Практическое руководство по Meilisearch: как развернуть серверный поиск, настроить индекс, фильтры и ранжирование, защитить API и улучшить UX.
Серверный поиск нужен, когда «найти по базе» перестаёт означать простой SQL LIKE. Пользователь ждёт мгновенного ответа, подсказок на лету, терпимости к опечаткам и адекватной сортировки — а приложение при этом должно оставаться предсказуемым по нагрузке и безопасным по доступам.
Скорость и стабильная задержка. Поисковый движок заранее строит индекс, поэтому запросы выполняются быстро даже на больших объёмах данных.
Релевантность «как у людей». Ранжирование, работа с опечатками, разбор слов, подсветка совпадений — всё это сложнее и дороже реализовать «на чистой БД».
Контроль данных и UX. Можно чётко управлять тем, какие поля ищутся, какие возвращаются, какие доступны для фильтров, и как выглядит выдача.
Meilisearch особенно хорош там, где важна интерактивность и «ощущение мгновенности»:
Обычно ориентируются на метрики:
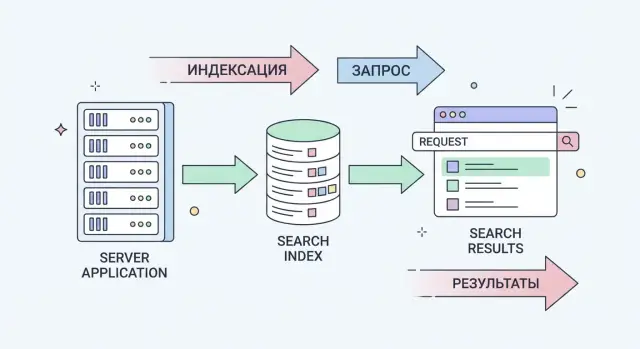
Данные загружаются в виде документов и превращаются в индекс. Затем приложение отправляет поисковый запрос, а движок возвращает результаты, применяя ранжирование и дополнительные правила (опечатки, синонимы, поля для поиска).
Meilisearch — не замена базе данных:
Meilisearch — это отдельный сервис поиска, который вы запускаете рядом с вашим приложением. Он хранит подготовленные данные в удобном для поиска виде и отвечает на запросы через API быстрее, чем обычная база данных при полнотекстовом поиске.
Сервер Meilisearch — процесс, который принимает документы, строит индекс и отвечает на поисковые запросы (обычно по HTTP).
Ваши данные — товары, статьи, пользователи, заказы: всё, по чему нужно искать. В Meilisearch данные отправляются как JSON‑документы.
Клиент в приложении — ваш backend или frontend, который вызывает API Meilisearch: загружает документы, обновляет настройки, выполняет поиск.
Документ — одна сущность в поиске. Например, один товар: { "id": 123, "title": "Кофеварка", "price": 7990, "category": "Кухня" }.
Индекс — «коллекция» документов одного типа и набор правил поиска для них. Обычно делают отдельные индексы для разных сущностей: products, articles, faq.
Индекс — это не «таблица», а структура, оптимизированная под быстрый поиск, подсветку совпадений, фильтры и сортировку.
Сервис живёт в трёх основных режимах:
Важно: операции загрузки/обновления выполняются как задачи — результат появляется не мгновенно, а после обработки (обычно быстро, но асинхронно).
Помимо текста документов, на результаты поиска заметно влияют настройки индекса:
Практичное правило: один индекс = одна логическая сущность с общей схемой полей и общими правилами релевантности.
type с фильтром.Так вы сохраняете понятные настройки и избегаете ситуации, когда правила поиска для «статей» неожиданно портят поиск по «каталогу».
Meilisearch удобно ставить «как утилиту»: один процесс, один HTTP‑порт, данные на диске. Важно заранее решить, где будет жить индекс и как вы будете обновлять версию — это экономит время при первом продакшен‑релизе.
Минимально нужно задать мастер‑ключ и путь к данным. По умолчанию Meilisearch слушает порт 7700.
docker run -d --name meili \
-p 7700:7700 \
-e MEILI_MASTER_KEY="change_me" \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:v1.5
curl http://localhost:7700/health
Если /health отвечает available, сервис поднят.
Индекс хранится на диске, поэтому:
Планируйте апгрейды как у базы данных: читайте release notes, тестируйте на копии данных, обновляйте версию образа/бинарника, затем прогоняйте базовые сценарии (фильтры, сортировка, подсветка).
MEILI_MASTER_KEY, ключи не светятся в логах и CI.Индекс в Meilisearch — это «витрина» ваших данных. Чем аккуратнее вы подготовите документы, тем стабильнее будут релевантность, фильтры и скорость.
Обычно в документ кладут два типа полей:
Полезное правило: храните в индексе только то, что нужно для поиска/фильтрации/показа карточки. Всё «тяжёлое» (длинные тексты, большие JSON, служебные поля) лучше оставить в основной БД.
Выберите поле, которое всегда уникально и не меняется: id, sku, slug. Это будет primary key. Если «естественного» ключа нет — заведите отдельный. Смена идентификатора на ходу усложняет синхронизацию: для Meilisearch это удаление старого документа и добавление нового.
Фильтры и сортировка работают предсказуемо, когда типы данных единообразны:
2025-12-23) или timestamp;active, archived).Загружайте документы пачками (батчами) — так быстрее и проще контролировать ошибки. Для изменений используйте частичные обновления: обновляйте только поля, которые реально поменялись (например, цена и наличие). Удаление — отдельной операцией по id, чтобы индекс не «раздувался».
Синхронизацию лучше строить как поток событий: запись изменилась в БД → событие попало в очередь → воркер обновил Meilisearch. Для надёжности часто используют паттерн outbox (события пишутся в ту же БД и гарантированно доставляются). Если событийной системы нет, подойдёт периодическая задача (cron), но она даёт задержки и сложнее ловит удаления.
Хороший поиск ощущается «мгновенным» не только из‑за скорости, но и из‑за того, как вы показываете результаты: что именно выводите, как объясняете совпадения и как пользователь двигается по выдаче. Meilisearch помогает на уровне API — важно правильно собрать запрос и продумать интерфейс.
Минимальный запрос — это строка поиска и имя индекса. Дальше обычно добавляют поля для вывода и параметры UX: подсветку, фильтры, сортировку.
POST /indexes/products/search
Content-Type: application/json
{
"q": "кроссовки",
"limit": 20,
"offset": 0,
"attributesToRetrieve": ["id", "title", "price", "brand"],
"attributesToHighlight": ["title"],
"highlightPreTag": "<mark>",
"highlightPostTag": "</mark>"
}
В ответе вы получите массив hits (результаты) и метаданные (estimatedTotalHits, limit, offset). Эти данные удобно напрямую связывать с UI: количество найденного, текущая страница, состояние «ничего не найдено».
Для списков используйте limit и offset. Практика для интерфейса: 10–30 результатов на страницу (или на «подгрузку») — так вы не перегружаете сеть и не заставляете пользователя скроллить бесконечный список.
Если у вас автопоиск при вводе, держите limit ещё меньше (например, 5–10) и добавьте задержку (debounce) 150–300 мс, чтобы не отправлять запрос на каждый символ.
Подсветка (attributesToHighlight) делает выдачу понятной: человек сразу видит, почему документ попал в результаты. Для длинных текстов (описаний, статей) полезны сниппеты — краткие фрагменты вокруг совпадения. В интерфейсе показывайте 1–2 строки, иначе выдача превращается в «стену текста».
Сортировка нужна там, где есть бизнес‑логика: «сначала дешевле», «по рейтингу», «в наличии». Для этого поле должно быть пригодно для сортировки (число/дата) и заранее лежать в документе. В UI лучше явно обозначать режим: «По релевантности» (по умолчанию) и отдельные переключатели «По цене», «По новизне».
Автодополнение полезно разделять на два блока: подсказки‑запросы (что пользователь мог иметь в виду) и быстрые результаты (например, 3 товара/статьи). «Похожие запросы» можно строить простым способом: хранить популярные запросы и показывать их при пустой выдаче или коротком вводе. Главное — не мешать: подсказки должны ускорять выбор, а не перекрывать результаты.
Когда поиск используется не только для «найти по словам», а как навигация по каталогу, решают три вещи: фильтры, фасеты (агрегации) и сортировка. В Meilisearch это настраивается явно — и это плюс: вы заранее определяете, какие поля можно безопасно и быстро использовать в запросах.
Фильтры помогают сузить выдачу по структуре данных. Типичные варианты: category, price, status, tags, brand, in_stock.
Важно: фильтрация работает только по полям, объявленным filterable attributes. Например, для товаров вы заранее задаёте:
Если поле не объявлено фильтруемым, запрос с фильтром либо не сработает, либо вынудит вас «обходить» систему на уровне приложения — что обычно хуже и для UX, и для производительности.
Фасеты отвечают на вопрос: «сколько результатов в каждой категории/бренде/диапазоне?». Они нужны, чтобы рисовать боковую панель фильтров и показывать, какие варианты доступны.
Практика: фасеты обычно строят по тем же полям, что и фильтры (категории, бренды, теги), а диапазоны — по числовым полям (цена). Так интерфейс не предлагает «пустые» фильтры и помогает пользователю быстрее сузить выбор.
Сортировка включается через sortable attributes. Обычно сортируют по price, created_at, rating, иногда — по «популярности» или маржинальности.
Старайтесь формализовать бизнес‑правила: например, сортировка «сначала в наличии», затем по релевантности, затем по цене. Если правила меняются, проще обновить сортируемые поля и параметры запроса, чем переписывать логику на фронтенде.
Частые проблемы при запуске:
Правило простое: фильтруемыми и сортируемыми делайте только те поля, которые реально используются в UI и отражают структуру каталога.
Хороший поиск — это не только «нашёл/не нашёл», но и порядок результатов. В Meilisearch релевантность настраивается через несколько понятных рычагов — и именно они чаще всего определяют, довольны ли пользователи выдачей.
По умолчанию Meilisearch использует набор правил ранжирования (учёт опечаток, близость слов, важность полей, точные совпадения). На практике вы управляете релевантностью в основном двумя вещами:
searchableAttributes: какие поля участвуют в поиске и в какой очередности. Если title стоит выше description, совпадение в заголовке будет «сильнее».rankingRules: можно менять порядок правил под ваш сценарий (например, сильнее ценить точные совпадения или учитывать бизнес‑сортировку).Разбейте данные на поля «для поиска» и «для фильтров». Типичный набор для каталога: title, subtitle, description, brand, categories, а также атрибуты вроде color или material. Важно не добавлять в searchableAttributes всё подряд: лишние поля часто ухудшают выдачу и увеличивают «шум».
Синонимы помогают, когда пользователи формулируют одно и то же по‑разному: «кроссовки» ↔ «кеды», «ноутбук» ↔ «лэптоп». Но ими легко переусердствовать: слишком широкие синонимы склеивают разные намерения и приводят к нерелевантным результатам.
Стоп‑слова иногда полезны для служебных частиц («и», «в», «на»), но не добавляйте их без проверки: в некоторых доменах короткие слова важны (например, «Go», «C», «in vitro»).
Пользователи ожидают, что поиск «простит» ошибки. В Meilisearch можно тонко управлять допуском опечаток: минимальной длиной слова для исправлений, отключением опечаток для конкретных полей/слов (например, артикулы, модели, коды). Это снижает риск, что “A52” превратится во что-то неожиданное.
Соберите 30–100 типовых запросов: популярные, «пустые», с опечатками, синонимичные, уточняющие. Для каждого зафиксируйте ожидаемые топ‑результаты и периодически прогоняйте список после изменений настроек. Простая дисциплина «тестовых запросов» быстрее всего показывает, стало ли лучше — и где именно стало хуже.
Meilisearch управляется через API, поэтому безопасность начинается с правильной модели ключей, сетевых ограничений и наблюдаемости.
У Meilisearch есть master key (супер‑админ) и ключи с ролями/правами. Практичное правило: master key никогда не попадает ни во фронтенд, ни в логи, ни в клиентские приложения.
Держите ключи максимально «узкими»: доступ только к нужным индексам и только к нужным действиям (принцип минимальных прав).
Даже с правильными ключами полезно ограничить поверхность атаки:
Если фронтенд обращается напрямую, используйте только search key и следите, чтобы индекс не содержал чувствительных полей. Часто безопаснее делать поиск через backend: вы сможете добавлять обязательные фильтры (например, tenant_id = X) и скрывать служебные атрибуты.
Есть два типовых подхода:
tenant_id — проще поддержка, но критично обеспечить, чтобы фильтр невозможно было убрать (лучше через backend).Фиксируйте минимум: кто делал админ‑операции, какие индексы менялись, ошибки авторизации, всплески запросов, изменения ключей. Эти данные помогают разбирать инциденты и быстрее откатывать небезопасные настройки.
Meilisearch часто «летает» из коробки, но в проде скорость поиска зависит не только от движка, а от того, как вы обновляете индекс, наблюдаете систему и планируете рост.
Кэш полезен, когда запросы повторяются (типично для каталога и автокомплита). Кэшировать можно на нескольких уровнях:
Важно: не кэшируйте слишком долго, если данные обновляются часто — пользователи заметят устаревшую выдачу.
Частые мелкие обновления создают нагрузку и увеличивают очередь задач. Практичнее:
Помимо CPU/RAM стоит следить за «поисковыми» метриками:
Ориентир простой: больше документов и полей → больше индекс и выше требования к памяти.
Планируйте запас по:
Полезно различать два режима: «пиковая индексация» (импорт/реиндекс) и «пиковый поиск» (распродажи/кампании) — и понимать, где становится узко.
Для эксплуатационной устойчивости заранее подготовьте:
Так вы избегаете ситуации, когда поиск «жив», но качество или свежесть данных внезапно проседают.
Meilisearch чаще подключают не «напрямую из фронтенда», а через ваш бэкенд — так проще контролировать права доступа, кэширование и лимиты. Практичный подход — выделить единый слой, который отвечает за все поисковые запросы и настройки.
Сделайте на бэкенде эндпоинт вроде GET /api/search?q=...&filters=..., который:
filter в зависимости от пользователя (например, tenant_id = X);Это снижает связность: фронтенд не знает про ключи и тонкости индексов, а вы можете менять схему фильтров без массовых правок клиента.
У Meilisearch есть SDK и понятный REST API, поэтому интеграция обычно выглядит похоже:
Search API.Если SDK вам не подходит, используйте REST — это упрощает поддержку и переносимость.
Индекс должен обновляться так же надёжно, как и сама база данных. Типовые варианты:
Не полагайтесь только на «скрытие» в интерфейсе. Фильтруйте на уровне Search API: добавляйте ограничения по пользователю/роли/организации и держите чувствительные поля вне возвращаемых атрибутов.
Если вы делаете продукт и хотите быстро получить работающий поиск «под ключ», Meilisearch удобно встраивается в приложения, собранные на TakProsto.AI.
TakProsto.AI — это vibe‑coding платформа для российского рынка: вы описываете продукт в чате, а платформа помогает собрать веб‑приложение (React), бэкенд (Go) и базу (PostgreSQL), а затем подключить инфраструктуру. Для поиска это особенно полезно в двух местах:
Search API, схему документов для индекса и базовый UI поиска — и уже на реальных данных проверить релевантность.Плюс для проектов, где важны комплаенс и местная инфраструктура: TakProsto.AI работает на серверах в России, использует локализованные и open‑source LLM‑модели и не отправляет данные в другие страны. При необходимости можно экспортировать исходный код, настроить деплой/хостинг и подключить кастомный домен. По тарифам есть уровни free, pro, business и enterprise — это удобно, когда вы начинаете с пилота и постепенно масштабируетесь.
Подробнее о планах и возможностях — /pricing. Похожие практики интеграции и UX можно собрать в /blog, а технические детали — вынести в /docs.
Выбор поискового движка обычно упирается не в «кто быстрее», а в баланс: функциональность, стоимость владения и скорость внедрения. Meilisearch хорош там, где нужен понятный API, быстрый запуск и «приятный» поиск без длительной настройки.
Elasticsearch/OpenSearch — это комбайн: огромная гибкость схем, агрегаций, анализа текста, сложных запросов и экосистемы. Цена — сложность.
Meilisearch проще в эксплуатации и интеграции: меньше решений «как правильно настроить», быстрее получить результат и предсказуемее поддерживать небольшой командой. Но если вам нужны сложные агрегации, кастомные анализаторы, многоуровневые пайплайны индексации и нестандартная логика запросов — Elastic/OpenSearch часто окажутся более подходящими.
Algolia — SaaS: вы получаете сильный поиск «из коробки», панели, аналитику, высокий SLA и минимум DevOps. В обмен — плата за объёмы/операции и меньший контроль над инфраструктурой.
Meilisearch — self‑hosted (или managed у провайдеров): данные остаются у вас, вы контролируете окружение, сеть, изоляцию и стоимость на больших объёмах. Но администрирование, обновления и мониторинг — ваша зона ответственности.
Подумайте о практичных параметрах:
Если критичны нестандартные запросы, сложные агрегации, тяжёлая персонализация ранжирования на лету или глубокая интеграция с аналитикой на уровне поисковой платформы — Elastic/OpenSearch или Algolia могут закрыть задачу лучше.
Сделайте короткий POC: один индекс, 200–2000 реальных документов, 10–20 ключевых сценариев (поиск, опечатки, фильтры, сортировка, пагинация). Измерьте:
Если пилот «ложится» в требования без костылей — это лучший сигнал, что Meilisearch вам подходит.
Перед релизом поиска важно зафиксировать «минимально достаточное» состояние: чтобы пользователи уже получали быстрые и понятные результаты, а команда — контроль и точки роста.
id.searchableAttributes и displayedAttributes, чтобы поиск не «шумел» и не выдавал лишнее.filterableAttributes и sortableAttributes только для реально нужных полей (это влияет на память и скорость обновлений).Сфокусируйтесь на трёх вещах:
Если есть каталожные сценарии, заранее договоритесь, какие сортировки допустимы (например, по цене/рейтингу), и убедитесь, что они одинаково работают на вебе и в мобильных клиентах.
Не усложняйте: сделайте две конфигурации индекса (или два индекса) и направляйте 5–10% трафика во «второй вариант». Сравнивайте:
Нужно ли реиндексировать всё при изменении настроек? Иногда — да. Планируйте окно обслуживания и держите стратегию отката.
Почему фильтры не работают? Частая причина — поле не добавлено в filterableAttributes или данные имеют неожиданный тип.
Можно ли открывать поиск прямо из фронтенда? Да, но только с ограниченным ключом и без админ‑доступа.
Когда вам нужен не просто поиск по подстроке, а быстрые ответы, подсказки при вводе, терпимость к опечаткам, подсветка совпадений и предсказуемая релевантность. SQL LIKE и даже встроенный полнотекст в БД часто начинают проигрывать по задержке и UX, особенно на больших объёмах и под нагрузкой.
Meilisearch — это отдельный сервис, который хранит ваши данные в виде индекса и отвечает на запросы через HTTP API.
Типовой поток такой:
q + параметры (фильтры, сортировка, подсветка) и получает hits + метаданные.Запускайте Meilisearch там, где важны скорость и интерактивность:
Если нужна сложная аналитика, джойны и нестандартные запросы, Meilisearch не заменит БД и может быть не лучшим выбором.
Обычно смотрят на три группы метрик:
Практика: автопоиск часто держат в более строгих рамках, чем обычную выдачу.
Удобное правило: один индекс = одна логическая сущность с общей схемой и правилами релевантности.
products и articles (разные поля, фильтры, сортировки);type + фильтр.Так вы избегаете ситуации, когда настройки для одного сценария ломают качество поиска в другом.
Заранее продумайте документ как «карточку для поиска»:
title, description, brand) и для отображения (цена, ссылка, короткое описание);id, sku, slug) и не меняйте его без необходимости.Это упрощает синхронизацию и делает выдачу предсказуемой.
Чаще всего причина одна из двух:
filterableAttributes;Проверьте нормализацию данных (числа, даты, массивы тегов) и обновите настройки индекса, затем убедитесь, что обновления задач применились.
Для UI обычно достаточно:
limit 10–30, offset по страницам;limit 5–10 + debounce 150–300 мс.Не делайте слишком большие лимиты: это увеличивает нагрузку и ухудшает восприятие. Для объяснимости включайте подсветку (attributesToHighlight) и показывайте короткие сниппеты (1–2 строки) вместо длинных полотен.
Базовые практики:
Если есть мультиарендность, безопаснее делать поиск через свой Search API, который принудительно добавляет фильтр по tenant_id.
Meilisearch — не замена БД:
searchableAttributes, синонимы, правила ранжирования);Если критичны сложные агрегации и нестандартные запросы, иногда лучше смотреть в сторону Elasticsearch/OpenSearch; если нужен SaaS и минимум DevOps — в сторону Algolia.