Практическое руководство по AI‑first продуктам: как встроить модель в логику приложения, спроектировать потоки, качество, безопасность и мониторинг.
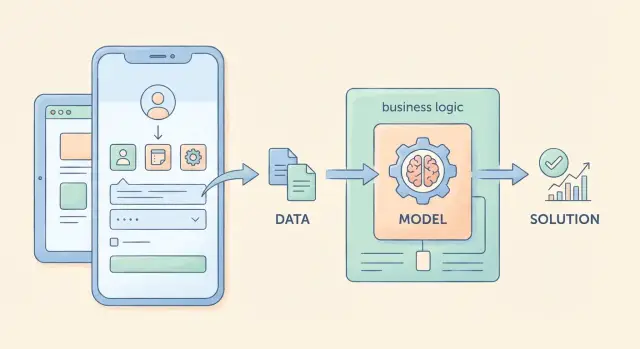
AI‑first продукт — это не «добавили чат‑бота в уголок интерфейса». Это продукт, где модель реально участвует в принятии решений: от неё зависит, что произойдёт дальше в сценарии пользователя, какие данные будут запрошены, какое действие выполнит система и какой результат получит человек.
Важно сразу принять мысль: как только вывод модели влияет на бизнес‑логику, вы переносите часть решений в вероятностную систему. Это даёт гибкость, но требует дисциплины в проектировании.
Модель становится частью логики, когда её вывод используется как вход для следующих шагов приложения: открывает или закрывает ветку процесса, выбирает маршрут, формирует итоговую сущность (ответ, резюме, заполненную форму), запускает автоматическое действие.
Типичные «ядерные» функции:
Правила хорошо работают там, где мир стабилен и входы строго формализованы. AI‑first подход нужен, когда данные «живые»: свободный текст, речь, нестандартные формулировки, неполные контексты.
Ключевой нюанс: модель обычно не заменяет логику целиком. Она расширяет её там, где правила начинают бесконечно разрастаться, а цена поддержки детерминированных веток становится выше, чем цена контролируемой вероятности.
AI‑first меняет не только технологию, но и операционные процессы.
Решение «делать на модели или на правилах» — это не про моду, а про свойства задачи и цену ошибки. Если модель становится частью бизнес‑логики, это должно быть оправдано измеримым эффектом.
Модель уместна, когда логику нельзя выразить правилами без взрыва сложности.
Примеры признаков:
Перед тем как выбирать LLM в приложении, проверьте практические ограничения:
Ошибка модели — это не «погрешность», а конкретный ущерб: неверный совет клиенту, неправильная блокировка, утечка данных, юридически опасная формулировка.
Чем ближе решение к деньгам, доступам и безопасности, тем важнее пороги, проверки и (часто) человек в контуре.
Используйте модель, если:
Оставайтесь на правилах, если:
Когда модель становится частью логики, её нельзя описывать как «сделай красиво» или «помоги пользователю». Ей нужна роль, как у любого компонента: что она решает, что получает на вход и что обязана вернуть на выход.
Сначала зафиксируйте, что является результатом работы модели на уровне продукта — не «ответ», а решение, которое влияет на сценарий.
Например:
Если результат запускает автоматическое действие, обычно нужен структурированный вывод, а не свободный текст.
Контракт — это то, что можно проверить и логировать.
Если вы ждёте JSON — так и пишите: «верни только JSON с ключами X, Y, Z». Это снижает двусмысленность и упрощает интеграцию.
Заранее договоритесь, что значит «модель работает»:
Пропишите запреты как часть контракта: какие данные нельзя раскрывать, какие действия нельзя инициировать, какие темы/формулировки запрещены.
Отдельно задайте поведение при неопределённости: например, «если уверенность ниже порога — верни status=needs_review».
Модель — не «кнопка магии», а шаг пайплайна рядом с правилами, БД и интеграциями. Чем точнее определено её место в цепочке, тем проще управлять качеством, стоимостью и рисками.
Типовой поток:
Сбор контекста: профиль пользователя, параметры запроса, история, данные из БД, документы (если есть RAG), ограничения политики.
Вызов модели: промпт + формат ответа (например, JSON), инструменты/функции, лимиты.
Постобработка: валидация формата, нормализация, проверка запрещённых действий, вычисление уверенности/порогов.
Действие: запись в БД, создание задачи, отправка сообщения, эскалация человеку, запуск интеграции.
Практичное правило: действие должно зависеть не от «красоты текста», а от структурированного результата и проверок.
Ответ модели — это предложение, а не источник правды. «Истина» должна жить в ваших системах:
Всё, что влияет на деньги, доступы и обязательства, фиксируйте транзакционно в БД, а не «со слов модели».
Модель может ответить по‑разному, а сеть — дать ретрай. Поэтому:
Ассистент: контекст (профиль + история) → модель генерирует ответ и/или «план» → валидатор → отправка ответа → запись резюме диалога в БД.
Модерация: текст/изображение → модель выставляет метки и риск‑скор → правила порогов → авто‑решение или очередь на проверку → журнал причин.
Маршрутизация заявок: форма + вложения → извлечение полей моделью → проверка обязательных полей → выбор очереди/приоритета → создание тикета с заполненными атрибутами.
Модель даёт гибкость, но продукту обычно нужна предсказуемость. Поэтому в AI‑first приложениях работает гибрид: модель оценивает/генерирует, а вокруг неё стоят детерминированные «рельсы», которые не дают системе выйти за рамки.
Правила — не конкурент модели, а страховка. Типичные слои:
Если выход не проходит проверки, система должна переключаться на безопасный сценарий (а не пытаться бесконечно «дожимать» модель).
Где возможно, вводите численные пороги: уверенность, similarity‑score, классификационный балл, риск‑скор.
Ниже порога — fallback: уточняющий вопрос пользователю, упрощённый режим, шаблонный ответ, ручная модерация или другой инструмент.
Для критичных шагов добавьте асинхронный «второй взгляд»: правило, специализированная модель или другая LLM проверяет результат на риски (токсичность, несоответствие политике, подозрительные суммы/реквизиты).
При расхождении — блокируем действие и отправляем на разбор.
Оператор нужен там, где ошибка дорогая: финансы, юридически значимые тексты, безопасность, персональные данные, публичные публикации.
Встраивайте человека как часть потока: очередь на проверку, понятная карточка «почему сработал порог», быстрые кнопки «принять/исправить/отклонить», обязательная запись решения в лог для улучшения правил и подсказок.
Когда модель становится частью логики, промпт — это не «текст для чата», а интерфейс. Он задаёт входы, ограничения и ожидаемый выход так же строго, как API‑контракт.
Промптинг (плюс хорошие примеры) обычно достаточен, если задача — переформулировать, классифицировать по понятным критериям, извлечь поля из текста, составить черновик письма или краткое резюме.
Fine‑tuning/дообучение имеет смысл, когда нужно стабильно соблюдать фирменный стиль, терминологию, редкие паттерны, или когда примеры в промпте становятся слишком длинными и дорогими.
Ещё один сигнал: вы постоянно «латаете» промпт частными правилами, а качество всё равно скачет на похожих входах.
Если ответ идёт в бизнес‑логику, требуйте структуру, а не «красивый текст». Просите JSON и описывайте схему: обязательные поля, типы, допустимые значения, поведение при неопределённости (например, "confidence" и "needs_human_review": true).
Это упрощает валидацию, логирование и тесты, а также снижает риск «галлюцинаций» в критичных местах.
Вместо того чтобы просить модель «посчитать» или «проверить по базе», дайте ей инструменты: вызов API, поиск, расчёт, проверку прав доступа.
Модель выбирает функцию, а фактические данные возвращает система. Так вы отделяете генерацию от истины и лучше контролируете побочные эффекты.
Снижайте температуру, добавляйте 1–3 эталонных примера, фиксируйте формат ответа и запрещайте лишний текст.
Полезно явно задавать правила: «если данных нет — верни null и причину», «не придумывай значения», «используй только перечисленные статусы». Это делает поведение предсказуемым.
Даже сильная LLM хорошо «рассуждает», но не обязана знать ваши внутренние правила, свежие цены или статус конкретного тикета. RAG (Retrieval‑Augmented Generation) решает это: сначала находит релевантные фрагменты в ваших источниках, затем модель отвечает, опираясь на них.
RAG обычно внедряют по четырём причинам:
Начните с того, что реально отвечает на пользовательские вопросы:
Не «скармливайте всё подряд». Сначала определите типы запросов и под них соберите минимальный набор источников.
У контента должна быть понятная жизненная цикличность:
RAG легко превращается в канал утечек, если не продумать доступы.
Если RAG настроен правильно, «знания» становятся управляемой частью продукта: обновляемой, проверяемой и безопасной.
Если модель встроена в бизнес‑логику, она становится частью поверхности атаки. Проектируйте систему так, чтобы ошибка или манипуляция ответом не превращалась в утечку данных, нежелательное действие или репутационный риск.
Частые проблемы — не «взлом ИИ», а эксплуатация доверчивости:
Ставьте проверки и на ввод, и на вывод:
Фильтры должны быть частью пайплайна, а не «галочкой» в промпте.
Если модель может вызывать функции (платежи, изменение данных, доступ к CRM), вводите allowlist действий и принцип минимальных прав: модель не должна «уметь всё».
Для опасных операций добавляйте подтверждение (человек или дополнительная проверка правил/порогов), а параметры функций валидируйте так же строго, как в обычном API.
Логи нужны для разборов инцидентов и улучшения качества, но хранить их следует аккуратно:
Оценка качества — это не «понравился ли ответ», а проверка, что модель стабильно выполняет продуктовый контракт: даёт полезный результат, не ломает формат и не ухудшает метрики бизнеса. Полезно сразу разделить измерения на оффлайн и онлайн — и связать их с версиями промпта/модели.
Соберите небольшой, но репрезентативный тест‑набор: реальные запросы пользователей, типовые кейсы и «углы» (двусмысленности, шум, провокации).
Для части примеров сделайте «золотые ответы» или хотя бы ожидаемые свойства ответа: какие поля вернуть, что упомянуть/не упоминать, какие источники процитировать.
Оффлайн‑проверка нужна, чтобы быстро сравнивать версии: промпт v3 против v4, модель A против B, изменение RAG‑источников — и видеть, где стало лучше или хуже.
В продакшене качество измеряется через поведение пользователей и экономику процесса:
Заранее определите «провал сценария» (например, пользователь просит переделать ответ, уходит в поддержку, или модель не возвращает валидный формат).
Критерии лучше фиксировать как чек‑лист: полезность (решил задачу), точность (нет выдумок), соблюдение формата (JSON/таблица/структура), соответствие политике (безопасность, тон).
Это помогает измерять не только «качество в среднем», но и типовые дефекты.
Если оценка ручная, заранее определите:
Проверяйте совпадение оценок между разметчиками и периодически калибруйте — иначе метрика будет шумной.
Когда модель становится частью бизнес‑логики, «работает/не работает» перестаёт быть бинарным. Важно видеть, что именно произошло в каждом запросе, насколько это дорого и быстро, и соответствует ли результат ожиданиям.
Минимальный набор метрик:
Отдельно считайте долю ответов, которые прошли валидатор, и долю запросов, ушедших в fallback.
Дрейф бывает двух типов:
Данные и контекст: меняются документы в базе знаний, источники отдают другое, ухудшается поиск (RAG), появляются новые термины.
Поведение пользователей: запросы становятся длиннее, появляются новые сценарии, люди начинают ломать формат или искать обход ограничений.
Практика: регулярно пересчитывайте качество на контрольном наборе и сравнивайте распределения (длина промпта, топ‑источники, темы, язык, доля отказов).
Инцидент для AI‑функции — не только 500‑я ошибка. Типичные SLO:
Алерты лучше строить на трендах (рост ретраев, рост отказов) и порогах (например, format error > 2% за 15 минут).
Чтобы быстро воспроизводить проблемы, логируйте (с учётом приватности):
Когда модель — часть бизнес‑логики, «релиз» становится шире, чем деплой кода. Меняются промпты, параметры, правила маршрутизации, источники знаний (RAG), а иногда и поведение поставщика модели. Управлять изменениями нужно так же дисциплинированно, как API‑контрактами.
Минимальный набор артефактов, которые стоит версионировать и уметь воспроизводить:
Хорошая практика — собирать это в «пакет релиза» с единым идентификатором, чтобы по одному ID можно было поднять точную копию поведения.
Новые версии сначала гоняют в песочнице на зафиксированном наборе кейсов и логов (replay). Затем — постепенный rollout: 1–5% трафика, мониторинг качества и стоимости, расширение доли.
A/B полезен не только для конверсии, но и для ошибок: доля отказов, нарушения формата, рост ручных эскалаций. Заранее определите «стоп‑сигналы».
Откат должен быть технически простым: переключение на предыдущий пакет релиза (промпт + модель + индекс + правила).
Типовые триггеры:
После отката — разбор причин с точными примерами и фиксацией новых тестов, чтобы проблема не вернулась.
Каждый релиз должен отвечать на два вопроса: что поменяли (промпт, модель, источник, пороги) и какой эффект ожидаем (метрики, целевые значения, риски). Это ускоряет согласования и помогает поддержке объяснять изменения пользователям.
Начните не с «добавим LLM везде», а с одной функции, которая:
Примеры: авто‑черновики ответов в поддержке, классификация обращений, поиск по базе знаний с кратким резюме.
Параллельно с первым прототипом заложите «страховку», иначе пилот быстро упрётся в недоверие.
0–2 недели: прототип на ограниченных данных, ручная оценка качества, фиксация контракта и метрик.
3–6 недель: пилот на небольшом сегменте пользователей, A/B или постепенное включение, сбор обратной связи, настройка порогов и fallback.
7–8 недель: масштабирование: оптимизация стоимости/латентности, расширение тестов, регламент релизов (версии промптов и конфигов), обучение команды поддержки.
Когда вы проектируете пайплайн (контекст → модель → валидация → действие), много времени уходит не на саму идею, а на «обвязку»: API, БД, роли, деплой, откаты, наблюдаемость и управляемые версии.
Если вы хотите быстрее пройти путь от прототипа к пилоту, имеет смысл смотреть на платформы, которые позволяют собирать приложение и AI‑логику из чата, но при этом оставляют контроль: структуру данных, интеграции, хранение состояния и возможность отката.
Например, TakProsto.AI — vibe‑coding платформа, ориентированная на российский рынок: через чат можно собрать веб‑приложение (React), серверную часть (Go + PostgreSQL) и при необходимости мобильное приложение (Flutter). Для AI‑first задач это удобно тем, что вы быстрее доходите до «боевого» контура: подключаете БД как источник истины, добавляете RAG по базе знаний, настраиваете валидации и пороги, а затем можете включить хостинг/деплой и привязать кастомный домен. Полезные для AI‑релизов вещи — snapshots и rollback (быстро откатить неудачную версию) и planning mode (сначала согласовать структуру и поток, затем реализовывать).
Отдельный практический плюс для чувствительных данных: платформа работает на серверах в России, использует локализованные и open‑source LLM‑модели и не отправляет данные в другие страны — это упрощает разговор про приватность и комплаенс в сценариях, где модель встроена в бизнес‑логику. Когда прототип созрел, вы можете экспортировать исходный код и продолжить развитие в своей инфраструктуре.
Если вы уже внедряете AI‑функции внутри команды, такой подход помогает быстрее проверить гипотезу (free/pro), а затем масштабировать с нужным уровнем контроля (business/enterprise), не теряя управляемость версий, метрик и процессов отката.
AI‑first — это продукт, где вывод модели влияет на следующий шаг сценария: выбирается ветка процесса, создаётся сущность (например, заполненная карточка), запускается действие (тикет, уведомление, эскалация).
Практическая проверка: если убрать модель, и продукт теряет способность принимать решения на «живых» входах (текст, документы, речь), значит модель — ядро, а не декорация.
Выбирайте модель, когда правила начинают «взрываться» по сложности:
Если вход строго структурирован и нужна детерминированность — обычно лучше правила.
Начните с «контракта решения»: что именно модель решает и как это влияет на поток.
Минимум:
Потому что свободный текст сложно валидировать и безопасно использовать как вход в логику.
Практика:
null + причину;Соберите поток как пайплайн, где модель — один из шагов:
Ключевое правило: «истина» живёт в ваших системах, а вывод модели — предложение, которое проходит проверки.
Добавьте «рельсы» вокруг модели:
Если проверка не пройдена — не пытайтесь «допромптить» в рантайме, а переключайтесь на безопасный сценарий.
RAG нужен, когда модель должна отвечать по актуальным внутренним данным, а не по «общим знаниям».
Базовая настройка:
Так проще обновлять знания без переобучения модели.
Закладывайте безопасность в пайплайн, а не только в промпт:
Для чувствительных операций добавляйте подтверждение или дополнительную проверку («второй взгляд»).
Сведите качество к проверяемым сигналам:
Отдельно фиксируйте «провал сценария» (например, невалидный формат или уход в поддержку).
Версионируйте не только код:
Делайте постепенный rollout (1–5% трафика) со стоп‑сигналами: рост format errors, скачок стоимости, рост эскалаций, падение ключевых метрик. Откат должен быть переключением на предыдущий «пакет релиза».
needs_review: true).