Разбираем, как LLVM и идеи Криса Латтнера стали базой для современных языков и инструментов: IR, оптимизации, бэкенды, отладка и анализ кода.
LLVM — это не «ещё один компилятор», а инфраструктура, на которой строятся компиляторы, оптимизации и значительная часть инструментов разработки. Её часто «не видно»: вы пишете код, нажимаете Build, запускаете тесты — и редко задумываетесь, что внутри работает цепочка преобразований. Но именно LLVM во многом определяет, насколько быстро собирается проект, каким окажется машинный код и какие диагностические инструменты будут доступны.
LLVM решает три практические задачи, которые важны и «обычному» разработчику:
Вы разберётесь, из каких частей состоит LLVM, как связаны Clang и LLVM IR, где в конвейере появляются оптимизации и почему выбор настроек сборки (например, LTO/PGO) меняет результат. Это пригодится при ускорении приложений, настройке CI, поиске ошибок памяти и при кроссплатформенной сборке — даже если вы никогда не будете писать собственный компилятор.
Для практического старта пригодится раздел /blog/kak-nachat-znakomstvo-s-llvm-i-ne-utonout.
Крис Латтнер — один из тех инженеров, чьи идеи «сдвигают» целую область. В начале 2000‑х он работал над исследовательским проектом в Университете Иллинойса и столкнулся с типичной болью компиляторов того времени: системы были монолитными, сложными для расширения и плохо переиспользовали наработки между языками и платформами.
Ключевая мысль Латтнера была простой: разделить компилятор на понятные слои и ввести универсальное промежуточное представление программы (IR), через которое можно пропускать разные языки и получать код под разные процессоры. Так LLVM изначально задумывался не как «компилятор одного языка», а как инфраструктура — набор библиотек и инструментов, которые можно комбинировать.
Модульный подход сделал возможным то, что раньше требовало переписывания половины системы:
В результате вокруг LLVM быстро сформировалась экосистема: исследователи и компании могли брать «кирпичики» и собирать свой пайплайн компиляции под задачу.
Показательной связкой стал Clang — фронтенд для C/C++/Objective‑C, который переводит исходники в LLVM IR. Дальше IR проходит оптимизации и превращается в машинный код для нужной цели.
На концептуальном уровне это и есть современная цепочка: язык → IR → оптимизации → платформа, где компоненты можно заменять и улучшать по отдельности.
LLVM часто называют «компилятором», но точнее думать о нём как о конструкторе: это набор библиотек и утилит, из которых можно собрать компилятор, анализатор кода, JIT-исполнитель, инструменты профилирования и многое другое.
Важно: у LLVM нет одной-единственной «кнопки компиляции». Есть инфраструктура, которую используют разные проекты (например, Clang) под свои задачи.
В классической схеме LLVM разделяет работу на понятные этапы:
Такое разделение позволяет развивать части независимо: язык можно менять, не переписывая весь «хвост» до железа, а новые процессоры поддерживать, не трогая правила языка.
Для языков это шанс «подключиться» к готовым оптимизациям и генерации кода. Для IDE и CI — единая база для диагностики, анализа и проверок: те же библиотеки, что помогают компилировать, могут помогать подсвечивать ошибки, находить уязвимости и поддерживать единый стиль сборки на разных платформах.
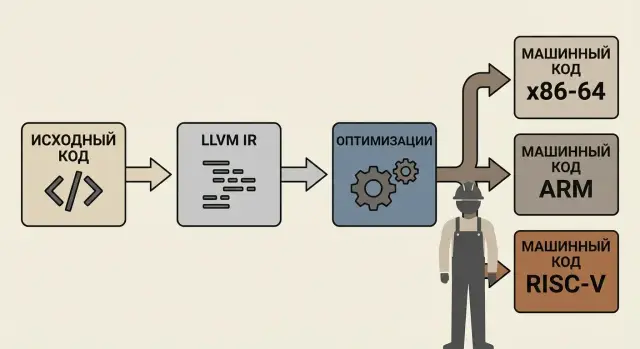
LLVM IR (Intermediate Representation) — это промежуточный «общий язык», на который компилятор переводит исходный код, прежде чем превратить его в машинные инструкции.
Идея проста: фронтенды разных языков (например, Clang для C/C++) могут выдавать один и тот же формат IR, а дальше общая цепочка оптимизаций и бэкендов уже решает, как получить быстрый код под x86_64, ARM, RISC‑V и другие архитектуры.
Главный выигрыш — разделение труда. Языку не нужно «знать» детали каждого процессора, а конкретному процессору не нужно «знать» особенности каждого языка. Между ними стоит IR, где сосредоточены оптимизации компилятора и анализ.
LLVM IR построен вокруг SSA (Static Single Assignment): каждое значение присваивается ровно один раз, а «ветвления» выражаются через специальные узлы (например, phi). Это упрощает многие оптимизации: распространение констант, устранение лишних вычислений, анализ зависимостей.
IR при этом строго типизирован: операции явно задают типы (i32, i64, float и т. д.). Такая точность помогает оптимизатору быть агрессивнее и при этом сохранять корректность.
define i32 @add(i32 %a, i32 %b) {
entry:
%sum = add i32 %a, %b
ret i32 %sum
}
LLVM IR существует в двух формах:
Фронтенд — это часть компилятора, которая «понимает» конкретный язык программирования. Его задача — взять текст программы, разобраться в структуре и смысле, а затем выразить всё это в виде LLVM IR — промежуточного представления, с которым дальше работают оптимизаторы и генераторы машинного кода.
Во‑первых, парсинг: фронтенд читает исходный код и строит дерево разбора (AST), где видно, что является выражением, что — объявлением функции, где блоки и скобки.
Во‑вторых, семантический анализ: проверяется смысл. Например, существует ли переменная, совпадают ли типы, можно ли вызвать функцию с такими аргументами, корректно ли используются шаблоны/дженерики. На этом этапе формируется более точная «модель» программы — уже не просто текст.
В‑третьих, диагностика: хорошие сообщения об ошибках и предупреждениях — не побочный эффект, а отдельная инженерная работа. Фронтенд должен не только сказать «неправильно», но и показать место, объяснить причину и, по возможности, предложить исправление.
Для C/C++/Objective‑C таким фронтендом является Clang. Его ценят за быстрый разбор, качественные диагностические сообщения и удобство как основы для инструментов: форматтеров, статического анализа и автодополнения в IDE. По сути, Clang — это «передняя дверь» в экосистему LLVM для мира C/C++.
LLVM не привязан к одному языку. Язык «подключается» через собственный фронтенд: он строит AST, проверяет семантику и затем генерирует LLVM IR. Дальше — общий конвейер: оптимизации, выбор целевой платформы, сборка.
Практический итог: один и тот же бэкенд может обслуживать разные языки, а языку не нужно заново изобретать весь компилятор — достаточно корректно переводить смысл программы в IR.
После того как фронтенд (например, Clang) превратил исходники в LLVM IR, начинается самая «инженерная» часть компиляции: улучшение IR так, чтобы программа работала быстрее (или занимала меньше памяти), но при этом оставалась корректной.
В LLVM оптимизации устроены как набор passes — отдельных проходов по IR. Каждый pass решает свою задачу: упрощает выражения, убирает мёртвый код, переупорядочивает инструкции, улучшает циклы.
Ключевой момент — это именно конвейер: результат одного pass становится входом для следующего. Иногда проходы повторяют в разных комбинациях, потому что одна оптимизация «раскрывает» возможности для другой. Например, после инлайнинга появляются новые константы и ветвления, которые можно упростить, а затем — удалить ставший лишним код.
Несколько «классических» техник, которые вы почти наверняка увидите в реальных пайплайнах LLVM:
Оптимизация — не бесплатная. Более агрессивные уровни (условно «-O2/-O3») обычно дают более быстрый бинарник, но:
Поэтому LLVM предлагает разные режимы и пайплайны: для быстрой итерации в разработке и для максимально эффективной сборки релиза. Именно гибкость passes делает эту настройку практичной, а не мистической.
Сильная сторона LLVM в том, что после этапа LLVM IR можно «подключать» разные бэкенды — части компилятора, которые знают конкретный процессор и его особенности. Один и тот же IR может быть превращён в машинный код для x86_64, ARM, RISC‑V или даже в WebAssembly — без переписывания фронтенда языка.
Бэкенд берёт IR и проходит несколько практичных шагов:
Во‑первых, выбирает инструкции: высокоуровневые операции нужно разложить на реальные команды процессора.
Во‑вторых, распределяет регистры: процессорных регистров мало, и бэкенд решает, что держать «внутри», а что временно выгружать в память.
В‑третьих, занимается планированием (scheduling): переставляет инструкции так, чтобы лучше загрузить конвейер и сократить простои.
Итог — генерация объектного файла или готового исполняемого файла.
Цель обычно задаётся target triple — строкой из трёх частей: архитектура, «поставщик/вендор», ОС+ABI.
Примеры:
x86_64-unknown-linux-gnu — типичный серверный Linux на Intel/AMD.aarch64-apple-darwin — современные устройства Apple на ARM.wasm32-unknown-unknown — WebAssembly для запуска в браузере или рантайме.Это и делает кроссплатформенную сборку приземлённой: вы можете собирать проект на одном компьютере, но выпускать бинарники под другие платформы — меняя цель сборки, а не переписывая код.
LLVM ценят не только за генерацию машинного кода, но и за «обвязку» для повседневной разработки: отладку, поиск ошибок в рантайме и автоматические проверки стиля и корректности. Эти инструменты работают лучше всего, когда включены в обычный цикл сборки и запуска.
LLDB — отладчик, который хорошо дружит с кодом, собранным через Clang/LLVM. На практике это означает предсказуемые точки останова, понятные стек-трейсы и корректное отображение переменных.
Чтобы отладчик «видел» ваш код, сборка должна содержать отладочные символы. Чаще всего это делается флагом -g. Внутри используются стандартные форматы описания отладочной информации (например, DWARF), но углубляться в них обычно не нужно: достаточно помнить, что агрессивные оптимизации могут усложнять пошаговую отладку. Если цель — диагностика, иногда полезно собирать без максимальных оптимизаций.
Санитайзеры — это режимы сборки, которые добавляют проверки прямо в исполняемый файл:
Их обычно включают в тестовых сборках и CI: они замедляют программу, зато превращают «странные падения у пользователя» в конкретный отчёт с местом в коде.
clang-tidy — набор проверок кода: от подозрительных конструкций до правил стиля. Его удобно подключать к сборке, чтобы замечания появлялись как обычные предупреждения.
clangd — языковой сервер для IDE: подсказки, переход к определению, рефакторинги. Он использует ту же «понимающую код» инфраструктуру, поэтому качество подсветки и диагностики часто выше там, где проект реально компилируется Clang-ом.
В сумме это делает LLVM не только компилятором, а полноценным набором инструментов для качества кода.
LLVM часто воспринимают как «что-то про компиляцию и оптимизации», но для повседневной разработки важнее другое: вокруг LLVM выросли инструменты, которые делают код понятнее, ошибки — яснее, а проверку качества — быстрее.
Большая часть «дружелюбия» начинается не в самом LLVM, а во фронтендах, например в Clang для C/C++. Они строят подробное представление программы и могут показывать сообщения об ошибках с точным указанием места, контекстом и практичными подсказками.
Это особенно заметно при работе с шаблонами, макросами и сложными типами: где раньше приходилось гадать по длинной простыне текста, теперь чаще видно, что именно не так и почему.
clangd использует те же знания о языке, что и компилятор, поэтому автодополнение, «перейти к определению», поиск ссылок и подсказки типов становятся точнее. Важно, что это не отдельный «умный редактор», а единый источник правды о языке.
Итог — меньше расхождений между тем, что показывает IDE, и тем, что реально соберётся.
Экосистема LLVM помогает автоматизировать рутину в CI:
В результате удобство разработки растёт не за счёт «магии», а за счёт более точной диагностики и повторяемых проверок, которые легко встроить в процесс.
Производительность в LLVM — это не один «секретный тумблер», а набор понятных техник, которые включаются в нужных местах пайплайна. Полезно различать: что ускоряет саму программу, а что может заметно замедлить сборку.
AOT (ahead-of-time) — классическая компиляция «заранее»: исходники превращаются в машинный код, вы получаете исполняемый файл или библиотеку. Это типичный сценарий для C/C++ через Clang и для многих продакшн-сборок.
JIT (just-in-time) — компиляция «на лету» во время работы программы. В LLVM это часто используют там, где нужен интерактивный опыт или динамика: REPL, плагины, скриптовые движки, вычислительные пайплайны, когда код генерируется под конкретные данные или железо.
Плюс: можно оптимизировать именно под текущий процессор и реальную нагрузку. Минус: появляется стоимость компиляции в рантайме и сложнее отлаживать «что именно было сгенерировано».
PGO (Profile-Guided Optimization) опирается на профили выполнения: сначала собирается «инструментированная» версия, она прогоняется на типичных сценариях, затем профиль используется при финальной сборке.
Идея простая: компилятор начинает лучше угадывать, какие ветки кода горячие, где уместнее инлайн, как разложить код в памяти. Ожидаемый эффект — более предсказуемые улучшения в реальных нагрузках, но только если профиль действительно похож на продакшн-трафик.
LTO (Link Time Optimization) позволяет оптимизировать программу «целиком», когда видны границы модулей: агрессивнее инлайнить, выкидывать мёртвый код, лучше специализировать функции.
ThinLTO — компромисс: сохраняет часть преимуществ LTO, но обычно заметно дружелюбнее к времени сборки и параллелизации.
Цена и риски: увеличение времени линковки, больше потребление памяти, возможные сюрпризы с отладкой и более сложная диагностика, если сборка ломается на позднем этапе. Поэтому LTO/ThinLTO чаще включают точечно: для релизных сборок, ключевых бинарников и «горячих» библиотек.
LLVM редко «светится» как отдельный продукт, но его компоненты регулярно оказываются в центре реальной разработки — от локальной сборки до проверок в CI. Ниже — ситуации, где LLVM приносит ощутимую пользу без необходимости глубоко погружаться в устройство компилятора.
Многие команды выбирают Clang не только ради сборки, но и из‑за качества диагностик: предупреждения часто точнее, сообщения понятнее, а флаги анализа богаче.
Санитайзеры (AddressSanitizer, UndefinedBehaviorSanitizer, ThreadSanitizer) помогают ловить ошибки памяти, гонки и неопределённое поведение на ранних этапах. Это особенно полезно в больших кодовых базах, где дефекты могут проявляться «случайно» и дорого обходиться.
Многие современные языки и их компиляторы выбирают LLVM как «движок» для выпуска машинного кода. Язык реализует свой фронтенд (разбор и семантика), а затем опирается на готовые бэкенды LLVM, чтобы получить поддержку разных процессоров и ОС.
Практический эффект — быстрее появляется кроссплатформенность и проще подключать оптимизации компилятора без написания собственного генератора кода с нуля.
LLVM‑инструменты часто встраивают в CI для улучшения качества:
В результате LLVM становится «страховочной сеткой»: ошибки ловятся до релиза, а требования к качеству фиксируются автоматикой. Если интересно углубиться в тему, начните с разделов про инструменты и оптимизации (см. /blog).
Даже если ваша основная разработка не связана с компиляторами, понимание LLVM помогает системно выстраивать сборку и качество. А «обвязку» вокруг этого (сервисы, админки, внутренние панели, небольшие веб‑инструменты для команды) часто хочется делать быстро — без тяжёлого старта и долгой настройки.
В таких задачах может помочь TakProsto.AI — vibe-coding платформа для российского рынка, где вы собираете веб, серверные и мобильные приложения из чата. Это удобно, когда нужно оперативно поднять сервис (React на фронтенде, Go + PostgreSQL на бэкенде, Flutter для мобильных клиентов), а затем уже встраивать привычные практики качества: CI, статический анализ, тестовые сборки с санитайзерами и воспроизводимые toolchain‑версии. Отдельный плюс для команд, которым важна локализация и контур данных: TakProsto.AI работает на серверах в России и использует локализованные/opensource LLM‑модели.
Если вы делаете контент про платформу или приводите коллег по реферальной ссылке, можно получать кредиты (earn credits program), а в тарифах (free/pro/business/enterprise) есть опции вроде деплоя, хостинга, кастомных доменов, snapshots и rollback, planning mode и экспорта исходников — чтобы не «запираться» в инструменте.
LLVM легко переоценить как «что-то для авторов компиляторов». На практике полезнее подход «маленькими шагами»: сначала научиться получать LLVM IR из обычного кода, затем — чуть-чуть читать его глазами, и только потом трогать оптимизации и бэкенды.
Clang (C/C++ фронтенд для LLVM) — самый простой вход.
Базовые утилиты LLVM: llvm-dis, llvm-as, opt, llc, llvm-profdata (опционально).
LLDB (если хотите посмотреть на экосистему отладки вокруг LLVM).
Обычно достаточно установить пакет «clang + llvm tools» из менеджера пакетов вашей ОС или дистрибутива LLVM. Дальше прогресс делается командами и маленькими экспериментами.
Начните с крошечного примера на C и попросите компилятор вывести IR:
clang -O0 -S -emit-llvm hello.c -o hello.ll
Если нужен бинарный bitcode (удобно для дальнейших инструментов), сделайте так:
clang -O0 -emit-llvm -c hello.c -o hello.bc
llvm-dis hello.bc -o -
Что смотреть в *.ll в первую очередь:
define ... @имя_функции(...) — объявление функции.%0, %1, %tmp — SSA-значения (переменные «один раз присвоили — дальше только читаем»).br, ret, icmp, add, call — базовые инструкции.entry:, if.then:) — структура потока управления.Первые чтения IR лучше делать на -O0: так связь с исходником понятнее.
После того как вы уверенно получаете IR, попробуйте прогнать его через оптимизатор и посмотреть разницу:
opt -O2 hello.ll -S -o - | head
Дальше логичный путь — инструменты качества кода (санитайзеры, статический анализ) и понимание, как они цепляются к пайплайну сборки. Для следующих шагов загляните в /blog, а если вы выбираете решение для команды или хотите поддержку/автоматизацию сборок — проверьте, что есть на /pricing.
LLVM часто воспринимают как «универсальный мотор» для компиляции и инструментов разработчика. Но при внедрении — особенно в продуктовую сборку или CI — полезно заранее понимать, где возникают реальные издержки.
Экосистема LLVM большая: IR, оптимизации, бэкенды, диагностика, отладка, санитайзеры, инструменты анализа. Это плюс, пока вы пользуетесь «по умолчанию», и минус, когда нужно отладить нестандартный кейс.
Типичные сложности:
LLVM активно развивается, и поведение (включая оптимизации и предупреждения) меняется от версии к версии. Для воспроизводимости результатов важно:
Иногда цель проекта — не максимальные оптимизации, а, например, минимальная сложность инфраструктуры, сверхбыстрая сборка в прототипах или строгая предсказуемость результатов. В таких случаях логично рассмотреть более узконаправленные компиляторы/пайплайны или иной формат сборки — не как «лучше/хуже», а как выбор под конкретные ограничения команды и продукта.
Лучший способ понять возможности ТакПросто — попробовать самому.