Пошаговый план, как спроектировать и собрать веб‑приложение для фичефлагов: модели данных, UI, API, правила раскатки, аудит, безопасность и наблюдаемость.
Фичефлаг (feature flag) — это переключатель, который позволяет включать или выключать часть функциональности без повторного релиза приложения. Проще говоря, код новой фичи уже может быть в продакшене, но пользователи увидят её только тогда, когда вы «поднимете флаг».
Важно не путать фичефлаги с обычной конфигурацией. Конфигурация — это параметры работы уже существующей логики (например, «таймаут 5 секунд» или «цвет кнопки»). Фичефлаг же управляет тем, выполняется ли вообще ветка логики: показывать ли новый экран, запускать ли новый алгоритм, отправлять ли запрос в новый сервис.
Раскатка — это не просто «включить/выключить», а включать постепенно и по правилам. Это снижает риск: вы даёте новой функциональности маленькую аудиторию, смотрите на метрики и только потом расширяете охват.
Что это даёт на практике:
Самые частые правила включения выглядят так:
Если флаги «живут» в коде, в переменных окружения или в таблице базы данных без правил и аудита, команда быстро сталкивается с хаосом: непонятно, кто и когда что поменял, как безопасно трогать продакшен и почему у разных сервисов «разные версии правды».
Отдельный сервис фичефлагов решает это системно: даёт единое место управления, одинаковые правила раскатки для всех приложений, быстрый kill switch, историю изменений и понятный процесс для команды.
Прежде чем рисовать интерфейс и писать API, полезно договориться о границах системы фичефлагов: кто ею пользуется, какие операции обязательны, и какие «неочевидные» требования важнее всего. Это экономит недели, потому что фичефлаги почти сразу становятся критичной частью релизного процесса.
Минимальный набор ролей обычно выглядит так:
Под эти роли стоит сразу перечислить ключевые операции: создать флаг, включить/выключить, настроить правила/раскатку, посмотреть историю изменений. Даже в MVP важно, чтобы каждое действие было понятно, обратимо и оставляло след в аудите.
Фичефлаги читаются гораздо чаще, чем меняются — поэтому требования к runtime‑части обычно жёстче, чем к админке.
Зафиксируйте хотя бы приблизительно:
Эти оценки влияют на хранение, кэширование, формат доставки (пуш/пулл) и стоимость эксплуатации.
Для первой версии обычно достаточно:
Главное — чтобы MVP уже позволял безопасно управлять релизным риском: быстро выключить функцию, понять кто и когда менял настройки, и не зависеть от ручных правок конфигов.
Отдельная практичная опция для старта — собрать MVP на TakProsto.AI: админку на React, runtime‑сервис на Go и хранение правил в PostgreSQL можно быстро набросать в формате чата, а затем развернуть, подключить домен и при необходимости экспортировать исходники. Это удобно, если хотите быстро провалидировать UI/модель данных и перейти к промышленной реализации без «выбрасывания» прототипа.
Хорошая система фичефлагов держится на понятной модели данных: она должна быть достаточно гибкой для реальных раскаток, но не превращаться в «конфигурационный комбайн», который трудно поддерживать.
Обычно хватает трёх уровней:
new_checkout), описание, владелец/команда, ссылки на задачу.На практике удобно хранить значения и правила на уровне окружения, потому что раскатка почти всегда отличается между stage и prod.
Тип флага лучше фиксировать явно:
control, v1, v2) для A/B‑тестирования или постепенной замены алгоритма.Правило обычно описывается как «если… то…»:
Хорошая практика — отделить условия (предикаты по атрибутам) от результата (какое значение/вариант выдаём).
Процентная раскатка должна быть стабильной: один и тот же пользователь не должен «прыгать» между включено/выключено.
Для этого используют хэш от пары (flag_key + user_id) и сравнивают его с порогом процента. Тогда при 10% один и тот же набор пользователей будет попадать в эти 10% независимо от времени и количества запросов.
Чтобы изменения были управляемыми, добавьте жизненный цикл:
Плюс полезно хранить версию/ревизию правил (например, автоинкремент при каждом изменении). Это облегчает аудит, откаты и воспроизводимость: «какие правила действовали вчера в 14:00».
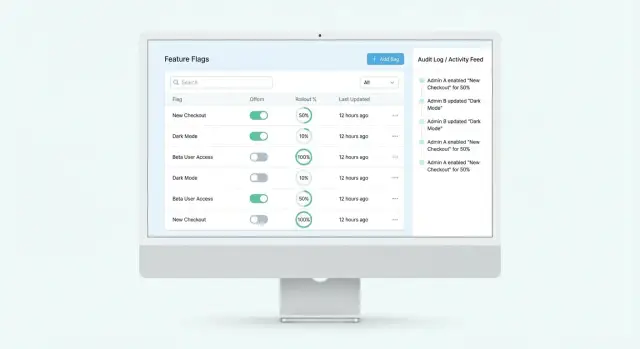
Хороший UI для фичефлагов — это не «красивый список переключателей», а рабочее место, где ошибки стоят дорого. Цель панели — помочь человеку быстро понять контекст, уверенно внести изменение и не сломать продакшен случайным кликом.
Начните с панели, где флаги легко просматриваются и фильтруются. Важно, чтобы список не превращался в свалку:
Полезная деталь: показывайте краткую сводку прямо в строке — текущие правила, процент раскатки, дату последнего изменения.
В карточке флага сделайте обязательными поля, которые предотвращают «безымянные переключатели»:
Добавьте историю изменений внизу карточки: кто менял, что именно и в каком окружении.
Правила таргетинга должны читаться как текст, а не как формула. Используйте «конструктор условий» с человеческими подписями и примерами значений.
Ключевая функция — предпросмотр «кто попадёт»: пользователь вводит пример идентификатора/атрибутов, а UI объясняет, почему правило сработало (или нет). Это резко снижает риск неверных условий.
Для опасных действий добавьте предохранители:
Сделайте отдельный экран активности: последние изменения, популярные флаги по обращениям, алерты (например, слишком частые правки или всплеск выключений). Такой дашборд помогает заметить проблемы раньше, чем их увидят пользователи.
В системе фичефлагов обычно живут два разных мира: админский (где люди настраивают правила) и runtime (где приложения быстро получают готовый ответ «включено/выключено/какой вариант»). Если смешать их в один сервис и один API, вы быстро упрётесь в проблемы с производительностью и безопасностью.
Admin‑контур делает много записей, требует валидаций и прав доступа. Runtime‑контур — это почти всегда чтение, высокая частота запросов, минимальная задержка и предсказуемая нагрузка.
Практичный вариант: одна база/хранилище правил + два сервиса (или два набора эндпоинтов) с разными политиками доступа и масштабирования.
Админское API обычно покрывает:
Важно: любые изменения в продакшене должны проходить через авторизацию, аудит и, по возможности, «двухэтапность» (черновик → публикация).
Runtime‑эндпоинт должен быть простым и быстрым, например:
GET /runtime/v1/flags?env=prod&app=myappОн возвращает готовый результат вычисления (или предвычисленные данные), а не «сырые» правила. Контекст запроса (например, userId, country) можно передавать заголовками или в теле — это зависит от выбранной модели вычисления и требований к кешированию.
Есть две стратегии:
Часто делают гибрид: streaming как «ускоритель», pull как запасной путь.
Базовый набор:
ETag + If-None-Match для ответа runtime (304 Not Modified вместо полного payload).Держите ответ компактным и стабильным:
schemaVersion и/или flagsVersion (монотонный номер/хеш), чтобы удобно сравнивать и отлаживать;Чем меньше «лишнего» вы отправляете в runtime, тем проще масштабировать систему и тем безопаснее она для продакшена.
Фичефлаг ценен не тем, что «включает/выключает», а тем, что умеет включаться для нужных пользователей и в нужный момент. Поэтому правила таргетинга и раскатки — сердце системы: здесь чаще всего появляются ошибки и «сюрпризы».
В рантайме вы почти всегда решаете один вопрос: попадает ли пользователь под правило? Для этого у сущности «контекст» (user/org/request) должны быть атрибуты, по которым можно фильтровать:
@company.ru) — удобно для пилотов с конкретными заказчиками;org_id;Практика: заранее зафиксируйте «словарь атрибутов» и их типы (строка/число/список). Так UI сможет валидировать правила, а SDK — корректно отправлять контекст.
Сегменты обычно бывают двух типов:
Хорошая панель управления показывает оценку размера сегмента (примерно сколько пользователей/организаций попадёт) и даёт предпросмотр: «проверить конкретного пользователя по ID».
Правила почти всегда пересекаются. Нужны понятные и стабильные приоритеты:
Дефолт должен быть очевиден в UI и API (например, off), иначе при удалении правила можно случайно «включить всем».
Процентная раскатка должна быть:
Обычно это делается через детерминированный хэш от (flag_key + stable_id) и сравнение с порогом. Важно выбрать стабильный идентификатор (user_id или org_id), иначе после миграций/логинов доля «поплывёт».
Kill switch — отдельный быстрый рубильник, который перекрывает все правила и принудительно возвращает безопасное значение (обычно off).
Ключевые требования: действие должно применяться за секунды, быть заметным в UI (яркий статус) и обязательно фиксироваться в аудите: кто, когда и почему отключил. Это ваш план «Б», когда метрики упали, а раскатывать фикс релизом некогда.
Фичефлаги влияют на поведение продакшена «на лету», поэтому безопасность здесь — не опция, а базовая функция продукта. Хорошая новость: большинство рисков закрываются простыми правилами и несколькими обязательными механизмами.
Для пользователей панели управления обычно достаточно SSO (SAML/OIDC) или логина по паролю с MFA. Главное — единый способ входа и централизованное отключение доступа при увольнении.
Для runtime‑сервисов и SDK нужны отдельные токены (API keys), которые:
RBAC стоит строить вокруг окружений и типов действий. Минимальный набор ролей:
Отдельно продумайте права на «опасные» операции: включение kill switch, изменение правил таргетинга, массовые правки.
Аудит должен отвечать на вопросы кто/что/когда и что именно изменилось:
Полезно уметь фильтровать события и быстро восстанавливать предыдущее значение (rollback) на основе истории.
Чтобы один клик не «уронил» релиз, добавьте:
Не храните секреты в значениях флагов: ни токены, ни пароли, ни ключи API. Фичефлаг — это про поведение, а не про секретное хранилище. Для чувствительных данных используйте отдельный vault/секрет‑менеджер, а во флагах держите лишь идентификаторы или переключатели.
Клиентские SDK — это «проводник» между вашим приложением и сервисом фичефлагов. От их качества зависит, будут ли флаги удобны разработчикам и безопасны для пользователей: SDK должен работать быстро, предсказуемо и не ломать приложение при сбоях.
Минимальный набор — простой API вроде isEnabled(flagKey, context) и getVariant(flagKey, context). Хорошая практика — возвращать детерминированный результат (boolean/variant) и опционально — причину (из кеша, по умолчанию, по правилу).
Критично иметь:
Для таргетинга и раскаток SDK должен уметь работать с несколькими идентификаторами:
userId — для авторизованных пользователей.anonymousId — для гостя (генерируется и хранится локально).deviceId — полезен на мобильных, но используйте осторожно.Важно: один и тот же пользователь не должен «прыгать» между вариантами. Поэтому при наличии userId именно он должен быть основным ключом для хеширования раскатки.
Контекст — это атрибуты, по которым вы делаете правила: версия приложения, платформа, страна, тариф, внутренний сотрудник/нет. Собирайте только то, что реально участвует в правилах, и заранее определите схему: какие поля допустимы, какие типы (строка/число/булево), какие ограничения.
Если runtime‑сервис недоступен, SDK должен:
Фичефлаги влияют на поведение продукта так же сильно, как и релизы. Поэтому для них нужна наблюдаемость: понимать, что именно включено, кому показывается, и не стало ли хуже после изменения.
Начните с базового набора метрик, которые собираются автоматически из runtime‑сервиса и SDK:
Метрики стоит срезать по окружению (dev/stage/prod), приложению/сервису, версии релиза и, при необходимости, по сегментам пользователей (в обезличенном виде).
Помимо метрик нужны события управления (audit events): включение/выключение, изменение правил таргетинга, изменение процента раскатки, публикация в prod, откат. В событии фиксируйте «кто/что/когда» и контекст: окружение, имя флага, предыдущие и новые значения.
{
"type": "flag.published",
"flagKey": "new_checkout",
"env": "prod",
"actor": "ivan.petrov",
"from": {"rollout": 10},
"to": {"rollout": 50},
"release": "2025.12.3",
"timestamp": "2025-12-26T10:15:00Z"
}
Логи помогают отвечать на вопрос «почему конкретному запросу показали именно так». Добавляйте в логи корреляционный id запроса, версию конфигурации и итог оценок ключевых флагов (без персональных данных). Если используете распределённую трассировку — прикрепляйте эти же атрибуты к спанам, чтобы связывать изменения флагов с деградациями.
Полезные правила оповещений:
Сразу продумайте экспорт метрик и событий в вашу систему аналитики: пакетная выгрузка (например, по расписанию) или потоковая доставка. Важно сохранить единые идентификаторы (flagKey, env, release), чтобы потом удобно строить отчёты: «какие флаги чаще всего меняют», «какие изменения приводили к инцидентам», «какие эксперименты завершены, но флаги не убраны».
Фичефлаги часто воспринимают как «конфиг», который можно менять без риска. На практике это продакшен‑код и продакшен‑данные: ошибка в правилах или деградация runtime‑сервиса способна остановить выпуск так же, как падение API. Поэтому тестирование и эксплуатацию нужно закладывать в дизайн системы с самого начала.
Самое хрупкое место — вычисление итогового значения флага. Для него стоит выделить отдельный модуль (policy engine) и покрыть юнит‑тестами:
Полезный приём — «табличные» тесты: набор входных атрибутов + ожидаемое решение. Так проще ловить регрессии при добавлении нового типа правил.
Runtime‑эндпоинт обычно самый горячий: его дергают все клиенты. Прогоняйте нагрузку на сценариях:
Отдельно проверьте поведение кешей: TTL, инвалидирование по версии конфигурации, защита от «thundering herd».
Флаги живут годами, поэтому миграции неизбежны. Правило: новые типы правил и поля добавляйте backward‑compatible.
Сервис флагов лучше деплоить по blue/green: две версии работают параллельно, трафик переключается постепенно.
Откат должен быть не только «кодовый», но и конфигурационный: храните версии конфигов и разрешите откат по номеру версии/времени (без ручного редактирования правил).
Если вы собираете сервис на TakProsto.AI, удобно использовать снапшоты и откат как для конфигураций, так и для приложения целиком: это дополняет kill switch на уровне флагов и ускоряет восстановление после неудачных изменений.
Бэкапы конфигураций делайте регулярно и автоматически. Проверьте восстановление на практике: как быстро поднять чистую инсталляцию и вернуть актуальные флаги, кто имеет право запускать процедуру, и как убедиться, что восстановлена именно нужная версия.
Если хотите, полезно закрепить эти процедуры в коротком runbook рядом с /blog/feature-flags-observability (или вашим разделом про наблюдаемость), чтобы дежурные не искали знания по чатам.
Технически фичефлаги можно сделать быстро. Но без правил они превращаются в «кладбище переключателей», где никто не помнит, что можно выключать, а что держит оплату. Поэтому рядом с кодом нужны простые процессы.
Договоритесь об одном формате и зафиксируйте его в гайдлайне в админке.
billing.*, ui.*, search.*, onboarding.* — по ним удобно фильтровать и назначать владельцев.enable_… для включения фичи, kill_… для аварийного отключения, exp_… для экспериментов.team-payments, q1-2026).У каждого флага должен быть статус и владелец.
В карточке флага сделайте поля обязательными: краткое описание, ожидаемый эффект (что изменится для пользователя/метрик), ссылка на задачу, дата ревизии/отключения. Это снижает риск случайно тронуть продакшен и облегчает передачу между командами.
Поставьте календарную ревизию (например, раз в две недели):
Разработка своего сервиса оправдана не всегда. Выбирайте готовый продукт, если важны: быстрый старт, поддержка, продвинутый аудит, готовые SDK, сегментация и эксперименты, соответствие требованиям безопасности.
Если же вы хотите собственный сервис (под свои процессы и требования), но без долгого разгона команды, удобно стартовать с TakProsto.AI: собрать рабочий прототип «админка + runtime + PostgreSQL», включить режим планирования, быстро пройти несколько итераций с владельцами продукта, а затем — при необходимости — перейти на тариф Pro/Business/Enterprise, подключить деплой/хостинг и выгрузить исходники. Дополнительно можно получать кредиты за контент про платформу или по реферальной программе — это помогает снизить стоимость экспериментов на ранней стадии.
Фичефлаг — это переключатель, который управляет тем, выполняется ли ветка логики. Код уже может быть в продакшене, но функция станет доступна только после включения флага.
Конфигурация обычно настраивает параметры уже работающей логики (таймауты, лимиты), а флаг решает: выполнять логику вообще или нет.
Раскатка (rollout) снижает риск за счёт постепенного включения:
Если что-то пошло не так, вы останавливаете эффект на небольшой доле пользователей.
Kill switch — это аварийный рубильник, который перекрывает все правила и принудительно возвращает безопасное значение (обычно off).
Практика:
Чтобы пользователь не «мигал» между вариантами, используйте детерминированное распределение:
user_id или org_id);(flag_key + stable_id);Так одни и те же пользователи будут попадать в те же 10% и завтра, и через неделю.
Минимальный MVP обычно включает:
boolean и multivariate;Главная цель MVP — безопасно снижать релизный риск и быстро откатывать изменения без деплоя.
Полезная базовая модель:
Разнос по окружениям защищает от случайного переноса тестовых правил в продакшен.
Два контура упрощают и безопасность, и производительность:
Практично: одно хранилище правил + отдельный runtime-эндпоинт, который отдаёт готовые вычисленные значения, а не «сырые» правила.
Чтобы флаги не тормозили приложение:
Не делайте получение флагов блокирующим для критичного пользовательского потока.
Минимально полезный RBAC:
Для prod добавьте предохранители: подтверждение опасных действий, обязательное поле «причина», опционально правило «четырёх глаз» (ревью второй ролью).
Начните с того, что помогает быстро находить проблемы:
Хорошее правило алерта: «после изменения флага выросли ошибки/латентность» и «резко увеличилась доля фолбэков из-за недоступности runtime».