект не превратился в бесконечную доработку, заранее задайте измеримые критерии:
После этого шага полезно набросать «карту» будущих разделов и выбрать приоритет: сначала статьи и теги, а серии/сравнения — позже. Это снижает риск переусложнить запуск.
Хорошая структура техблога — это когда и читатель, и поисковик сразу понимают: где список материалов, где темы, где авторы, а где конкретная статья. Для программных страниц это особенно важно: одна ошибка в правилах URL может размножить дубли и «размазать» вес.
Отталкивайтесь от простой и расширяемой схемы:
Такая карта помогает планировать навигацию и сразу задаёт рамки для генерации программных страниц.
Договоритесь о правилах один раз и зафиксируйте их в документации проекта:
/blog/tag/next-js, а не /blog/tag/NextJS.tech-debt лучше читается, чем tech_debt.Продумайте элементы, которые будут увеличивать глубину просмотра:
Блог → Тема → Статья.Чтобы не плодить дубли, заранее определите «главные» версии:
?sort=, ?utm=) должны либо иметь canonical на чистый URL, либо быть закрыты от индексации по правилам SEO-команды.Если вы хотите показать пользователю фильтры, но не хотите индексировать каждую комбинацию, отделяйте UX от того, что реально должно попадать в поиск.
Программные страницы начинаются не с генератора, а с понятной контентной модели: какие «сущности» есть на сайте, какие у них поля и откуда берутся данные. Чем аккуратнее вы это зададите, тем легче масштабировать блог и избегать хаоса в URL, тегах и SEO.
Минимальный набор для техблога:
Для Article полезно стандартизировать поля: title, description, slug, date, updated, tags, canonical, faq.
Практика, которая экономит время: сразу договориться, что slug — только латиница/цифры/дефисы, date — в ISO-формате, updated заполняется при существенных правках, а canonical обязателен для репаблишинга.
Выберите источник под ваш процесс:
Главное — держать единый слой загрузки данных, чтобы смена источника не ломала шаблоны.
Добавьте правила: обязательные поля, уникальность slug, ограничения длины заголовков и описаний, проверка, что теги и категории существуют. Это снижает шанс пустых страниц, дублей и «битых» canonical.
Храните изображения и диаграммы там, где их легко версионировать и кэшировать (репозиторий или объектное хранилище). Для каждого файла заведите понятные имена, alt-тексты и превью для шаринга. Если диаграммы генерируются, фиксируйте исходники рядом — так проще обновлять статьи без потерь.
Фреймворк и способ рендеринга определяют, насколько быстро вы сможете выпускать программные страницы, как будет работать SEO, и сколько сил уйдёт на поддержку. Здесь важнее не «модно», а «предсказуемо» для вашей команды и контентного потока.
SSG (Static Site Generation, предсборка) — страницы генерируются заранее и отдаются как статические файлы. Подходит, если статьи и справочники обновляются не каждую минуту, а скорость и простота хостинга критичны. Отличный вариант для большинства техблогов с программной генерацией.
SSR (Server-Side Rendering) — страница собирается на сервере при каждом запросе. Полезно, когда контент зависит от авторизации, гео/AB-тестов или данные меняются очень часто. Минусы: дороже в эксплуатации и выше риск «медленных» страниц при пиках.
ISR/гибрид (Incremental Static Regeneration) — компромисс: страницы по сути статические, но могут пересобираться по расписанию или по событию. Это удобно для programmatic SEO, когда у вас тысячи URL и нужно обновлять только изменившиеся.
Смотрите на: поддержку нужного рендеринга, простоту работы с вашей контентной моделью, скорость сборки при росте числа страниц и стабильность деплоя.
Если авторы пишут в CMS и ждут быстрых предпросмотров, вам важны preview-окружения и понятный пайплайн сборки. Если поддерживать сайт будет один человек, выбирайте то, что проще обновлять и дебажить, даже если теоретически есть более «оптимальный» стек.
Отдельно оцените, как вы будете создавать и менять шаблоны программных страниц. Например, для команд, которым важно быстро собрать прототип и затем забрать исходники, может подойти TakProsto.AI: это vibe-coding платформа, где веб-приложения (включая контентные сайты на React) собираются из диалога, с возможностью экспорта кода, деплоя, снапшотов и отката. Это удобно, когда нужно быстро проверить структуру таксономий, шаблоны листингов и базовые SEO-настройки до того, как вы «закопаетесь» в полной реализации.
Проверьте заранее:
Если эти пункты закрыты, программные страницы будут масштабироваться без неприятных сюрпризов при росте трафика и объёма контента.
Чтобы программные страницы выглядели единообразно и не расползались по стилям, сначала договоритесь о «скелете» страниц и наборе повторяемых компонентов. Это экономит время авторам, упрощает поддержку и делает опыт чтения предсказуемым.
Минимальный комплект обычно включает:
Для материалов на ~3000 слов заранее продумайте читаемость:
Задайте стандарты: контраст, размеры шрифта, межстрочный интервал, кликабельные зоны ссылок, видимый фокус клавиатуры. Заголовки должны отражать структуру (H1 один, дальше по иерархии), а ссылки — отличаться не только цветом.
Добавьте повторяемые элементы, которые помогают читателю оценить актуальность:
Главная идея: контент меняется, а интерфейс и правила — стабильны. Тогда программная генерация действительно работает на масштаб, а не на хаос.
Программные страницы появляются не «сами»: вам нужен воспроизводимый пайплайн, который берёт данные, превращает их в список маршрутов, подставляет в шаблоны и выпускает готовый HTML. Если этот конвейер прозрачен, вы легко добавляете новые типы страниц и контролируете качество.
Начните с понятных генераторов:
/tags/observability, /tags/kubernetes — для широких тем./category/backend — если есть стабильная рубрикация./authors/ivan-petrov — удобно для редакционного блога./series/ci-cd-basics — для материалов, которые читают по порядку.Важно: заранее решите минимальный порог ценности. Например, не создавать страницу тега, если по нему меньше 2–3 статей.
Базовая схема всегда одна и та же:
входные данные → маршруты → шаблон → HTML.
На входе могут быть Markdown-файлы, CMS, таблица или API. На шаге маршрутов вы строите список URL (например, все теги, все авторы, все страницы пагинации). Дальше каждый маршрут рендерится одним из шаблонов: карточки в листинге, шапка автора, блок «похожие статьи» и т. д.
Для листингов используйте пагинацию вида /tags/observability/page/2. Первая страница должна быть канонической (без /page/1), а остальные — индексируемыми, если на них есть уникальные карточки и навигация. Обязательно добавьте ссылки «Назад/Вперед» и понятный заголовок листинга.
Два рабочих режима:
Старайтесь пересобирать только затронутые страницы (статья, её теги, категория, автор, серия), чтобы обновления были быстрыми.
Не генерируйте страницы с «нулевой ценностью»: пустые теги, авторов без публикаций, серии из одной заметки, дублирующие листинги. Лучше показывать такие сущности только внутри навигации или скрывать до накопления контента — так вы экономите бюджет сканирования и удерживаете качество сайта.
SEO для техблога с программными страницами начинается не с «лайфхаков», а с аккуратной технической базы: предсказуемые метаданные, понятные сигналы для поисковиков и корректные файлы служебной инфраструктуры.
Для каждой статьи и для каждого типа программной страницы задайте минимум:
Если страницы генерируются из данных, зафиксируйте правила: как строится title из полей, что делать, если нет обложки, как ограничивать длину.
Добавьте структурированные данные, которые реально соответствуют содержимому:
Минимальный набор для /blog:
Служебные страницы (поиск по сайту, черновики, превью) помечайте noindex.
Удалённый контент:
Прогоните ключевые шаблоны через валидатор микроразметки и инструменты предпросмотра сниппетов. Отдельно проверьте, что canonical, Open Graph и sitemap совпадают с реальными URL и не ведут на редиректы.
Перелинковка — это «скелет» техблога: она помогает читателю быстро находить нужное и одновременно подсказывает поисковым системам, какие страницы важнее и как они связаны. В программных страницах это особенно удобно: многие ссылки можно генерировать по данным (теги, категории, авторы, темы).
Начните с простого набора страниц, между которыми всегда есть понятные переходы:
/blog/blog/tag/observability/docsВ статье добавляйте блок «Теги» со ссылками на соответствующие страницы, а на странице тега — список статей с краткими аннотациями и ссылками обратно на материалы.
Хорошая структура для роста — тематические кластеры: одна центральная обзорная статья (pillar page) и несколько дочерних материалов, раскрывающих частные вопросы. Внутри кластера:
Программно добавьте внизу статьи блок «Связанные материалы». Самый понятный алгоритм: пересечение тегов + свежесть публикации, с фильтром «не показывать текущую статью». Более продвинутый вариант — учитывать семантическую близость (например, по ключевым фразам или эмбеддингам), но важно сохранить предсказуемость: читатель должен понимать, почему ему это предлагают.
Текст ссылки должен объяснять, что откроется по клику: «гид по логированию» лучше, чем «observability». Избегайте одинаковых анкоров, ведущих на разные страницы, и не превращайте абзацы в набор ссылок. Для навигации внутри хронологии добавьте «Предыдущая/следующая статья» — это простой способ увеличивать глубину просмотра без навязчивости.
Программные страницы легко размножить, но любая «мелочь» в шаблоне будет повторяться тысячами раз — и бить по метрикам. Поэтому производительность лучше закладывать на уровне дизайн-системы и шаблонов, а не «допиливать потом».
Для контентных страниц техблога обычно важны три показателя:
Эти метрики напрямую зависят от шаблонов: обложка без заданных размеров ухудшит CLS на всех статьях, тяжёлая подсветка кода ухудшит INP везде.
Изображения часто становятся LCP-элементом. Договоритесь о правилах:
Подсветка синтаксиса легко превращается в мегабайты JS. Для техблога обычно лучше:
Если вы используете готовые HTML-код-блоки, важно сохранить структуру и прокрутку:
<pre><code class="language-js">// пример
const x = 1;
</code></pre>
Контентные страницы должны быть максимально «тонкими»: минимум интерактивных виджетов, никаких тяжёлых трекеров «в лоб», аккуратные сторонние скрипты.
Статику (HTML/CSS/шрифты/изображения) выгодно раздавать через CDN и настраивать долгие заголовки кеширования для неизменяемых ассетов. Это особенно заметно, когда у вас сотни и тысячи страниц.
Lighthouse полезен как быстрый чек шаблона, но он не заменяет реальные данные. После запуска смотрите полевые метрики (например, в веб-аналитике): какие страницы чаще всего проседают по LCP/INP/CLS и какой элемент становится проблемой. Затем правьте именно шаблон — так вы улучшите сразу весь массив программных страниц.
Программные страницы хорошо масштабируются только тогда, когда масштабируется и публикация. Если у вас десятки авторов и сотни материалов, «на глаз» быстро превращается в битые ссылки, пустые описания и хаос со slug.
Самый удобный маршрут для техблога — короткий и повторяемый: черновик → ревью → публикация → обновление.
Черновик пишется по шаблону (о нём ниже), на ревью статья проходит проверку у редактора и (по необходимости) у технического ревьюера. Публикация — это не ручное копирование, а мердж в основную ветку, после которого система сама собирает страницу.
Отдельно заложите этап «обновление»: для техтем это норма. Лучше заранее договориться, что статьи имеют «дату последнего обновления» и плановый пересмотр, например раз в 6–12 месяцев.
Часть качества проще обеспечить автоматикой, а не дисциплиной. Минимальный набор проверок перед публикацией:
Эти проверки можно запускать в CI на пулреквесте, чтобы автор видел проблему до мерджа.
Чтобы статьи выглядели как части одного продукта, дайте авторам простой гайд: структура (вступление, «что узнаете», шаги, вывод), правила терминов, стиль кода (форматирование, язык комментариев), примеры допустимых заголовков и ссылок. Ссылка на гайд может жить в репозитории, например /blog/editorial-guide.
Техматериалы устаревают: меняются API, интерфейсы, рекомендации. Определите политику:
Помимо программных страниц нужны опорные: /blog (каталог и фильтры), /about (кто вы и зачем этот блог), /contact (если есть поддержка/партнёрства). Они задают доверие и помогают навигации, даже если основной рост идёт через SEO.
Когда у техблога много программных страниц, «просто залить на хостинг» перестаёт работать: важны предсказуемые сборки, быстрые превью и понятный план изменений. Ниже — практичный набор договорённостей, который обычно спасает от ночных релизов.
Сведите деплой к повторяемому конвейеру: сборка → проверки → публикация.
Обычно в пайплайне достаточно:
Превью для PR/MR — ключ к спокойствию: можно заранее заметить, что шаблон «поехал», а новая партия страниц получила не те заголовки.
Разделяйте окружения минимум на:
Переменные окружения храните безопасно (в секретах CI), а не в репозитории. Важно договориться, какие значения различаются между stage/prod: ключи аналитики, базовые URL, доступ к источникам данных. Для статической генерации помните: часть переменных «запекается» в сборку — проверьте, что в клиент не утекают приватные токены.
Минимальный набор наблюдаемости:
URL в техблоге меняются: вы пересобираете структуру, объединяете категории, исправляете слаги. Заранее держите процесс:
/sitemap.xml и проверку, что canonical смотрят на новые адреса.Перед выкладкой пробегитесь по короткому списку:
rel=canonical на всех программных страницах;robots.txt (особенно для stage, чтобы не индексировался);/sitemap.xml) и отсутствие неожиданных noindex.Так деплой превращается в рутину, а поддержка — в плановую работу, даже если вы публикуете сотни страниц за раз.
Запуск программных страниц — это только начало. Дальше важно наладить измерения так, чтобы вы понимали не просто «сколько трафика пришло», а какие материалы реально помогают читателю и бизнесу.
Сразу договоритесь, какие действия считаются успехом, и заведите их как события и конверсии:
События должны быть сопоставимы между шаблонами: статья, категория, тег, программная подборка. Тогда вы сможете сравнивать страницы «на равных».
Если техблог — часть продуктовой воронки, один из CTA может вести на TakProsto.AI (например, «Собрать прототип проекта»): так вы честно связываете контент про разработку и programmatic-подход с инструментом, который ускоряет создание веб/серверных/мобильных приложений через чат.
Соберите набор регулярных отчетов (еженедельно/ежемесячно):
Смысл отчета — не графики ради графиков, а список решений: что улучшить в контенте, перелинковке или CTA.
Programmatic SEO хорошо растёт, когда темы подтверждены спросом. Берите идеи из:
Заранее заведите календарь обновлений: раз в квартал пересматривайте ключевые материалы, дополняйте примеры, обновляйте скриншоты, проверяйте внешние ссылки. Для программных страниц полезно отслеживать «устаревшие блоки» в данных (например, списки инструментов/версий) и обновлять их централизованно.
Просмотры легко растут, но не всегда означают ценность. Добавьте метрики качества:
Так вы превратите аналитику в понятный план улучшений, а не в бесконечный мониторинг чисел.
Программные страницы — это страницы, которые создаются по одному шаблону из данных (теги, авторы, серии, термины глоссария и т. п.).
Вы описываете:
Дальше сайт генерирует тысячи URL автоматически, без ручной верстки каждой страницы.
Минимальный практичный набор:
/blog/[slug];/blog;/blog/tag/[tag];/blog/topic/[topic] (или /blog/category/[category]);Серии и сравнения добавляйте позже, когда базовая навигация и публикация уже стабильно работают.
Зафиксируйте правила заранее и придерживайтесь их везде:
slug (не меняйте без необходимости);Это снижает риск дублей и упрощает перелинковку и аналитику.
Определите «главную» версию для каждого типа страницы и последовательно применяйте:
rel=canonical на чистые URL (особенно при utm и сортировках);noindex для служебных страниц (поиск, превью, черновики).Так вы защищаетесь от дублей и экономите бюджет сканирования.
Стандартизируйте поля и ограничения, чтобы контент не «ломал» генерацию:
Ориентируйтесь на частоту обновлений и требования к SEO:
Важно оценить не только «модно», но и стоимость поддержки и стабильность сборок.
Порог ценности помогает не плодить thin content. Типовые правила:
Если сущность нужна для UX, но пока слабая — показывайте её внутри навигации, а не отдельной индексируемой страницей.
Рабочая схема:
/blog/tag/observability — первая страница;/blog/tag/observability/page/2 — следующие.Практика:
Минимальный набор:
Смотрите на повторяющиеся проблемы шаблонов, потому что они масштабируются на тысячи страниц:
Проверяйте шаблоны в Lighthouse, а после релиза — полевые метрики из аналитики.
/blog/author/[author].title, description, slug, date, updated, tags, canonical;slug;title/description.Лучше ловить ошибки в CI до деплоя, чем чинить сотни страниц после.
/page/1;Каноникал и индексацию для пагинации задайте единообразно и придерживайтесь выбранного правила.
title, description, canonical;Article, BreadcrumbList (и FAQ только если блок FAQ реально есть);/sitemap.xml, /robots.txt, RSS/Atom для /blog.В sitemap включайте только канонические URL с кодом 200 — это ускоряет и упрощает индексирование.