Пошаговый план, как спроектировать веб‑приложение для ценовых экспериментов: цели, данные, варианты цен, рандомизация, метрики, аналитика и безопасность.
Ценовые эксперименты — это управляемые проверки гипотез о цене: мы меняем цену (или формат предложения) для части аудитории и сравниваем результаты с контрольной группой. Отдельный инструмент нужен, потому что цена затрагивает выручку, маржу, доверие клиентов и работу поддержки — здесь важны дисциплина, прозрачность и воспроизводимость, а «табличек и чатов» быстро становится недостаточно.
Приложение для ценовых экспериментов помогает пройти весь цикл без хаоса:
Итог для команды — меньше ошибок, быстрее согласования и понятная связь между изменением цены и финансовым эффектом.
Самые частые кейсы выглядят так:
Важно, чтобы каждый сценарий фиксировал: где показывается цена, когда она применяется (в карточке, корзине, в счёте), и что считается конверсией.
Инструмент нужен продукту (гипотезы и UX), маркетингу (офферы), финансам (маржа и риск), аналитикам (методология и метрики), поддержке (объяснения клиентам и исключения).
При этом это про управление экспериментами: кто в каком варианте, какие правила, какие выводы. Это не система динамического ценообразования в реальном времени и не «движок оптимизации цен» — такие задачи обычно требуют другой архитектуры и иных контуров контроля.
Приложение для ценовых экспериментов полезно ровно настолько, насколько чётко определены цели и «правила игры». Без этого тест легко превращается в спор мнений: данные есть, но никто не понимает, что считать успехом и когда остановиться.
Начните с одной основной цели и 1–2 ограничителей. Типовые варианты:
Сразу договоритесь, что важнее при конфликте метрик: допустим, выручка растёт, но маржа падает — это победа или провал?
Гипотеза должна связывать изменение цены с измеримым эффектом и контекстом:
«Если повысить цену на план Pro на 5% для новых пользователей, то ARPA вырастет минимум на 2% за 14 дней без роста отмен выше 0,3 п.п.»
Заранее задайте:
Выбор единицы — ключ к честному сравнению:
Зафиксируйте в приложении и в процессе:
Опишите роли и полномочия: кто утверждает запуск, кто может поставить на паузу, кто финально принимает решение о раскатке. Удобный шаблон — RACI: ответственный, согласующие, консультируемые, информируемые.
Практика: фиксируйте решение прямо в карточке эксперимента (дата, причина, ссылка на отчёт), чтобы через месяц не возвращаться к дискуссии заново.
Правильная модель данных — фундамент ценовых экспериментов: она должна одинаково хорошо «понимать» каталог, биллинг и аналитику, а ещё выдерживать параллельные тесты без путаницы. Ниже — минимальный набор сущностей и ключевые поля, которые стоит заложить сразу.
Продукт/план (Product) — то, что вы продаёте: товар, подписка, тариф, пакет услуг.
Вариант цены (PriceVariant) — конкретная цена и правила её отображения. Обычно один продукт имеет несколько вариантов цены (например, контрольная и тестовая).
Эксперимент (Experiment) — описание теста: что меняем, когда, на кого и как распределяем.
Аудитория (Audience) — набор правил, по которым пользователь попадает в эксперимент (гео, платформа, сегмент, новый/старый, канал и т. п.).
События (Events) — факт взаимодействия: показ цены, добавление в корзину, покупка, возврат, апгрейд/даунгрейд. Эти события связывают эксперимент с метриками.
Типовые связи:
Чтобы не «потерять» сущности при интеграциях, у каждой записи должны быть стабильные внешние ключи:
catalog_product_id — ID товара/плана в каталогеbilling_price_id / billing_plan_id — ID цены/плана в биллингеexperiment_key — человекочитаемый ключ теста (например, pricing_q1_annual), удобен для аналитики и логовПрактика: храните внутренний UUID + внешние идентификаторы. Внутренний UUID нужен для миграций и независимости, внешние — для склейки с системами.
Цена — это не просто число. Важно понимать, кто и почему поменял её, особенно если результаты эксперимента позже «не сходятся».
Минимально:
PriceVariantVersion): price_variant_id, amount, currency, tax_mode, rounding_rule, display_rules, valid_from, valid_toAuditLog): entity_type, entity_id, changed_by, changed_at, change_reason, diff полейТак вы сможете восстановить картину: какая цена была показана пользователю в конкретный день и с какими правилами.
Частые ошибки возникают не в расчётах, а в деталях:
currency отдельно от суммы, используйте целые значения в «минимальных единицах» (копейки/центы), чтобы избежать ошибок округления.tax_included/tax_excluded) и ставку/правило расчёта, иначе сравнение выручки будет некорректным.Заложите механизм, который предотвращает ситуацию, когда один пользователь одновременно попадает в два теста, меняющих одну и ту же цену.
На уровне модели данных это обычно решается так:
scope (например, product_id + тип воздействия price) и priorityprice_variant_idExperimentConflictRule) или простое ограничение: в один момент времени активен только один эксперимент на продукт в данном scopeЭта дисциплина в данных упростит всё дальше: назначение вариантов, сбор событий и отчёты. Если хотите глубже про то, как это реализовать в логике назначения, см. раздел про рандомизацию и конфликты в /blog/price-experiments-randomization.
Хороший интерфейс для ценовых экспериментов — это не «красота», а способ снизить число ошибок и ускорить согласования. Здесь важнее всего: понятные роли, единая карточка эксперимента и прозрачный след действий.
Чтобы не усложнять доступы на старте, обычно достаточно четырёх ролей:
Права лучше задавать не «по страницам», а по действиям: кто может менять вариант цены, кто может запускать, кто может подтверждать завершение.
Карточка должна быть шаблонной и предсказуемой — чтобы по ней можно было принять решение без переписок в мессенджерах:
Добавьте блок «Риски и допущения» — он часто экономит недели споров после запуска.
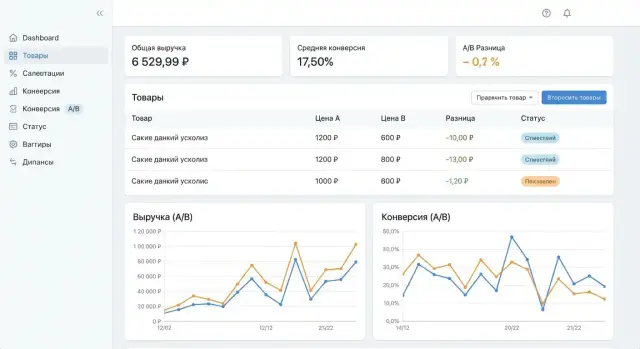
В списке экспериментов важны не только названия. Минимальные колонки:
Такой список работает как «пульт управления» и помогает быстро найти эксперименты, требующие внимания.
Нужны две сущности: автоматический журнал (кто, что, когда изменил) и комментарии (почему решили так). В карточке эксперимента держите историю изменений параметров, запусков/остановок и подтверждений — это упрощает аудит и разбор инцидентов.
Интерфейс должен предупреждать до запуска:
Лучший UX здесь — не «ругаться», а объяснять: что именно не так, чем это грозит и как исправить.
Правильное назначение вариантов — основа честного ценового эксперимента. Если пользователи «прыгают» между ценами или один и тот же товар одновременно участвует в разных тестах, результаты начинают отражать шум, а не влияние цены.
Чаще всего для цены нужна стабильная привязка: один и тот же человек должен видеть один и тот же вариант на протяжении всего эксперимента.
account_id.user_id (например, после регистрации).Практика: храните назначение в таблице «назначения» и вычисляйте вариант детерминированно (например, по хэшу ключа назначения). Тогда даже при сбоях и масштабировании вы не потеряете стабильность.
Главное правило: если пользователь авторизовался, используйте серверный ключ (аккаунт/пользователь), а не устройство.
Типовой подход:
user_id/account_id и сохраняйте серверное назначение.Если бизнес-результат сильно зависит от признаков (регион, тариф, канал, тип клиента), добавьте стратификацию: сначала разделите аудиторию на слои, затем рандомизируйте внутри каждого слоя.
Примеры слоёв:
Это снижает риск, что «случайно» в одном варианте окажется больше дорогих регионов или более платёжеспособных клиентов.
В приложении стоит предусмотреть правила исключений:
Исключения должны применяться до назначения вариантов и логироваться, чтобы было понятно, почему пользователь не попал в тест.
Нужен механизм, который не даст двум экспериментам одновременно управлять ценой одного товара на одном экране.
Хорошая модель — «единица конфликта» (например, product_id + surface), где surface — контекст показа (карточка товара, корзина, страница оплаты).
Правила:
Так вы сохраняете интерпретируемость результатов и избегаете ситуаций, когда пользователи видят комбинации цен, которых не было в дизайне эксперимента.
Ценовой эксперимент живёт или умирает на данных. Если события собираются неполно, а метрики трактуются по‑разному, вы получите «красивый» отчёт и неправильное решение.
Минимальный набор событий лучше зафиксировать до запуска и не менять в середине эксперимента:
Важно: в каждом событии должны быть единый идентификатор пользователя (или устройства) и идентификатор эксперимента/варианта. Это убирает «серые зоны», когда продажа есть, а к варианту она не привязана.
Собирайте метрики, которые отражают и спрос, и экономику:
Не ограничивайтесь «сегодняшними» цифрами. Делайте срезы по окнам день/неделя, а для подписок и повторных покупок — когортный анализ (по дате первого назначения варианта или первой покупки).
Заведите короткий «словарь метрик»: формула, источники событий, фильтры (налоги/доставка включены или нет), правила округления, валюта, часовой пояс. Это документ, на который ссылаются и продукт, и аналитика, и финансы — иначе команда будет спорить не о цене, а о том, что считать выручкой.
Отчёт по ценовому эксперименту должен отвечать на вопрос: «что будет с бизнес‑метриками, если мы закрепим этот вариант цены?». Для этого важно заранее договориться о формуле эффекта, способе оценки неопределённости и правилах «остановки» теста.
В отчёте показывайте эффект в двух видах:
Рядом с точечной оценкой выводите доверительный интервал (например, 95%). Он помогает отличать «эффект похож на ноль» от «эффект стабильно положительный». Практично также показывать вероятность «хуже контроля» (risk of loss) — её легко понять даже без статистического бэкграунда.
Частая ошибка — смотреть на результаты каждый день и «побеждать» при первом же зелёном числе.
Что фиксировать заранее:
Если вы делаете MVP, можно упростить: не строить сложные модели, а строго соблюдать предзаданные метрики и сроки и не менять их по ходу.
В MVP допустим «пороговый» подход: заранее задать минимальный объём наблюдений на вариант (например, N заказов или N уникальных пользователей) и минимальную длительность (например, 2 полных недели), чтобы пройти сезонность по дням недели. Позже можно добавить полноценный калькулятор мощности и MDE.
Сегментные разрезы делайте как отдельные вкладки, чтобы не смешивать выводы:
Важно: сегменты трактуйте как диагностику. Решение о выкатывании лучше принимать по основной метрике на всей аудитории, а сегменты использовать для поиска причин и уточнения гипотез.
Хороший отчёт содержит не только таблицу, но и графики:
Такой набор делает результаты объяснимыми для бизнеса и снижает риск ошибочного «победителя».
Запуск — это не кнопка «включить», а управляемый процесс с понятными статусами, правилами остановки и ритуалами после завершения. Чем чётче вы формализуете этот цикл, тем меньше шансов «поймать» неверный вывод из‑за багов, интеграций или случайных всплесков спроса.
Удобная схема статусов помогает команде понимать, что можно менять, а что уже зафиксировано:
Важно: в статусе «Запущен» разрешайте только безопасные правки (например, текст описания), а изменения, влияющие на эксперимент (варианты, аудитории, рандомизация), — только через паузу и новую версию.
Чтобы не зависеть от выкладки, используйте фичефлаги или конфигурацию цен в каталоге/прайс‑сервисе. Принцип простой: приложение экспериментов публикует «какой вариант кому показывать», а продуктовый контур читает это как конфиг.
Это снижает риск: вы запускаете/ставите на паузу эксперимент операционно, без срочных релизов и без «горячих» правок.
Мониторинг должен ловить два класса проблем: бизнес‑аномалии и технические сбои.
Настройте оповещения:
Правила остановки зафиксируйте заранее:
Перед запуском: цель и критерии успеха, список метрик и «стоп‑сигналов», аудитория и исключения, проверка отображения цен, тест назначения вариантов, план коммуникаций.
После завершения: зафиксировать итоговый вывод (что делаем с ценой), ссылку на отчёт, дату и версию конфигурации, причины пауз/остановок, риски и что улучшить в следующем запуске. Такой «протокол решения» экономит недели споров в будущем.
Интеграции — это то место, где ценовые эксперименты чаще всего «ломаются»: цена показана одна, списана другая, а в аналитике всё выглядит иначе. Поэтому важно заранее договориться, где живёт «источник истины» и как системы обмениваются событиями.
Вариантов два:
Каталог/CRM — источник базовой цены, а приложение экспериментов вычисляет экспериментальную цену поверх (с учётом аудитории, варианта, ограничений).
Приложение экспериментов — источник финальной цены, а каталог и биллинг получают уже рассчитанную цену (или идентификатор правила), чтобы избежать расхождений.
На практике часто удобнее держать базовые цены в каталоге, а правила эксперимента и назначение вариантов — в вашем приложении. Но биллинг должен уметь принимать либо итоговую цену, либо ссылку на правило (например, price_rule_id) для повторяемости списаний и возвратов.
Минимальный контракт — один вызов, который возвращает цену и объяснение, почему она такая:
GET /api/price?user_id=123&product_id=sku_7
{
"product_id": "sku_7",
"currency": "RUB",
"base_price": 990,
"final_price": 890,
"experiment_id": "exp_42",
"variant": "B",
"reason": "active_experiment"
}
Важно: API должен быть детерминированным — тот же пользователь при повторном запросе получает тот же вариант (пока эксперимент активен).
События лучше доставлять не «в лоб» синхронными запросами, а через вебхуки или очередь (Kafka/RabbitMQ/SQS — что принято в компании). Типовые события: order_paid, refund_issued, subscription_changed. Для каждого события передавайте: experiment_id, variant, final_price, quantity, timestamp, order_id.
Для аналитики нужен регулярный экспорт в DWH/BI: назначения вариантов, экспозиции (показы цены), транзакции, возвраты. Обратная загрузка полезна для статусов: например, когда data-team посчитал победителя, приложение получает decision и автоматически переводит эксперимент в завершённый.
См. также: /pricing и /blog — там удобно разместить правила формирования цены и примеры отчётов для команд.
Эксперименты с ценой напрямую влияют на выручку, маржу и доверие клиентов, поэтому безопасность здесь — не «опция», а часть дизайна продукта. Хорошее правило: любая операция, которая может изменить цену для реальных пользователей, должна быть прослеживаемой, ограниченной по правам и защищённой от случайных действий.
На старте достаточно ролевой модели из раздела про UX (админ, менеджер экспериментов, аналитик, просмотр) и выдачи прав «по действиям». По мере роста можно детализировать доступы: например, разрешать запуск только в конкретной категории, регионе или для определённых surface.
Практика: права выдавайте по принципу «доступ по необходимости» и обязательно разделяйте:
Сделайте аудит обязательным для всех критичных операций: создание/изменение эксперимента, правки вариантов, изменение цены, запуск, пауза, завершение, откат. Логи должны быть неизменяемыми (append-only) и включать: кто, что, когда, из какого интерфейса/API, старое/новое значение, причину (короткий комментарий).
Для экспериментов чаще всего не нужен «сырой» PII. Используйте минимизацию и псевдонимизацию: храните идентификаторы пользователей в виде хэша/токена, а персональные атрибуты подтягивайте только при строгой необходимости и с отдельными правами.
Добавьте защиту от ошибок оператора:
Если сервис экспериментов недоступен, система должна предсказуемо деградировать: например, возвращать базовую цену из каталога, фиксировать инцидент в журнале и блокировать опасные операции до восстановления. Для критичных запусков полезна кнопка «экстренная остановка» с откатом на контрольный вариант.
MVP для ценовых экспериментов — это не «мини‑версия всего», а минимальный набор возможностей, который позволяет безопасно запускать тесты и доверять результатам. Ниже — практичный план, что сделать в первую очередь, что отложить и где чаще всего ошибаются.
Создание эксперимента: продукт(ы), период, варианты цены, целевая аудитория/фильтры, цель (например, выручка или маржа), статус (черновик → активен → завершён).
Назначение варианта: понятный механизм, который при каждом обращении пользователя возвращает один и тот же вариант (с сохранением назначения), и не допускает конфликтов.
Базовый отчёт: по каждому варианту показать ключевые числа (посетители, покупки, выручка, маржа/прибыль если доступна, конверсия), сравнение с контролем и простые предупреждения о качестве данных.
Критерий готовности MVP: команда может запустить тест на ограниченной аудитории, получить итоговый отчёт и объяснить, почему данным можно доверять.
Отдельная практичная идея для ускорения разработки: если вам нужно быстро собрать административный интерфейс, API и основу модели данных, можно прототипировать приложение на TakProsto.AI — это платформа vibe‑coding, где веб‑часть (React), бэкенд (Go) и PostgreSQL‑схема собираются из диалога. Удобно, что можно включить planning mode, получить экспорт исходников, а затем уже доработать под свои требования по безопасности, интеграциям и нагрузке (в том числе развернуть на инфраструктуре в России).
Спринт 1: каркас и сущности
Спринт 2: назначение варианта
Спринт 3: сбор событий и базовый отчёт
Начните с одной основной цели и 1–2 ограничителей:
Дальше зафиксируйте порог эффекта (MDE «в бизнес-терминах»), срок теста и правила досрочной остановки. Это должно быть записано в карточке эксперимента до запуска, иначе вы будете «договариваться с данными» по ходу.
Единица эксперимента выбирается так, чтобы пользователь не видел «прыжки» цены:
Практика: после логина «переводите» гостя на серверное назначение по user_id/account_id, чтобы сохранялась стабильность на разных устройствах.
Минимально задайте понятный scope конфликта, например product_id + surface (где surface — карточка, корзина, чек-аут), и правило:
Чтобы потом можно было восстановить «какую цену видел пользователь», храните:
amount (в минимальных единицах), currency, tax_mode, rounding_rule, , ;Собирайте минимум событий, которые связывают показ цены с покупкой:
price_view (фактическая цена, валюта, продукт/SKU, вариант, контекст показа);add_to_cart (кол-во, цена на момент добавления, скидки/купон, вариант);purchase (сумма, налоги/доставка, маржа/себестоимость если есть, вариант);refund/cancel (сумма, причина, связь с заказом).Используйте детерминированное назначение (например, хэш от assignment_key + experiment_key) и храните результат:
experiment_id, assignment_key (user/account), variant, assigned_at;Сделайте один простой эндпоинт «дай цену» и возвращайте не только число, но и объяснение:
base_price и final_price;experiment_id и variant;reason (например, active_experiment, excluded, no_experiment).Требование: API должен быть для одного пользователя в рамках активного эксперимента, иначе вы получите несходимость между витриной, корзиной и списанием.
Заранее согласуйте:
В MVP можно взять пороговый подход: минимум N пользователей/заказов на вариант + минимум 2 полные недели, чтобы сгладить сезонность по дням недели.
Задайте статусы и ограничения на правки:
Добавьте мониторинг двух типов:
Правила остановки фиксируйте до запуска, чтобы не спорить в момент инцидента.
Минимальные меры, которые реально предотвращают дорогие ошибки:
Если сервис экспериментов недоступен, система должна предсказуемо деградировать к базовой цене и фиксировать инцидент.
Так вы сохраняете интерпретируемость: пользователь не попадает в «комбинацию цен», которой не было в дизайне теста.
display_rulesvalid_from/valid_toЭто особенно важно, если базовая цена в каталоге меняется параллельно с экспериментом (промо, ручные правки).
В каждом событии должны быть единый идентификатор пользователя/аккаунта и experiment_id + variant, иначе продажи не «склеятся» с веткой теста.
Это защищает от проблем масштабирования и ретраев: даже если сервис перезапустился, пользователь не «переедет» в другую ветку.