План создания веб‑приложения для управления уведомлениями: требования, архитектура, шаблоны, правила отправки, интеграции, безопасность и мониторинг.
Центр управления уведомлениями — это единое место, где компания настраивает, изменяет и контролирует все сообщения пользователям: от сервисных писем и пушей до SMS и уведомлений внутри продукта. Он нужен не только «для рассылок», а для управляемой коммуникации, которая напрямую влияет на конверсию, удержание и нагрузку на поддержку.
Для продукта — это единый стандарт общения с пользователем: одинаковый тон, понятные статусы заказов, предсказуемые напоминания, меньше раздражающих повторов.
Для компании — снижение рисков и потерь: меньше ошибок в тексте и ссылках, меньше несанкционированных отправок, проще соблюдать требования к согласованиям.
Для команд — ускорение работы: маркетинг и поддержка не ждут релиза, чтобы поправить шаблон; разработчики меньше отвлекаются на просьбы «поменяйте одну фразу».
Когда уведомления живут в разных сервисах и кусках программирования, быстро появляются типичные проблемы:
Обычно в центре уведомлений выделяют несколько ролей: администратор (права, правила, доступы), редактор шаблонов (тексты и переменные), разработчик (события и интеграции), оператор поддержки (поиск истории, разбор инцидентов).
В итоге вы получаете контроль (кто отправляет и что именно), скорость изменений (правки без долгих цепочек) и прозрачность отправок (история, причины, статусы). Это заметно снижает количество обращений и «пожаров» вокруг коммуникаций.
Прежде чем проектировать сервис уведомлений, важно договориться о том, какие задачи он решает, а какие — нет. На этом этапе ошибки обходятся особенно дорого: без фиксированных ожиданий система быстро превратится в набор исключений и «ручных правил».
Начните с классификации. Обычно выделяют:
Тип важен не «для красоты»: от него зависят приоритеты, окна отправки, требования к согласию пользователя (opt‑in/opt‑out) и юридические ограничения.
Сформулируйте SLA в терминах, понятных бизнесу и поддержке:
Сразу зафиксируйте, что считается «доставкой»: попытка отправки провайдеру, подтверждение провайдера или факт прочтения.
Перечислите системы‑источники: продукт (события пользователя), биллинг, поддержка, мониторинг. Для каждого источника назначьте владельца, который отвечает за корректность событий и их схему (какие поля обязательны, какие — опциональны).
Зафиксируйте рамки:
Результат этапа — короткий документ с матрицей «тип уведомления × SLA × ограничения» и перечнем источников событий. Он станет опорой для следующих решений по каналам, моделям данных и маршрутизации.
Центр управления уведомлениями обычно начинают с 2–3 каналов, но проектировать лучше так, чтобы добавление новых не превращалось в переделку всей системы. Практичный минимум: email и SMS (для критичных случаев), плюс push (мобильный/веб) для быстрых действий. Дальше по мере роста часто добавляются мессенджеры и вебхуки для интеграций.
На старте полезно разделить каналы на:
Заранее договоритесь, какие каналы являются «обязательными» (например, SMS для подтверждения входа), а какие — «мягкими» (маркетинговые и информационные).
Вместо жёсткой привязки к одному каналу задайте политику доставки: попытки, таймауты и переключения. Например:
Фолбэк должен учитывать смысл сообщения: для одноразовых кодов поздний повтор часто хуже, чем отказ и новая попытка пользователя.
Сделайте простую модель приоритетов (например, P0–P3) и правила очередности:
Чтобы каналы были взаимозаменяемыми, используйте общий «конверт» события: тип, получатель, параметры, приоритет, ограничения по времени, разрешённые каналы. А уже на стороне канала формируется конкретное сообщение (тема письма, текст SMS, payload push). Это упрощает расширение каналов и поддерживает единые правила доставки.
Чтобы центр управления уведомлениями не превратился в набор «разрозненных отправок», важно сразу договориться о базовых сущностях и статусах. Это упростит аудит, поддержку, аналитику и интеграции с другими системами.
Минимальный набор, который покрывает большинство сценариев:
Заложите трассировку сразу — иначе разбор инцидентов станет ручной археологией. В каждой записи Notification (и часто в DeliveryAttempt) полезны:
Практичная цепочка статусов:
создано → поставлено в очередь → отправлено → доставлено
И два важных терминальных состояния:
Разделяйте «отправлено» и «доставлено»: первое означает, что ваш сервис передал сообщение провайдеру, второе — что провайдер подтвердил доставку (если канал это поддерживает).
Повторы неизбежны: ретраи, сетевые таймауты, повторные вебхуки. Нужны:
event_id + recipient_id + channel или внешний idempotency_key),Так вы получите предсказуемую историю и снизите риск двойных уведомлений — одну из самых болезненных проблем для пользователей.
Центр управления уведомлениями обычно строится вокруг простой идеи: принять запрос на уведомление, надежно поставить его в обработку и доставить по нужному каналу, сохранив след для аудита. Чтобы не «завязывать» бизнес‑системы на особенности провайдеров и не терять сообщения при всплесках нагрузки, полезно сразу отделить прием запросов от отправки.
Для MVP достаточно связки API + очередь + воркеры отправки + база данных:
Такой разрез позволяет независимо масштабировать прием (API) и доставку (воркеры), а также проще изолировать сбои у внешних провайдеров.
Если вам важно быстро собрать рабочий прототип (админ‑панель + API + воркеры) и показать его командам, удобно использовать подход vibe‑coding. Например, в TakProsto.AI можно описать требования в чате и получить каркас веб‑приложения на React, бэкенд на Go и PostgreSQL, а затем итеративно докрутить очереди, статусы и RBAC. Плюс полезны snapshots и быстрый rollback, когда вы активно меняете правила и шаблоны в процессе пилота.
Для центра уведомлений микросервисы не обязательны с первого дня. Критерии выбора:
Практичный компромисс: монолитное API + несколько воркеров/процессов по каналам, которые можно вынести в сервисы позже.
Повторы должны быть предсказуемыми: экспоненциальный backoff (например, 1 мин → 5 мин → 30 мин), лимит попыток и отдельная dead-letter queue для «неисправимых» сообщений. Это защищает систему от бесконечных циклов и позволяет оператору увидеть проблемные уведомления и причины.
История уведомлений быстро растет, поэтому заранее решите:
Если продумать эти элементы на старте, система будет стабильнее и дешевле в эксплуатации по мере роста объема уведомлений.
Шаблоны — это «контентный слой» сервиса уведомлений: именно здесь формулировки становятся понятными пользователю, а данные из системы превращаются в письмо, SMS или push. Хорошо устроенные шаблоны ускоряют запуск новых сценариев и уменьшают количество ошибок при отправке.
Один и тот же смысл сообщения обычно требует разных форматов:
Важно хранить это не «в одном поле», а как структуру по каналам — так проще валидировать и менять.
Шаблон должен явно описывать, какие данные ему нужны. Практичный минимум:
Это защищает от ситуаций, когда пользователю уходит «Здравствуйте, {{name}}» из‑за пропущенного поля.
Локализация — не только перевод. Часто критичнее корректный формат дат/времени, валют, телефонных масок и, при необходимости, падежей/согласования. Хорошая практика — хранить шаблон по ключу (например, order_paid) и отдельные версии по языкам, с единым набором переменных.
Шаблоны стоит версионировать как код: черновик → предпросмотр на тестовых данных → публикация. В админ‑панели полезны:
Так изменения текста не превращаются в риск для отправок и поддержки.
Маршрутизация — это «мозг» центра уведомлений: она решает, кому, когда и по каким каналам отправить сообщение, а также когда лучше промолчать. Важно сразу отделить бизнес‑правила (приоритеты, окна тишины, исключения) от технических деталей доставки.
Практичный подход — хранить правила как набор условий и действий:
Например: для события «подтверждение входа» — высокий приоритет, отправка сразу, канал по умолчанию SMS, а в регионе с дорогими SMS — push + email.
Хорошие правила включают защиту от спама и повторов:
Если вы делаете платформу для нескольких клиентов, закладывайте уровни наследования правил: глобальные → клиент → проект → конкретный аккаунт. При конфликте побеждает более конкретное правило, а система должна объяснять «почему так решили» (это важно для поддержки и аудита).
Для безопасных изменений нужен режим, где правила прогоняются без реальной отправки:
Так вы сможете развивать маршрутизацию постепенно и предсказуемо — без сюрпризов для пользователей и команды.
API — это контракт между вашим центром уведомлений и всеми системами, которые генерируют события (CRM, биллинг, поддержка), а также внешними провайдерами доставки (SMS, email, push). Чем точнее вы его спроектируете, тем меньше «ручных исключений» будет в интеграциях.
Для MVP обычно достаточно трёх групп:
POST /api/v1/events — принимает тип события, получателя, параметры шаблона, контекст (заказ, тикет), желаемые каналы/ограничения. В ответ — notification_id.GET /api/v1/notifications/{id} — возвращает текущий статус (создано/в очереди/отправлено/доставлено/ошибка) и важные метаданные.GET /api/v1/notifications/{id}/attempts — показывает все ретраи, коды ошибок провайдера, время, использованный канал и провайдера. Это критично для поддержки и аудита.Практичный вариант — API‑ключи или токены на сервис/интеграцию:
Большинство провайдеров присылают обратные события: подтверждение доставки, отписки, жалобы, bounce. Заведите, например, POST /webhooks/provider/{name} и обязательно:
Возвращайте структурированные ответы: HTTP‑код + машинный код ошибки (INVALID_RECIPIENT, TEMPLATE_NOT_FOUND, RATE_LIMITED) + короткую рекомендацию (можно ли повторить запрос и когда). Это снижает нагрузку на команду и ускоряет подключение новых систем.
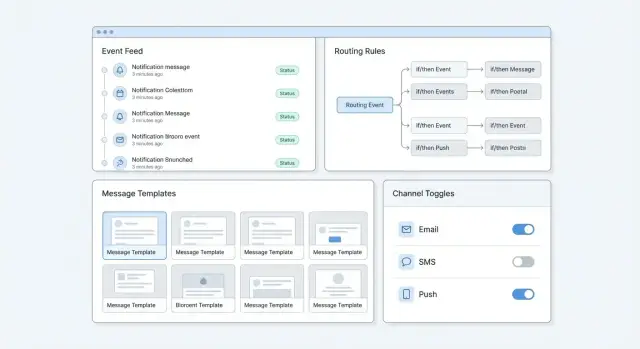
Админ‑панель — это рабочее место поддержки и продуктовой команды: здесь быстро находят проблемные отправки, правят тексты, включают/выключают правила и объясняют пользователю, «почему не пришло». В MVP важно не «нарисовать красиво», а закрыть ежедневные сценарии.
1) Лента уведомлений (журнал событий)
Это стартовый экран: таблица/лента со всеми отправками и попытками доставки. Минимальные колонки: время, получатель, канал, тип/событие, статус, провайдер, причина ошибки.
2) Карточка уведомления/события
Открывается из ленты. Внутри: исходные данные, итоговый текст, выбранный шаблон и версия, сработавшие правила, история попыток (retry), ответы провайдеров, технические метки для поддержки.
3) Шаблоны
Список и редактор: текст, переменные, превью, языки, статусы (черновик/активен), история версий и кнопка «откатить».
4) Правила
Условия (кто/когда/по какому событию), маршрутизация по каналам, приоритет, «тихий режим», ограничения частоты. В MVP достаточно понятного конструктора и явного логирования «почему правило сработало».
Если вы хотите ускорить создание такой админ‑панели, TakProsto.AI может помочь собрать интерфейс на React и связать его с API (включая RBAC, аудит изменений, предпросмотр шаблонов и журнал уведомлений) через чат‑итерации. При необходимости вы сможете экспортировать исходники и развивать продукт внутри своей инфраструктуры.
Сделайте фильтры «как в поддержке»: период, тип, канал, получатель, статус, ошибка/код провайдера. Плюс быстрый поиск по ID уведомления и ID пользователя. Обязательно — сохранение фильтров (например, «Ошибки за сутки») и прямые ссылки на результаты.
Минимальный набор ролей:
Для разбора инцидентов нужны: экспорт в CSV из ленты, копируемые ссылки на карточки, поле «заметка/комментарий» с автором и временем. Если планируете SLA, добавьте простой отчёт «ошибки по каналу/провайдеру» и «время доставки».
Центр управления уведомлениями почти всегда работает с персональными данными: телефоны, email, имена, идентификаторы заказов, иногда — адреса и детали платежей. Поэтому безопасность нужно проектировать не «в конце», а как часть MVP: иначе вы либо утонете в инцидентах, либо не пройдёте внутренний аудит.
Базовый принцип — хранить и передавать только то, что действительно нужно для доставки.
iv***@domain.com, +7 *** ***‑**‑12). Полный контакт — только тем ролям, кому это требуется.Данные уведомлений быстро превращаются в «архив всего», который сложно защищать и дорого держать.
Определите политики заранее:
Разделите доступ по ролям и по проектам (tenant‑изоляция): оператор поддержки, маркетолог, инженер, администратор.
Для API обязательны:
Если вы планируете раздел «история и аудит уведомлений», заранее продумайте, какие поля можно логировать безопасно, а какие должны быть замаскированы по умолчанию.
Уведомления — это часть продукта, которая быстро становится «невидимой» для команды, пока что‑то не сломается: пользователям не приходит код входа, клиенты получают письмо на чужом языке, а массовая рассылка падает из‑за лимитов провайдера. Поэтому в центре управления уведомлениями важно тестировать не только бизнес‑логику, но и шаблоны, данные и сценарии доставки.
Шаблоны меняются чаще, чем логика очередей, и ошибки в них обычно выявляются уже «в бою». Минимальный набор юнит‑проверок:
user_name или order_id;{{name}}, не ломает переносы и не превышает ограничения (например, длина SMS);Практика: храните «эталонные» входные данные для шаблона (fixtures) и прогоняйте их при каждом изменении шаблона или версии.
Даже если ваше API стабильно, внешний провайдер может по‑другому трактовать параметры, кодировки или лимиты. Интеграционные тесты стоит строить так:
Сервис уведомлений обязан выдерживать всплески: акции, начисления, аварийные оповещения.
Проверьте:
Часть проблем — не в доставке, а во входных данных. Добавьте автоматические проверки:
Итоговый критерий качества простой: уведомление должно быть корректным по содержанию, отправляться только тем, кому нужно, и предсказуемо вести себя при сбоях и перегрузках.
Чтобы центр управления уведомлениями не превратился в «чёрный ящик», наблюдаемость нужно закладывать с первого дня: что происходит с уведомлением, где оно задержалось, почему не доставилось и кто это заметит.
Минимальный набор метрик лучше привязать к воронке доставки:
Эти метрики удобно собирать по тегам: channel, provider, template_id, tenant/project.
В каждом компоненте (API → очередь → воркер → провайдер) используйте сквозной идентификатор: notification_id и/или correlation_id. Он должен попадать в структурированные логи, трейс и ответы API.
Полезно логировать ключевые переходы статусов (created → queued → sent → delivered/failed) и причину сбоя в нормализованном виде (код, категория, текст).
Ставьте алерты не на «всё подряд», а на симптомы:
Запуск проще проводить поэтапно:
Так вы снижаете риск массовых сбоев и быстрее находите узкие места в эксплуатации.
Это единая система, где вы управляете всеми уведомлениями: шаблонами, правилами отправки, каналами (email/SMS/push), историей доставок и правами доступа.
Практический эффект — меньше ошибок и дублей, быстрее правки контента без релизов и понятный аудит «что ушло пользователю и почему».
Потому что при «зоопарке» (разные сервисы и куски программирования) неизбежны:
Центр управления сводит это в один контур с ролями, версиями и статусами.
Минимально выделите:
Тип влияет на SLA, приоритеты, «тихие часы» и требования к согласию (opt-in/opt-out).
Зафиксируйте SLA в бизнес-терминах:
Отдельно договоритесь, что считать «доставкой»: передачу провайдеру, подтверждение провайдера или факт прочтения.
Полезный минимум:
Разделяйте:
Дополнительно нужны терминальные состояния:
Используйте идемпотентный ключ (например, event_id + recipient_id + channel или внешний idempotency_key) и дедупликацию на уровне БД/кэша (уникальный индекс/таблица ключей).
Отдельно задайте политику: когда повтор должен обновить существующее Notification, а когда создать новое — это критично для предсказуемой истории.
Рабочая база для MVP:
Ретраи делайте предсказуемыми: экспоненциальный backoff, лимит попыток и DLQ (dead-letter queue) для «неисправимых» сообщений.
В MVP обычно достаточно:
POST /api/v1/events — создать уведомление по событию;GET /api/v1/notifications/{id} — получить статус и метаданные;GET /api/v1/notifications/{id}/attempts — увидеть все попытки доставки.Для провайдерских колбэков заведите /webhooks/provider/{name} с проверкой подписи и идемпотентной обработкой.
Минимум — четыре зоны:
И сразу заложите RBAC: просмотр, поддержка, контент-менеджер, администратор.
Сразу добавьте correlation_id, source, notification_type, template_version — это ускоряет расследования и поддержку.