Пошаговый план веб‑приложения для централизованной SLA‑отчётности по всем клиентам: данные, мультиарендность, метрики, дашборды, алерты и безопасность.
Единая SLA‑отчётность становится критичной, когда вы обслуживаете несколько клиентов одновременно: у каждого свои договорённости, свои сервисы и свой взгляд на «нормально» и «плохо». Цель такого веб‑приложения — дать всем участникам одну точку правды по SLA, чтобы отчёты были сопоставимыми, проверяемыми и собирались без ручного труда.
Когда SLA считают «как привыкли» в разных командах и инструментах, быстро появляются типовые боли: цифры не сходятся, формулы отличаются, источники данных противоречат друг другу, а отчёты делаются в таблицах вручную и зависят от конкретного человека.
Централизованный подход убирает хаос: правила расчёта фиксируются, данные подтягиваются автоматически, а история изменений сохраняется. В результате спор «у нас 99,9%» превращается в разговор «по какой методике и по каким событиям считаем».
Прежде чем строить дашборды и автоматизировать отчёты, нужно договориться о «языке цифр»: какие SLA/KPI считаем, в каких единицах и по каким правилам. Иначе один и тот же месяц может получиться «99,95%» в одном отчёте и «99,5%» в другом — просто из‑за разных трактовок.
Обычно достаточно 3–5 метрик, которые понятны клиенту и привязаны к договору:
Сразу фиксируйте:
Пример расчёта доступности:
Availability = 1 - (Downtime_SLA / Total_Time)
Где Downtime_SLA — только тот простой, который по договору влияет на SLA.
Чтобы отчёт был полезным, закладывайте разрезы: клиент → услуга → регион, а также критичность, канал поддержки (почта/портал/телефон) и тип инцидента.
Самое важное — формализовать правила:
Эти договорённости стоит закрепить в справочнике правил — это снижает количество разбирательств и делает отчётность сопоставимой от периода к периоду.
Мультиарендность в SLA‑отчётности — это не только про экономию инфраструктуры, но и про доверие: клиент должен быть уверен, что видит только свои инциденты, свои расчёты и свои правила.
Отдельная БД на клиента упрощает изоляцию и аудит: меньше риск «протечки» через ошибку в запросе, легче делать экспорт/удаление данных. Минусы — больше операционных затрат, сложнее выпускать миграции и поддерживать одинаковые версии схем.
Общий кластер с разделением данных (одна БД, общий набор таблиц) обычно выгоднее и удобнее для развития продукта. Но тогда изоляция должна быть встроена в архитектуру: и в данных, и в доступах.
Практика по умолчанию — добавлять tenant_id во все «арендные» сущности и делать фильтрацию неизбежной:
Важно не полагаться только на один слой: ошибки случаются, а дублирование барьеров снижает риск.
Такой граф позволяет корректно отвечать на вопрос «по какому договору и по каким правилам считать этот отчёт». Измерения (инциденты, даунтайм, окна обслуживания) должны ссылаться на конкретный сервис и версию правил.
Для SLA с рабочими часами критично хранить:
И обязательно версионировать правила SLA: отчёт за март должен считаться по правилам, действовавшим в марте, даже если в июле вы обновили формулу или расписание. Это защищает от «пересчёта задним числом» и упрощает разбор спорных ситуаций.
Чтобы SLA‑отчётность была доверенной, важно заранее договориться, откуда берутся факты об инцидентах и как вы «склеиваете» их в единую картину. Чаще всего данные приходят из нескольких источников, и каждый закрывает свой кусок правды.
Мониторинг даёт точные таймстемпы (начало/конец деградации), но не всегда содержит бизнес‑контекст.
Тикет‑система фиксирует коммуникации, приоритеты, ответственных и этапы обработки. Это ключ к метрикам типа MTTA/MTTR и соблюдению регламентов.
Статус‑страницы полезны как независимое подтверждение публичных объявлений (когда сообщили клиенту, что именно признали инцидентом).
Ручные корректировки нужны для исключений: плановые работы, спорные интервалы, ошибки источников. Их важно ограничивать ролями и обязательно протоколировать.
Выбирайте режим по природе данных:
Практика: разделить «оперативный поток» (для алертов) и «витрину отчётности» (для финального расчёта), чтобы корректировки и запоздавшие статусы не ломали онлайн‑логику.
У разных систем разные статусы, приоритеты и названия сервисов. Нужен слой нормализации:
Один и тот же инцидент может появиться в мониторинге, нескольких тикетах и на статус‑странице. Закладывайте правила связывания: по временным окнам, затронутому сервису, корреляционному ключу (если есть) и признакам «родитель/дочерний» для крупных аварий.
Каждая загрузка должна быть повторяемой: если вы импортируете один и тот же период дважды, результат не должен удваиваться.
Храните журнал импорта: источник, диапазон времени, количество записей, версии маппингов, ошибки и предупреждения. Это ускоряет разбор расхождений и помогает на этапе аудита (см. также /blog/konfidencialnost-audit-sla если у вас есть отдельный материал).
Чтобы SLA‑отчётность была воспроизводимой и «доказуемой», модель данных лучше строить от фактов (что случилось) к вычислениям (как посчитали). Тогда любое число в отчёте можно разложить на исходные события, правила и историю правок.
Минимальный набор сущностей обычно выглядит так:
Практика, которая экономит время на спорных кейсах: хранить две зоны данных.
Raw‑слой — неизменяемые события «как пришли» (допускается только добавление).
Report‑слой — агрегаты для дашбордов: итоговый downtime, доступность, количество инцидентов по категориям, топ причин. Агрегаты пересчитываются по версии правил и фиксируются на момент публикации отчёта.
Базовая формула для доступности на период:
Важно явно моделировать исключения, иначе цифры будут «плавать»:
Каждое правило исключения должно быть применено детерминированно: по типу сервиса, клиенту, региону, времени и причине.
Отдельно храните слой объяснений (например, sla_explanations): ссылки на инциденты, причины, комментарии, приложенные файлы и отметки «почему не считается в SLA». Это превращает отчёт из таблицы в аргументированный документ.
Для доверия критичны требования «кто и когда»: журналируйте правки данных и правил.
Так вы сможете восстановить расчёт за любой период и объяснить расхождения между предварительными и финальными цифрами.
Доступ к SLA‑отчётности — это не только «кто может войти», но и «что именно он увидит» и «какие действия сможет выполнить». Ошибка в настройках быстро превращается в утечку данных между клиентами, поэтому роли и правила доступа лучше заложить в продукт с самого начала.
Обычно достаточно четырёх ролей:
Поддержите несколько способов входа:
Важно: отдельно храните «пользователь» и «принадлежность к организациям», чтобы один человек мог иметь доступ к нескольким клиентам (например, подрядчик) без смешивания прав.
Помимо роли, задайте ограничение по:
Отдельно выделите доступ к черновикам и к утверждённым отчётам: черновики видят только админ и менеджер аккаунта, а клиент — после публикации.
Для интеграций и автоматизации используйте:
Так вы снижаете риск компрометации и упрощаете контроль доступа при росте числа клиентов и интеграций.
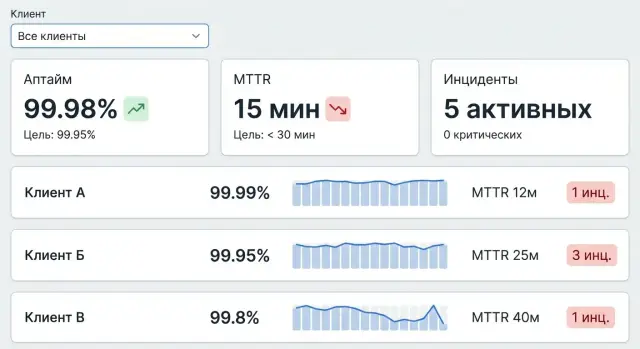
Хороший SLA‑дашборд отвечает на два вопроса: «где мы сейчас относительно цели?» и «почему получилось именно так?». Пользователю не нужно разбираться в источниках данных — ему нужны ясные выводы, а при необходимости быстрый путь к деталям.
На главной удобно показывать таблицу/плитки по всем клиентам: выполнение SLA за текущий период, отклонение от цели, статус (норма/риск/нарушение) и короткий список «что ухудшилось за 7 дней». Добавьте быстрые фильтры: период, клиент, сервис/компонент, регион, критичность.
Сразу отделяйте «плохие данные» от «плохого SLA»: например, индикатор покрытия (сколько инцидентов/метрик пришло корректно) рядом с итоговой цифрой.
В карточке клиента — KPI за период (месяц/квартал), тренд по неделям, топ‑нарушения и «проблемные сервисы» с вкладом в общий простой. Полезны два вида сравнений: с целевым SLA и с прошлым периодом.
При клике на сервис пользователь должен увидеть таймлайн инцидентов с длительностью, статусом и тем, как каждый простой повлиял на итоговую метрику (в минутах и процентах). Это снимает споры: «вот конкретные события, вот их вес в расчёте».
Экспортируйте PDF/CSV по шаблонам ежемесячных отчётов: титульная страница, итоговые KPI, список нарушений, приложения с деталями. Поддержите брендирование клиента (логотип, цвета, реквизиты) и ссылку на онлайн‑версию отчёта (например, /reports/2025-11/client-123).
Сделайте отдельный блок «Как посчитано»: формула, окно измерения, правила округления, таймзона, список исключений (плановые работы, неприменимые сервисы, инциденты вне охвата) и ссылки на первичные записи. Чем прозрачнее расчёт, тем меньше ручных согласований.
Алерты в SLA‑отчётности нужны не для «поймать виноватых», а чтобы успеть исправить ситуацию до того, как период закроется с нарушением. Поэтому полезно проектировать уведомления как систему раннего предупреждения, а не как набор разрозненных писем.
Вместо простого правила «SLA нарушен» используйте предиктивные пороги: приложение считает, какой запас по SLA остаётся и насколько быстро он расходуется.
Примеры сигналов:
Такой подход требует фиксировать период расчёта (месяц/квартал), учитывать окна обслуживания и исключения, а также показывать пользователю, что именно повлияло на прогноз.
Разные роли предпочитают разные каналы. В интерфейсе задайте правила доставки по типу события и уровню критичности: письмо руководителю, сообщение в корпоративный мессенджер дежурной смене, веб‑хук во внутреннюю автоматизацию.
Добавляйте в уведомление краткую суть (клиент, сервис, риск/порог, период) и ссылку на карточку события внутри приложения.
Эскалация должна учитывать расписание: кто «на линии» сейчас, кто резервный, какие часы нерабочие.
Обычно работает цепочка: исполнитель → старший смены → менеджер сервиса. Для каждой ступени задаются таймеры (например, 10/30/60 минут без реакции).
Чтобы алерты превращались в управляемый процесс, используйте статусы: «открыто» → «в работе» → «закрыто». Добавьте подтверждение получения (ack) и комментарий о принятых мерах — это снижает дублирование и упрощает разбор.
Без контроля алерты быстро превращаются в спам. Помогают:
В результате пользователи получают меньше сообщений, но с более высоким сигналом и понятным следующим шагом.
Архитектуру SLA‑сервиса лучше проектировать «от API», даже если вы сначала делаете только веб‑интерфейс. Это помогает заранее договориться о терминологии (инцидент, сервис, окно обслуживания, клиент) и избежать ситуации, когда отчёты «живут» в одном месте, а данные для пересчёта — в другом.
Хорошая практика — выделить несколько понятных групп:
Такой разрез упрощает интеграции: сначала можно подключить один источник инцидентов, а позже добавить второй, не меняя контракты для потребителей.
Для большинства команд разумно начинать с модульного монолита: одна кодовая база, но чёткие модули (импорт, расчёты, отчёты, доступ). Микросервисы становятся оправданными, когда у вас:
Импорт данных и пересчёты SLA почти всегда удобнее выносить в фон:
Очереди помогают «разгладить» пики и делают систему устойчивее к временным сбоям внешних API.
Пользователь ожидает, что дашборд откроется за секунды. Для этого часто используют комбинацию:
Добавьте базовую наблюдаемость с первого релиза: структурированные логи, метрики по импортам/очередям/ошибкам, трассировку ключевых запросов, а также журнал ошибок с привязкой к клиенту и интеграции. Это снижает время поиска причин, когда пользователи видят «не те цифры» и нужно быстро доказать, где произошёл разрыв в данных.
Если задача — быстро проверить гипотезу (формулы, структуру данных, роли, формат отчёта) и показать первый прототип, удобно использовать TakProsto.AI. На платформе можно в режиме чата собрать веб‑приложение с личными кабинетами и базовыми дашбордами: фронтенд на React, бэкенд на Go с PostgreSQL, а затем при необходимости выгрузить исходники, подключить деплой/хостинг, настроить домен и откаты (snapshots/rollback). Это особенно полезно, когда нужно за 1–2 недели подготовить пилот для нескольких клиентов и параллельно уточнять требования к SLA‑правилам.
SLA‑отчётность ломается не из‑за формул, а из‑за «грязных» входных событий: пропущенных статусов, разъехавшихся таймзон, дублей и поздних обновлений. Поэтому надёжность системы начинается с дисциплины данных и проверок на каждом шаге — от импорта до вывода отчёта.
Разведите dev/stage/prod не только по инфраструктуре, но и по правилам доступа к данным. В dev используйте синтетические наборы и анонимизированные копии, в stage — максимально близкие к продакшену объёмы, но без персональных данных, если это возможно.
Тестовые «клиенты» должны покрывать разные профили: круглосуточная поддержка, рабочие часы, разные часовые пояса, разные правила исключений (плановые работы, «заморозка» на ожидании клиента).
Минимальный набор автоматических проверок перед расчётом:
Ошибки важно не «чинить молча»: сохраняйте исходное событие, помечайте проблему флагом качества и показывайте её в техотчёте для администраторов.
Проверяйте расчёты на контрольных наборах: небольшой «эталонный» датасет с вручную посчитанными результатами. Отдельно заведите кейсы спорных инцидентов: переходы статусов в нерабочее время, перекрывающиеся паузы, переоткрытия, частичное выполнение SLA по нескольким целям. Полезен подход «golden tests»: одно изменение формулы — и сравнение с ожидаемыми значениями по всем сценариям.
Нагрузочно тестируйте два узких места: импорт (пики вебхуков/пакетная выгрузка) и тяжёлые отчёты (агрегации за квартал по множеству клиентов). Закладывайте лимиты, кэширование и предагрегации там, где пользователю нужен быстрый ответ.
Регулярные бэкапы базы и хранилища событий дополняйте проверками восстановления: раз в месяц поднимайте копию и прогоняйте расчёт SLA, чтобы убедиться, что восстановление реально работает. Зафиксируйте RPO/RTO и храните «плейбук» действий на инцидент — кто, что и в каком порядке делает.
SLA‑отчётность быстро превращается в «витрину доверия»: клиенты смотрят не только на цифры доступности, но и на то, как вы обращаетесь с данными. Поэтому требования к конфиденциальности лучше заложить в продукт сразу, а не «докручивать» перед аудитом.
Шифруйте данные в транзите (TLS) и в хранении (например, на уровне дисков/базы). Для ключей и токенов интеграций используйте централизованное хранилище секретов, а не переменные в коде или конфиги в репозитории.
Разделяйте секреты по средам (dev/stage/prod), ограничивайте доступ по принципу минимальных привилегий и регулярно ротируйте ключи. Для внешних интеграций удобны короткоживущие токены и отдельные сервисные аккаунты на каждого арендатора.
Определите сроки хранения сырых событий и агрегатов SLA: сырые логи обычно нужны недолго, а агрегированные показатели — дольше для сравнения периодов.
Продумайте:
Если персональные данные не влияют на расчёт SLA, не тяните их в витрину. Чаще всего достаточно идентификаторов тикетов/инцидентов и технических атрибутов (время, сервис, приоритет). Если имена/почта всё же нужны, используйте маскирование в интерфейсе и раздельные права на просмотр.
Сделайте аудит «первоклассной» сущностью: фиксируйте входы, попытки доступа, экспорты, изменения правил расчёта SLA и любых исключений (например, согласованные окна работ). Логи аудита должны быть неизменяемыми и иметь отдельные сроки хранения.
Для запросов клиентов подготовьте пакет подтверждений: перечень контролей, описание потоков данных, матрицу доступов, процедуры реагирования на инциденты и шаблоны документов. Удобно вести это в отдельном разделе, например /security, и обновлять вместе с релизами продукта.
У SLA‑отчётности высокий риск «споров о калькуляторе»: если расчёты и формат отчёта не совпадут с ожиданиями клиента, доверие к системе падает сразу. Поэтому внедрение лучше строить как управляемый проект с пилотом, прозрачной миграцией и заранее согласованными критериями успеха.
Начните с пилота на одном «простом» и одном «требовательном» клиенте. Цель — не покрыть все кейсы, а подтвердить корректность формул (окна обслуживания, исключения, правила округления) и договориться о форматах: что считается инцидентом, какие периоды показываем, как выглядят комментарии к отклонениям.
Исторические данные полезны, чтобы сразу показать динамику и снять вопросы к новым отчётам. Загружайте историю порциями (например, последние 3–6 месяцев), фиксируйте источники и делайте сверку с прежними отчётами: выборочно по датам, сервисам и «крайним» случаям (пограничные интервалы, пересекающиеся инциденты). Любые расхождения оформляйте как правила: что именно меняем — данные или формулу.
Сработают короткие материалы: 1–2 страницы «как читать отчёт», памятка по ролям и правам, FAQ по частым вопросам. Хорошая практика — встроенные подсказки в интерфейсе и шаблоны комментариев к инцидентам.
Метрики внедрения можно измерять просто: меньше времени на подготовку отчёта, снижение числа спорных кейсов, быстрее реакция на риск нарушения SLA.
Дальше систему логично развивать в сторону прогнозирования (риск нарушения до конца месяца), сценариев улучшения (что даст сокращение MTTR) и каталога сервисов с едиными определениями SLA. Это позволяет перейти от «отчётности ради отчётности» к управлению качеством сервиса.
Если вы делаете продукт под российский контур и важны требования к данным, заранее продумайте размещение и стек: TakProsto.AI, например, работает на серверах в России, использует локализованные/opensource LLM‑модели и не отправляет данные в другие страны. На практике это упрощает прохождение внутренних проверок безопасности ещё на этапе пилота, а дальше можно выбрать подходящий тариф (free/pro/business/enterprise) и масштабировать решение по мере роста числа клиентов.
Начните с фиксации методики в виде «справочника правил»:
Пока правила не формализованы, любые дашборды будут воспроизводить разные трактовки.
Минимально практичный набор — 3–5 метрик, привязанных к договору:
Важно сразу указать, какие метрики считаются 24×7, а какие — в рабочих часах.
Это «главный источник расхождений». Зафиксируйте:
И храните версию календаря вместе с версией правил, чтобы отчёты за прошлые месяцы не «пересчитывались задним числом».
Есть два базовых варианта:
tenant_id — дешевле и быстрее развивать, но требует строгой защиты на всех слоях.На практике часто начинают с общего кластера и усиливают контроль: глобальные фильтры, политики на уровне БД и проверки в API.
Используйте несколько барьеров одновременно:
tenant_id во всех «арендных» сущностях и неизбежная фильтрация;Дополнительно полезны авто‑тесты, которые проверяют, что любой эндпоинт возвращает данные только своего арендатора.
Соберите факты из нескольких источников и нормализуйте их:
Ключевой слой — маппинг статусов/приоритетов/сервисов в единый словарь.
Закладывайте правила корреляции заранее:
Обязательно ведите журнал импорта: источник, диапазон времени, количество записей, ошибки, версия маппингов.
Практичный минимум — разделить хранение на два слоя:
Так любое число можно «развернуть» до исходных событий и понять, где появилась разница.
Сделайте аудит «первоклассной» функцией:
Это помогает объяснять расхождения между черновыми и финальными отчётами и выдерживать проверку безопасности.
Ориентируйтесь на два вопроса пользователя: «где мы относительно цели?» и «почему так вышло?»
Экспорт (PDF/CSV) лучше делать по шаблонам и давать ссылку на онлайн‑версию вида /reports/2025-11/client-123.