Пошаговый план, как спроектировать и сделать веб‑приложение для локализации: роли, хранение строк, редактор, интеграции с Git/CI, QA и релизы.
Это веб‑приложение для локализации нужно, чтобы превратить переводы из набора разрозненных файлов и переписок в управляемый процесс: кто и что перевёл, что готово к релизу, где есть проблемы и как быстро доставить обновления в продукт.
Важно сразу зафиксировать границы: в этой статье речь про управление строками и переводами и их поставку в продукт. Вне фокуса — полноценный CAT‑редактор «как у бюро переводов» и управление контентом сайта (CMS).
i18n (internationalization) — это подготовка продукта к нескольким языкам и форматам: отделение строк от кода, поддержка локалей, форматирование дат/валют, правила множественного числа, RTL‑языки и т. п.
l10n (localization) — это наполнение подготовленной системы конкретными переводами и адаптациями под рынок: тексты, терминология, тон, юридические формулировки, иногда — скриншоты и контекст.
Наш продукт про управление l10n‑процессом, но он обязан «понимать» i18n‑ограничения (плейсхолдеры, ICU, длины строк). Иначе переводы будут ломать интерфейс, а команда будет тратить время на ручные правки и откаты.
Команде продукта — чтобы управлять приоритетами и релизами. Разработчикам — чтобы не править строки вручную и уменьшить количество конфликтов. Переводчикам и редакторам — чтобы видеть контекст и единые термины. QA — чтобы быстро находить ошибки до выкладки.
Успех измеряется не количеством функций, а метриками процесса:
Хорошая система переводов начинается не с кнопок, а с понимания, кто и зачем будет ею пользоваться. Роли стоит проектировать так, чтобы каждому было «быстро и безопасно» выполнять свою часть работы, а ответственность была прозрачной.
Для разработчиков ключевое — управлять ресурсами переводов без ручной возни.
Им нужны: импорт/экспорт файлов (JSON/YAML/PO и т. п.), предсказуемая структура путей и быстрый цикл «внёс изменения → открыл PR → получил обновлённые переводы». Полезны подсказки при добавлении новых ключей (например, пометка «нужны переводы») и возможность подтянуть изменения обратно в репозиторий одним действием.
Переводчику важны скорость и контекст — без них качество неизбежно падает.
Встроенный редактор должен поддерживать: просмотр контекста (скрин/описание, где строка используется), поиск по ключам и тексту, проверку плейсхолдеров, а также горячие клавиши для навигации и массовых действий. Отдельный плюс — видеть похожие строки и предложения, но подтверждать результат явно.
Эта роль превращает переводы в управляемый процесс.
Нужны статусы (черновик → на проверке → готово), дедлайны, назначение задач по локалям/модулям и простые отчёты: сколько строк в работе, где блокеры, что просрочено. Удобно, когда менеджер может «заморозить» релизный срез и контролировать, что уходит в сборку.
QA смотрит на риски и регрессии: сломанные плейсхолдеры, переполнение интерфейса, несогласованные термины, ошибки формата.
Обычно QA нужен отдельный режим: список проверок, фильтры по типам проблем, повторные прогоны после правок и журнал «кто и когда исправил строку». Это снижает вероятность, что проблема «уедет» в релиз и будет ловиться уже пользователями.
Чтобы система переводов была предсказуемой и удобной для команды, важно с самого начала описать «скелет» данных. Хорошая модель данных снижает количество конфликтов, упрощает импорт/экспорт форматов и делает поиск по проекту быстрым.
Базовая структура обычно выглядит так:
Проект — контейнер продукта или набора продуктов. Внутри проекта хранится список Locale (например, ru-RU, en-US) и набор «файлов» (часто это логические namespaces, например common, checkout, errors). Такая привязка помогает повторять структуру исходного репозитория и не смешивать строки из разных частей интерфейса.
Практичный минимальный набор:
StringKey в конкретной Locale. Здесь же: текст, метаданные, статус, ссылки на проверки.marketing, legal, mobile), чтобы фильтровать и собирать отчёты.Удобно иметь понятные статусы: черновик → на проверке → подтверждено, а также устарело (например, когда исходная строка изменилась). Статус — это не «косметика», а основа для workflow локализации: кто что делает, что можно выгружать в релиз, а что ещё нельзя.
Каждая правка должна оставлять след: кто изменил, когда, что было до/после и почему (не обязательно подробно, но хотя бы ссылка на Comment или Issue). История изменений и авторство правок помогают:
На уровне схемы это часто реализуется как журнал событий (audit log) или версионирование записей Translation и StringKey с хранением предыдущих значений.
Правильное хранение переводов — это баланс между удобством для команды, прозрачностью изменений и скоростью работы приложения. На практике почти всегда выбирают один из трёх подходов: база данных, репозиторий или гибрид.
Только в БД удобно для веб‑интерфейса: быстрый поиск, фильтры, массовые операции, история правок «из коробки». Но появляется отдельный источник истины, а выгрузка в репозиторий становится отдельным шагом.
Только в репозитории (Git) делает разработку простой: переводы рядом с кодом, есть знакомые механики ревью и веток, легко откатиться. Минусы — сложнее строить удобный веб‑поиск, тонкая настройка прав доступа обычно ограничена, а массовые правки могут превращаться в «шум» в diff.
Гибридный вариант чаще всего самый практичный: в БД живёт рабочее состояние (редактирование, статусы, комментарии), а в Git регулярно публикуется «снимок» файлов локалей. Важно заранее определить, кто «главный»: БД (и Git — экспорт) или репозиторий (и БД — индекс/кэш).
Минимальная единица истории — ревизия перевода: кто изменил строку, когда, старое/новое значение, причина. Отдельно полезно версионировать состояние ключа (создан, переименован, устарел). Переименование лучше хранить как связь «старый ключ → новый ключ», чтобы не терять историю и облегчать автоматические миграции.
Если БД — источник истины, настройте ежедневные бэкапы, проверку восстановления на тестовом стенде и хранение нескольких точек во времени. Для Git‑подхода критично иметь защищённые удалённые реплики и понятный процесс отката релиза. В гибриде восстанавливать нужно оба слоя: БД (история/статусы) и репозиторий (публикуемые файлы), с чётким правилом, что считать актуальным после инцидента.
Хороший UX в системе переводов решает две задачи одновременно: ускоряет работу (меньше кликов, меньше ошибок) и делает процесс предсказуемым для разных ролей — менеджера локализации, переводчика, редактора и разработчика. Ниже — набор экранов и паттернов, которые обычно дают максимальный эффект.
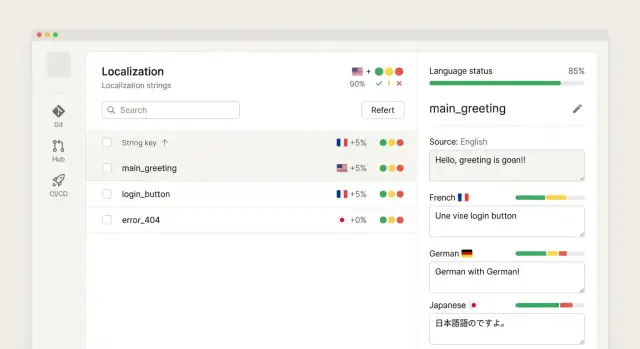
Главный рабочий экран — таблица ключей с быстрым поиском и понятными фильтрами. Здесь пользователь не «бродит по проекту», а сразу видит, что нужно сделать.
Сделайте фильтры первоклассными:
Добавьте группировку по namespace/файлам, теги, сортировку по приоритету и возможность сохранить наборы фильтров («Мои очереди»).
Редактор должен поддерживать множественные локали в одном окне (например, базовая + целевая + справочная), а также массовые операции: применить ко всем, копировать из базовой, заменить подстроку, подтвердить/отклонить пакет.
Обязательные UX‑детали:
Контекст должен быть доступен прямо в редакторе, а не жить отдельным «архивом».
Покажите:
Так вы снижаете число уточняющих вопросов и правок после релиза.
Переводы редко делаются «сами по себе» — обычно это часть релиза. Нужен экран задач: назначение, дедлайны, чек‑листы по локалям и комментарии на уровне ключа и задачи.
Полезно связывать задачу с набором ключей и показывать прогресс (например, 120/200 переведено, 15 с ошибками QA). Для навигации между задачами и строками добавьте короткие ссылки формата /projects/{id}/tasks/{id}.
Чтобы система переводов была удобной для разных команд, важно поддержать популярные форматы и при этом не «сломать» строки при импорте/экспорте. Пользователь должен видеть ровно то, что попадёт в репозиторий и в продукт.
Базовый набор обычно включает JSON и YAML для веб‑приложений, PO для gettext‑экосистемы, XLIFF для обмена с бюро переводов и CAT‑инструментами, CSV — для быстрых правок в табличном виде.
Ключевое требование: корректный парсинг и сериализация без неожиданной нормализации (например, чтобы YAML не менял типы или кавычки там, где это критично). Для PO и XLIFF важно сохранять контекст и комментарии, потому что они напрямую влияют на качество перевода.
Хорошее правило: ключи читаемы и стабильны. На практике работают неймспейсы вида checkout.payment.title или errors.network.timeout. В интерфейсе полезно подсвечивать «плохие» ключи (с пробелами, случайными UUID, смешением стилей) и предлагать авто‑переименование с безопасной миграцией.
Строки часто содержат переменные: {name}, %s, {{count}}. Система должна валидировать совпадение плейсхолдеров между исходной строкой и переводом и показывать понятные подсказки переводчику.
Для plural forms важно не только хранить варианты, но и подсказывать правила для локали (например, для русского — несколько форм). Ошибка в plural обычно приводит к багу в UI, поэтому лучше блокировать публикацию строк с некорректными формами.
При импорте/экспорте стоит сохранять порядок ключей, комментарии разработчика и «контекст» (например, описание, где используется строка). Это снижает шум в Git‑диффах и помогает переводчикам понимать смысл. Дополнительно полезны режимы: «мягкий импорт» (только новые/изменённые) и «строгий импорт» (с удалением устаревших ключей по правилам проекта).
Система переводов почти всегда работает с продуктовой информацией, ещё не вышедшей в релиз: названия функций, маркетинговые тексты, юридические формулировки. Поэтому управление доступами и аудит — не «доп. опция», а базовая часть доверия к платформе.
Минимум — вход по почте с подтверждением и строгими правилами паролей. Для компаний удобнее SSO (например, через корпоративного провайдера), чтобы быстро подключать и отключать сотрудников.
Если в проектах есть чувствительные данные (финтех, медицина, закрытые релизы), включайте 2FA хотя бы для админов и менеджеров проекта. Дополнительно стоит поддержать сессии с ограничением времени и принудительный выход при смене пароля.
Права лучше выдавать не «в целом по аккаунту», а по проектам и локалям. Практичный набор ролей: владелец, админ, менеджер локализации, переводчик, редактор/ревьюер, наблюдатель (только чтение).
Матрица прав должна явно отвечать на вопросы:
Аудит‑лог нужен, чтобы понимать «кто и что изменил» и быстро расследовать инциденты. Полезно хранить: пользователя, время, проект/локаль/ключ, старое и новое значение, источник изменения (UI, API, импорт), а также correlation ID для цепочек действий.
Шифруйте данные «в пути» (TLS) и «на диске», а секреты (токены интеграций, ключи API) храните отдельно от основной БД в секрет‑хранилище. Применяйте принцип минимальных привилегий: доступы выдаются только тем, кому они нужны, и регулярно пересматриваются (например, раз в квартал).
Интеграция с Git превращает систему переводов из «отдельного сервиса» в часть обычного процесса разработки. В идеале переводные ресурсы живут рядом с кодом, а изменения проходят через те же практики: ветки, ревью и автопроверки.
Самый понятный сценарий — система создаёт Pull Request с изменёнными файлами локалей (например, locales/ru.json, locales/de.yaml). В PR видно диффы, можно назначить ревьюеров (разработчика, локализатора, владельца продукта), а после мержа изменения автоматически попадают в релизный поток.
Чтобы не возникало конфликтов, важно договориться о правилах:
main);CI должен гарантировать, что локализация не ломает продукт. Типовой набор проверок:
Webhooks удобны для событий «появились новые строки», «переводы обновлены», «PR создан/смёржен». Дальше можно слать уведомления в почту/мессенджер или запускать внутренние джобы (например, пересчёт статистики).
Часто используют гибрид: push через PR для продакшена и pull для тестовых окружений.
QA в системе переводов — это не «финальная проверка перед релизом», а набор постоянных правил, которые помогают ловить ошибки рано и не тратить время на бесконечные правки. Хорошо настроенный контроль качества снижает число багов в интерфейсе и конфликтов между разработкой, переводчиками и редакторами.
Автопроверки должны срабатывать сразу при сохранении строки и перед экспортом/отправкой в Git. Минимальный набор:
{name}, %d, {{count}}), включая регистр и порядок, если это важно.Подключите проверку орфографии по локалям и проверку терминов по глоссарию. Практичный подход — не блокировать сохранение из‑за спорных случаев, а выдавать подсказки и пометки «требует внимания».
Для терминов полезно различать:
Когда исходный текст меняется, перевод должен автоматически помечаться как устаревший (stale) и уходить в отдельный статус. Важно хранить историю изменений исходника, чтобы переводчик видел, что именно изменилось, а не перепереводил строку «вслепую».
Сделайте понятную очередь: «Новые переводы» → «На ревью» → «Принято/Отклонено». Правила принятия стоит формализовать: обязательное прохождение автопроверок, отсутствие stale‑меток, соблюдение глоссария, плюс комментарий ревьюера при отклонении. Это превращает QA в повторяемый процесс, а не в спор вкусов.
Глоссарий и память переводов (Translation Memory, TM) — два инструмента, которые заметно ускоряют локализацию и помогают удерживать единый язык продукта. Глоссарий отвечает за «как правильно называть вещи», а TM — за «как мы уже переводили похожие строки».
Глоссарий лучше хранить на уровне проекта и локали, с возможностью переопределений для конкретных продуктов. Для каждого термина полезно фиксировать:
Например, «Workspace» может быть утверждён как «Рабочее пространство», а «Рабочая область» — запрещена, если это путают с другой сущностью. В интерфейсе удобно показывать карточку термина прямо рядом со строкой, чтобы переводчик не искал правила по разным документам.
TM хранит пары «исходная строка → перевод» и предлагает подсказки для новых строк. Практический минимум — поиск совпадений:
Важно не подставлять fuzzy автоматически: лучше предлагать как подсказку с подсветкой различий, чтобы переводчик быстро отредактировал.
Помимо терминов, стоит завести гайд по стилю: форматы дат/времени, валюты, правила обращения на «вы/ты», использование кавычек («ёлочки» vs ""), пробелы перед единицами измерения и т. п. В интерфейсе это можно оформлять как «правила локали» и показывать при проверке строк.
Чтобы термины не менялись хаотично, добавьте короткий workflow:
предложение нового термина или изменения (с причиной и примерами),
согласование с продуктом/редактурой,
публикация в глоссарий и автоматическая пометка затронутых строк.
Так глоссарий становится источником истины, а TM — ускорителем, который не разрушает смысл и стиль.
Хорошая система переводов — это не только хранение строк, но и предсказуемый процесс: кто и когда берёт задачу, что считается «сделано», где видно, что блокирует релиз. Чем меньше ручной координации в чатах и таблицах, тем стабильнее выпуск версий.
Опишите базовый workflow локализации как набор состояний: «Новые строки» → «В работе» → «На проверке» → «Готово» → «В релизе». Переходы должны быть понятны всем ролям: автор контента добавляет строки и контекст, переводчик переводит, редактор проверяет стиль и термины, владелец продукта решает спорные места.
Поддержите комментарии и упоминания прямо на уровне ключа/строки — это снижает потери контекста и ускоряет согласование.
Уведомления должны помогать действовать, а не отвлекать. Обычно достаточно четырёх типов:
Дайте пользователю настройки частоты и каналов (внутри приложения, email, webhook), а также «тихий режим» для команд, которые работают спринтами.
Дашборд должен отвечать на три вопроса: сколько готово, что блокирует, успеваем ли к сроку. Практичные метрики: покрытие переводами по локалям (% готовых строк), количество строк «на проверке», список блокеров (например, нет контекста или термин спорный), скорость перевода (строк/день) и прогноз даты завершения.
SLA лучше измерять по понятным событиям: время реакции на новые строки, время до первого перевода, время до закрытия замечаний. Дедлайны связывайте с релизными вехами (например, «заморозка строк» за N дней до выкладки), чтобы не ломать процесс постоянными «срочно».
Руководству и смежным командам часто нужен простой артефакт: PDF/CSV с прогрессом по локалям, списком рисков и датой прогнозного завершения. Добавьте запланированную отправку отчётов и ссылку на живой статус в приложении (например, /reports), чтобы меньше тратить времени на ручные сводки.
Первая версия веб‑приложения для локализации должна закрывать базовый цикл «добавили строку → перевели → выгрузили», не превращаясь в комбайн. Минимальный набор обычно выглядит так:
Следующий шаг — снять основные боли команд:
Интеграции: синхронизация с Git (PR/коммиты), триггеры в CI/CD, чтобы переводы обновлялись предсказуемо.
QA переводов: проверки плейсхолдеров, длины строк, запрещённых слов, единообразия терминов.
Глоссарий и память переводов: подсказки, автозаполнение похожих строк, согласование терминов на уровне продукта.
Масштабирование: несколько сред (dev/stage/prod), ветки/версии, производительность на больших объёмах.
Конфликт ключей решается правилами нейминга и блокировками/проверками при импорте. Потерю контекста снижайте превью экранов, комментариями и ссылками на фичу прямо в карточке строки. «Разъезд» версий лечится версионированием и дисциплиной: чётко фиксировать, откуда приходят исходники и куда уходит экспорт.
Отдельный практический совет по реализации: такой сервис удобно сначала собрать как рабочий прототип, проверить workflow на реальных проектах, а уже потом «допиливать» роли, интеграции и QA. Например, на TakProsto.AI можно быстро собрать веб‑интерфейс каталога ключей и редактора переводов (React), API и фоновые задачи (Go) и хранение в PostgreSQL — через чат, с Planning Mode для проработки модели данных, статусов и интеграций. Плюс есть снапшоты и откат, экспорт исходников, деплой и хостинг на серверах в России — это помогает быстрее пройти путь от идеи до пилота в команде.
Если нужно глубже погрузиться в практики локализации, загляните в /blog. Для оценки затрат и вариантов внедрения уместно посмотреть /pricing.
i18n — это подготовка продукта к нескольким языкам и форматам: отделение строк от кода, правила множественного числа, форматирование дат/валют, поддержка RTL и т. п.
l10n — это управляемый процесс наполнения переводами и адаптациями под рынок: тексты, терминология, тон, юридические формулировки.
Практика: приложение для l10n должно «понимать» i18n-ограничения (плейсхолдеры, ICU, plural), иначе переводы будут ломать интерфейс.
Обычно выделяют несколько ролей и под них проектируют права и интерфейсы:
Чем яснее границы ответственности, тем меньше «ручной координации» в чатах.
Практичный минимум для предсказуемой работы:
Рабочая схема статусов помогает строить очередь задач и понимать, что можно выпускать:
Рекомендация: блокируйте экспорт в релиз для переводов со статусом и с критическими QA-ошибками — это резко снижает риск поломок в продукте.
Выбор обычно один из трёх:
Главное — заранее договориться, где , и что делать при конфликтах/инцидентах.
Минимальный набор автопроверок, которые стоит запускать при сохранении и перед экспортом:
Базовый набор, который закрывает большинство кейсов:
Важно: при импорте/экспорте избегайте «неожиданной нормализации» (порядок ключей, кавычки, типы в YAML) и старайтесь сохранять комментарии и контекст — это уменьшает шум в Git-диффах.
Самый прозрачный сценарий — система создаёт PR с обновлёнными ресурсами локалей.
Рекомендуемые элементы интеграции:
Минимум, который обычно ожидают от платформы:
MVP должен закрывать цикл «добавили строку → перевели → выгрузили»:
Дальше по ценности обычно идут:
Важно сразу заложить быстрый поиск по ключам, локалям и статусам — это основа производительности UX.
Практика: критические ошибки (плейсхолдеры/plural/валидность файла) лучше делать блокирующими для публикации.
Выбор модели:
Практика: принцип минимальных привилегий + регулярный пересмотр доступов снижает риски утечек и ошибок.
Так вы избегаете «комбайна» в первой версии и быстрее получаете измеримый эффект по скорости и качеству.