Когда прототип от ИИ пора превращать в продакшн‑систему
Практические признаки, что прототип, созданный с помощью ИИ, пора превращать в продакшн: риски, метрики, безопасность, тесты, мониторинг и процесс перехода.
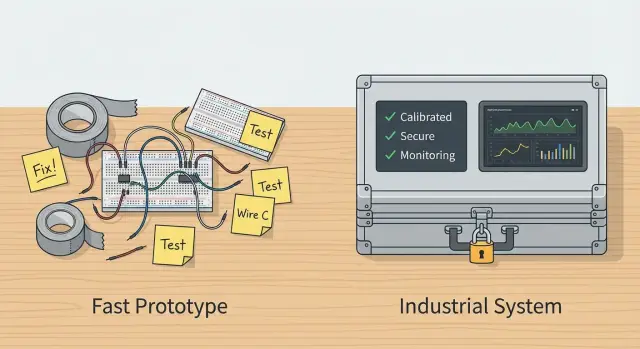
Прототип против продакшна: что реально меняется
Прототип ИИ — это быстрый способ проверить гипотезу: «работает ли вообще», «полезно ли пользователю», «можем ли мы получить нужный результат из данных». Продакшн‑система — это обещание: «будет работать стабильно, предсказуемо и безопасно в реальных условиях». Между ними разница не в «красивом интерфейсе», а в целях, допущениях и цене ошибки.
Цели и допущения
У прототипа допустимы ручные шаги, нестабильные ответы модели, «магические» настройки и временные костыли. Часто он живёт на локальной машине, опирается на небольшой набор тестовых данных и предполагает внимательного разработчика рядом.
У продакшна другие требования: понятные сценарии использования, воспроизводимость результатов, работа при пиковых нагрузках, контроль версий моделей и данных, а также ясные границы ответственности — кто и что делает, если ответ неверный.
Почему ИИ ускоряет старт, но не отменяет инженерную ответственность
Генеративные модели действительно сокращают время до первой демо‑версии. Но они добавляют новые источники неопределённости: вероятность галлюцинаций, дрейф качества на новых данных, зависимость от внешних API, непредсказуемые крайние случаи. Это нельзя «переговорить» презентацией — нужна инженерная дисциплина.
Цена «вечного прототипа»
Если прототип становится продуктом без «закалки», команда получает бесконечные пожары: ручные исправления, внезапные падения, спорные ответы модели и недоверие пользователей. Пользователи же сталкиваются с непоследовательностью: сегодня система помогла, завтра — подвела, и непонятно, можно ли на неё опираться.
Критерий: что должно быть правдой, чтобы «можно выпускать»
Переход в продакшн оправдан, когда вы можете честно сказать:
- мы знаем, для каких задач система предназначена и где она не применяется;
- качество измеряется метриками и регулярно проверяется, а не «кажется, стало лучше»;
- есть план обработки ошибок: безопасный отказ, ручная проверка или альтернативный сценарий;
- понятны риски и стоимость: сколько стоит запрос, какую нагрузку выдержим, что будет при сбоях.
Если хотя бы один пункт держится на надежде, это всё ещё прототип — даже если им уже пользуются.
Бизнес‑сигналы: когда ставки становятся высокими
Прототип ИИ хорош тем, что позволяет быстро проверить гипотезу и увидеть первые результаты. Но как только вокруг него появляется реальная ответственность, правила меняются: «достаточно работает» превращается в «нельзя ошибаться в ключевых местах».
Рост аудитории: больше пользователей — больше неожиданных сценариев
Пока прототипом пользуются 10 коллег, ошибки воспринимаются как курьёз. Когда пользователей становится сотни или тысячи, начинается эффект масштаба: редкий сбой превращается в ежедневную проблему.
Появляются новые сценарии: люди вводят данные иначе, задают нестандартные вопросы, используют сервис в неочевидное время и с разными ожиданиями. В этот момент цена «неаккуратностей» в логике, интерфейсе и обработке данных резко растёт.
От «поиграться» к критичным задачам
Главный бизнес‑сигнал — когда результат ИИ начинает влиять на деньги, здоровье или юридические риски.
Например:
- рекомендации участвуют в принятии решений о выплатах/скидках;
- ответы используются в коммуникациях с клиентами (и могут быть восприняты как обещание компании);
- система подсказывает действия, где ошибка приводит к штрафу, возвратам или претензиям.
Здесь уже недостаточно «в целом верно». Нужны заранее определённые ограничения: где ИИ можно доверять, а где он обязан передать решение человеку.
Внешние обязательства: SLA, сроки, поддержка
Как только появляются договорённости с клиентом или руководством (SLA, сроки реакции, обязательная поддержка, отчётность), прототип перестаёт быть внутренним экспериментом. Бизнесу важно не только качество ответов, но и предсказуемость: доступность, скорость, повторяемость результата.
Сигнал‑триггер: один инцидент дороже всей «экономии»
Если потенциальный ущерб от одного инцидента (утечка, неверная рекомендация, простой сервиса, массовая ошибка) превышает стоимость доведения решения до продакшн‑уровня, момент для «закалки» уже наступил.
Технические признаки: прототип перестал быть «временным»
Прототип живёт на скорости: быстро проверить гипотезу, показать ценность, собрать обратную связь. Но в какой-то момент «временность» превращается в постоянный режим работы — и это видно по конкретным симптомам.
1) Стабильность результата становится критичной
Если пользователи (или смежные системы) ожидают повторяемого результата, прототип начинает подводить. Типичные сигналы:
- один и тот же запрос сегодня и завтра даёт заметно разные ответы;
- модель ведёт себя по-разному в зависимости от нагрузки или мелочей в контексте;
- невозможно объяснить, почему решение «вдруг стало хуже».
На этом этапе уже нужны версии промптов/моделей, фиксированные параметры, контроль изменений и регресс‑проверки — иначе предсказуемости не будет.
2) Интеграций больше — а точек отказа ещё больше
Пока прототип «одинок», он терпит многое. Но как только он встраивается в цепочку (CRM, база знаний, биллинг, аналитика, очереди, почта), любая нестабильность начинает размножаться. Появляются таймауты, лимиты API, гонки данных, «непонятные» дубли и расхождения.
Если вы всё чаще чините не сам ИИ, а стыки — это уже продакшн‑задача.
3) «Временные решения» накапливаются быстрее, чем исправляются
Ручные правки ответов, скрипты для подстановки данных, исключения «для одного клиента», обходные пути для ошибок — всё это технический долг. Если без этих костылей система не работает стабильно, прототип перестал быть экспериментом.
4) Главный сигнал — команда тушит пожары
Когда разработчики тратят больше времени на разбор инцидентов, чем на развитие, это означает одно: система уже стала критичной, просто без нужной инженерной «закалки».
Пора вводить строгие контракты входных данных, обработку ошибок, очереди/ретраи, а также единый процесс изменения промптов и конфигураций.
Метрики и пороги готовности: без них выпуск — на удачу
Прототип ИИ часто «кажется работающим», пока вы не пытаетесь ответить на простой вопрос: после последнего изменения стало лучше или хуже? Если уверенного ответа нет — вы фактически выпускаете систему на удачу.
Для продакшна нужен минимальный набор измеримых критериев и заранее согласованные пороги.
Минимальный набор метрик
Сфокусируйтесь на четырёх группах, которые напрямую отражают продуктовую ценность и эксплуатационные риски:
- Качество/точность: доля правильных ответов, pass@k, точность извлечения фактов, уровень галлюцинаций (например, % ответов без источника там, где источник обязателен).
- Скорость: p50/p95 задержки для ключевых сценариев (а не «среднее по больнице»).
- Стоимость: стоимость запроса/сессии, расход токенов, стоимость инференса на пользователя.
- Стабильность: доля ошибок, таймаутов, ретраев, деградаций при росте нагрузки.
Базовая линия и пороги (SLO)
Сначала фиксируется базовая линия: текущие значения метрик на «последней хорошей» версии. Затем задаются допустимые пороги (SLO) по сценариям, например: «p95 < 2,5 сек», «стоимость ответа < X», «ошибки < 0,5%», «качество не ниже базовой линии более чем на 1 п.п.».
Важно: пороги должны быть привязаны к пользовательским задачам (по типам запросов), а не к модели «в вакууме».
Офлайн и онлайн — это разные миры
- Офлайн-метрики: оценка на размеченных данных, регрессионные наборы, проверки на типовые ошибки.
- Онлайн-метрики: реальная удовлетворённость, конверсия, удержание, доля эскалаций в поддержку, ручные отмены, жалобы.
Если офлайн «выросло», а онлайн «упало» — значит, метрики выбраны неверно или данные/сценарии сместились. Поэтому продакшн начинается с договорённости: что считаем успехом и где красная линия.
Производительность и стоимость: когда масштабирование становится обязательным
Прототип ИИ часто «летает» на десятке запросов в день и одном ноутбуке. Но как только появляются реальные пользователи, выясняется простая вещь: скорость ответа и цена одного запроса становятся частью продукта.
Если задержки и счета растут быстрее, чем ценность для пользователя, это прямой сигнал, что пора закладывать масштабирование как обязательное требование.
Латентность и пропускная способность: что ломается при росте нагрузки
В прототипе обычно смотрят на «среднее время ответа». В продакшне важнее хвосты: 95/99‑й перцентиль. Именно они портят впечатление — пользователь помнит не типичный ответ, а тот, который «завис».
При росте нагрузки ломаются очереди: запросы начинают копиться, появляются таймауты, а затем лавина повторных попыток (ретраев), которая добивает систему.
Заранее определите целевые пороги: сколько запросов в минуту вы обязаны выдержать и какая максимальная задержка допустима для ключевого сценария.
Контроль стоимости: лимиты, кеширование, деградация функциональности
Стоимость ИИ‑функции в продакшне управляется не только выбором модели, но и правилами использования. Практики, которые быстро окупаются:
- лимиты на пользователя/организацию и понятные «квоты» в тарифах;
- кеширование повторяющихся ответов и результатов извлечения данных;
- деградация функциональности при перегрузке (например, упрощённый режим, отключение дорогих опций, более короткий контекст).
Главное — заранее решить, что важнее: стабильная скорость, предсказуемая цена или максимальное качество ответа, и закрепить это в приоритетах продукта.
Планирование мощности: пики, очереди, таймауты, ретраи
Масштабирование — это про пики, а не про «обычный день». Проверьте, что у вас есть: ограничение длины очереди, разумные таймауты, контролируемые ретраи с джиттером, а также понятная стратегия — что делать, когда ресурсы на исходе (отказывать, ставить в очередь, упрощать ответ).
Если вы уже обсуждаете эти решения не «на всякий случай», а потому что пользователи сталкиваются с задержками и поддержка получает жалобы — прототип фактически стал продакшном, просто без защиты.
Безопасность и приватность: переход от демо к ответственности
Прототипу часто «прощают» многое: тестовые аккаунты, упрощённые права, логи без фильтрации. Но как только в системе появляются реальные данные клиентов — или на горизонте возникают требования регулятора/контрактные обязательства — вы берёте на себя ответственность как за полноценный сервис.
С этого момента безопасность и приватность перестают быть задачей «потом».
Какие данные у вас на самом деле
Для начала зафиксируйте классы данных, которые проходят через ИИ‑сценарий:
- Персональные: ФИО, контакты, идентификаторы, данные сотрудников.
- Коммерческие: цены, договоры, планы продаж, внутренняя финансовая отчётность.
- Внутренние: инструкции, база знаний, переписка, тикеты поддержки.
- Публичные: контент, уже доступный извне (но даже его можно «склеить» в чувствительные выводы).
Чем выше класс чувствительности, тем жёстче должны быть ограничения: кто видит, кто меняет, кто может выгружать.
Хранение и доступ: минимум необходимого
Продакшн начинается там, где появляются базовые практики: шифрование данных «на диске» и «в пути», управление секретами (токены, ключи API) и регулярная ротация ключей.
Доступы — по принципу least privilege: у сервисов и людей ровно те права, которые нужны.
Отдельно важно: где лежат промпты, системные инструкции и контекст. Если они содержат внутренние знания, защищайте их как код и конфиденциальные документы.
Утечки через промпты и логи
ИИ‑системы часто «текут» не через базу, а через:
- промпт, куда случайно подставили лишние поля;
- логи запросов/ответов, где остались персональные данные;
- отладочные трассировки и снимки контекста.
Практика для продакшна: минимизация (не отправлять то, без чего модель справится) и маскирование (скрывать чувствительные значения до записи в логи).
И заранее решите, сколько и как долго вы храните историю запросов — это часть политики приватности, а не «удобство разработчика».
Риски ИИ: качество, ошибки и безопасные сценарии
Прототип ИИ часто «сходит с рук»: он помогает команде понять ценность идеи, но ошибки воспринимаются как досадные мелочи. В продакшне всё иначе: даже редкая галлюцинация или уверенный, но неверный совет могут стать причиной финансового ущерба, репутационных потерь или юридических претензий.
Главный сигнал зрелости здесь простой: ошибки ИИ начинают причинять измеримый вред.
Где особенно опасны галлюцинации
Опаснее всего не «странные ответы», а правдоподобные рекомендации без оснований: медицинские/психологические советы, интерпретация законов, инструкции по безопасности, финансовые подсказки.
Для таких зон нужен режим «безопасного отказа»: лучше честно сказать «не знаю» и предложить следующий шаг, чем угадать.
Ограничения, предупреждения и безопасные сценарии
В продакшне у ИИ должны быть явные рамки:
- предупреждения в интерфейсе: что это помощник, а не эксперт, и когда требуется специалист;
- ограничения по задачам: что модель делает, а что запрещено (например, диагнозы, составление юридически значимых документов);
- безопасные сценарии: шаблоны ответов для риска (самоповреждение, насилие, мошенничество), перенаправление в поддержку/к горячим линиям, отказ от инструкций.
Политики использования: «можно/нельзя» на бумаге
Нужны понятные правила: допустимые темы, запретные запросы, возрастные и юридические ограничения, требования к источникам и цитированию, правила хранения логов.
Эти политики важны не только для пользователей, но и для команды поддержки: как трактовать спорные случаи и когда эскалировать.
Human-in-the-loop: когда нужен человек
Ручной контроль стоит встраивать, если:
- ошибка дорого стоит (деньги, безопасность, юридические последствия);
- ответ запускает действие (платёж, изменение данных, письмо клиенту);
- модель часто «уверенно ошибается» на отдельных темах.
Практически это делается через очередь на проверку, выборочные аудиты, обязательное подтверждение перед отправкой и кнопку «оспорить/исправить ответ» с быстрым маршрутом к оператору.
Наблюдаемость и поддержка: чтобы система не была «чёрным ящиком»
Пока ИИ‑прототип живёт у команды, проблемы «видны глазами»: кто-то перезапустил, кто-то поправил промпт, кто-то подсказал пользователю обходной путь. В продакшне так не работает — система должна сама объяснять, что с ней происходит, и помогать быстро восстановиться.
Логи, трассировка, метрики: что нужно видеть в реальном времени
Наблюдаемость — это три слоя:
- Метрики: время ответа, доля ошибок, нагрузка, стоимость запросов, доля отклонённых/заблокированных запросов.
- Логи: что именно запросили (с маскированием чувствительных данных), какую версию промпта/модели использовали, какие ограничения сработали.
- Трассировка: путь запроса через компоненты (API, оркестратор, инструменты/поиск, модель), чтобы найти узкое место за минуты, а не за дни.
Важно договориться о «норме»: какие значения считаются приемлемыми, а какие уже требуют реакции.
Аудит запросов/ответов: как объяснять решения и разбирать инциденты
Для ИИ‑систем критично уметь восстановить контекст: какие данные были доступны, какие источники использованы, какие правила безопасности применились, почему ответ получился именно таким.
Практика: хранить идентификатор запроса, версию конфигурации и безопасный «снимок» входа/выхода. Это ускоряет разбор жалоб, юридических запросов и внутренних проверок качества.
Алерты и дежурство: кто реагирует и за какое время
Если алерт не приводит к действию, это не алерт. Заранее определите: каналы уведомлений, ответственных, целевое время реакции и план действий (runbook): «что проверить первым», «как откатить», «как временно отключить функцию».
Сигнал: баги находят пользователи, а не мониторинг
Если о сбоях вы узнаёте из чатов поддержки или отзывов, продакшн уже наступил — просто без страховки. Наблюдаемость делает ошибки измеримыми, а поддержку — предсказуемой.
Тестирование и релизы: как перестать бояться изменений
ИИ‑функции часто «ломаются молча»: интерфейс работает, но ответы становятся хуже, токсичнее или просто не подходят бизнес‑сценарию.
Если вы заметили сигнал «каждое обновление вызывает непредсказуемые побочные эффекты», значит прототип уже живёт как продакшн — только без страховки.
Тесты для ИИ‑функций: примеры, регрессия, анти‑примеры
Начните с простого набора эталонных кейсов (20–100 штук), которые отражают реальные запросы пользователей. Для каждого сохраните ожидаемый результат в понятном виде: ключевые факты, стиль, запрещённые темы, допустимую длину.
Добавьте регрессию качества: при каждом изменении прогоняйте один и тот же набор и сравнивайте метрики (например, долю «приемлемых» ответов по ручной разметке или по LLM‑оценщику).
Отдельно соберите анти‑примеры: провокационные запросы, попытки обойти правила, неоднозначные формулировки. Эти кейсы не про «лучший ответ», а про безопасный отказ, уточняющий вопрос или строгий формат.
Контроль изменений: версионирование всего, что влияет на ответ
Чтобы понимать, что именно вызвало деградацию, версионируйте:
- промпты и системные инструкции;
- модель/провайдера и параметры (temperature, max tokens);
- данные (RAG‑индекс, документы, справочники);
- конфигурацию фильтров и пост‑обработки.
Одна правка — один «срез» версии, который можно воспроизвести.
Песочница и поэтапный релиз: canary, A/B, фича‑флаги
Новые версии выпускайте через песочницу и поэтапно: сначала canary на 1–5% трафика, затем расширение; для спорных изменений — A/B; для быстрого отката — фича‑флаги.
Так релизы становятся управляемыми, а не азартной игрой.
Данные и MLOps: порядок вместо ручных правок
Почти любой ИИ‑прототип держится на «ручной магии»: кто‑то выгрузил таблицу, кто‑то поправил колонку, кто‑то перезапустил скрипт. Это нормально на старте — пока вы проверяете идею.
Но как только фраза «на тех данных работало, а на новых — нет» начинает звучать регулярно, прототип уже просит дисциплины данных и MLOps.
Pipeline данных: источники, права, обновления
В продакшне важны не только сами данные, но и то, как они приходят.
Нужно зафиксировать: источники (CRM, логи, формы, файлы), правила очистки и преобразования, а также права на использование (кто владелец, можно ли хранить, можно ли обучать). Отдельно — расписание обновлений: ежедневно, еженедельно, по событию.
Без этого модель будет «кормиться» разными версиями реальности, а команда — спорить, чьи цифры правильные.
Дрейф данных и качества: как заметить и что делать
Данные меняются: сезонность, новые продукты, другой канал продаж, обновление интерфейса. Это приводит к дрейфу — входы становятся не похожи на те, на которых модель обучалась.
Практика для продакшна: мониторить простые индикаторы (доли категорий, распределения ключевых полей, долю пропусков) и метрики качества на контрольной выборке/ручной разметке.
Заранее определите действие при ухудшении: переключиться на безопасный режим, ограничить сценарии, запустить переобучение, поднять задачу на разметку.
Хранение артефактов и воспроизводимость
Чтобы перестать «угадывать», что именно было в успешной версии, храните артефакты как продукты:
- версии датасетов и схемы признаков;
- параметры обучения и версии библиотек;
- отчёты по качеству и принятые пороги;
- модельные файлы и конфигурации.
Тогда любой результат можно воспроизвести, сравнить и объяснить бизнесу — без поисков «той самой папки» и ручных правок на сервере.
Процесс перехода: роли, документы и ответственность
Переход от прототипа ИИ к продакшну — это не «допилить пару багов», а договориться, кто отвечает за систему как за продукт. Пока ответственности размыты, любая проблема превращается в хаос: непонятно, кто принимает решение, кто чинит, кто объясняет пользователям и кто фиксирует выводы.
Роли и зоны ответственности
Минимальный набор ролей, который закрывает типичные провалы:
- Продукт: формулирует ценность, SLA/ожидания, приоритеты, принимает компромиссы (качество vs скорость vs стоимость).
- Инженерия: эксплуатация сервиса, деплой, стабильность, производительность, инциденты.
- Безопасность/юристы/комплаенс: требования к данным, доступам, хранению, рискам и процедурам.
- Аналитика/DS: метрики качества модели, мониторинг дрейфа, правила переобучения.
- Поддержка: сценарии общения с пользователями, маршрутизация обращений, сбор обратной связи.
Если знания «держатся на одном человеке» или живут в личных сообщениях — это явный сигнал, что прототип уже стал критичным, а процесс ещё нет.
Документация, без которой нельзя
Нужен короткий, но конкретный набор артефактов:
- Архитектура (схема компонентов и потоков данных, интеграции, зависимости).
- Ограничения и известные риски (где модель ошибается, что считается недопустимым результатом).
- Инструкции для on-call: типовые алерты, куда смотреть, как откатываться, кого будить.
Критерии «готово» и пересмотр
Зафиксируйте «Definition of Done»: чек‑лист, ответственные за каждый пункт и дата пересмотра. Это превращает запуск из «на удачу» в управляемое решение: ясно, что выполнено, что принято как риск, и кто подписался под этим.
Где помогает TakProsto.AI: ускорить путь от идеи до управляемого пилота
Когда задача — быстро собрать прототип и тут же начать «закалку» (метрики, роли, релизы, интеграции), критично сократить время на рутину разработки.
TakProsto.AI — это vibe‑coding платформа для российского рынка: вы описываете сценарий в чате, а система помогает собрать веб‑приложение (React), серверную часть (Go + PostgreSQL) или мобильное приложение (Flutter). Практически это полезно в двух точках перехода:
- Прототип → пилот: быстрее собрать рабочий контур (авторизация, роли, формы, интеграции, журналирование), чтобы начать измерять метрики и получать реальную обратную связь.
- Пилот → продакшн: удобнее управлять изменениями — через снимки, откат (rollback) и планирование изменений в planning mode, а также развертывание и хостинг с поддержкой кастомных доменов.
Отдельно важно для тем безопасности и приватности: платформа работает на серверах в России и использует локализованные и open‑source LLM‑модели, не отправляя данные в другие страны — это снижает организационные риски там, где прототип уже начинает «трогать» реальные данные.
Если вы делаете публичные разборы или кейсы по тому, как доводите ИИ‑функцию до продакшна, в TakProsto.AI есть программы, которые помогают получить кредиты за контент (earn credits) и за рекомендации через реферальную ссылку. А по мере роста нагрузки можно перейти с free на pro, business или enterprise — чтобы масштабировать процесс без «пересборки всего с нуля».
Практический чек‑лист: момент для «закалки» и первые шаги
Ниже — быстрый способ понять, остаёмся ли мы в режиме прототипа, делаем ограниченный пилот или уже обязаны переходить в продакшн. Это не про перфекционизм, а про снижение риска там, где он реально появился.
Решающее дерево: прототип → пилот → продакшн
- Оставаться прототипом, если верно почти всё:
- используют 1–3 человека внутри команды;
- ошибки не влияют на клиентов/деньги/репутацию;
- данные тестовые или обезличенные.
- Делать пилот (ограниченный запуск), если:
- появились реальные пользователи, но их можно ограничить (по ролям/региону/функциям);
- уже есть ценность, но качество нестабильно;
- нужны метрики и контроль, но допускается ручной «надзор».
- Идти в продакшн, если:
- решение влияет на деньги, SLA, безопасность, юридические обязательства;
- система интегрирована в процессы (CRM, заявки, платежи, поддержка);
- команда устала «чинить руками», а объём запросов растёт.
Минимальный план на 30–60 дней
Первые 30 дней (закрыть базовые риски):
- Метрики: определить 3–5 ключевых показателей (качество ответа/точность, доля отказов, скорость, стоимость запроса) и пороги «можно/нельзя».
- Логи и мониторинг: сбор ошибок, латентности, затрат, а также примеров плохих ответов.
- Безопасность данных: что отправляем в модель, что маскируем, кто имеет доступ.
- Тесты: минимум — набор эталонных сценариев + регрессионный прогон перед релизом.
30–60 дней (сделать управляемым):
- канареечные релизы/фича‑флаги и быстрый откат;
- процедура обработки инцидентов (кто дежурит, как эскалировать);
- каталог промптов/версий модели и правила обновлений.
Что можно отложить, а что нельзя
Нельзя откладывать: пороги качества, мониторинг ошибок/стоимости, контроль доступа, журналирование критичных действий, план отката.
Можно отложить (в пределах разумного): идеальную автоматизацию MLOps, полное покрытие тестами, оптимизацию каждой миллисекунды, сложные дашборды — если есть минимальный контроль.
Шаблон чек‑листа для команды
- Кто владелец продукта и кто отвечает за качество модели
- Где зафиксированы метрики и пороги «проходим/не проходим»
- Как измеряем стоимость одного запроса и общий бюджет
- Какие данные запрещено отправлять в модель, как они маскируются
- Где смотреть ошибки, задержки, частоту отказов
- Есть набор тест‑сценариев и регрессия перед релизом
- Есть фича‑флаг/канарейка и понятный откат
- Описан процесс инцидента: контакты, сроки реакции, пост‑морем
- Версионируются промпты/модель/настройки и есть история изменений
FAQ
Как понять, что ИИ‑прототип уже пора переводить в продакшн?
Ориентируйтесь на критерий «что должно быть правдой, чтобы можно выпускать». Если у вас:
- определены границы применения (и где система не используется);
- качество измеряется метриками и проверяется регулярно;
- есть сценарий обработки ошибок (безопасный отказ/ручная проверка/альтернатива);
- понятны стоимость, нагрузка и план действий при сбоях,
то вы близки к продакшну. Если хотя бы один пункт держится на надежде — это всё ещё прототип.
Почему разница между прототипом и продакшном не сводится к интерфейсу?
Потому что в продакшне вы даёте обещание стабильности, предсказуемости и безопасности. Это требует:
- воспроизводимости (версии модели/промптов/данных, фиксированные параметры);
- устойчивости к нагрузке и «хвостам» задержки (p95/p99);
- контроля точек отказа (интеграции, таймауты, лимиты API);
- понятной ответственности и процедуры инцидентов.
Без этого «красивый интерфейс» не спасёт.
Какие бизнес‑сигналы означают, что ставки стали высокими?
Когда результат ИИ влияет на деньги, безопасность или юридические риски. Типовые сигналы:
- ответы уходят клиентам и становятся обещаниями компании;
- рекомендации участвуют в скидках/выплатах/решениях;
- ошибка приводит к штрафам, возвратам, претензиям.
В таких зонах нужен минимум: ограничения по задачам, обязательная проверка человеком там, где ошибка «дорого стоит», и сценарии безопасного отказа.
Почему рост пользователей быстро ломает «нормально работающий» прототип?
При росте аудитории растёт разнообразие входов и крайних случаев: нестандартные запросы, другие форматы данных, неожиданные часы пик. То, что было «редким багом» на 10 коллегах, становится ежедневной проблемой на тысячах пользователей.
Практика: заранее ограничьте сценарии пилота, введите метрики стабильности (ошибки/таймауты/ретраи), и сделайте поэтапные релизы (canary, фича‑флаги) для снижения риска.
Какие метрики нужны, чтобы выпуск был не «на удачу»?
Минимум — четыре группы:
- качество (точность, доля галлюцинаций, % ответов с источником там, где он обязателен);
- скорость (p50/p95 по ключевым сценариям);
- стоимость (цена запроса/сессии, расход токенов/инференса);
- стабильность (ошибки, таймауты, деградации под нагрузкой).
Дальше зафиксируйте базовую линию и SLO/пороги, чтобы любой релиз можно было оценить как «лучше/хуже».
На что смотреть в производительности при переходе в продакшн?
Смотрите на p95/p99, а не на среднее. При росте нагрузки обычно ломаются очереди: копятся запросы → таймауты → лавина ретраев.
Что сделать быстро:
- поставить ограничения очереди и разумные таймауты;
- добавить контролируемые ретраи с джиттером;
- определить, что делаете при перегрузке: отказ, очередь или упрощённый режим.
Это превращает «зависания» в управляемую деградацию.
Как держать стоимость ИИ под контролем, когда начинается масштабирование?
Три самых окупаемых механизма:
- квоты и лимиты на пользователя/организацию (и привязка к тарифам);
- кеширование повторяющихся результатов (ответы, извлечение фактов, поиск);
- деградация функциональности при перегрузке (короче контекст, более дешёвая модель, отключение дорогих опций).
Важно заранее выбрать приоритет: стабильная скорость, предсказуемая цена или максимальное качество — и закрепить это в продуктовых правилах.
Что обязательно сделать по безопасности и приватности перед запуском на реальных данных?
Начните с инвентаризации классов данных (персональные, коммерческие, внутренние) и примените принцип минимально необходимого.
Практики, которые нельзя откладывать:
- шифрование «в пути» и «на диске»;
- управление секретами и регулярная ротация ключей;
- доступ по least privilege;
- маскирование чувствительных данных в логах;
- политика хранения истории запросов (что, сколько и зачем храните).
Частая утечка происходит не из базы, а через промпты и логи.
Как снизить риск галлюцинаций и «уверенных ошибок» в продакшне?
Сфокусируйтесь на трёх слоях защиты:
- ограничения по задачам (что разрешено и что запрещено);
- безопасные сценарии (отказ «не знаю», уточняющие вопросы, эскалация к человеку);
- human-in-the-loop там, где ответ запускает действие (платёж, изменение данных, письмо клиенту).
Для рискованных тем лучше предсказуемый отказ, чем правдоподобная ошибка. Дополнительно полезны выборочные аудиты и кнопка «оспорить/исправить ответ».
Что должно появиться в поддержке и релизах, чтобы перестать «тушить пожары»?
Нужен минимум наблюдаемости и управляемых релизов:
- метрики, логи (с маскированием) и трассировка по всей цепочке компонентов;
- сохранение версии промпта/модели/конфигурации для каждого ответа;
- алерты, которые ведут к действию (ответственный, время реакции, runbook);
- поэтапный релиз: песочница → canary 1–5% → расширение, плюс фича‑флаги для быстрого отката.
Сигнал проблем: о сбоях вы узнаёте от пользователей, а не из мониторинга.