План создания веб‑приложения для прогнозирования запасов и планирования спроса: данные, модели, интерфейс, интеграции, тестирование и запуск.
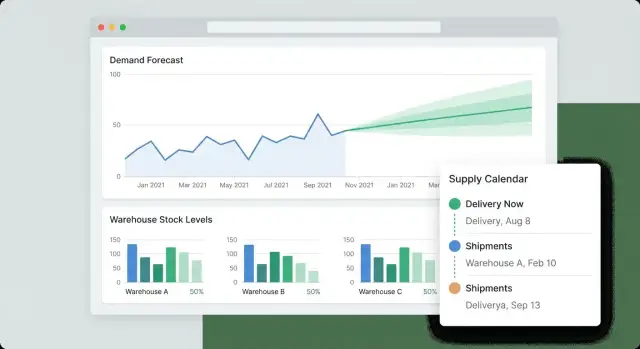
Прежде чем выбирать методы прогнозирования и проектировать интерфейсы, важно договориться, какую бизнес‑проблему решает система и кто будет ею пользоваться. Один и тот же прогноз может быть «хорошим» для планировщика и бесполезным для склада, если он не превращается в понятный план действий.
Чаще всего в проекте участвуют четыре основные группы пользователей:
Сразу определите, чьи решения система должна поддерживать в первую очередь: это влияет на сценарии, KPI, требования к объяснимости и набор данных.
Минимальный «набор ценности» обычно включает:
Прогноз спроса по связке SKU/склад/канал.
Целевой уровень сервиса (например, 95–98%) и контроль риска дефицита.
План пополнения: что заказать, на какой склад, к какой дате — и почему именно так. Объяснимость повышает доверие и снижает число ручных правок.
Зафиксируйте, как часто пересчитывается план (день/неделя/месяц) и на сколько вперёд он нужен (часто 4–26 недель). Чем короче цикл пересчёта, тем важнее автоматизация алертов, быстрые исключения и удобные сценарии «проверить и подтвердить».
Опишите, чем вы будете измерять успех:
И обязательно перечислите ограничения: минимальные партии, кратность поставок, lead time, графики поставщиков, лимиты склада, а также бюджет. Эти правила должны быть не «пожеланиями», а входом в расчёт пополнения — иначе приложение будет выдавать красивый прогноз без применимого плана.
Для прогноза спроса и планирования пополнения важнее всего не «сложная модель», а стабильный поток корректных данных. На старте стоит составить инвентаризацию источников и договориться, кто за них отвечает.
Минимальный набор обычно выглядит так:
Практичный стандарт для forecasting — SKU‑склад‑день. Даже если отчётность нужна «по категории и по неделям», храните первичную детализацию и задайте правила агрегации: как суммировать продажи, как пересчитывать цены, что делать с нулевыми днями, как учитывать возвраты.
Иногда прогноз заметно улучшают погода (температура/осадки), локальные события и сезонные индексы. Важно заранее проверить юридическую возможность использования, качество покрытия по регионам и стабильность источника.
Согласуйте владельцев данных (продажи, склад, закупки, промо) и правила доступа: кто может видеть себестоимость, поставщиков, маржинальность. Это лучше оформить до интеграций, чтобы не «переоткрывать» доступы на ходу.
Заранее определите политику: пропущенные дни (нет выгрузки vs нулевые продажи), смены SKU/переупаковка, объединение дублей, новые товары (cold start), закрытые склады. Эти решения напрямую влияют на качество прогноза и на то, насколько ему будут доверять пользователи.
Хорошая модель данных — основа прогноза и планирования пополнения. Если сущности и факты описаны однозначно, приложение сможет объяснять расчёты, сравнивать версии данных и корректно собирать историю для разных складов и каналов.
В ядре обычно лежат справочники, которые меняются редко, но влияют на все расчёты:
Важно сразу определить, где хранится «истина»: например, карточка SKU из ERP, параметры сроков годности — из PIM, а статусы точки продаж — из WMS/кассы.
Факты — это то, что формирует спрос и движение запасов во времени:
Для прогнозирования удобно приводить всё к «зерну» день × SKU × локация и хранить источники как отдельные поля/метки.
Отдельными сущностями/атрибутами держите:
Реальность меняется: упаковка, замены SKU, закрытые точки. Храните связи «старый SKU → новый SKU», даты действия атрибутов и статусы локаций. Критично договориться о едином ключе сопоставления между системами (например, sku_id, location_id) и правилах матчинга (приоритет источников, обработка дублей, маппинг единиц измерения).
Качество прогноза запасов почти всегда упирается в качество входных данных. Даже сильная модель будет «плавать», если в истории продаж есть дубликаты, пропуски или продажи записаны в неправильный день. Поэтому подготовку данных стоит оформить как повторяемый процесс: единые правила, автоматические проверки и понятные отчёты о том, что было исправлено.
Начните с контролей, которые ловят самые частые проблемы:
Чтобы модель не путала промо‑всплеск с «обычным ростом спроса», периоды акций лучше отражать отдельными признаками: флаг промо, глубина скидки, тип механики, наличие витрины/выкладки. Цена и промо должны храниться в разрезе даты и магазина/склада, иначе признаки окажутся «смазанными».
Ключевая ошибка — считать нулевые продажи нулевым спросом. Если товара не было, это потерянные продажи, и их нужно отделять от истинного снижения спроса. Практика: строить индикатор доступности (остаток > 0, статус поставки, блокировки) и исключать периоды отсутствия из обучения или корректировать целевую метрику.
Одинаковая модель для всех SKU редко оптимальна. Сделайте сегментацию: ABC (вклад в оборот/маржу) и XYZ (стабильность спроса). Для X‑товаров можно использовать более «агрессивное» сглаживание и короткие окна, для Z — осторожнее и с большим упором на наличие и события.
Оформите загрузку как конвейер: ежедневное расписание, инкрементальная загрузка (только новые/изменённые записи), контрольные суммы и идемпотентность. Обязательно ведите логирование: сколько строк пришло, сколько отбраковано, какие проверки не прошли. Это упрощает поиск источника ошибок и ускоряет поддержку.
Для следующего шага удобно связать результаты контроля качества с настройками интеграций в разделе /blog/api-i-integracii-s-uchetnymi-sistemami.
Выбор метода — это не «самый умный алгоритм», а компромисс между точностью, скоростью расчёта и тем, насколько просто объяснить и поддерживать результат в эксплуатации. Надёжная стратегия — начать с понятных базовых моделей, а усложнять только там, где это даёт измеримую выгоду.
Для многих SKU с ровным спросом достаточно скользящего среднего или экспоненциального сглаживания без сезонности. Сезонная наивная модель (например, «как в тот же день/неделю год назад») часто оказывается сильным бейзлайном: она дешёвая, быстрая и сразу показывает, есть ли выраженная сезонность.
ETS и ARIMA полезны, когда у ряда чёткая структура: тренд, сезонность, автокорреляции. Эти модели хорошо интерпретируются и подходят для стабильных рядов с достаточной историей.
«Prophet‑подобные» подходы удобны, когда нужно быстро собрать модель с трендом и несколькими сезонностями (недельная/годовая) и при этом легко добавлять календарные эффекты (праздники, распродажи). Это часто хороший баланс для массового прогноза.
Градиентный бустинг (CatBoost/LightGBM‑класс) хорошо работает, когда важны внешние признаки: календарь, промо, цена, наличие, поставщики. Ключ — правильно сформировать лаги и агрегаты (продажи 7/14/28 дней назад, скользящие суммы, доля дней без продаж).
Если прогноз нужен и по SKU, и по категориям, и по общему спросу, полезно строить иерархию (товар → категория → итог) и согласовывать уровни, чтобы суммы «сходились». Это повышает доверие к отчётам и упрощает планирование.
Смотрите на: точность (и её стабильность по группам товаров), скорость пересчёта, интерпретируемость для бизнеса, простоту поддержки (данные, фичи, мониторинг) и стоимость ошибок. Практично держать 2–3 модели в наборе и выбирать лучшую по сегментам SKU, а не пытаться одним методом закрыть всё.
Когда прогнозирование запасов уже настроено, следующий шаг — превратить прогноз в понятные действия: сколько и когда пополнять. В веб‑приложении для склада это обычно реализуется как набор правил и расчётов, которые одинаково применяются к каждому «SKU‑склад».
Базовые показатели:
Практичная схема:
Планирование спроса должно учитывать реальность: lead time, минимальные партии, кратность упаковки, ограничения поставщика, бюджет и складские лимиты. Поэтому «идеальный» расчёт превращается в «выполнимую» рекомендацию: округление до кратности, объединение заказов, приоритизация дефицитных позиций.
Выход системы управления пополнением — конкретная строка на каждый SKU‑склад:
Полезный блок — сценарии: рост спроса, задержка поставки, изменение цены/промо. Для доверия важны прозрачные объяснения: какие факторы (сезонность, тренд, акции, частота продаж) сильнее всего повлияли на прогноз и почему рекомендация изменилась. Это особенно ценно для forecasting для ритейла и при спорных позициях с низкой оборачиваемостью.
Хорошая архитектура для прогноза запасов начинается с простого принципа: разделяйте «тяжёлые» расчёты и пользовательский интерфейс. Тогда приложение остаётся быстрым для пользователей, а прогнозы можно пересчитывать столько, сколько нужно бизнесу.
Отдельно стоит отметить практический аспект: собрать рабочий прототип (дашборды, роли, интеграции, расчёт рекомендаций) часто важнее, чем сразу «идеальная» платформа. В этом смысле полезны решения класса vibe‑coding — например, TakProsto.AI, где можно описать систему в виде требований в чате и быстро получить каркас веб‑приложения (фронтенд на React, бэкенд на Go, база PostgreSQL), а затем итеративно уточнять бизнес‑правила пополнения, экраны и интеграции. Для проектов в РФ дополнительно важны локальная инфраструктура и хранение данных в стране — TakProsto.AI работает на серверах в России и использует локализованные и opensource‑модели.
Обычно систему удобно разложить на четыре слоя:
Есть два режима, и на практике часто нужны оба:
Пакетный режим проще контролировать по SLA, событийный — быстрее реагирует на изменения, но требует аккуратной очереди задач.
Частый выбор: реляционная база для справочников (товары, склады, поставщики, параметры) и витрина фактов (продажи, остатки, поставки) для быстрых выборок по длинной истории. Это снижает нагрузку на транзакционную часть и ускоряет отчёты.
Запланируйте очереди для: импортов, расчётов прогнозов, генерации рекомендаций, отправки уведомлений и построения отчётов. Так интерфейс не «подвисает», а задачи можно ретраить и мониторить.
Нагрузка растёт от числа SKU × складов × горизонта прогноза × длины истории. Заранее определите SLA (например, «прогнозы обновляются до 06:00» и «дашборд открывается < 2 сек») и решите, что кэшировать: агрегаты по дням/неделям, последние прогнозы, статусы алертов.
Интеграции — это «кровеносная система» приложения для прогноза запасов: без регулярного притока качественных данных прогноз быстро теряет смысл. Обычно вам нужно подключиться минимум к трём источникам: ERP (заказы, поставки, закупочные цены/сроки), WMS (остатки, движения, инвентаризации) и POS/CRM (продажи, возвраты, промо‑активности).
ERP чаще всего отвечает за плановую часть: созданные и ожидаемые поставки, статусы заказов, поставщиков и условия поставки. WMS — за фактическую: что реально лежит на складе и как товар двигался. POS/CRM даёт «истину спроса»: продажи по дням/часам, отмены, возвраты, иногда — сегменты клиентов.
Оптимальный вариант — REST API с инкрементальной выгрузкой (по updated_at или номеру события). Если API нет или он ограничен, используйте файлы по расписанию (SFTP/облачное хранилище) с чётким форматом и схемой. Вебхуки полезны, когда система умеет пушить события (например, «поступление подтверждено»), но их всё равно стоит дополнять регулярной сверкой.
Главная причина ошибок — несовпадение справочников. Заранее договоритесь о:
Заложите повторную загрузку (retry) и идемпотентность: один и тот же пакет данных не должен «удваивать» продажи или движения. Используйте дедупликацию по ключам события (например, operation_id) и контроль версий данных/схем (schema version), чтобы изменение полей не ломало пайплайн.
Оформляйте API‑контракты в OpenAPI/Swagger и фиксируйте примеры запросов/ответов, коды ошибок и SLA по обновлению данных. Для интеграций полезен отдельный тестовый стенд: песочница с синтетическими товарами и «искусственными» продажами, где можно безопасно проверять маппинг, дедупликацию и крайние случаи перед запуском в прод.
Хороший интерфейс для планирования спроса — это не «красивые графики», а быстрые ответы на вопросы: где мы рискуем потерять продажи из‑за out‑of‑stock, где замораживаем деньги в излишках, и что конкретно нужно сделать сегодня.
Базовый набор экранов обычно включает несколько ключевых витрин:
Важно, чтобы клик по любому показателю вёл в детализацию: конкретные SKU, партии/поставки, историю продаж и рассчитанные рекомендации.
Пользователям нужна единая панель фильтров, которая работает везде: период, склад, категория, поставщик, статус товара (новинка, сезонный, выводится, блокирован к закупке). В детализации полезно показывать «контекст»: минимальные партии, кратность заказа, срок годности/оборачиваемость, ограничения по хранению.
Алерт должен отвечать на три вопроса: что случилось, почему это важно, что сделать. Например: «Через 5 дней ожидается out‑of‑stock по SKU X на складе Y — предложить пополнение 120 шт. с учётом lead time 7 дней». Из алерта должна создаваться задача с дедлайном и исполнителем: закупки, склад, категорийный менеджер.
Даже при наличии API пользователи часто требуют выгрузки. Поддержите CSV/XLSX и «пакетные» отчёты: список рекомендаций на закупку, план перемещений между складами, перечень проблемных позиций для инвентаризации.
Разделите роли: кто может просматривать, кто — подтверждать рекомендации, и кто — формировать заказ. Практика: рекомендации можно менять (количество/дата), но система сохраняет причину корректировки и связывает её с задачей — это помогает разбирать ошибки и улучшать правила планирования (см. /blog/testing-forecast-accuracy).
Система прогноза запасов быстро становится «точкой истины» для закупок и пополнения. Поэтому важно заранее заложить безопасность: кто что видит, кто что может менять, и как потом объяснить, почему заказ был сформирован именно так.
Начните с простой модели ролей и усложняйте по мере роста процессов. Практичный минимум:
Лучше сразу поддержать разграничение по объектам: склад, юрлицо, бренд, категория, регион. Это снимает часть рисков и упрощает соответствие внутренним регламентам.
Базовые меры обычно закрывают 80% рисков:
Если есть чувствительные поля (телефоны, адреса, персональные данные), добавьте маскирование в интерфейсе и в выгрузках по ролям.
Аудит должен отвечать на вопросы «кто, что, когда и откуда сделал». Логируйте:
Хорошая практика — хранить «до/после» и request‑id, чтобы связать действие пользователя с конкретным расчётом и экспортом.
Заранее определите сроки и объёмы:
Чёткие политики хранения помогают и безопасности, и стоимости: меньше лишних данных — меньше рисков утечек и проще расследования.
Точность прогноза — не абстрактная цифра, а ответ на вопрос: «насколько безопасно по нему заказывать и перераспределять товар». Поэтому тестирование лучше строить так, чтобы оно повторяло реальный процесс планирования: прогнозируем «завтра», имея данные только «до сегодня».
Для временных рядов важна хронология: данные делят на train/validation/test по датам, а не случайно.
Если в признаках случайно окажется информация из будущего (например, фактические поставки, сформированные уже после даты прогноза), результаты будут «слишком хорошими» и быстро разочаруют на запуске.
Обычно достаточно двух уровней контроля:
Всегда сравнивайте с простыми базовыми моделями: «как в прошлом периоде», скользящее среднее, сезонный наивный прогноз. Если «умная» модель выигрывает слабо или нестабильно, лучше сначала улучшить данные и логику признаков.
Перед масштабированием делайте пилот на части ассортимента: выберите типичные категории и разные профили спроса. Заранее зафиксируйте критерии успеха (например, WAPE ниже бенчмарка на X%, рост попаданий в коридор на Y п.п.) и план расширения по волнам.
Финальная проверка — не только метрики, а результат:
Так вы доказываете, что прогноз улучшает решения по пополнению, а не просто «красиво считается».
Запуск системы прогноза и пополнения — это не «включили и забыли». Важно заранее спланировать релиз, договориться о регламентах и настроить наблюдаемость: что именно вы отслеживаете, кто реагирует и в какие сроки.
Начните с пилота на одном складе или небольшой группе SKU (например, 200–500 позиций) и 1–2 сценариях: прогноз спроса и рекомендации заказа. Цель — проверить данные, интеграции и то, как пользователи принимают решения.
Далее переходите к ограниченному запуску: добавляйте категории, увеличивайте горизонт планирования, подключайте больше пользователей, но сохраняйте возможность быстро откатиться.
Полный запуск делайте только после того, как измеримо снизились ошибки (out‑of‑stock/overstock) и сформированы правила работы: когда допустима ручная корректировка, а когда нужна дисциплина процесса.
Наблюдаемость стоит разделить на три слоя:
На практике полезны алерты по порогам (например, «данные не обновлялись 6 часов») и регулярный отчёт по качеству прогноза.
Частота зависит от динамики спроса. Обычно прогноз пересчитывают ежедневно/еженедельно, а переобучение делают раз в 2–4 недели или по триггерам: дрейф данных, смена ассортимента, длительное падение точности. Параметры пополнения (страховой запас, lead time) имеет смысл пересматривать отдельно — по фактической статистике поставок.
Фиксируйте причины ручных корректировок прямо в интерфейсе (списком причин + комментарий). Это помогает отличить «ошибку модели» от «неучтённого события» (разовая закупка, витринный запас, изменение выкладки). Такие метки — источник задач для улучшения признаков, правил и качества данных.
Следующий шаг после стабилизации:
Если вы хотите ускорить реализацию этих этапов, полезно заложить в процесс быстрые итерации: «описали сценарий → получили рабочий экран → проверили на пилоте → улучшили правила». В TakProsto.AI это удобно делать за счёт чат‑подхода, планировочного режима (planning mode), снапшотов и отката (rollback), а также экспорта исходного кода и развёртывания — когда прототип уже доказал ценность и его нужно перевести в стабильную эксплуатацию.
Начните с фиксации сценария решения и «первичного пользователя»:
От этого зависят KPI, гранулярность данных и то, как выглядят рекомендации.
Практичный минимум — три результата:
Если есть прогноз, но нет «выполнимой» рекомендации с ограничениями, пользователи не смогут применять результат.
Базовый набор источников:
Важно сразу назначить владельцев данных и договориться о частоте обновления.
Рабочий стандарт для forecasting — день × SKU × локация. Даже если отчётность нужна по неделям и категориям, храните первичную детализацию и задайте правила агрегации:
Это снижает число «споров о данных» при разборе ошибок.
Ключевая практика — отделять нулевые продажи от нулевого наличия:
Иначе модель научится «любить дефицит» и систематически занижать спрос.
Стартуйте с простых бейзлайнов и усложняйте только там, где виден эффект:
Практично держать 2–3 метода и выбирать по сегментам (ABC/XYZ), а не «одну модель на всё».
Используйте связку «сервис → страховой запас → точка заказа»:
Далее применяйте ограничения (MOQ, кратность, график поставок, лимиты склада/бюджета), чтобы рекомендация была исполнимой.
Разделяйте тяжёлые расчёты и интерфейс:
Обычно нужен и пакетный пересчёт по расписанию, и точечные обновления по событиям (поставка, изменение цены, обновление остатков).
Главные принципы надёжности:
updated_at/событиям);operation_id и т. п.);Отдельно заранее согласуйте маппинг справочников: , , единицы измерения, типы остатков (available/reserved/in-transit).
Для временных рядов тестируйте «как в жизни»:
Полезные практики контроля — в связанной теме: /blog/testing-forecast-accuracy.
sku_idlocation_id