План веб‑приложения, которое объединяет метрики работоспособности, логи и бизнес‑KPI: источники данных, дашборды, алерты, права доступа и запуск в прод.
Вы строите веб‑приложение, которое в одном месте показывает здоровье сервиса (техметрики, логи, инциденты) и бизнес KPI (выручка, конверсии, удержание, стоимость лидов). Смысл такого объединения — убрать разрыв между «система красная» и «что это значит для денег и пользователей».
Когда техметрики и бизнес KPI живут отдельно, команды спорят на уровне ощущений: поддержка видит всплеск ошибок, продукт — падение конверсии, финансы — недобор выручки, а связать причины и последствия быстро не получается. Единый дашборд KPI помогает увидеть цепочку: деградация → влияние на ключевой сценарий → финансовый эффект.
Такой продукт ускоряет:
Обычно пользователи системы — продуктовые менеджеры, поддержка, маркетинг, финансы и инженеры. Важно, чтобы каждый видел «свой» слой (сводка для бизнеса, детализация для инженеров), но работал с одной правдой в данных.
Успех измеряется не красотой графиков, а сокращением времени:
и итогом в деньгах: меньше потерь выручки и меньше повторяющихся инцидентов благодаря правильным приоритетам.
Мониторинг стоит начинать не с графиков, а с ясного ответа на вопрос: кто принимает решения по данным и какие решения должны стать быстрее. На этом этапе вы экономите недели разработки, потому что заранее фиксируете «что считаем успехом» и «что точно не делаем в MVP».
Соберите 3–5 ключевых сценариев, где мониторинг должен помогать найти причину и быстро выбрать действие. Формулируйте их как связку «сигнал → расследование → решение». Примеры:
Для каждого сценария договоритесь о том, что будет считаться «обнаружено» (какой сигнал) и что должно быть доступно «в два клика» (какие разрезы и фильтры).
Опишите роли и их действия:
Зафиксируйте права: просмотр, создание алертов, подтверждение инцидента, доступ к персональным данным, выгрузки.
Согласуйте определения и параметры: единицы измерения, частота обновления, допустимая задержка данных, часовой пояс, правила округления, «источник истины». Иначе разные команды будут спорить о цифрах вместо действий.
Запишите ограничения по бюджету и срокам, требования безопасности и соответствия, а также операционные условия: кто будет сопровождать систему, какой уровень отказоустойчивости нужен, можно ли хранить сырые события и сколько. Эти решения лучше зафиксировать до проектирования архитектуры (см. раздел /blog/architecture-monitoring).
Лучше начать не с «соберём всё», а с минимума, который отвечает на два вопроса: сервис работает? и бизнес получает результат? Ниже — стартовый комплект, который обычно даёт максимум пользы уже в MVP.
Собирайте базовые «золотые сигналы» по каждому ключевому пользовательскому пути (логин, поиск, оформление заказа, отправка заявки):
Сразу договоритесь о единицах измерения, окнах агрегации (1/5/15 минут) и разрезах (регион, платформа, версия).
Метрики показывают симптом, а логи и события помогают найти причину. Минимально полезно:
Выберите KPI по вашему продукту: выручка, конверсия, ARPU, удержание, CAC, количество лидов/заявок. Ключевое — не количество, а ясные определения.
Постройте простую причинно‑следственную схему: например, рост p95 задержки → падение конверсии на шаге оплаты → снижение выручки. Это подскажет, какие техметрики действительно критичны и где ставить алерты.
Для каждого KPI запишите:
Так вы избежите ситуации, когда один и тот же KPI «не сходится» в разных дашбордах и вызывает споры вместо решений.
Чтобы в одном веб‑приложении рядом жили «здоровье сервиса» и бизнес KPI, сначала перечислите источники данных и договоритесь, как они стыкуются. Иначе получится два параллельных мира: графики про CPU отдельно, конверсии и выручка — отдельно.
К техданным обычно относят APM/метрики приложения (время ответа, ошибки, throughput), логи (приложение, gateway, фоновые задачи) и мониторинг инфраструктуры (контейнеры/виртуалки, базы, очереди, сеть). Важно сразу продумать общие поля для корреляции:
Бизнес‑показатели чаще всего живут в базе продукта (заказы, статусы, возвраты), в системах продаж/платежей/аналитики и в витрине данных (таблицы, подготовленные для отчётов). Практика, которая экономит время: не тащить всё «как есть» в дашборд, а собрать витрину с KPI‑таблицами (например, daily_orders, funnel_steps, payments_success_rate), где уже решены вопросы валют, таймзон, статусов и дублей.
Чтобы бизнес KPI можно было связать с деградацией сервиса, из приложения стоит отправлять ключевые события с понятными именами и обязательными атрибутами: «заказ создан», «оплата успешна/неуспешна», «ошибка шага оформления», «пользователь прошёл шаг X». События должны содержать минимум контекста: user_id, session_id, order_id (если есть), tenant_id, а также error_code/step_name при ошибках.
Заранее зафиксируйте, какие идентификаторы считаются «истиной» (user_id vs email/телефон, order_id vs payment_id), и как они пробрасываются через фронтенд, бэкенд, очереди и логи. Добавьте правила качества данных: дедупликация событий, допустимые задержки (late arrivals), обработка пропусков, версионирование схем (v1/v2) и мониторинг нарушений — тогда связка тех‑ и бизнес‑метрик будет устойчивой, а не случайной.
Чтобы мониторинг «здоровья сервиса» и бизнес KPI не разъехались по разным системам, архитектуру лучше сразу разделить на понятные слои: сбор → обработка → хранение → выдача в интерфейс. Тогда проще масштабировать, менять источники и добавлять новые метрики без переделки всего приложения.
На этом уровне важно обеспечить стабильную доставку и единый формат идентификаторов (пользователь, сессия, заказ, устройство).
Сырые события обычно шумные и разнородные. Нужны:
Метрики удобнее хранить во временных рядах, логи — в хранилище логов, а бизнес KPI и разрезы — в аналитической базе (для быстрых фильтров, сегментов, когорт).
Фронтенду проще жить с единым API‑слоем: один набор эндпоинтов для графиков, таблиц и списка алертов, с общей моделью фильтров (период, сегмент, сервис, версия).
По задержкам разумно разделить потоки: near‑real‑time для алертов и инцидентов, а для отчётных KPI — периодическое обновление (например, каждые 15–60 минут или раз в день), чтобы не усложнять систему без заметной пользы.
Хороший дашборд — это структура экранов и понятные действия, а не набор виджетов. Если пользователь каждый раз «ищет цифру», интерфейс не выполняет свою работу.
Практичный минимум — 4–5 разделов:
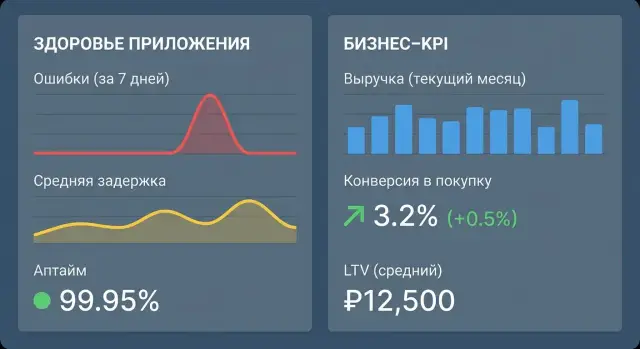
Сделайте один «пульт управления», где помещаются 6–12 ключевых карточек. Ограничение полезно: оно заставляет выбрать главное. Хорошая структура — две строки: сверху здоровье (SLO, ошибки, latency), ниже бизнес (ключевой KPI и 2–3 ведущих индикатора).
Правила простые: единые цвета статусов, подписи без лишних аббревиатур, сравнение с базой (вчера/неделя), и рядом — короткий текст «что это значит».
Дайте одинаковые фильтры на всех экранах: период, сегмент пользователей, регион, версия приложения, канал. Важно показывать, какие фильтры активны, и позволять быстро сбросить их одним кликом.
Клик по просадке KPI должен вести по цепочке: KPI → шаг воронки → конкретный сервис/эндпоинт → ошибка или задержка. Пользователь не обязан гадать, где искать первопричину.
Добавьте: постоянные ссылки на дашборды, CSV‑выгрузку и сохранённые представления (например, «RU, iOS, версия 3.2»). Это превращает дашборд в рабочий инструмент, а не в «витрину».
Алерт — это не просто «что-то пошло не так», а приглашение к конкретному действию. Хорошая система делает две вещи: быстро поднимает нужных людей и не превращается в бесконечный шум.
По SLO — самые ценные для качества сервиса: рост ошибок, увеличение задержки, падение доступности. Они напрямую отвечают на вопрос «пользователи страдают?».
По порогам бизнес‑KPI — например, конверсия, выручка, количество оплат. Важно выбирать пороги, которые отражают реальный риск, а не естественные колебания.
По аномалиям KPI — когда метрика «ведёт себя странно», но заранее трудно задать точный порог (например, резкая смена структуры трафика, необычное падение среднего чека).
Частая проблема: одна ошибка вызывает цепочку симптомов (выросла задержка, потом ошибки, потом падает конверсия), и вы получаете 20 уведомлений.
Нужны правила:
Отправляйте алерты туда, где команда действительно реагирует: почта, корпоративный мессенджер, система тикетов. Разделите каналы по важности: критичное — сразу дежурному, менее срочное — в тикеты.
Добавьте «тишину»: окна обслуживания, релизные периоды, плановые работы. Поддержите расписания дежурств и приоритизацию (P1/P2/P3), чтобы ночью не будить из‑за косметических отклонений.
Сообщение должно экономить время на уточняющих вопросах:
Что: рост 5xx на /checkout
Где: prod, region=EU
Когда: с 12:41, длится 8 мин
Влияние: конверсия -12% (оценка), затронуто ~3% запросов
Первые шаги: проверить деплой 12:35, логи платежного шлюза, нагрузку БД
Ссылка: дашборд + последние ошибки
Так алерт превращается в управляемый инцидент: понятно, кто реагирует, что проверять и как оценить эффект на бизнес KPI.
Мониторинг здоровья сервиса и бизнес KPI почти всегда затрагивает чувствительные данные: финансовые показатели, поведение пользователей, иногда — персональные данные. Поэтому безопасность стоит проектировать сразу, а не «докручивать» после запуска.
Сделайте разграничение доступа не только к страницам, но и к самим данным и полям:
Практично сочетать RBAC (роли) и ABAC (атрибуты: команда, проект, клиент, среда). В интерфейсе это выражается как «один дашборд — разные представления», чтобы каждый видел ровно то, что нужно.
Базовый минимум:
Обязателен аудит действий: кто менял пороги, формулы KPI, доступы, настройки алертов и интеграции. Это помогает разбирать спорные ситуации и снижает риск ошибок.
Если приложение рассчитано на несколько клиентов/команд, заложите мультиарендность: изоляция данных по tenant’ам (фильтрация на уровне запросов, отдельные пространства/схемы, разные ключи шифрования — по требованиям).
Ориентируйтесь на внутренние политики и применимые регуляторные нормы: сроки хранения, правила доступа, процесс согласования изменений. Важно не обещать «полное соответствие стандартам» без подтверждённой проверки — лучше описывать конкретные меры и процессы, которые вы внедрили.
MVP для мониторинга — это минимальный сквозной путь: сбор → отображение → сигнал → действие. На старте достаточно 1–2 техметрик + 1–2 бизнес‑KPI + один дашборд + один канал алертов.
Если задача — быстро проверить гипотезу по UX и связности метрик, удобно собрать рабочий прототип в формате vibe‑coding. Например, в TakProsto.AI можно через чат описать экраны (обзор, инциденты, drill‑down), модель фильтров и источники данных — платформа соберёт каркас веб‑приложения (обычно на React) и API‑слой, а затем вы сможете выгрузить исходники и доработать под свои интеграции.
Начните с контракта данных: схема событий, названия метрик, единицы измерения и частота отправки. Зафиксируйте:
Это снижает споры «почему график не совпадает» и ускоряет дальнейшие изменения.
Соберите один основной дашборд: здоровье сервиса (например, ошибки/латентность) рядом с 1–2 KPI (например, конверсия/выручка). Параллельно сделайте прототип UI и проведите 10–15‑минутные сессии с 5–7 пользователями: что они ищут первым, что считают «красным», какие решения принимают.
Настройте один канал алертов (почта/мессенджер) и простое правило: кто реагирует и за сколько.
Следующий прирост ценности — корреляция: показывайте на одном экране, что инцидент по техметрикам совпал с просадкой KPI (и наоборот). Дальше работайте итерациями: каждую неделю демо, короткий список критериев приёмки и одно улучшение, которое уменьшает шум и ускоряет реакцию.
На этом этапе особенно полезны «безопасные изменения» и быстрый откат. Если вы собираете приложение в TakProsto.AI, обратите внимание на снимки и rollback: они помогают экспериментировать с формулами KPI и логикой алертов без страха «сломать всем».
Система мониторинга ценна ровно настолько, насколько ей доверяют. Поэтому тестируйте не только интерфейс, но и сами данные: корректность расчётов, устойчивость пайплайна и работу алертов.
Начните с «контрольных примеров»: небольшой тестовый набор событий и ожидаемые значения KPI (выручка за день, конверсия, SLA/SLO и т. п.). Прогоняйте расчёты автоматически при каждом изменении формул или источников.
Полезно держать «источник истины» — эталонную выгрузку из бухгалтерии/CRM/бэкенда и регулярно сверять агрегаты (с допусками на задержки). Отдельно проверяйте граничные случаи: пустые периоды, отмены, возвраты, дубли, смена часового пояса.
Смоделируйте пики: всплеск событий (например, распродажа), резкий рост логов при ошибках и «плохие» внешние источники (медленные ответы, частичные данные, таймауты). Смотрите, как ведут себя очереди, время обновления дашбордов и задержка данных (data latency).
Заложите повторную доставку и идемпотентность: одно и то же событие может приехать дважды — результат не должен «раздуваться». Тестируйте обработку задержек и поздних событий: KPI должны корректно пересчитываться, а не «застывать».
Мониторинг должен мониторить сам себя: метрики сборщиков, глубина очередей, процент ошибок API, время обработки, доля отброшенных/невалидных событий.
Проверяйте сценарии ложных срабатываний и «тишины» (когда алерт не пришёл). Делайте тестовые инциденты: срабатывание → подтверждение → действия → восстановление. Важно измерять время до обнаружения и до восстановления, а также качество сигналов (сколько алертов реально требуют реакции).
Первые версии системы мониторинга часто ломаются не из‑за кода, а из‑за отсутствия дисциплины в запуске и поддержке. Поэтому эксплуатацию стоит продумать сразу: где живут конфиги, как выпускать изменения, как долго хранить данные и как обучать команды.
Разведите как минимум три среды: dev для быстрых экспериментов, stage для проверки «как в проде», prod для пользователей. Для каждой среды зафиксируйте набор конфигов (эндпоинты, частоты сборов, лимиты) и правила хранения секретов.
Секреты (ключи API, токены, пароли) не должны попадать в репозиторий и логи. Удобно иметь единый механизм выдачи секретов по ролям и автоматическую ротацию. Миграции схем (для БД, событий, справочников KPI) выпускайте как отдельный шаг релиза: с проверкой совместимости и планом отката.
Составьте календарь релизов: когда добавляются новые метрики/события, когда меняются формулы KPI, когда обновляются дашборды. Новые метрики включайте «безопасно»: сначала собирайте в фоне, потом показывайте на дашбордах, затем подключайте алерты.
Обязателен сценарий отката: вернуться на предыдущую версию схемы, выключить проблемный сбор, убрать метрику из расчёта KPI. Практика «мягкого запуска» (по пользователям/командам) снижает риск, что ошибка затронет всех.
Определите сроки хранения по типам данных: сырые события — меньше, агрегаты по минутам/часам — дольше, итоговые KPI — максимально долго. Пропишите правила агрегаций и удаления, чтобы стоимость хранения не росла незаметно.
Сделайте короткую документацию для команд: как добавить новую метрику/KPI, какие поля обязательны, примеры названий, как проверить корректность, как настроить алерт. Полезны шаблоны запросов и чек‑лист перед релизом.
Внутри приложения добавьте подсказки у сложных полей и экранов, а также глоссарий терминов (SLA/SLO, конверсия, активные пользователи и т. п.), чтобы одинаково понимать цифры. Ссылки на глоссарий удобно держать рядом с графиками и фильтрами, например в /help/glossary.
Главная развилка — собрать всё самим или собрать продукт из готовых компонентов. Оба пути рабочие, но по-разному влияют на сроки и стоимость владения.
Если делать всё с нуля, вы платите временем команды: проектирование, поддержка, обновления, безопасность, документация. Зато получаете максимальную подгонку под свои процессы и UX.
Если использовать готовые компоненты (хранилища, визуализация, алертинг, коннекторы), вы быстрее выпускаете MVP и снижаете риски по надёжности, но появляется зависимость от ограничений продукта и лицензии.
Практичный компромисс: свой веб‑интерфейс и бизнес‑логика, а сбор/хранение/поиск — на проверенных компонентах.
Если важны быстрый старт, предсказуемая эксплуатация и работа с данными внутри России, дополнительно оцените платформенный подход: TakProsto.AI, например, ориентирован на российский рынок, умеет ускорять разработку через чат (vibe‑coding), поддерживает экспорт исходников и развёртывание, а данные и вычисления остаются на серверах в России.
Закладывайте расширение с первого дня: плагины/коннекторы (под новые источники данных), вебхуки (на алерты и изменения статусов), «тонкий» SDK для отправки событий. Важно иметь версионирование схем и контрактов, чтобы интеграции не ломались от релизов.
Сравнивайте по чек‑листу:
Составьте матрицу «требования → категории инструментов» и оцените бюджет владения на 12–18 месяцев. Если хотите прикинуть варианты и стоимость, начните с /pricing, а для примеров компоновки решений загляните в /blog.
Даже хорошо продуманная система мониторинга быстро теряет ценность, если в ней невозможно договориться о цифрах, сложно найти главное или непонятно, кто и что должен делать при проблеме. Ниже — частые ошибки и практичные способы их предотвратить.
Когда продажи в отчёте BI не совпадают с цифрами в продуктовой аналитике, доверие к системе падает.
Выход: заранее зафиксируйте определения метрик (что считается «активным пользователем», когда заказ «успешный», как считаются возвраты), версионируйте формулы и храните их в одном месте (короткий словарь метрик). Полезная привычка — на дашборде рядом с графиком иметь ссылку на описание расчёта.
Сотни виджетов выглядят солидно, но мешают принимать решения.
Выход: начните с минимального набора: доступность/ошибки, задержки, нагрузка, ключевой бизнес‑KPI и один‑два ведущих индикатора (например, рост ошибок оплаты до падения выручки). Остальные графики прячьте в детализацию (drill‑down), а главный экран держите компактным.
Если уведомления приходят постоянно, их перестают читать.
Выход: каждый алерт должен отвечать на три вопроса: что сломалось, как проверить, что делать дальше. Настройте уровни (инфо/предупреждение/критично), добавьте дедупликацию и задержку срабатывания, чтобы не ловить краткие всплески. И главное — назначьте владельца сигнала и время реакции (простая таблица ответственности часто эффективнее сложных правил).
Частая проблема — «временный» лог с email/телефоном, который остаётся навсегда.
Выход: маскирование полей по умолчанию, запрет на вывод чувствительных данных, разные уровни доступа для ролей и регулярные проверки логов/событий на утечки.
Мониторинг полезен только тогда, когда влияет на поведение команды.
Выход: для ключевых метрик заранее определите пороги, сценарии действий и бизнес‑решения (например: при падении конверсии — проверка воронки, откат релиза, включение резервного провайдера). После инцидентов проводите короткий разбор: какой сигнал сработал, что было лишним, что нужно добавить.
Потому что так быстрее видна цепочка «деградация → пострадавший сценарий → влияние на деньги и пользователей». В одном месте вы сравниваете технические сигналы (ошибки, задержки, доступность) и бизнес‑KPI (выручка, конверсия, удержание) и быстрее принимаете решения: что чинить, кого подключать и как оценить ущерб.
Выберите 3–5 «болезненных» историй в формате «сигнал → расследование → решение». Для каждой зафиксируйте:
Это защищает от ситуации, когда дашборд красивый, но не ускоряет реальные решения.
Начните с «золотых сигналов» по ключевым пользовательским путям (логин, поиск, оплата, отправка заявки):
Сразу договоритесь об окнах агрегации (1/5/15 минут) и обязательных разрезах (регион, платформа, версия).
Берите 1–2 «итоговых» KPI и 1–2 ведущих индикатора, которые объясняют падение результата. Примеры:
Главное — не количество, а точные определения: формула, что включаем/исключаем (возвраты, отмены, тестовые транзакции), и какая система является «источником истины».
Сделайте «единый язык метрик» и закрепите его письменно:
Практика: рядом с графиком держать ссылку на описание расчёта в глоссарии (например, в /help/glossary), чтобы меньше спорить о цифрах и быстрее действовать.
Нужно заранее продумать поля корреляции, которые проходят через фронтенд, бэкенд, очереди и логи:
Параллельно введите политику качества данных: дедупликация, обработка поздних событий (late arrivals), версионирование схем событий (v1/v2).
Удобная схема — слои «сбор → обработка → хранение → API»:
Так проще масштабироваться и добавлять новые метрики без переделки всего приложения.
Сделайте один «пульт управления» на 6–12 виджетов и несколько экранов для детализации:
Обязательные UX‑мелочи: одинаковые фильтры на всех экранах, видимость активных фильтров, быстрый сброс, сравнение с базой (вчера/неделя) и короткое пояснение «что это значит».
Снижайте шум и превращайте сигнал в действие:
Уведомление должно сразу отвечать на вопросы: что случилось, где, когда, как влияет на KPI, какие первые шаги и ссылка на дашборд/ошибки.
В MVP достаточно сквозного пути «сбор → показ → сигнал → действие»:
Ограничивайте объём: лучше меньше метрик, но доработанные определения, права доступа и полезные drill‑down переходы.