Разбираем, как key-value хранилища ускоряют приложения: кэш, хранение сессий и быстрые обращения по ключу. Паттерны, TTL, масштабирование и ошибки.
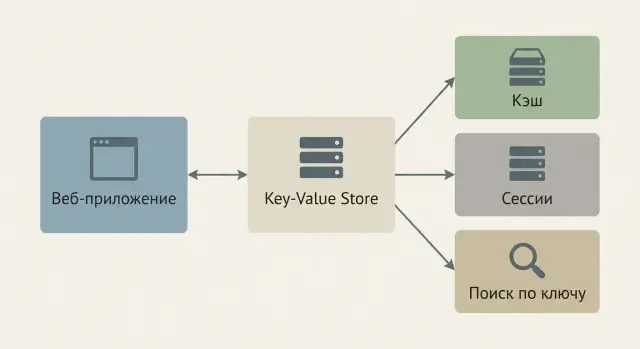
Key-value хранилище — это база данных, где каждый объект лежит под уникальным ключом, а по этому ключу можно получить значение. Аналогия с обычным словарём простая: ключ — это слово, значение — его определение. Важный момент: вы не «ищете по смыслу», вы обращаетесь к записи по точному идентификатору.
Эта модель кажется примитивной, но именно она делает key-value хранилища отличным инструментом для задач, где важны скорость и предсказуемость.
Главная причина скорости — простая модель доступа. Запрос выглядит как «дай значение по ключу», без сложных JOIN, фильтров и сканирования больших таблиц.
Обычно такие системы:
На практике это делает key-value удобным «ускорителем» рядом с основной базой данных.
Key-value хранилища отлично подходят, когда вам нужно:
А вот где они не лучший выбор:
Значение — не обязательно просто строка. В зависимости от конкретного продукта (например, Redis и его альтернативы) вы можете хранить:
"user:42:name" → "Анна";Итог: key-value хранилище — это инструмент для быстрых обращений по ключу и временных данных, который часто дополняет, а не заменяет основную БД.
В key-value вы заранее формулируете ключ доступа, и система возвращает значение. В SQL и документных БД основной сценарий другой: вы описываете какие данные нужны через условия и фильтры, а база решает, как их эффективно найти.
В key-value обычно нет богатого языка запросов уровня WHERE age > 30 AND city = .... Вы не спрашиваете «найди всех», вы спрашиваете «дай объект с ключом X».
Отсюда важный нюанс:
SQL-базы сильны транзакциями, связями и сложными выборками. Но за универсальность часто платят: схемой, джойнами, индексами, блокировками, более дорогими операциями записи/чтения при высокой конкуренции.
Если задача сводится к операциям вроде «получить значение по ID», «обновить счётчик», «положить и быстро забрать результат», то полноценная реляционная модель может быть лишней — key-value будет проще и быстрее в эксплуатации.
Документные БД (например, с JSON-документами) занимают середину: они дают гибкую схему и более удобные запросы по полям, но обычно проигрывают чистому key-value в предсказуемости и скорости именно точечных обращений по ключу.
Практический вывод: выбирайте key-value, когда вы можете заранее сформулировать ключ доступа и вам важны быстрые чтения/записи. Если же бизнес-логика требует «умных» выборок, агрегаций и аналитики — лучше смотреть в сторону SQL или документных решений.
Когда приложение слишком часто читает одни и те же данные из основной БД, оно начинает «платить» за каждое обращение: время на сетевой запрос, парсинг, выполнение SQL, блокировки, конкуренцию за соединения. В пиковые часы это выливается в рост задержек для пользователей и лавинообразное увеличение нагрузки на базу — даже если сами данные почти не меняются.
Key-value хранилище хорошо подходит для кэша, потому что отдаёт значение по ключу очень быстро и с предсказуемой задержкой. Вместо повторного похода в основную БД приложение сначала проверяет кэш:
Так кэш снижает среднее время ответа (особенно на популярных запросах) и разгружает основное хранилище: меньше запросов, меньше конкуренции за ресурсы, больше «запаса прочности» на реальные обновления данных.
Кэш выигрывает там, где есть «горячие» данные — небольшое число объектов, которые запрашивают часто:
Важно, что кэш не обязан хранить «всё». Часто достаточно держать только наиболее востребованные фрагменты: например, отрендеренный JSON ответа или вычисленный результат сложного запроса.
Главная цена кэша — риск вернуть устаревшие данные. Поэтому заранее продумайте, когда и как очищать/обновлять ключи:
Кэш — это ускоритель. Он приносит максимум пользы, когда у вас есть повторяемые чтения и понятные правила актуальности данных.
Выбор паттерна кэширования влияет не только на скорость, но и на простоту кода, нагрузку на базу данных и риск получить устаревшие данные. Ниже — три самых популярных подхода и ситуации, где они работают лучше всего.
При cache-aside приложение само управляет кэшем: сначала пытается прочитать данные по ключу, при промахе идёт в основную БД, а затем кладёт результат в key-value хранилище с TTL.
Плюсы: гибкость, кэшируется только реально востребованное («горячее»), легко внедрять точечно.
Минусы: нужно аккуратно обрабатывать промахи и «шторм» при одновременных запросах (когда много клиентов одновременно идут в БД).
Где подходит: каталоги, карточки товара, профили, любые сценарии с преобладанием чтений и терпимостью к кратковременной устарелости.
Read-through: приложение читает как будто из кэша, а кэш (через библиотеку/прослойку) сам подтягивает данные из БД при промахе.
Write-through: запись идёт через кэш, и кэш синхронно записывает в БД.
Плюсы: проще бизнес-коду — меньше ветвлений «если промах, то…», единая точка контроля.
Минусы: write-through увеличивает задержку записей (нужно дождаться БД), а read-through требует готовой интеграции/абстракции.
Где подходит: сервисы, где важна предсказуемость и единый механизм чтения/записи; команды, которые хотят меньше «кэш-логики» в приложении.
При write-behind запись сначала попадает в кэш, а в основную БД уходит асинхронно (пачками или с задержкой). Это даёт очень быстрые ответы на запись.
Главный риск: можно потерять данные при сбое кэша/узла до того, как изменения будут зафиксированы в БД. Снизить риск помогают: журналирование/очередь, репликация, ограничение окна задержки, периодические флеши и чёткая политика восстановления.
Где подходит: счётчики, метрики, лайки/просмотры, агрегаты — то, что можно пересчитать или где допустима небольшая потеря.
Если чтений много, а записи редки — чаще всего выигрывает cache-aside. Если важны простота и единый путь данных — смотрите в сторону read-through/write-through. Если записи должны быть максимально быстрыми и допустим «eventual» подход — write-behind, но только с продуманной защитой от потерь.
TTL (time-to-live) — это «срок годности» записи в key-value хранилище. Вы задаёте время, после которого ключ автоматически удалится. Для кэша и сессий это базовый механизм: он ограничивает рост данных, снижает риск устаревшей информации и помогает системе оставаться предсказуемой под нагрузкой.
Без TTL хранилище постепенно заполняется «мусором», и вы платите памятью (и деньгами) за данные, которые больше никому не нужны.
Даже при TTL память может закончиться: новые ключи приходят быстрее, чем старые успевают протухать. Тогда включаются стратегии выселения (eviction) — правила, какие ключи удалить первыми.
Выбор зависит от того, как ведут себя запросы: всплески и тренды чаще любят LRU, а стабильные популярные данные — LFU.
Хорошее правило: TTL должен отражать допустимую устарелость данных.
«Кэш без истечения» выглядит заманчиво, но обычно приводит к трём вещам: переполнению памяти, накоплению устаревших данных и сложным ручным чисткам. В итоге кэш перестаёт ускорять систему и начинает быть источником инцидентов. Лучше управлять сроком жизни явно — TTL + понятная стратегия выселения дают контролируемое поведение даже при росте нагрузки.
Сессия — это способ «узнать» пользователя между запросами: кто он, какие права имеет, что лежит в корзине и т. п. Чтобы ответы были быстрыми, данные сессии часто читаются при каждом запросе. Поэтому key-value хранилище хорошо подходит: доступ по ключу (ID сессии) обычно занимает миллисекунды и не требует сложных запросов.
Главный принцип — хранить минимум, а всё остальное получать из профильных систем по необходимости.
Не стоит складывать в сессию крупные объекты (полный профиль, длинные списки, историю действий). Это увеличивает память, усложняет миграции формата и повышает риск утечки.
Когда сессии хранятся в RAM конкретного инстанса приложения, появляются проблемы:
Вынос сессий в отдельное key-value хранилище делает приложение более «без состояния»: любой инстанс может обслужить любой запрос, просто прочитав session:{id}. Это упрощает автоскейлинг, отказоустойчивость и катящиеся обновления.
Задавайте TTL для сессий и продлевайте его при активности (sliding expiration) — но с верхним лимитом. Используйте ротацию идентификатора сессии после логина/повышения привилегий, чтобы снизить риск фиксации сессии. Храните идентификатор в cookie с флагами HttpOnly, Secure, SameSite, а при выходе из аккаунта удаляйте ключ (инвалидация) и при необходимости ведите список отозванных токенов с TTL.
Key-value хранилище особенно полезно там, где запрос почти всегда выглядит одинаково: «вот ключ — верни значение». Такой доступ предсказуем, хорошо кэшируется в памяти и даёт минимальную задержку даже при большом трафике.
Для автодополнения важны быстрые чтения маленьких фрагментов данных. Частый приём — держать «справочник» по ключу: префикс → список подсказок, или префикс → id набора подсказок.
Главное — избегать тяжёлых вычислений в момент ввода пользователя: лучше заранее подготовить значения и обновлять их фоном. Тогда каждое нажатие клавиши превращается в дешёвый запрос по ключу.
Key-value отлично подходит для «переводчиков» между идентификаторами:
Такой слой часто снижает нагрузку на основную БД: вместо сложного запроса вы делаете одно чтение по ключу и получаете нужный id или набор атрибутов.
Сценарии типа «сколько раз пользователь сделал действие за минуту» требуют атомарных операций: увеличить счётчик и сразу проверить порог.
Типичная схема: ключ вида rl:<user_id>:<minute> → значение-счётчик, плюс TTL чуть больше окна. Это позволяет ограничивать:
Одноразовые коды, временные ссылки, подтверждение email/телефона — идеальные кандидаты для key-value: запись создаётся, живёт ограниченное время и автоматически исчезает.
Практика: хранить минимум данных (например, code → user_id), выставлять короткий TTL и делать одноразовое «погашение» кода, чтобы исключить повторное использование.
Хороший дизайн ключей — это половина успеха при работе с key-value хранилищем. Он влияет на скорость, предсказуемость, удобство миграций и даже на стоимость инфраструктуры.
Практичный подход — строить ключи из «кирпичиков» через разделитель (обычно :):
billing, auth, catalogsession, user, cache, rateuserId, orderId, хэш параметровv1, v2 (особенно полезно при изменении формата значения)Пример: auth:session:v2:9f2c... или catalog:product:v1:sku-12345.
Коллизии чаще всего возникают, когда разные команды/сервисы «случайно» выбирают одинаковые ключи. Чтобы этого избежать:
user:123 без namespace;Key-value идеально подходит для быстрых чтений, но хранить огромные значения не всегда выгодно:
Частая практика: хранить в key-value короткий «указатель» (ID, URL, версию), а сам объект — в основной БД или object storage. В кэше держать только то, что реально ускоряет критичный путь.
Проектируйте ключи так, чтобы их можно было агрегировать. Метрики по префиксам помогают быстро находить проблемы: рост miss rate, «взрывы» кардинальности, неожиданные объёмы памяти.
Полезно отслеживать: топ ключей по частоте, топ префиксов по памяти, распределение размеров значений и время операций. Так вы заранее заметите горячие точки и сможете разделить нагрузку или пересмотреть структуру ключей.
Кэш ускоряет систему, но добавляет свои «болезни роста»: редкие баги превращаются в пики нагрузки, а пики — в простой. Ниже — самые частые сценарии и практики, которые обычно дают быстрый эффект.
Шторм возникает, когда популярный ключ одновременно истёк (или был вытеснен), и множество запросов параллельно идут в основную БД за одним и тем же значением. Итог — лавинообразный рост нагрузки на БД и рост задержек.
Как смягчить:
Если злоумышленник или просто «шумный» клиент запрашивает несуществующие ключи, кэш не помогает: каждый раз идёт запрос в БД, а кэш остаётся пустым.
Что помогает:
Лавина — это массовое истечение TTL у большой группы ключей примерно в одно время (часто после деплоя, прогрева или установки одинаковых TTL). В результате нагрузка резко возвращается в БД.
Как предотвратить:
Сочетайте несколько приёмов: джиттер TTL + отрицательное кэширование + блокировка на ключ для самых горячих данных. И обязательно добавьте метрики: hit/miss, p95 задержки, количество пересчётов и долю запросов, ушедших в БД — без наблюдаемости кэш «ломается молча».
Когда key-value хранилище перестаёт помещаться в память одного сервера или упирается в лимит запросов в секунду, его масштабируют. Обычно это сочетание шардинга и репликации — и почти всегда компромисс по согласованности.
Шардинг — это разбиение пространства ключей на «кусочки» и размещение их на разных узлах кластера. Часто используется хеш ключа: один и тот же ключ всегда попадает на один и тот же шард.
Последствия простые, но важные:
Репликация копирует данные с основного узла на один или несколько реплик. Это даёт:
Но цена — задержка доставки обновлений на реплики.
Если вы читаете с реплики, вы можете получить устаревшее значение — новое ещё не успело доехать. Для кэша это часто нормально, для сессий и денег — уже риск.
Практика: критичные чтения направляйте на основной узел или используйте режимы, где подтверждение записи ждёт реплики (если поддерживается), понимая, что латентность вырастет.
Key-value чаще всего держит данные в памяти, поэтому планируйте:
Хорошее правило: сначала посчитать объём, затем выбрать стратегию шардинга и только потом добавлять реплики под чтения и отказоустойчивость.
Выбор key-value хранилища начинается не с названия продукта, а с ответа на вопрос: что именно вы храните и какие гарантии нужны приложению. Для кэша одной и той же страницы и для хранения счётчиков в реальном времени требования будут разными — по задержке, по операциям и по тому, что считать «потерей данных».
Сначала зафиксируйте три параметра:
Если приложение чувствительно к пикам, смотрите не только среднюю задержку, но и хвосты (p95/p99) и поведение под нагрузкой.
Для многих сценариев (кэш, rate limiting, временные токены) допустимо временное хранение: перезапуск узла очищает данные, но сервис живёт.
Если же ключи — это фактически «источник правды» (например, баланс лимитов, важные счётчики, очереди задач), потребуется персистентность и понятная стратегия восстановления: журналирование, снапшоты, репликация, а также ожидаемое время возврата в строй после сбоя.
Проверьте, что хранилище поддерживает ваши примитивы:
Если вам нужны богатые структуры и атомарность «из коробки», часто смотрят в сторону Redis и его альтернатив. Если достаточно простого get/set при большом масштабе — важнее окажутся горизонтальное масштабирование и стабильные хвосты задержек.
Если пройтись по этому списку до выбора технологии, вы заметно сократите риск «не того» хранилища и неприятных сюрпризов после запуска.
Частая проблема на старте — не выбрать «идеальную» технологию, а быстро собрать рабочую архитектуру и проверить нагрузочный профиль: где у вас повторяющиеся чтения, какие ключи «горячие», где нужен TTL и какие хвосты задержек допустимы.
Если вы делаете продукт и хотите быстрее дойти до прототипа (например, API + веб-интерфейс + сессии и кэш), это удобно собрать в TakProsto.AI — платформе для vibe-кодинга, где приложение создаётся через чат. Вы описываете сценарии (кэширование профиля, хранение session:{id} с TTL, rate limiting по ключу), а платформа помогает развернуть основу: веб на React, бэкенд на Go, PostgreSQL для «источника правды», плюс интеграции под кэш и сессии. При необходимости можно экспортировать исходники, включить деплой/хостинг, подключить домен, а также пользоваться снапшотами и откатом.
Для российских команд отдельно полезно, что TakProsto.AI работает на серверах в России и использует локализованные и open-source LLM-модели, не отправляя данные за пределы страны — это иногда становится решающим фактором, когда обсуждаются сессии, токены и пользовательские данные.
Лучший способ понять возможности ТакПросто — попробовать самому.