Пошаговый план веб‑приложения для мониторинга нарушений SLA в реальном времени: метрики, вычисления, алерты, дашборды, эскалации и запуск в прод.
Чтобы мониторинг нарушений SLA приносил пользу, важно заранее договориться о терминах и о том, какие решения вы хотите принимать на основе данных. Иначе система превратится в «ещё один дашборд», которому никто не доверяет.
SLA (Service Level Agreement) — обещание, зафиксированное в договоре: какие показатели сервиса вы гарантируете клиенту и что будет, если не выполните (например, скидка или штраф). Это юридически и финансово значимый уровень.
SLO (Service Level Objective) — внутренняя цель команды, обычно строже SLA. Она нужна, чтобы успевать исправляться до того, как нарушится договор. Например: в SLA — 99,5% доступности, а SLO — 99,7%.
SLI (Service Level Indicator) — измеряемая метрика, по которой вы считаете выполнение SLO/SLA: процент успешных запросов, p95 времени ответа, доля обработанных задач в срок и т.д.
Нарушения стоит описывать как конкретные условия, которые можно проверить автоматически:
Мониторинг SLA должен приводить к действиям: алерты в нужный канал, эскалации по расписанию дежурств, отчёты за период, а иногда — расчёт компенсаций/штрафов и разбор инцидентов. Поэтому уже на старте полезно определить: кто реагирует, за какое время, и какие данные считаются «истиной».
SLA становится измеримым только когда его можно однозначно превратить в запрос к данным: что считаем, где берём события, за какой период и при каких условиях фиксируем нарушение. Ниже — минимальная структура, которая обычно спасает от разночтений между бизнесом, поддержкой и разработкой.
Начните со списка объектов, к которым SLA применяется. Это могут быть:
Важно: каждому пункту задайте уникальный идентификатор (service_id/process_id), чтобы метрики можно было группировать, фильтровать и сравнивать.
Зафиксируйте окна, в которых считается выполнение: 5 минут, 1 час, месяц — и что именно означает «месяц» (календарный или скользящий).
Отдельно опишите исключения: регламентные работы, праздничные дни, ночные окна, «заморозки» по согласованию. Лучше формализовать их как календарь (список интервалов времени с причиной), чтобы приложение могло автоматически исключать эти периоды из расчётов.
Сформулируйте правило так, чтобы оно читалось как проверка:
Добавьте определения спорных мест: что считать «ошибкой», как считать ретраи, что делать при частичной деградации.
SLA меняются — и это должно отражаться в данных. Храните версии с полями: sla_id, version, effective_from, effective_to (или признак актуальности), автор изменения и краткое описание.
Тогда отчёты за прошлые периоды будут пересчитываться корректно по действовавшим правилам, а детектор нарушений — применять актуальную версию с нужной даты.
Чтобы мониторинг нарушений SLA работал в реальном времени, сначала важно честно ответить на вопрос: откуда именно вы узнаёте, что услуга оказывается (или не оказывается) как обещано. На практике SLA «виден» сразу в нескольких системах, и почти всегда нужна комбинация источников.
Метрики (мониторинг инфраструктуры и приложений): время ответа, ошибки, доступность, длина очередей, насыщение ресурсов.
Логи (приложения, API‑шлюзы, балансировщики): фактические коды ответов, детальные причины ошибок, следы ретраев.
События тикетов/инцидентов (service desk): открытие/закрытие, категория, приоритет, время реакции и восстановления — полезно, если SLA завязан на процесс поддержки.
Бизнес‑данные из БД: статусы заказов, платежей, обработки заявок. Иногда именно они отражают качество сервиса лучше, чем инфраструктурные метрики.
Ключевая задача — связать техническое событие с конкретным клиентом и его условиями SLA. Рабочая схема выглядит так:
Лучше заранее описать «таблицу соответствий» (contract → сервисы → окружения → каналы данных) и поддерживать её как часть продукта.
Даже хорошие источники часто дают проблемы:
Сразу заложите правила: допустимое опоздание (lateness), дедупликацию по ключу события и обработку «неполных окон» расчёта, иначе алерты будут шуметь.
Если есть возможность повлиять на продуктовые команды, договоритесь о минимальном наборе идентификаторов в каждом событии:
tenant_id) для привязки к контракту.Без этого карта интеграций превращается в ручные склейки и исключения, а SLA — в спор, а не в измеряемую метрику.
Реальное время в мониторинге SLA — это не «каждую миллисекунду пересчитывать всё», а получать сигнал о риске нарушения достаточно быстро, чтобы успеть отреагировать. Для большинства сервисов это минуты или десятки секунд, и этого можно добиться без тяжёлой инфраструктуры.
Начните с простых, однозначных событий, которые можно собрать из ваших систем:
Важно заранее договориться о ключах корреляции: request_id/ticket_id, тип услуги, клиент/тариф, приоритет. Тогда приложение сможет связать start и finish, даже если они пришли из разных источников.
Потоковая обработка (streaming) даёт почти мгновенные статусы: событие пришло — метрика обновилась — риск нарушения пересчитан. Плюсы: быстрые алерты, актуальные дашборды. Минусы: сложнее отлаживать порядок событий и повторную доставку.
Периодические расчёты (batch/polling) проще: раз в N минут вы пересчитываете открытые таймеры. Плюсы: легче начать, меньше требований к очереди. Минусы: алерт может запаздывать на интервал.
На практике часто используют гибрид: поток для критичных сигналов + периодический «ремонтный» пересчёт для страховки.
Делайте обновления «по необходимости»: храните предрасчитанные статусы (например, OK / at_risk / breached), а не пересчитывайте всё на каждый запрос UI. Ограничивайте частоту пересчёта для длинных SLA (например, пересчитывать не чаще раза в минуту), используйте батчи для записи в хранилище и обязательно закладывайте идемпотентность (повторное событие не должно ломать состояние).
Чтобы мониторинг нарушений SLA работал быстро и предсказуемо, разделите данные на «справочники» (кто и что мониторим) и «измерения» (что происходило по времени). Это снижает стоимость хранения и упрощает запросы.
Обычно хорошо работает связка из двух типов баз:
Иногда добавляют объектное хранилище для архива «сырых» событий/логов и экспорта отчётов (дёшево хранить, удобно пересчитывать ретроспективно).
Разумный базовый набор сущностей:
Важно: breaches лучше хранить отдельно от «замеров». Нарушения — это бизнес‑события, к ним будут привязаны инциденты, комментарии и эскалации.
Под интерактивный дашборд нужны быстрые выборки по диапазону времени и сервису. Практика:
Сразу задайте правила:
Так вы контролируете стоимость и избегаете ситуации, когда отчёты нужны за год, а база раздулась до неприемлемых размеров.
Когда данные уже поступают, главная задача — посчитать метрики одинаково для всех команд и заранее определить, что именно считается нарушением. Иначе «SLA выполнен» в одном отчёте легко превратится в «SLA провален» в другом.
Для простых SLA по доступности удобно считать доли: сколько «успешных» событий было в окне времени относительно всех событий.
Важно заранее нормализовать, какие статусы относятся к «успешным», а какие — к «ошибкам» (например, таймауты, 5xx, бизнес‑ошибки).
Для SLA по времени ответа обычно используют квантили:
Детектор лучше делать по скользящему окну (например, 5–15 минут) и/или по окну отчёта (сутки/месяц). Тогда вы увидите и краткие всплески, и устойчивые проблемы.
Пример правила: «p95 > 800 мс 10 минут подряд» (устойчивое нарушение) или «p99 > 1500 мс в течение 3 из 5 последних минут» (пульсирующая деградация).
Если SLA завязан на обработку обращений/тикетов, определите таймер:
on hold, нерабочие часы.Здесь критично хранить историю статусов и уметь считать «эффективное время» по календарю рабочих часов.
Чтобы метрики были честными:
request_id.Детектор нарушений должен работать на чётких, документированных правилах — тогда алерты будут объяснимыми и пригодными для разборов.
Алертинг в SLA‑мониторинге — это не «сирена на каждый чих», а управляемый поток сигналов. Цель простая: нужный человек получает понятное сообщение вовремя и может быстро подтвердить/устранить проблему.
Практично разделять события как минимум на два уровня:
Чтобы предупреждения не превращались в спам, задайте им отдельные правила: ниже приоритет, более длинный cooldown, отправка только в рабочее время или только при подтверждённом росте метрики.
Шум чаще всего возникает из‑за повторов и «флаппинга» (метрика прыгает вокруг порога). Минимальный набор мер:
Каналы выбирайте по тому, где команда реально реагирует:
В каждом уведомлении держите «скелет»: что случилось, кого затронуло, когда началось, текущая величина метрики, ссылка на дашборд/инцидент.
Эскалация должна быть формальной:
Главный принцип: чем выше приоритет, тем меньше каналов и тем короче путь до человека, который может реально исправить причину, а не просто «поставить в очередь».
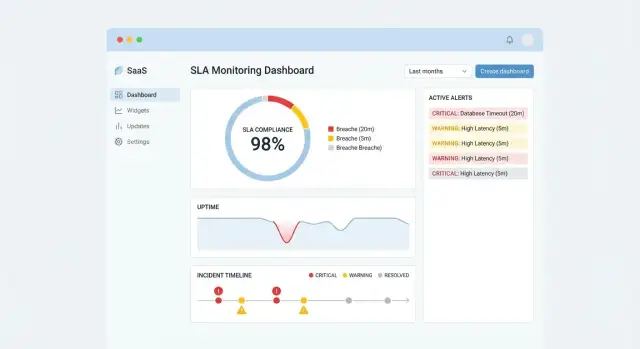
Пользователь открывает приложение не «посмотреть красивые графики», а быстро понять: где проблема, насколько она серьёзна и что делать дальше. Поэтому хороший UX для мониторинга SLA — это про приоритизацию и ясные ответы, а не про максимальное число виджетов.
1) Обзор по сервисам — стартовая страница «здоровья».
Покажите список сервисов (или клиентов) с понятным статусом: ОК / Риск / Нарушение. Рядом — ключевые числа за выбранный период: количество нарушений, суммарное время «вне SLA», текущие активные инциденты. Важно, чтобы клик по строке вёл в детализацию без потери контекста (сохраните фильтры).
2) Список нарушений — рабочая очередь.
Здесь людям нужна таблица: сортировка по серьёзности и времени, быстрый поиск, заметные статусы (активно/устранено/ложное срабатывание). Это экран, на котором чаще всего принимают решение об эскалации.
3) Карточка инцидента — одно место, где «всё про этот случай».
Соберите таймлайн: когда началось, какие метрики просели, какие уведомления ушли, кто назначен ответственным, какие шаги предприняты. Добавьте ссылки на связанные события и измерения, чтобы не прыгать по интерфейсу.
Базовый набор фильтров: клиент, период, сервис, серьёзность, статус. Сделайте их «липкими» (сохраняются при навигации) и добавьте пресеты: «последние 24 часа», «текущие активные», «высокая серьёзность». Это снижает количество кликов и ошибок.
График тренда нужен, чтобы увидеть ухудшение до нарушения. Распределения (например, по причинам/компонентам) помогают понять, где системная проблема. Таблица с сортировкой остаётся главным инструментом действий.
Не перегружайте: один график — одна мысль. Если метрик много, спрячьте их в переключатели (вкладки/чипы), а не в десяток линий на одном поле.
Операционным ролям важны быстрые выгрузки: CSV для анализа и PDF для отчётности.
Сделайте отдельные маршруты и понятную навигацию: /reports для регулярных отчётов и /alerts для просмотра правил и истории уведомлений. Экспорт должен уважать текущие фильтры и явно показывать период и область данных, чтобы отчёт не был двусмысленным.
Мониторинг SLA почти всегда затрагивает чувствительные данные: статусы инцидентов, внутренние правила эскалаций, иногда — контакты дежурных и переписку. Поэтому безопасность лучше проектировать сразу, а не «добавлять потом».
Начните с простых ролей и чётких границ доступа. Типичный набор:
На практике удобнее сочетать RBAC (роли) и точечные разрешения (например, «может изменять правила», «может подтверждать инциденты», «может видеть номера телефонов»).
Если продукт рассчитан на нескольких клиентов, заложите изоляцию на уровне данных:
Важно: в дашбордах и экспортах исключайте «утечки по агрегатам» — например, общий топ инцидентов без фильтра tenant_id.
Аудит нужен не только для безопасности, но и для разборов спорных ситуаций. Минимальный набор событий:
Храните: кто (user_id/роль), когда, что сделал, какой объект, и откуда (IP/клиент приложения). Логи аудита делайте неизменяемыми и доступными по отдельному праву.
Старайтесь собирать персональные данные по принципу необходимости: часто достаточно служебных идентификаторов и рабочих контактов, без лишних полей.
Технический минимум:
Если у вас есть раздел с интеграциями, полезно дополнить его страницей с политикой доступа и журналом изменений настроек: /settings/audit.
Приложение, которое фиксирует нарушения SLA в реальном времени, само должно быть наблюдаемым и устойчивым к сбоям. Иначе вы получите «мониторинг, которому нельзя верить»: алерт не пришёл — и непонятно, это инцидент у клиента или проблема у вас.
Договоритесь о базовом наборе сигналов и держите их на отдельном тех‑дашборде:
Важно добавить корреляцию: один trace_id/correlation_id должен проходить через приём события → расчёт → запись в хранилище → алерт.
Самая частая причина ложных нарушений — некорректные правила. Покройте их автоматикой:
Полезная практика — хранить такие наборы рядом с правилами и гонять их в CI при каждом изменении.
Проверьте сценарии «пик событий» и деградацию UI: как меняются задержки, не растёт ли очередь, и что увидит пользователь (пагинация, агрегации, кэширование). Отдельно тестируйте burst‑нагрузку, когда за короткое время прилетает много событий по одному объекту.
Устойчивость начинается с протоколов:
Минимальная цель: при сбое компонента вы теряете скорость обработки, но не теряете данные и не ломаете метрики.
Половина успеха SLA‑мониторинга — не в формулах, а в том, как приложение живёт после релиза: предсказуемо обновляется, быстро откатывается и не теряет данные при ошибках.
Минимальный набор сред — dev → stage → prod. Важно, чтобы конфиг не “зашивался” в код: адреса очередей, параметры окон расчёта, пороги алертов, ключи интеграций должны задаваться через переменные окружения или централизованный конфиг‑сервис.
Для базы данных сразу заведите миграции (например, «миграция как часть релиза»), чтобы схема менялась контролируемо. Правило простое: приложение стартует только после успешных миграций, а изменения делаются совместимыми (сначала добавили поля/таблицы, затем начали использовать).
В пайплайн CI/CD обычно входят:
Откат должен быть «одной кнопкой» и не ломать схему БД — поэтому не делайте разрушительных миграций без плана.
Контейнеризация упрощает воспроизводимость. Оркестрацию выбирает команда (часто это Kubernetes или более простой вариант). Главное — стандартизировать:
liveness/readiness) и автоперезапуск;Сделайте короткий runbook для поддержки: где смотреть статус очереди и воркеров, как включить «тихий режим» алертов, как проверить расчёт метрик, как восстановиться после падения. Полезно добавить внутренние ссылки вроде /status и /admin для быстрых проверок (с доступом по ролям).
Хорошая новость: систему мониторинга нарушений SLA можно запустить быстро, если не пытаться «сразу всё». MVP нужен, чтобы подтвердить ценность (видим нарушения вовремя, реагируем быстрее) и собрать реальные требования от поддержки, аккаунтинга и инженеров.
Сфокусируйтесь на минимальном наборе, который уже решает боль:
Важно: в MVP достаточно одного источника данных и одной команды пользователей. Это резко снижает сроки и риск «застрять» на интеграциях.
Если цель — быстро собрать прототип (UI + API + базовая БД) и показать его стейкхолдерам, удобно использовать TakProsto.AI: это vibe‑coding платформа, где веб‑приложения можно собрать из чата — с типичным стеком React на фронтенде и Go + PostgreSQL на бэкенде. Полезно и то, что есть режим планирования (planning mode), снапшоты и откат (rollback), а также экспорт исходников — можно начать быстро, а затем перенести решение в привычный контур разработки.
Сроки сильнее всего зависят от трёх зон:
Интеграции и данные: подключить 1–2 источника, договориться о формате событий/метрик, обработать пограничные случаи.
Хранение и расчёты: схема данных, агрегации, пересчёт за период, простая логика определения нарушения.
UI и операции: дашборд, фильтры, роли, минимальные логи, резервное копирование, окружения.
На практике MVP часто укладывается в 2–6 недель небольшой командой, если источники данных доступны и формулировки SLA уже согласованы.
Когда базовая цепочка «данные → метрика → нарушение → алерт» заработала, добавляйте ценность слоями:
Выбирайте не «самое модное», а то, что быстрее даст результат при ваших ограничениях:
Если прикидываете бюджет и варианты тарификации, зафиксируйте модель затрат и сверьте с ожиданиями бизнеса — это удобно оформить рядом с коммерческими условиями, например на странице /pricing.
Отдельно учитывайте требования к данным и размещению: для многих российских компаний важно, чтобы данные не уходили за пределы страны. TakProsto.AI в этом смысле удобен как платформа, ориентированная на российский рынок: инфраструктура и модели локализованы, а развёртывание и хостинг можно держать в контуре РФ (в зависимости от выбранного сценария и тарифа: free/pro/business/enterprise).
SLA — это договорное обещание клиенту с финансовыми последствиями (скидка/штраф).
SLO — внутренняя цель команды, обычно строже SLA, чтобы успевать исправляться.
SLI — измеряемая метрика, по которой считается выполнение (доступность, p95, доля ошибок, время обработки).
Опишите правило так, чтобы его можно было превратить в запрос к данным:
Минимум нужны:
service_id/process_id;customer_id/;Чаще всего используют комбинацию:
Выбирайте источник, который наиболее точно отражает качество для клиента, а не только состояние инфраструктуры.
Streaming полезен, когда важна скорость реакции: событие пришло → статус пересчитан → алерт отправлен почти сразу.
Batch/polling проще для старта: раз в N минут пересчитываете открытые таймеры и окна.
Частая практика — гибрид: поток для критичных сигналов + периодический «ремонтный» пересчёт, чтобы компенсировать задержки и пропуски данных.
Чтобы алерты не «шумели», заранее задайте:
Это особенно важно при очередях, ретраях доставки и батчевой загрузке.
Доступность удобно считать долями:
Если SLO 99,9%, то error budget на период — 0,1% ошибок. Практичный алерт — не только «бюджет исчерпан», но и «скорость расходования бюджета слишком высокая», чтобы успеть вмешаться.
Используйте квантили (p95/p99) и окна:
Для устойчивости добавьте условия вида «N минут подряд» или «3 из 5 последних минут», чтобы не реагировать на единичные всплески.
Минимальный набор против шума:
В уведомлении держите «скелет»: что сломалось, кого затронуло, когда началось, текущее значение и ссылка на нужный экран (например, /alerts или /reports).
Сделайте минимум:
tenant_id в данных и запросах;Отдельный журнал удобно вынести на /settings/audit с доступом по правам.
tenant_idrequest_id или ticket_id.Без этих полей любые отчёты и алерты превращаются в ручные «склейки» и споры, кому засчитывать нарушение.