Пошаговый план веб‑приложения для учета нагрузки саппорта и расчета потребности в сотрудниках: метрики, модель данных, дашборды, прогноз и запуск.
Это веб‑приложение нужно, чтобы превратить «кажется, нас заваливает» в управляемые решения: сколько людей выводить в смены, когда усиливать линию, а когда — наоборот, не держать лишних.
Приложение должно помогать отвечать на практичные вопросы:
Типовой набор болей у саппорта один и тот же.
Перегруз и очереди тикетов приводят к срыву SLA и росту повторных обращений. Простои возникают, когда смены распределены «по привычке», а фактический поток ниже. Наконец, нагрузка часто неравномерна: один канал «горит», другой почти пуст, а общий счетчик обращений не показывает перекос.
Успех приложения измеряется не красотой дашборда, а цифрами: точностью прогноза входящих обращений, долей соблюденного SLA (время первого ответа/решения), а также сбалансированной загрузкой (меньше «пожаров» и меньше простоев).
Чтобы приложение действительно помогало планировать смены, начните не с графиков, а с правильного набора данных. В поддержке важны не «красивые статусы», а последовательность событий во времени и единые справочники, которые не меняют смысл от недели к неделе.
Собирайте обращения из всех входов одинаково — как события, даже если источники разные: почта, чат, форма на сайте, телефон. Для телефона это может быть событие «звонок принят» и «разговор завершен» (или «пропущен»), для чата — «диалог начат/закрыт», для почты и формы — «сообщение получено/тикет создан».
Важно фиксировать канал как атрибут события, а не выводить его из очереди или команды: очереди часто меняются, а канал — это первопричина нагрузки.
Минимальный набор полей, который стоит сделать обязательным:
Дополнительно полезны: статус SLA, причина закрытия, тег «повторное обращение», исполнитель/команда.
Заведите управляемые справочники: команды, очереди, категории, каналы, регионы/языки. Главное правило — изменения справочников должны быть версионируемыми (когда переименовали очередь, прошлые данные не должны менять смысл).
Сразу выберите «истинное время» хранения (обычно UTC) и правила отображения. Отдельно зафиксируйте округление (например, до минуты) и трактовку границ смены, чтобы события на стыке дня не разъезжались в отчётах.
Без качества данные быстро превращаются в шум. Введите:
Эта база позволит дальше честно считать SLA и нагрузку службы поддержки, не споря о том, «что считать обращением».
Чтобы приложение не превратилось в набор разрозненных таблиц, полезно заранее зафиксировать «скелет» данных: какие сущности храним и как они связаны. Это упростит отчеты, прогноз и расчет смен.
Тикет — центральная сущность. Минимальный набор полей:
Важно: SLA лучше хранить как конкретные дедлайны (timestamps), а не только «политику», чтобы корректно считать нарушения при смене правил.
Вместо того чтобы перезаписывать тикет, фиксируйте ленту событий: создание, первый ответ, последующие ответы, перевод между очередями, постановка в ожидание, закрытие/переоткрытие.
Каждое событие обычно содержит: ticket_id, тип события, время, автора (агент или система), а также дополнительные детали (старый/новый статус, из какой очереди в какую перевели).
Так вы сможете честно восстановить путь тикета и посчитать, например, «время до первого ответа» или сколько тикетов зависает в ожидании.
Агент: навыки (языки/продукты), уровень (junior/middle/senior), доступность (график, отпуска, ограничения по часам). Стоимость часа — опционально, но полезно для оценки бюджета.
Смена: время начала/конца, перерывы, правила переработок. Связь обычно такая: одна смена принадлежит одному агенту, у агента — много смен.
Для скорости отчетов храните агрегаты по часу/дню: входящий поток, закрытия, среднее время ответа, SLA%. Отдельно полезны снимки очереди (backlog) — сколько открытых тикетов было на конкретный момент времени.
Эти «снимки» связывают «нагрузку службы поддержки» с реальным планированием смен и помогают объяснять причины провалов SLA.
Планирование смен упирается не в «побольше графиков», а в несколько метрик, которые напрямую отвечают на вопросы: сколько обращений придёт, как быстро команда их разбирает и где образуется очередь. Если выбрать правильный набор, дальше проще строить прогноз и переводить его в численность.
Входящий поток: обращений в час/день с разрезами по каналу (чат, почта, телефон) и категории. Для планирования важна сезонность и пики: будни/выходные, утро/вечер, акции, релизы.
Скорость обработки: не только среднее, но и медиана и хвосты (p90/p95) по времени решения и по времени «чистой работы» агента. Распределения важнее среднего: длинные кейсы «съедают» смену.
Очередь и бэклог: сколько тикетов ожидают и сколько в работе, плюс возраст тикетов. Возраст показывает реальную боль: даже небольшая очередь может быть критичной, если там старые обращения.
SLA: доля ответов/решений в срок, количество просрочек и время до первого ответа. Для смен чаще всего ключевым становится именно первый ответ — он чувствителен к пиковым часам.
Загрузка: занятость агентов и доля времени в продуктивной работе (контакты + оформление результата), отдельно от встреч, обучения и внутренних задач.
Фиксируйте таймзону, единые статусы и правила «стоп/старт» таймеров (например, пауза на ожидании клиента). Сегментируйте метрики по типам обращений: один поток «простых вопросов» и редкие сложные инциденты лучше планировать отдельно.
Не опирайтесь только на средние значения, не смешивайте каналы с разной природой (чат и почта) и не игнорируйте бэклог: он маскирует дефицит смен даже при «нормальном» SLA за день.
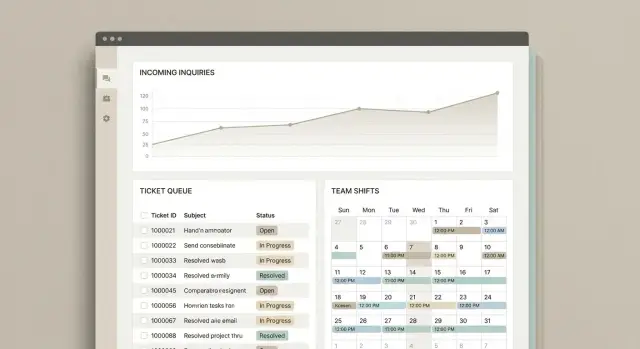
Хороший дашборд для саппорта отвечает на два вопроса: «что происходит прямо сейчас?» и «почему так произошло?». Если он не помогает принять решение за 30–60 секунд, значит, перегружен деталями.
Начните с компактного блока KPI: входящие обращения, закрытые, текущая очередь тикетов, доля просрочек по SLA и медианное время первого ответа/решения. Рядом — «тревоги»: рост очереди относительно среднего, всплеск по конкретному каналу или очереди, риск нарушения SLA в ближайшие часы.
Важно показывать не только число, но и контекст: стрелка тренда, сравнение с прошлой неделей и порог, после которого включается алерт.
Для планирования смен лучше всего работает тепловая карта недели: дни по вертикали, часы по горизонтали, цвет — объем входящих или «активная работа» (новые + переоткрытые + эскалации). Добавьте переключатель:
Так вы быстро находите «горячие» окна и проверяете, совпадают ли они с расписанием.
Фильтры должны быть одинаковыми во всех отчетах: команда, очередь, канал, категория, регион/язык. Лучшее правило — не больше 5–7 фильтров на первом уровне и сохранение состояния в ссылке (чтобы поделиться конкретным срезом).
Любая аномалия (например, рост просрочек) должна раскрываться кликом в список тикетов с причинами: «ожидает клиента», «эскалация», «нет исполнителя», «долго в очереди». Это экономит время на разбор и помогает исправлять процесс.
Для руководителей и смежных команд нужны PDF/CSV и «умные» ссылки на фильтры (например, /reports/load?queue=billing&week=2025-12). Так отчеты легко прикладывать к статусам и ретроспективам, не делая скриншоты.
Прогноз нужен не ради «красивого графика», а чтобы заранее понять: сколько обращений придёт завтра/на выходных/после релиза и где вы рискуете нарушить SLA по времени ответа. Хорошая новость: в большинстве саппортов хватает простых методов, если данные собраны аккуратно.
Начните с ежедневного (или почасового) ряда входящих обращений и посчитайте скользящее среднее за 7–28 дней. Затем добавьте «поправку на день недели»: например, понедельник обычно +20% к среднему, пятница −10%.
Практически это выглядит так:
Такой подход уже даёт прогноз, который удобно объяснить команде и руководству.
Если объём обращений растёт (или падает) неделями, скользящее среднее «отстаёт». Без сложных моделей можно ввести тренд-коэффициент: например, +3% в неделю.
Отдельно полезны ручные коэффициенты под события бизнеса: запуск, акция, изменение тарифа, массовая коммуникация. В приложении это удобно хранить как календарь факторов: дата/период, канал или очередь тикетов, ожидаемое влияние (например, +15%).
Единичные всплески ломают средние. Простое правило: помечать дни как «аномальные» и исключать их из базового расчёта, но сохранять для отдельного сценария «что если повторится». То же с праздниками: лучше вести справочник праздничных дней и использовать отдельные коэффициенты.
Проверяйте прогноз на прошлых периодах (backtesting): строите прогноз «как будто тогда» и сравниваете с фактом.
Простых методов достаточно, если сезонность стабильна и нет резких изменений в продукте. ML имеет смысл, когда появляются сложные зависимости (каналы, типы обращений, маркетинговые активности) и цена ошибки высокая.
Хороший критерий: если после аккуратной работы с сезонностью/трендами точность всё равно «плавает» и прогноз регулярно промахивается на пики — пора усложнять модель.
Прогноз обращений сам по себе не отвечает на главный вопрос: сколько людей нужно поставить в каждый час. Чтобы превратить «N тикетов в сутки» в план смен, достаточно аккуратно перевести спрос в рабочие часы и заложить реальную «жизнь» саппорта — перерывы, вариативность и мультискилл.
Базовая логика простая:
Нагрузка (часы) = прогноз обращений в интервале × AHT.
AHT (Average Handle Time, среднее время обработки) лучше считать по категориям: «платежи», «техпроблемы», «вопросы по тарифу» — у них разная длительность.
Дальше добавьте поправки:
На практике удобно хранить коэффициент: например, если 25% времени «съедают» перерывы и внутренние задачи, то делим доступные часы агента на 0,75.
Даже хороший прогноз ошибается. Добавьте буфер двумя слоями:
Один агент закрывает не все категории. В модели планирования храните матрицу «агент → категории» и распределяйте спрос по навыкам. Тогда «недостача» может быть не по людям в целом, а по конкретной компетенции.
Для каждого часового интервала:
Добавьте переключатель сценариев: +20% обращений, «минус два ключевых агента», «рост AHT на 15%». Это превращает планирование из спора мнений в быстрый расчет и помогает заранее увидеть, где потребуется подменный слот или перераспределение по категориям.
Планировщик смен — это место, где прогноз и расчёт потребности превращаются в понятный календарь: кто, когда и чем занимается. Важно, чтобы он поддерживал не только «расставить людей», но и правила, которые защищают качество обслуживания и самих сотрудников.
Начните с шаблонов: дневные/ночные, короткие смены (например, 4–6 часов), а также перекрытия в пиковые часы. Шаблон описывает длительность, локальное время, обязательные перерывы и «окна усиления» (например, +2 человека с 11:00 до 15:00).
Практика: храните шаблоны как справочник, чтобы планировщик собирал график из кубиков, а не из ручных вводов.
Правила распределения стоит сделать проверяемыми (валидаторами) и объяснимыми. Минимальный набор:
Если правило нарушено, планировщик должен подсветить конфликт и предложить варианты: переставить, добавить перекрытие, заменить сотрудника.
Не все смены одинаковы: на каждой должны быть роли (например, «старший», «чат», «почта», «тех. линия») и требования по навыкам/языкам. В интерфейсе удобно показывать «покрытие компетенций» как индикатор: закрыты ли обязательные роли и не перегружен ли единственный эксперт.
Чтобы график не жил отдельно от реальности, добавьте план‑факт: сравнение запланированного покрытия с реальной загрузкой и фактическими активностями (входящие, ответы, SLA).
Согласование лучше формализовать статусами: черновик → утверждение → публикация. После публикации изменения — только через комментарии и историю правок.
Так проще разбирать, почему в конкретный день «не хватило людей», и улучшать правила, а не искать виноватых.
Оповещения нужны не «для галочки», а чтобы команда успевала вмешаться до того, как пользователи увидят просроченный SLA и «вечную» очередь. Поэтому правила лучше привязывать к понятным сигналам: росту очереди, риску SLA и будущим провалам покрытия.
Начните с 3–5 простых триггеров, которые легко объяснить руководителю и агентам:
Важно: пороги должны отличаться по каналам (почта терпит больше, чат — меньше) и по приоритетам.
Разведите каналы по срочности:
У каждой тревоги должен быть владелец и таймер эскалации: «если не подтверждено за 5 минут — уходит тимлиду; за 10 — руководителю смены».
Вместо абстрактного текста прикрепляйте плейбук: перераспределить очередь, временно снизить приоритет внутренних задач, подключить резерв/подмену, включить шаблоны ответов.
Фиксируйте причину, действия и результат: что сломалось (всплеск, сбой интеграции, недовыход), что сделали, насколько быстро вернули показатели. Этот журнал затем превращается в список улучшений для правил и планирования, а не в поиск виноватых.
Если приложение помогает планировать смены и анализировать нагрузку службы поддержки, оно почти неизбежно касается персональных данных (имена сотрудников, расписание, иногда — данные клиентов из очереди тикетов). Поэтому права доступа и безопасность лучше проектировать сразу, а не «добавить потом».
Базовый набор ролей удобно строить вокруг типовых задач:
Важно разделить «кто видит» и «кто меняет»: права на просмотр отчетов и права на изменение смен/коэффициентов прогноза должны настраиваться отдельно.
На практике нужна изоляция по командам/очередям (например, линия 1/линия 2/премиум‑поддержка) и по чувствительным полям. Хороший минимум:
Для доверия к плану смен нужен журнал аудита: кто менял смены, правила, коэффициенты прогноза, справочники и интеграции; когда; что было/стало. Это ускоряет разбор конфликтов и помогает при проверках.
Заранее задайте сроки хранения: оперативные данные — дольше, сырьевые события — короче. Если требования строгие, добавьте псевдонимизацию/анонимизацию (например, хранить идентификаторы вместо ФИО) и политику удаления по запросу.
Минимальный набор «из коробки»: 2FA, принцип наименьших прав, шифрование секретов интеграций, регулярные резервные копии с проверкой восстановления и отдельный доступ к админ‑функциям. Это дешевле внедрить на старте, чем исправлять после инцидента.
Чтобы расчет нагрузки и планирование смен не превращались в ручную сводку, приложению нужны надежные интеграции: с helpdesk (тикеты, статусы, SLA) и с HR/учетом времени (смены, отпуска, больничные). Главная цель архитектуры — получать данные вовремя, не терять события и уметь переиграть загрузку без «дублей».
Лучше поддерживать два режима одновременно.
Практика: все входящие события складывайте в «сырой» журнал (inbox), а обработку делайте асинхронно — так проще выдерживать пики.
Интеграция с HR важна не меньше: без нее нельзя корректно посчитать доступную емкость команды. Минимальный набор — календарь смен, плановые отсутствия и фактические корректировки (замены, отгулы). Если источников несколько (HR + табель), заранее определите «источник истины» по каждому полю.
Загрузки делайте по расписанию (например, каждые 5–15 минут) и закладывайте:
Для приложения удобна транзакционная БД (пользователи, настройки, права, интеграции) и отдельная витрина для аналитики (агрегации по часам/дням, SLA, нагрузка по очередям). Это ускоряет отчеты и упрощает масштабирование.
Если вы хотите быстро собрать такой каркас (React‑интерфейс, API, PostgreSQL‑хранилище, роли/права, аудит и базовые отчеты) без долгого разгона команды, удобно начать с TakProsto.AI: в формате чата можно описать сущности и сценарии (тикеты, события, смены, алерты), включить режим планирования и получить рабочий прототип, который затем дорабатывается и при необходимости выгружается как исходный код.
Сразу заложите наблюдаемость: метрики задержки данных (lag), долю пропущенных событий, ошибки авторизации к API, рост очереди обработки. Простое правило: если данные «старше N минут» или полнота ниже порога — показывайте предупреждение в интерфейсе и отправляйте оповещение ответственным.
Запуск такого веб‑приложения лучше делать итеративно: сначала — минимально полезная версия, затем пилот, калибровка и расширение. Так вы быстрее получаете доверие команды и избегаете «большого взрыва», когда всё сложно, но никому не помогает.
На первом шаге ограничьтесь:
Ключевой критерий MVP: по нему можно принять решение «нужно ли усиливать смену» и проверить это на факте.
Если задача — ускорить путь от требований к MVP, TakProsto.AI помогает собрать первую версию быстрее за счет вайб‑кодинга: вы описываете логику (формулы AHT/shrinkage, пороги алертов, статусы согласования), а платформа генерирует приложение и позволяет делать снимки состояния с откатом, чтобы безопасно пробовать изменения правил.
Выберите одну линию/группу, где есть понятные правила и стабильный поток. Заранее задайте критерии успеха: например, снижение просрочки SLA, уменьшение очереди в часы пик, меньше переработок.
Собирайте обратную связь короткими циклами (раз в неделю): что непонятно на дашборде, каких фильтров не хватает, где цифрам не верят и почему.
После пилота обычно приходится настроить «ручки»: AHT по типам обращений, коэффициент буфера на перерывы/невыходы, правила тревог (когда и кому слать оповещения). Важно фиксировать изменения как версии настроек — тогда проще объяснять, почему план «вчера и сегодня» отличается.
Сделайте короткие инструкции на 5–7 минут: «как посмотреть нагрузку», «как понять, что смену надо усилить», «что делать при тревоге». Лучше в виде чек‑листов прямо в приложении.
Когда MVP стабилен, планируйте развитие: мультиканальность (почта/чат/телефония), мультискилл (разные компетенции в одной смене), более точный прогноз (разделение по темам и источникам), и аккуратная автоматизация рекомендаций по усилению смен.
Для прозрачности ведите публичный список улучшений, например на странице /roadmap.
Начните с решений, которые нужно поддержать:
Затем зафиксируйте минимальный набор данных: события по тикету (создание, первый ответ, закрытие), канал, приоритет, дедлайны SLA, агенты и смены.
Потому что статусы часто меняются и «перезаписываются», а события дают честную хронологию. На событиях вы сможете:
Это база для прогнозирования и расчета потребности в людях.
Минимум, который лучше сделать обязательным:
Без этих полей расчеты SLA и нагрузки будут «плыть».
Справочники (каналы, очереди, команды, категории) должны быть управляемыми и версионируемыми:
Так метрики останутся сопоставимыми неделя к неделе.
Выберите «истинное время» хранения (часто UTC) и строго зафиксируйте:
Иначе события на стыке дней будут «разъезжаться», и отчеты по часам станут недостоверными.
Вам нужен набор, который напрямую влияет на план смен:
Старайтесь не опираться только на средние значения.
Простой и объяснимый вариант:
Обязательно исключайте аномальные дни из базового расчета, но храните их для сценариев «что если повторится».
Переведите прогноз в рабочие часы:
Так получите потребность по каждому часовому интервалу.
Сделайте планировщик «из кубиков»:
Это снижает ручной труд и делает график объяснимым.
Минимальные практики безопасности и управляемости:
Так вы защитите данные и повысите доверие к плану смен.