Пошаговый план: как определить тиры аккаунтов, метрики внедрения, собрать события, построить витрины данных и дашборды, настроить алерты и права доступа.
Система трекинга внедрения нужна не «ради отчётов», а чтобы поддерживать конкретные решения команд: где и как вмешиваться, чтобы аккаунты быстрее получали ценность от продукта.
Customer Success — кого вести в онбординг «вручную», где нужен дополнительный тренинг, какие аккаунты попали в зону риска и по какой причине (не дошли до ключевого шага, перестали возвращаться, используют только базовые функции).
Продажи и аккаунт‑менеджмент — какие аккаунты готовы к апсейлу (используют продвинутые функции, растёт охват пользователей), а какие не стоит расширять, пока не пройдены базовые этапы активации.
Продукт — на каких шагах воронки внедрения больше всего потерь, какие функции «не открываются» пользователям, какие изменения в интерфейсе или коммуникациях дают измеримый прирост активации.
Где проседает внедрение: на первом входе, в настройке, в приглашениях команды, в использовании ключевых функций, в повторных сессиях.
Почему: нет нужных ролей у пользователей, не настроены интеграции, слишком длинный путь до первой ценности, функции не найдены или непонятны.
У кого: в каких сегментах и тирах проблема выражена сильнее.
Сразу зафиксируйте, кого вы считаете аккаунтом: компанию/организацию, рабочее пространство, проект или договор. Важно, чтобы один аккаунт имел устойчивый идентификатор и понятные границы (кто входит, какие события относятся к нему).
Тир — это класс аккаунта, который определяет ожидания по внедрению и глубину сопровождения (например: Enterprise / Mid‑market / SMB или A/B/C по потенциальной выручке). Тир не про «важность», а про разные модели поведения и разные целевые метрики.
Успех системы — это измеримые изменения: рост активации (доля аккаунтов, прошедших ключевые шаги), увеличение глубины использования (охват функций и пользователей), сокращение времени до первой ценности и снижение риска churn за счёт ранних сигналов и своевременных действий.
Тир аккаунта — простая, но очень «дорогая» в аналитическом смысле классификация: она определяет, с чем вы сравниваете внедрение, какие ожидания по активации нормальны и где нужен человеческий контакт.
Начните с 3–4 сегментов, которые понятны бизнесу и командам и при этом действительно отличаются по поведению:
Важно, чтобы определение тира было однозначным: любой сотрудник должен одинаково отнести аккаунт к сегменту.
Зафиксируйте правила в виде короткой спецификации (1 страница) и применяйте их автоматически, где возможно. Типовые критерии:
Если критериев несколько, заранее задайте приоритет (например, Enterprise определяется по ARR даже при небольшом числе мест).
Выбор зависит от того, кто управляет данными:
Главное — один «master» и понятный процесс обновления.
Не перезаписывайте тир «поверх». Храните историю (SCD Type 2):
account_idtiervalid_fromvalid_to (или признак текущей записи)change_reason, source_systemТак вы сможете корректно строить когорты и отвечать на вопросы вроде «как внедрение менялось до и после апгрейда в Enterprise», не ломая отчёты задним числом.
Метрики внедрения должны отвечать на один вопрос: «насколько аккаунт получает ценность от продукта — и насколько стабильно». При этом по тирам важно не только сравнивать «всех со всеми», а оценивать успех относительно ожиданий сегмента: для Enterprise и SMB пороги «нормы» почти всегда будут разными.
Определите одно проверяемое событие, которое лучше всего коррелирует с долгосрочным использованием: например, «первый отчёт создан», «первый проект запущен», «первый пользователь приглашён и выполнил действие».
Считайте:
Для каждой ключевой функции фиксируйте два измерения:
В разных тирах набор «ключевых функций» может отличаться: у крупных аккаунтов чаще важны администрирование и контроль, у небольших — быстрые сценарии.
Глубина показывает, насколько продукт «встроен» в процессы:
Отслеживайте:
Сделайте два уровня бенчмарков:
Правильная модель данных для трекинга внедрения начинается не с дашборда, а с договорённостей: что считать событием, какие сущности существуют и как однозначно идентифицировать аккаунт (особенно когда есть CRM и биллинг). Чем раньше вы закрепите эти правила, тем меньше «магии» и ручных правок будет в отчётности.
Событие — это атомарный факт действия в продукте, который можно агрегировать в метрики adoption. Важно вести единый словарь событий: стабильные названия, одинаковая структура свойств и понятные правила версионирования.
Практика: используйте имена в формате object_action (например, workspace_created, integration_connected, report_shared) и фиксируйте:
event_name — каноническое имя из словаряoccurred_at — время события в UTCuser_id и account_id — кто и в каком аккаунте совершил действиеproperties — контекст (план, роль, источник, тип интеграции и т. п.)Для трекинга по тиру центральная сущность — аккаунт. Пользователь почти всегда вложен в аккаунт, а рабочее пространство может быть как 1:1 с аккаунтом, так и 1:N — это нужно определить явно.
Минимальный набор связей:
account (тир, индустрия, регион, владелец в CRM)user (роль, статус, дата регистрации)workspace (настройки, созданные объекты)subscription (план, период, MRR/ARR, статус)ID должны быть стабильными и неизменяемыми. Не используйте email или домен как первичный ключ.
Рекомендуемая схема:
account_id/user_id (UUID).crm_account_id, billing_customer_id.Сразу задайте «контракт события»: какие поля обязательны, какие допускаются опционально. Минимально обязательные: event_name, occurred_at (UTC), account_id, user_id (если применимо), event_id.
Для качества:
event_id (или хэшу ключевых полей) на приёме данных.account_id против справочника аккаунтов, чтобы не появлялись «потерянные» события.Такая модель позволит уверенно строить метрики внедрения по тиру и сравнивать сегменты без бесконечных уточнений «а что мы имели в виду под активацией».
Чтобы трекинг внедрения по тиру работал, важно заранее договориться, откуда берутся данные и как именно событие попадает в аналитику. Ошибка на этом этапе приводит к «пустым» дашбордам и бесконечным уточнениям, почему цифры не сходятся.
Обычно хватает 3–4 источников, которые дополняют друг друга:
Начните с небольшого ядра — его достаточно, чтобы увидеть первые различия между тирами:
login_succeeded или session_started.Главное правило: событие должно иметь понятное бизнес‑значение и одинаково трактоваться командой продукта, аналитики и поддержки.
Есть три типовых пути:
Практика: критичные события (активация, ключевые действия) дублируйте на сервере, даже если отправляете их из клиента.
Приоритизируйте события по ценности:
Удобная эвристика: если событие не влияет на решение (что улучшать, кого обучать, где ставить алерт), его можно отложить на следующий спринт.
Хорошая архитектура для трекинга внедрения по тиру — это предсказуемый «конвейер», где можно понять, откуда взялась каждая цифра и что сломалось, если отчёт внезапно «поехал».
Обычно он выглядит так: сбор событий → очередь/хранилище → обработка → витрины → UI.
События (активация, использование ключевых функций, админские действия) попадают из продукта в приёмник: SDK, API-эндпоинт или трекер. Дальше их лучше складывать в буфер (очередь или лог), чтобы переживать пики и не терять данные. Затем обработка нормализует события, связывает их с аккаунтом и его тиром, рассчитывает агрегаты и публикует результат в витрины, из которых читает веб‑приложение.
Если вы хотите быстро собрать внутреннее веб‑приложение под такой трекинг (UI, API, базовые витрины, роли), это удобно делать на TakProsto.AI: через чат можно набросать React‑интерфейс, бэкенд на Go и схему PostgreSQL, а затем итеративно уточнять словарь событий и экраны без долгого «разгона» разработки.
Практика: справочники держать в реляционном, события — в колоночном, а витрины сделать «тонкими» и заточенными под конкретные дашборды.
Выберите подход:
Загрузки делайте инкрементальными (по времени события/ID пачки). Добавьте контроль: дедупликацию, мониторинг задержки (lag), таблицу «плохих» событий (dead-letter), алерты на рост ошибок парсинга.
События почти неизбежно меняются. Заложите совместимость:
schema_version в событии;Так вы сможете обновлять продукт и отчёты независимо, не ломая исторические данные и метрики по тиру.
События сами по себе редко удобны для продуктовой аналитики: их много, они «шумные», а вопросы бизнеса звучат иначе — «какие аккаунты Tier B застряли на онбординге?» или «какая функция драйвит удержание в Tier A?». Поэтому поверх сырого слоя стоит заранее подготовить несколько витрин (data marts) с понятной гранулярностью и едиными правилами подсчёта.
Базовая витрина для большинства отчётов: одна строка на account_id × дата (или неделя).
В неё обычно кладут:
is_active_day/week, число сессий/событий;active_users и active_seats (если есть лицензии);tier, индустрия, регион, план, стадия онбординга.Важно зафиксировать единые окна времени (например, неделя начинается в понедельник), правила дедупликации и обработку «поздних» событий (late arrivals), чтобы метрики в дашбордах не «прыгали» без причины.
Отдельная витрина под анализ использования функциональности: account_id × feature_id × период. Она помогает сравнивать adoption функций по тирам и быстро находить «фичи‑барьеры».
Практично хранить и абсолютные значения (сколько раз использовали), и бинарные флаги (использовали/нет), чтобы не путать интенсивность и факт внедрения.
Две полезные проекции:
Так вы сможете сравнивать скорость прохождения этапов между тирами и измерять «провалы» на конкретных шагах.
Чтобы тиры сравнивались честно, добавьте метрики «на пользователя/на место»: например, действий на активного пользователя, активность на 1 лицензию, доля активных мест. Это снижает эффект «большие аккаунты всегда больше кликают» и делает выводы по внедрению заметно точнее.
Дальше эти витрины становятся источником для дашбордов и алертов (см. /blog/alerts-by-adoption), а не сырые события.
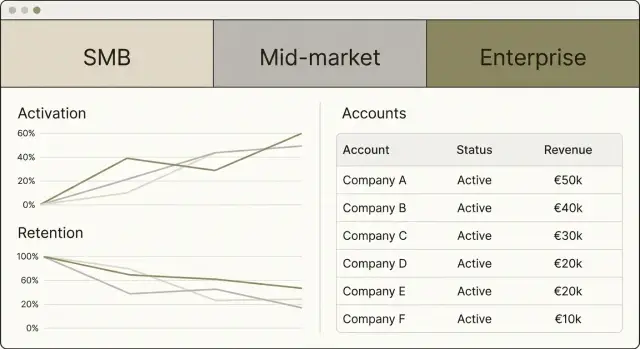
Хороший дашборд по внедрению — это не «всё и сразу», а короткий путь от вопроса к действию: где просадка, у кого риск, что именно нужно сделать дальше. Поэтому интерфейс стоит строить вокруг двух экранов: обзор (для руководителей и CSM) и карточка аккаунта (для работы «вглубь»).
На первом экране покажите картину по каждому тиру: доля активных аккаунтов, динамика за период и вклад тиров в общий результат. Важно дать и уровни, и тенденции: например, «Активные аккаунты (7 дней)» + график изменения + распределение по тирам.
Чтобы пользователь быстро понимал, где проблема, добавьте компактные блоки:
Карточка должна отвечать на три вопроса:
Сделайте «прогресс внедрения» в виде понятных шагов (чек‑лист или этапы), привязанных к ключевым событиям. Ниже — лента последних действий с датами и контекстом (например, какие функции использовались). Отдельный блок «Риски» лучше выводить простыми причинами: «нет ключевого события 14 дней», «падение активных пользователей на 30%».
Фильтры должны быть единообразными на всех страницах: тир, период, план, отрасль, регион, CSM. Важно сохранять выбранные фильтры между экранами, чтобы путь «обзор → аккаунт → назад» не сбрасывал контекст.
У каждой метрики добавьте короткую подсказку: определение, окно расчёта и примечание про исключения (например, тестовые пользователи). Это снижает споры и ускоряет принятие решений. Если нужно больше деталей — ссылка на внутреннюю страницу с методологией, например /docs/adoption-metrics.
Алерты в системе трекинга внедрения нужны не для «шума», а чтобы вовремя подсветить риск оттока или срыва внедрения — и сразу подсказать, что делать дальше. Поэтому важно заранее связать каждый алерт с сегментом (тиром) и конкретным сценарием реагирования.
Базовый набор пороговых алертов обычно строится вокруг двух вещей: активности и ключевых действий.
Чтобы алерты не срабатывали на сезонность, используйте сравнение с собственным базовым уровнем аккаунта (rolling baseline), а не только фиксированные числа.
Отдельный класс — алерты по онбордингу. Они отвечают на вопрос: аккаунт зарегистрировался, но не дошёл до ценности.
Пример: «Аккаунт не достиг aha‑события в течение 7 дней после приглашения первого пользователя». Aha‑событие стоит определить явно и хранить как правило (например, комбинация 2–3 событий), чтобы его можно было обновлять без переработки логики.
Одинаковые пороги для Enterprise и SMB почти всегда дают неверные приоритеты.
Доставляйте алерты туда, где команда реально реагирует: почта, Slack/Teams, веб‑уведомления внутри приложения. Полезно добавлять кнопку «Создать задачу» и ссылку на карточку аккаунта (например, /accounts/{account_id}) с контекстом: что упало, с какого дня, какие пользователи затронуты и рекомендованный следующий шаг.
Система трекинга внедрения почти всегда пересекается с коммерчески чувствительными данными (выручка, тариф, активность) и иногда — с персональными данными пользователей. Поэтому безопасность нужно проектировать сразу, иначе отчёты будут «жить в серой зоне» и их перестанут использовать.
Начните с простой матрицы ролей и ограничений:
Технически это удобно реализовать как row-level security на витринах/таблицах и как фильтры в API. В UI явно показывайте, почему данные скрыты (например: «нет доступа к финансовым метрикам»), чтобы не создавать ощущение ошибки.
Правило по умолчанию: не хранить то, без чего можно обойтись. Для трекинга adoption обычно достаточно:
Если PII всё же нужны (например, для коммуникаций), разделяйте хранилища: в аналитике — токены/ключи, в отдельном сервисе — расшифровка по строгим правам. Обязательно задайте сроки хранения и автоматическое удаление (retention).
Если для вас критично, чтобы данные и инфраструктура находились в России и не уходили за контур, учитывайте это на уровне выбора платформы и развёртывания. TakProsto.AI, например, ориентирован на российский рынок и использует локальную инфраструктуру, что упрощает согласования по данным для внутренних систем аналитики.
Ведите неизменяемый аудит: кто и когда менял тир аккаунта, правила сегментации, пороги алертов, права доступа, а также кто экспортировал данные. Это снижает риски и ускоряет разбор инцидентов.
До пилота согласуйте: модель данных и состав полей, схему доступов, сроки хранения, процедуры удаления, требования к шифрованию (в транзите/на диске), процесс реагирования на инциденты. Удобно оформить это как короткий чек‑лист в /docs/security.
Запуск системы трекинга внедрения лучше делать как продуктовый релиз: с ясным «минимально полезным» объёмом, проверкой качества данных и планом расширения. Это снижает риск построить красивый дашборд, которому никто не доверяет.
Начните с пилота на 1–2 командах (например, CSM + PM) и узком наборе тиров и метрик. Хорошая стартовая рамка:
Цель пилота — не «покрыть всё», а доказать, что метрики объясняют реальность и помогают принимать решения.
Если пилот делаете «внутренним продуктом», полезно заложить быстрый цикл итераций: планирование → изменения → проверка → откат. В TakProsto.AI для этого есть planning mode и снапшоты с rollback — удобно, когда вы часто уточняете формулы, пороги алертов и UX карточки аккаунта.
Проверка точности должна быть формальной. Сверьте результаты с:
Отдельно зафиксируйте «известные расхождения» (например, задержка событий, неполный трекинг в мобильном клиенте) — это убирает споры в стиле «данные не те».
Сделайте одностраничный гайд: что измеряем, как читать графики, какие действия ожидаются. Добавьте шаблоны интерпретации: «если активация просела в SMB — проверьте X; если удержание падает в Enterprise — проверьте Y».
После 2–4 недель пилота зафиксируйте бэклог расширения: новые функции, сегменты, источники данных. Вводите изменения итеративно: добавили источник → провалидировали → обновили документацию → обучили пользователей. Так система растёт без потери доверия и управляемости.
Система трекинга внедрения ценна только тогда, когда по её данным регулярно принимаются решения. Поэтому отчётность и цикл улучшений стоит продумать заранее: кто читает отчёты, как часто, какие вопросы должен закрывать каждый формат, и что считается «действием по итогам».
Оптимальный базовый ритм — еженедельно. Такой отчёт должен быть коротким и сравнимым от недели к неделе:
Чтобы отчёты не превращались в статистику «ради статистики», привязывайте их к OKR. На практике это выглядит так: (1) какая метрика по тиру должна улучшиться, (2) что конкретно сделали (кампания онбординга, обучение, изменение фичи, коммуникации), (3) какой эффект увидели на следующей неделе/в следующем спринте. В отчёте фиксируйте не только цифры, но и гипотезу, которую проверяли.
Отдельно ведите список «что не заводится» по каждому тиру: какие функции не доходят до регулярного использования, где бросают настройку, на каком шаге возникают ошибки или непонимание. Это даёт продуктовой команде понятный, сегментированный бэклог: улучшения UX, подсказки, шаблоны, ограничения ролей, обучение.
Минимум раз в месяц проводите «health‑check» аналитики: пропуски событий, резкие изменения объёмов, дрейф определений метрик и сегментов, несоответствие идентификаторов аккаунтов/пользователей. Договоритесь о процессе: кто подтверждает изменения в событиях, где хранится актуальный словарь метрик, и как быстро чинится критичный разрыв данных.
Начните с перечня решений, которые трекер должен поддерживать:
Затем сформулируйте 5–10 вопросов ("где проседает", "почему", "у кого") и уже под них выберите события и витрины.
Определите «аккаунт» на уровне, где:
account_id;Чаще всего это компания/организация или рабочее пространство. Главное — зафиксировать определение в 1–2 абзацах и не менять его «по ходу» без миграции данных.
Возьмите 3–4 тира, которые реально отличаются по поведению и модели сопровождения (например, SMB / Mid-market / Enterprise или A/B/C).
Критерии сделайте однозначными и проверяемыми:
Если критериев несколько — заранее задайте приоритет (например, ARR важнее seats).
Нужен один «источник правды» и понятный процесс обновлений. Практичные варианты:
Дополнительно храните историю изменения тира (SCD Type 2), чтобы когорты «до/после апгрейда» не ломали отчёты задним числом.
Соберите «ядро» метрик, которые отвечают на вопрос ценности и стабильности:
Пороги и ожидания задавайте отдельно для каждого тира, иначе сравнение будет нечестным.
Выберите одно проверяемое событие, которое коррелирует с долгосрочным использованием (например, «первый проект создан», «первая интеграция подключена», «первый отчёт отправлен»).
Проверка качества определения:
Если aha — это комбинация шагов, храните правило отдельно (чтобы менять без переписывания всего пайплайна).
Минимальный «контракт события»:
event_name (из словаря),occurred_at (UTC),Базовый поток: сбор событий → буфер (очередь/лог) → обработка → витрины → UI.
Практичные правила, чтобы цифрам доверяли:
event_id;account_id по справочнику;Сделайте минимум две витрины:
account_id × период (активность, ключевые действия, активные пользователи, атрибуты тира/плана/региона).account_id × feature_id × период (факт использования и интенсивность).Добавьте нормализацию «на пользователя/на место», чтобы большие аккаунты не выигрывали просто из-за размера.
Сначала настройте пороги и SLA по тирам, затем каналы доставки и «что делать дальше».
Примеры алертов:
Каждый алерт должен вести в карточку аккаунта (например, /accounts/{account_id}) и содержать причину, период и рекомендуемый следующий шаг.
account_id,user_id (если применимо),event_id,properties (контекст: план, роль, тип интеграции и т. п.).Лучше использовать именование object_action и версионировать схему (schema_version). Критичные события дублируйте на сервере, даже если отправляете из клиента.
Так проще объяснить происхождение любой метрики и быстро найти поломку.