Разбираем, что такое Kubernetes, какие задачи он решает и почему часто усложняет запуск: стоимость, поддержка, безопасность и простые альтернативы.
Kubernetes часто называют «стандартом» для запуска контейнеров, но понимать его полезно не только тем, кто уже планирует миграцию. Эта статья пригодится фаундеру стартапа, продакт‑менеджеру, тимлиду и инженеру, который отвечает за деплой и доступность сервиса. Даже если вы никогда не будете поднимать кластер самостоятельно, знание базовых идей помогает трезво оценивать предложения подрядчиков, требования в вакансиях «нужен Kubernetes» и реальные потребности проекта.
Разберём, что Kubernetes делает на практике, почему он нередко создаёт больше работы, чем экономит, и в каких случаях он действительно оправдан. Цель — выбрать подходящую сложность инфраструктуры под текущий этап продукта, а не делать «как у больших компаний».
Оверкилл — это когда решение:
Важно: оверкилл не означает, что технология плохая. Это про несоответствие масштаба. Для небольшого сервиса лишний уровень абстракции часто превращается в постоянные «почему оно не развернулось», «почему не проходит health‑check» и «где смотреть логи».
Перед тем как идти в Kubernetes, честно ответьте себе:
Эти ответы задают рамки: где Kubernetes даст выигрыш, а где станет дорогой привычкой «на будущее».
Kubernetes (часто говорят «k8s») — это оркестратор контейнеров. Если упростить, он работает как диспетчер: следит, чтобы ваше приложение в контейнерах (например, Docker) всегда было запущено в нужном количестве копий, переживало сбои и обновлялось по правилам.
Контейнер сам по себе — это «упаковка» для сервиса. Но как только контейнеров становится много (разные сервисы, разные версии, несколько серверов), вручную управлять этим тяжело. Kubernetes берёт на себя операционные задачи: где что запустить, что перезапустить, как распределить нагрузку.
Кластер — это группа машин (виртуальных или физических), на которых запускаются ваши контейнеры.
Ключевая мысль: вы описываете «как должно быть», а Kubernetes пытается поддерживать это состояние автоматически.
Масштабирование: быстро поднять больше копий сервиса при росте нагрузки и убрать лишнее при спаде.
Отказоустойчивость: если контейнер упал или нода стала недоступной, Kubernetes перезапустит сервис и переразместит его на другой машине.
Релизы и обновления: помогает выкатывать новые версии постепенно (rolling update), откатываться при проблемах и снижать простой.
Итого: Kubernetes полезен, когда контейнеров и требований много. Но за этот «автопилот» придётся платить сложностью.
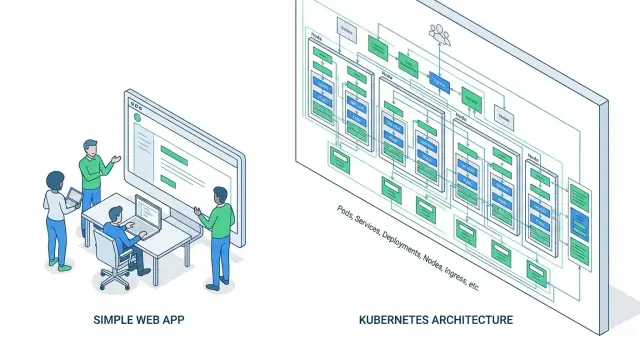
Kubernetes действительно «оркестрирует контейнеры», но на практике он заставляет мыслить не одним сервером и не одним контейнером, а набором взаимосвязанных объектов. Даже у небольшого сервиса быстро появляется несколько сущностей, которые нужно уметь читать, создавать и отлаживать.
Pod — минимальная единица исполнения. Обычно это один контейнер (иногда несколько), который Kubernetes запускает и перезапускает при сбоях. Важно: pod не «вечный» — он может быть пересоздан, получить новый IP и новое имя.
Deployment — объект, которым вы чаще всего управляете. Он отвечает за то, сколько копий pod должно быть, как делать обновления (rolling update), как откатываться назад и как обеспечивать доступность во время релиза.
Service — стабильная точка доступа к группе pod’ов. Он даёт постоянный адрес (виртуальный IP/имя в кластере) и балансирует запросы между репликами. Без Service вы постоянно «догоняете» динамические IP ваших pod’ов.
Когда нужно принять внешний HTTP/HTTPS‑трафик (домен, TLS‑сертификат, маршруты вроде /api и /admin), обычно подключают Ingress.
Ingress — это правила маршрутизации: какой домен и какой путь ведёт в какой Service. Но вместе с ним появляется ещё один слой: Ingress Controller (например, NGINX/Traefik), который нужно установить, обновлять и мониторить. Плюс — управление сертификатами, редиректами, лимитами, заголовками и нюансами WebSocket/HTTP2.
В результате вместо «настроить один reverse proxy» вы получаете набор объектов и компонент, который живёт внутри кластера и тоже может ломаться.
В Kubernetes конфигурацию принято выносить из образа и из команд запуска:
ConfigMap хранит «обычные» настройки: адреса сервисов, флаги, параметры приложения.
Secret — то же, но для чувствительных данных: пароли, токены, ключи. На практике это добавляет дисциплину: где и как хранить секреты, как их обновлять без простоя, кто имеет доступ, как не утечь ими в логи и дампы.
Даже простой деплой превращается в «набор деталей»: образ приложения + Deployment + Service + (Ingress) + ConfigMap/Secret. Это не «плохо» — просто важно заранее понимать объём новых понятий и ежедневной поддержки.
Kubernetes ценят не за «модность», а за перевод эксплуатации сервисов из ручного режима в предсказуемый и повторяемый. Это особенно заметно, когда приложений много, нагрузка плавает, а простой стоит денег.
Если контейнер упал, завис или нода стала недоступной, Kubernetes пытается вернуть систему в рабочее состояние автоматически: перезапускает контейнеры, пересоздаёт pod’ы и переразмещает их на других узлах. Это снижает число инцидентов, где «нужно зайти на сервер и руками поднять сервис», и помогает переживать частичные сбои без заметного простоя.
Когда трафик растёт, Kubernetes может увеличивать количество реплик сервиса и равномерно распределять запросы. Масштабирование становится процедурой: вы задаёте правила (например, по CPU/памяти), и система добавляет или убирает экземпляры. Это удобно для сезонных пиков, рекламных кампаний и продуктов, где трудно заранее предсказать нагрузку.
Kubernetes задаёт единый способ выкатывать обновления: постепенно, с контролем здоровья, с возможностью откатиться на предыдущую версию. В командах это превращается в общий «язык» релизов: меньше уникальных скриптов, меньше зависимости от конкретных людей, проще держать несколько окружений (dev/stage/prod) одинаковыми.
Вы описываете желаемое состояние системы в манифестах, а Kubernetes старается поддерживать его постоянно. Это повышает воспроизводимость и прозрачность изменений, но в реальности означает больше YAML‑файлов, проверок и дисциплины: нужны ревью, валидация, контроль конфигураций и аккуратная работа с секретами.
Итог: Kubernetes особенно хорош там, где важны непрерывность работы, масштабирование и единые правила эксплуатации — но плюсы раскрываются только если команда готова платить за сложность.
Kubernetes решает реальные задачи масштабирования и надёжности, но «плата за вход» и цена ошибок нередко оказываются выше выгоды — особенно у небольших команд и проектов с простой инфраструктурой.
Чтобы уверенно работать с кластером, придётся освоить не только контейнеры, но и большой набор концепций.
Во‑первых, YAML‑манифесты и их логика: deployment’ы, service’ы, configmap’ы, secret’ы, лимиты ресурсов, стратегии обновления.
Во‑вторых, контроллеры и «самовосстановление»: система постоянно приводит фактическое состояние к желаемому, и если вы описали желаемое неверно — она будет стабильно и быстро делать «не то».
Отдельная тема — сеть и доступы: DNS, ingress, сетевые политики, роли и права (RBAC). Ошибка в правах или сетевой политике часто выглядит как «у нас просто не работает», без очевидной причины.
Kubernetes — это набор взаимосвязанных систем. К ним обычно добавляются ingress‑контроллер, CNI‑плагин сети, CSI‑драйвер хранилища, инструмент сертификатов, autoscaling, реестр, GitOps/CI‑интеграции.
Каждый такой компонент нужно устанавливать, обновлять, конфигурировать и держать в совместимых версиях. Чем больше «пазлов», тем выше шанс, что обновление одной части неожиданно ломает другую.
Когда запрос «не проходит», важно понять, где именно проблема: в приложении, в service, в DNS, в ingress, в сетевых правилах, в прокси, в storage или в лимитах ресурсов.
При этом симптомы часто одинаковые (таймауты, 502, рестарты), а причина — на другом слое. Диагностика превращается в системную работу по проверке гипотез.
С Kubernetes вы берёте на себя эксплуатацию: мониторинг, логирование, алерты, бэкапы (включая данные и, иногда, состояние кластера), ротацию секретов, управление доступами и реагирование на инциденты.
Если это не закрыто людьми и процессами, кластер быстро превращается в источник постоянных мелких аварий и отвлекает от развития продукта.
Kubernetes часто продают как способ «упростить эксплуатацию», но на старте он почти всегда добавляет отдельный слой работы. В стартапе это особенно заметно: важнее быстро проверять гипотезы, чем строить идеальную платформу. Стоимость эксплуатации Kubernetes — это не только счета за серверы, но и постоянные затраты внимания.
Даже если вы понимаете, что такое Kubernetes, команде придётся договориться о стандартах и поддерживать их: как упаковываем сервисы, как выкатываем, как откатываем, где храним конфиги и секреты.
Типичные «статьи затрат» по времени:
Минимально жизнеспособный кластер обычно требует нескольких нод для отказоустойчивости, плюс системные компоненты (DNS, контроллеры, ingress, мониторинг). Это означает:
На практике сравнение Docker Compose vs Kubernetes часто упирается в простую вещь: Compose может жить на одном‑двух серверах, а Kubernetes редко получается экономным в малом масштабе.
Чтобы оркестрация контейнеров работала предсказуемо, понадобится связка инструментов: пайплайны деплоя, логирование, метрики/алерты, трассировка, управление секретами. Каждый компонент — это настройка, обновления, доступы и ответственность.
Главный минус — не деньги, а фокус. Если инфраструктура начинает диктовать темп продуктовой разработки, вы платите сложностью вместо скорости. И тогда вопрос «когда нужен Kubernetes» становится не техническим, а бизнес‑вопросом: окупает ли платформа время, которое вы перестали тратить на продукт?
Kubernetes раскрывается, когда нужно управлять большим количеством сервисов и инфраструктуры «на автомате». Но для многих команд он добавляет слои абстракции и новых точек отказа, которые просто не окупаются.
Если у вас 1–3 сервиса (например, API + воркер + база), низкая или средняя нагрузка и релизы происходят не каждый день, Kubernetes чаще становится дорогой заменой более простых инструментов.
Обычно это выглядит так:
Kubernetes требует постоянного внимания: обновления кластера, настройка сети, RBAC‑доступов, мониторинга, резервного копирования, политики безопасности, управление секретами. Если в команде нет выделенного DevOps/SRE (или хотя бы человека, который готов стать им «на полставки»), эти задачи начнут конкурировать с разработкой продукта.
Маркер простой: если вы уже сейчас откладываете «на потом» базовые вещи вроде алертов, бэкапов и регулярных обновлений зависимостей, Kubernetes почти наверняка усилит этот долг.
Kubernetes — распределённая система, а значит:
Если вам критичнее иметь одну понятную и воспроизводимую среду (один VM/сервер, один Compose‑файл, один пайплайн деплоя), то переход на кластер может снизить скорость разработки и усложнить эксплуатацию — парадоксально, но это частый сценарий.
Многие выбирают Kubernetes «на вырост», ожидая магии: автоскейлинг, rolling‑updates, самовосстановление. Если нагрузка предсказуема, а падения редки и легко чинятся, эти преимущества не превращаются в бизнес‑выгоду. В итоге вы платите временем и вниманием команды за функциональность, которой почти не пользуетесь.
Kubernetes — не «обязательный уровень» зрелости, а инструмент под конкретные боли. Он начинает окупаться, когда цена простоя, ручных операций и несогласованности между командами становится выше, чем стоимость эксплуатации Kubernetes.
Если простой измеряется потерянными деньгами, штрафами по SLA или прямым риском для бизнеса, Kubernetes полезен тем, что помогает переживать падения узлов и быстрее восстанавливаться.
Речь не про абстрактное «хотим, чтобы было надёжно», а про требования: автоматический перезапуск, распределение по зонам/узлам, плановые обновления без остановки сервиса, понятные сценарии восстановления.
Когда у вас десятки микросервисов и несколько команд, быстро появляется хаос: разные стандарты деплоя, разные способы настройки, «у нас работает, у вас нет». Kubernetes оправдан, если нужна единая платформа:
Это особенно актуально, если вы рассматриваете Kubernetes для стартапа не «на будущее», а потому что рост уже случился.
Когда трафик то в 10 раз выше, то почти нулевой (акции, сезонность, ночные провалы), автоскейлинг становится экономикой. Kubernetes помогает автоматически добавлять и убирать мощности, сохраняя скорость ответа и не переплачивая за постоянный «запас».
Если одна платформа обслуживает несколько команд, клиентов или проектов, важны границы: кто что может развернуть, к каким данным имеет доступ, какие лимиты ресурсов. Политики доступа, изоляция и правила сетевого взаимодействия — как раз те случаи, когда «просто оркестрация контейнеров» превращается в управляемую систему.
Если хотя бы два пункта — ваши ежедневные проблемы, вопрос «когда нужен Kubernetes» становится практическим, а не модным.
Если ваша цель — «чтобы сервис работал и обновлялся без боли», Kubernetes часто не обязателен. Для многих команд важнее предсказуемость, простота отладки и понятная цена владения, чем максимальная гибкость оркестрации контейнеров.
Недооценённый вариант. Один VPS/VM, конфигурация через systemd‑units, логи в journald, обновления через простой скрипт или CI — и у вас уже есть управляемый продакшен.
Плюсы: минимум зависимостей, прозрачная диагностика («почему упало» видно сразу), лёгкий бэкап, понятная стоимость. Минусы: масштабирование вширь придётся продумывать отдельно, а катастрофоустойчивость — вашей задачей.
Подходит, если у вас 1–3 сервиса и нагрузка умеренная, а главное — нужно быстро и надёжно запуститься.
Если вы уже используете контейнеры, Docker Compose часто закрывает 80% потребностей: несколько сервисов, общая сеть, переменные окружения, тома, зависимости между сервисами.
Compose удобен тем, что система «видна целиком»: один файл описывает окружение, его легко читать и менять. В связке с reverse‑proxy (например, Nginx/Traefik) и CI деплой становится почти «в один шаг». В малой команде сравнение уровня сложности почти всегда не в пользу Kubernetes: Compose даёт лучший time‑to‑production.
Если вы не хотите заниматься инфраструктурой вообще, PaaS часто оптимальнее, чем разбираться, почему Kubernetes сложный.
Варианты зависят от стека: приложения можно деплоить как контейнеры или напрямую из репозитория, а платформа берёт на себя сертификаты, роутинг, автоскейлинг (в рамках модели), мониторинг и простые роллбеки.
Компромисс: меньше свободы в сетевых настройках и окружении, возможен vendor lock‑in. Зато эксплуатация становится проще и дешевле по вниманию команды.
Если вы на этапе, где важнее скорость проверки гипотез, чем тонкая настройка инфраструктуры, стоит посмотреть на подход «приложение из чата» с готовым деплоем.
Например, TakProsto.AI — vibe‑coding платформа, ориентированная на российский рынок: вы описываете, что нужно сделать, в диалоге, а платформа помогает собрать веб/серверное/мобильное приложение (React, Go + PostgreSQL, Flutter), развернуть и хостить, подключить домен, а также использовать снапшоты и откат (rollback). Это не заменяет Kubernetes там, где уже десятки сервисов и строгие SLO, но часто закрывает ранние задачи «быстро собрать, запустить, обновлять без боли» — и уже потом решать, нужен ли вам кластер.
Отдельно полезны режим planning mode (когда вы сначала согласуете план изменений, а потом вносите их) и экспорт исходников: если продукт вырастет, вы не застрянете в «тупике платформы».
Если у вас нет постоянной нагрузки, а есть «срабатывания» (вебхуки, очереди, cron‑задачи, обработка файлов), serverless часто лучше любой оркестрации контейнеров.
Вы платите за фактическое выполнение, получаете автоматическое масштабирование и избавляетесь от заботы «держать сервисы тёплыми». Минусы: ограничения по времени выполнения, холодные старты, сложнее локально воспроизводить окружение.
Если вы всё же уверены, что «когда нужен Kubernetes» — это про ваш случай, управляемый Kubernetes снимает часть боли: установку/control plane, базовую доступность мастеров, иногда — обновления и интеграции с балансировщиками.
Но стоимость эксплуатации Kubernetes не исчезает полностью. На вас обычно остаются: настройки сети и ingress, политики доступа, наблюдаемость, управление ресурсами, деплой‑процессы, работа с лимитами, инциденты на уровне приложений и их взаимодействия.
Если выбираете managed‑вариант, оцените заранее, какие зоны ответственности реально уедут к провайдеру, а какие останутся на вашей команде — это и определяет, будет ли Kubernetes для стартапа оправдан или всё ещё слишком тяжёлым решением.
Решение «идём в Kubernetes» лучше превращать не в веру, а в проверку гипотез. Ниже — практичный чек‑лист, который помогает сравнить варианты (Kubernetes, Docker Compose, managed‑платформы) и не переплатить сложностью.
Сначала честно зафиксируйте, что вам нужно уже сейчас — независимо от выбранной платформы:
Если половина пунктов пока «на словах», Kubernetes не сделает магии — он добавит ещё один слой, который тоже нужно обслуживать.
Масштабирование имеет смысл только когда вы видите, что именно упирается в предел. Минимум, который стоит настроить заранее:
Без этого вы будете «автоскейлить вслепую» и лечить симптомы.
Проверьте базовые практики, которые должны быть в любом варианте:
Если это не закрыто, переход на Kubernetes часто лишь усложняет аудит и повышает цену ошибки.
Сделайте короткий «пилот» на реальном сервисе (1–2 недели):
Если Kubernetes не даёт заметной выгоды по вашим сценариям (скорость релизов, отказоустойчивость, изоляция команд), его ценность для проекта сейчас, скорее всего, ниже стоимости владения.
Переход в Kubernetes проще, когда он становится не «большой заменой всего», а логичным следующим шагом. Главная идея: сначала сделать приложение и процессы предсказуемыми в простой среде — и только потом переносить их в оркестратор.
Начните с контейнеризации и дисциплины вокруг конфигурации.
До Kubernetes важно стандартизировать выпуск и контроль качества в любой среде (VM, Docker Compose, простая платформа).
Определите минимальный набор: сборка образов, автотесты, прогон миграций БД, развёртывание, откат. Параллельно настройте мониторинг, алерты и централизованные логи — иначе в Kubernetes вы просто быстрее будете выпускать непонятные инциденты.
Заранее договоритесь, что именно должно измениться, чтобы Kubernetes был оправдан: рост нагрузки, число сервисов, требования по доступности, скорость релизов, необходимость изоляции команд.
Полезно оформить это как короткий документ: «мигрируем, когда X, Y, Z; не мигрируем, если нет владельца платформы или не закрыта наблюдаемость».
Лучший сценарий — пилотный сервис.
Сначала перенесите один не критичный, но показательный компонент: он должен иметь метрики, понятные SLO и реальную пользу от автомасштабирования/раскатки. Затем расширяйте периметр: ещё 1–2 сервиса, общий ingress, секреты, политики, и только после этого — более критичные части.
Не меняйте архитектуру одновременно с переездом. Миграция — это про упаковку и эксплуатацию, а не про перепроектирование. Если хочется «сделать по‑новому», отделите это в отдельный проект и привяжите к бизнес‑целям — иначе переход затянется и потеряет смысл.
Kubernetes (k8s) — оркестратор контейнеров: он следит, чтобы ваши сервисы в контейнерах были запущены в нужном количестве, перезапускались при сбоях и обновлялись по правилам.
Ключевая идея — декларативность: вы описываете «как должно быть», а система поддерживает это состояние.
Потому что он добавляет слой распределённой системы и много сущностей, которые нужно понимать и сопровождать: Deployment, Service, Ingress, ConfigMap/Secret, лимиты ресурсов, RBAC и т. д.
Если у вас 1–3 сервиса и редкие релизы, цена этой сложности часто выше выигрыша от «автопилота».
Спросите себя:
Ответы обычно быстро показывают, нужен ли вам кластер или хватит более простого варианта.
Обычно связка такая:
На практике чаще всего вы меняете Deployment, а Service обеспечивает «постоянный адрес» для трафика.
Ingress — правила маршрутизации внешнего HTTP/HTTPS-трафика (домены, пути, TLS) к Service.
Но вместе с Ingress почти всегда появляется Ingress Controller (например, NGINX/Traefik), который нужно установить, обновлять и мониторить. Это дополнительный компонент и потенциальная точка отказа.
Чтобы отделить код/образ от окружения:
Плюс: проще менять конфигурацию без пересборки образов. Минус: появляется отдельный контур управления секретами и доступами (кто может читать/обновлять, как ротировать, как не утечь в логи).
Типовые причины:
Практика: заранее иметь метрики, централизованные логи и минимальный набор алертов — иначе диагностика превращается в угадайку.
Чаще всего да, если совпадают хотя бы несколько условий:
Если этих болей нет, выгоднее вложиться в простую, но дисциплинированную инфраструктуру.
Рабочие варианты «для большинства»:
Выбор зависит от сценариев деплоя, требований к отказоустойчивости и доступного времени команды.
Managed Kubernetes снимает часть рутины (например, control plane и иногда обновления базовых компонентов), но не отменяет эксплуатацию.
На вашей стороне обычно остаются: настройка Ingress/сети, политики доступа (RBAC), наблюдаемость, управление ресурсами, CI/CD, работа с секретами и разбор инцидентов на уровне приложений.
Перед выбором полезно явно выписать границы ответственности провайдера и вашей команды.