Мониторинг для раннего продукта: что поставить в первые 48 часов, чтобы видеть ошибки, latency, фоновые задачи и ключевые бизнес-события без лишнего шума.
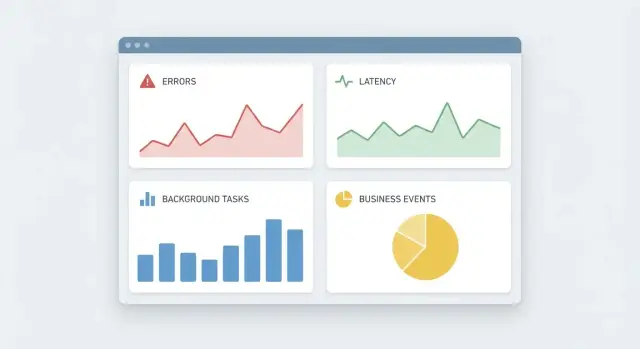
В первые дни после запуска мониторинг нужен не для красивых дашбордов. Он отвечает на несколько приземленных вопросов: продукт вообще жив, пользователь может сделать ключевое действие, и если что-то сломалось, где искать причину и насколько это срочно.
Сотни метрик на старте чаще вредят. Они создают шум, отнимают время на настройку и споры о формулировках, а главное - размывают внимание. В итоге команда смотрит на графики, но не понимает, что делать дальше.
Лучше начать с небольшого набора сигналов, на которые есть понятная реакция: кто отвечает, что проверяем, когда считаем инцидент закрытым.
Обычно достаточно четырех типов сигналов:
Важно не путать мониторинг с продуктовой аналитикой. Мониторинг отвечает на вопрос «работает ли система прямо сейчас» и помогает быстро чинить. Аналитика отвечает на вопрос «как люди пользуются» и куда развивать продукт.
На старте бизнес-события в мониторинге нужны не для воронок, а как датчик. Если события вдруг пропали или резко просели, это повод проверить релиз, интеграцию или фоновые задачи.
Мониторинг начинается не с графиков, а с ответа на простой вопрос: где заканчивается ваша система.
Если у вас один сервис, граница обычно ясна: API, база, очередь, внешние интеграции. Если сервисов несколько, заранее решите, что вы считаете «продуктом» в первые 48 часов: весь набор или только критичный путь (например, регистрация, оплата, создание проекта). И отдельно отметьте внешние зависимости, которые вы не контролируете, чтобы не «дежурить» по чужим сбоям.
Сразу определите минимум окружений. Частая ошибка раннего старта - мешать тест и прод в одних и тех же алертах. Достаточно двух уровней: прод (то, что видит пользователь) и тест (где вы ломаете). Алерты в первые двое суток должны быть только по проду, иначе вы быстро перестанете им верить.
Дальше важнее всего договориться о реакции. Не нужен сложный регламент, нужен короткий и понятный набор правил:
С каналами алертов тоже лучше не усложнять. В первые 48 часов оставьте 1-2 канала, которые вы точно читаете (например, чат и звонок для критичных). Заранее решите, что считается критичным, а что можно разбирать утром. Тогда мониторинг будет помогать, а не будить без причины.
В первые дни важны не все ошибки подряд, а те, из-за которых продукт перестает выполнять обещание: страница не открывается, заказ не создается, оплата не проходит, чат не отвечает.
Хорошая отправная точка - приоритет у 5xx, необработанных исключений и «успешных» ответов, где внутри пришел отказ.
Полезно сразу разделить ошибки пользователей и внутренние сбои. 4xx часто означают неправильный ввод, устаревшую ссылку или попытку без прав. Это не всегда авария. А вот 5xx, таймауты, паники, падения воркеров и «500 вместо 200» - почти всегда проблема вашей системы.
Чтобы ошибки не превращались в кашу, оставьте минимум тегов. Их достаточно, чтобы быстро найти источник и понять, что сломалось после релиза:
Версия особенно важна, если вы часто выкатываетесь и откатываетесь. Тогда видно, что всплеск начался ровно на конкретной версии.
Порог алерта лучше строить не на «любая ошибка», а на сочетании частоты и длительности. Например:
Чтобы не утонуть в одинаковых сбоях, включите группировку по месту падения: стек, сообщение, ручка, версия. Один корень проблемы - один алерт, а не сотня одинаковых уведомлений.
Скорость - это не только «как быстро открывается», но и «как часто бывает очень медленно». Поэтому одного среднего времени ответа почти всегда недостаточно: редкий, но длинный запрос легко прячется в среднем и при этом ломает опыт реальных людей.
Главные точки, которые стоит смотреть в первые дни: p50, p95 и p99. p50 показывает «типичную» скорость, p95 - как живет большинство в плохие минуты, а p99 - хвост, где часто сидят блокировки базы, тяжелые отчеты и таймауты. Если растут хвосты (p95/p99), продукт ощущается «тормозным», даже если p50 почти не меняется.
Важно разделить две вещи: серверное время и общее время ответа. Серверное время помогает понять, что именно «тяжелеет» внутри (код, запросы в БД, внешние сервисы). Общее время ответа показывает то, что видит клиент, и включает сеть и очередь. Бывает, что сервер работает быстро, но общая latency растет из-за очереди, перегретого балансировщика или проблем на стороне клиента.
Минимальный набор измерений в первые 48 часов - 5-10 самых важных маршрутов: логин, регистрация, главный экран, создание ключевой сущности, оплата (если есть). Выбирайте то, без чего продукт не существует.
Пороговые значения можно выбрать без гадания. Возьмите базовую линию за несколько часов нормальной работы и поставьте алерт на относительный рост (например, p95 стал в 2 раза хуже) плюс простой абсолютный «красный флаг» (например, p95 больше 2-3 секунд на ключевых действиях). Так вы поймаете деградацию рано и не утонете в ложных тревогах.
Фоновые задачи ломают продукт тихо. Пользователь не видит ошибку сразу, но позже не приходит письмо, не создается документ, не обновляются данные. Поэтому их стоит включить в мониторинг в первые сутки: именно здесь часто появляются зависания и бесконечные ретраи.
К фоновым задачам обычно относят очереди и воркеры (обработка событий, отправка уведомлений, генерация файлов), а также cron-задачи (регулярные пересчеты, очистка, синхронизации).
Минимум сигналов удобно держать в трех метриках:
Долю падений важно считать по типам задач. Иначе одна проблемная задача «съест» весь сигнал.
Отдельно поставьте алерт на застревание: нет прогресса N минут. «Прогресс» - это не ноль в очереди, а рост счетчика выполненных задач или сдвиг времени последнего успешного выполнения. Очередь может быть пустой, но cron может перестать запускаться.
С ретраями договоритесь заранее. 1-3 повтора - нормальная страховка при временных сбоях. А вот рост числа попыток и увеличение времени в очереди одновременно уже выглядит как инцидент.
В логах задач пишите то, что помогает за 2 минуты найти причину: тип задачи, id, входные параметры в безопасном виде, номер попытки, время старта и окончания, и короткое поле «почему упало» (код ошибки, источник, контекст).
Ошибки и скорость показывают, что системе плохо. Бизнес-события показывают, что продукт перестал приносить пользу. На старте достаточно нескольких событий, которые прямо отражают ценность.
Выберите 3-5 действий, без которых вы не готовы жить: регистрация, подтверждение контакта, создание ключевой сущности (проект, заказ, задача), оплата или запуск пробного периода. Важно, чтобы события были редкими, но важными. Иначе вы снова получите шум.
Одно событие почти всегда имеет варианты: успешно, отклонено, отменено, в обработке. Сразу договоритесь, какой статус считается успехом и где вы фиксируете событие (клиент, сервер, платежный провайдер). Лучше начинать с серверной фиксации, чтобы не зависеть от сбоев на фронтенде.
Чтобы видеть проблему быстро, считайте простую конверсию по шагам, без усложнений. Например: «регистрация -> создание первого проекта -> первая оплата». Не нужно строить сложные воронки, пока вы не уверены, что сами события стабильны.
Полезный алерт для первых дней: «0 событий за N минут». Если за час не было ни одной регистрации или ни одной оплаты (когда обычно бывают), это часто реальная авария: сломалась форма, отвалилась база, зависла фоновая задача.
Чтобы связать бизнес-провал с техникой, прокидывайте request id (или trace id) через логи и события. Тогда вы сможете открыть конкретную оплату, увидеть ее id и найти точную ошибку в логах или в обработчике очереди.
В первые 48 часов мониторинг должен отвечать на простые вопросы: что сломалось, где стало медленно, и затронуло ли это ключевой сценарий. Все, что не помогает быстро принять решение, почти всегда превращается в шум, расходы и усталость от алертов.
Самая частая ошибка - пытаться снять «все на всякий случай». В итоге появляются десятки графиков без смысла и логи, в которых невозможно найти проблему.
Обычно лишним на самом старте становится следующее:
Практичное правило: добавляйте сигнал только под конкретный вопрос. Например: «после релиза пользователи не могут войти» или «очередь задач растет быстрее, чем обрабатывается». Если вопроса нет, сигнал почти точно не нужен.
Хороший подход - сначала выбрать 3-5 тревожных сценариев и мерить только то, что подтверждает или опровергает каждый из них. Трейсы включайте выборочно: для самых важных ручек (логин, оплата, создание заказа) или по сэмплингу, чтобы видеть типичные проблемы, но не собирать все подряд.
Если вы собираете прототип и хочется добавить в теги все, что есть в данных, остановитесь. Лучше оставить 1-2 безопасных измерения (например, тип операции и код ответа), а детали конкретного пользователя искать уже через структурированные логи по запросу.
Перед тем как что-то логировать или вводить метрику, спросите себя:
Так вы останетесь с минимумом, который реально спасает, и не начнете платить шумом.
За первые двое суток цель простая: получить несколько надежных сигналов, чтобы быстро понять, жив ли продукт и где он ломается. Важнее скорость реакции, чем идеальная красота графиков.
Сделайте минимум, который ловит реальную боль пользователя и технические аварии:
После этого у вас уже будет базовая картина: ошибки, скорость, фон.
Теперь привяжите технику к смыслу. Определите 3-5 бизнес-событий и начните фиксировать их в логах или простой аналитике: регистрация, успешный платеж, создание сущности, завершение сценария, отмена.
Дальше настройте 5-8 алертов и один дашборд «здоровье». Пример набора:
В конце обязательно сделайте проверку «что будет, если»: искусственно вызовите тестовую ошибку, задержку, зависшую задачу. Если алерт не сработал, его как будто нет.
Первая неделя чаще ломает мониторинг не из-за инструментов, а из-за привычек. Хочется увидеть все и сразу, и система превращается в ленту уведомлений, которым никто не верит.
Самые частые ошибки:
Короткий пример: после релиза фоновой задачи очередь начала расти, но алерт был настроен на каждую ошибку в логах. Логи шумели из-за тестовых запросов, команда привыкла игнорировать уведомления, и реальный сигнал про очередь не стал заметным. Через несколько часов пользователи начали жаловаться на задержки.
Чтобы не попасть в эту яму, держите простые правила:
Сделайте один главный экран, который вы открываете каждый день. На нем только то, что реально говорит, жив ли продукт: ошибки (5xx и критичные исключения), latency (p95 или p99), очередь и фоновые задачи, плюс 1-2 ключевых бизнес-события.
Пять быстрых вопросов, на которые этот экран должен отвечать:
Если был релиз, добавьте мини-проверку: текущая версия, время деплоя, и есть ли резкий пик ошибок или latency в первые 15-30 минут.
Когда сработал алерт, держите короткую 10-минутную процедуру, чтобы не метаться:
Новый сигнал добавляйте только когда он проходит простой критерий: по нему можно принять понятное действие за 10 минут, и он уже хотя бы раз помог (или точно помог бы) поймать реальную поломку.
После вечернего релиза команда замечает странное: регистраций стало в 2 раза меньше. При этом в логах почти нет явных ошибок. На глаз кажется, что «маркетинг просел» или «люди передумали».
Первое, что помогает, - связать скорость и бизнес-события. В метриках видно, что p95 latency на эндпоинте регистрации вырос с 400 мс до 6-8 секунд. Ошибок 500 почти нет, но доля ответов 200 с очень долгим временем резко выросла.
Дальше смотрим критичные события по шагам: registration_started осталось на месте, а registration_completed упало. Значит, трафик есть, люди пытаются, но не доходят до конца. На стороне клиента это часто проявляется таймаутами и отмененными запросами.
Третья подсказка - фоновые задачи. После регистрации пользователю должно уйти письмо или уведомление, и это делает очередь. Очередь не падает, но глубина растет, а обработанных задач почти нет: воркер жив, но завис на внешнем вызове и держит все задачи.
Дальше действия по порядку:
registration_completedВ постмортем стоит записать: какие сигналы сработали, какие пороги были слишком высокими, где не хватило метрики «обработано задач за минуту», и кто отвечает за первые 15 минут после релиза.
Первые 48 часов мониторинг нужен, чтобы увидеть проблемы раньше пользователей. Дальше задача другая: закрепить этот минимум как привычку и не превратить его в шум.
Начните с короткой ревизии алертов вместе с командой. Не обсуждайте абстрактно, смотрите на факты: какие уведомления помогли принять решение, а какие просто отвлекали. Если на алерт нельзя ответить действием за 10 минут, чаще всего он лишний или ему нужен другой порог.
Чтобы минимум не расползался, зафиксируйте стандарт:
Глубокие метрики и трассировка нужны не сразу. Добавляйте их, когда вы уже видите деградацию, но не понимаете причину, или когда продукт начинает часто меняться и растет число зависимостей. Простой признак, что пора: проблемы стабильно ловятся по ошибкам и latency, но на поиск источника уходит слишком много времени.
Если вы делаете MVP на TakProsto (takprosto.ai), имеет смысл заложить этот минимум еще до первых пользователей: ошибки, p95 на ключевых действиях, состояние очередей и 3-5 критичных бизнес-событий. Остальное добавляйте только после пары реальных инцидентов, когда станет ясно, какие сигналы действительно экономят время.
На старте важнее быстро понять, что продукт «жив» и ключевой сценарий работает, чем разглядывать десятки графиков. Большое число метрик создает шум: вы тратите время на настройку и споры, но не понимаете, что именно чинить. Лучше оставить несколько сигналов, по которым у команды заранее есть понятное действие.
Начните с того, что реально ломает пользователя: всплески 5xx и необработанные исключения, деградация p95 на ключевых ручках, остановка воркеров или рост очереди, пропажа критичных бизнес-событий. Если алерт не ведет к конкретной проверке или решению за 10–15 минут, его лучше не включать в первые двое суток.
Мониторинг отвечает на вопрос «работает ли система прямо сейчас» и помогает быстро найти и устранить поломку. Продуктовая аналитика отвечает на вопрос «как люди пользуются» и куда развивать продукт. На старте полезно держать это раздельно: мониторинг должен быть быстрым и аварийным, без длинных отчетов и сложных воронок.
Сначала зафиксируйте границы системы: что вы считаете «продуктом» в эти 48 часов и какие внешние зависимости вы не контролируете. Затем разделите окружения: алерты должны быть только по продакшену, иначе вы быстро перестанете им доверять. И самое важное — договоритесь о реакции: кто дежурит, за сколько минут замечает алерт и когда вы откатываете релиз вместо долгого «покопаюсь еще».
Ставьте пороги не на «любую ошибку», а на частоту и длительность, чтобы не ловить единичные случайности. Практичный старт — алерт на превышение доли ошибок за окно времени и отдельный алерт на резкий рост относительно базовой линии после деплоя. Обязательно включите группировку по месту падения (тип исключения, ручка, версия), иначе один баг превратится в сотни уведомлений.
Среднее время ответа часто скрывает редкие, но очень долгие запросы, которые и портят опыт. Поэтому смотрят перцентили: p50 показывает типичную скорость, p95 — что видит большинство в плохие минуты, p99 — тяжелый хвост, где обычно сидят блокировки и таймауты. Если растут p95/p99, пользователи чувствуют «тормоза», даже когда p50 почти не меняется.
Проверьте минимум из трех вещей: глубину очереди, время от постановки до выполнения и долю падений по типам задач. Дополнительно нужен сигнал «нет прогресса N минут», потому что очередь может быть пустой, а cron или воркер уже не выполняется. И заранее договоритесь про ретраи: несколько повторов — нормально, но рост попыток вместе с ростом времени в очереди обычно означает инцидент.
Это простой датчик поломки: если при обычном трафике внезапно нет регистраций, оплат или создания ключевой сущности, часто проблема техническая, а не «люди перестали приходить». Для такого алерта выберите события, которые действительно редкие и важные, и фиксируйте их на сервере, чтобы не зависеть от сбоев фронтенда. Дальше при расследовании помогает связка через request_id/trace_id, чтобы быстро найти конкретный запрос в логах.
Не добавляйте теги с высокой кардинальностью вроде user_id, email или номера заказа в метрики и алерты — это раздувает стоимость и делает графики бесполезными. Для быстрого поиска причины чаще всего хватает компонента (frontend/api/worker), операции или ручки, типа ошибки и версии сборки. Детали конкретного пользователя лучше доставать через структурированные логи по запросу, когда уже понятно, что именно сломалось.
Оставьте один «экран здоровья», который за минуту отвечает на вопросы: есть ли всплеск 5xx и критичных исключений, не просел ли p95/p99 на ключевых действиях, не растет ли очередь и идут ли 1–2 важные бизнес-события. Если был релиз, сразу сверяйте версию и время деплоя с началом проблем. Новый сигнал добавляйте только если по нему реально можно принять действие быстро, иначе он станет еще одним источником шума.