Разбираем, почему агентные системы разваливаются в проде, и как спроектировать надёжную архитектуру с повторами, машинами состояний и наблюдаемостью.
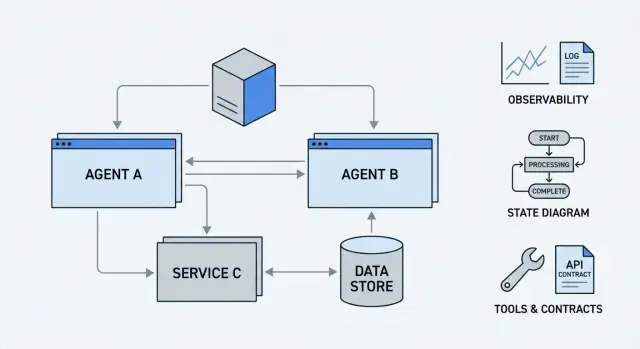
Агентная система — это связка LLM + инструменты + окружение, где модель не просто отвечает на вопросы, а сама планирует шаги, вызывает API, ходит в базы данных, запускает задачи и принимает решения на основе обратной связи.
Такие системы уже используют для поддержки клиентов, аналитики данных, internal tooling, автоматизации DevOps, маркетинговых операций и работы с документами. В прототипах они выглядят впечатляюще: пара промптов, несколько инструментов — и кажется, что можно сразу ставить в прод.
В лабораторных демо всё обычно «сходится»: данных мало, запросы контролируемы, нагрузка невысокая, а человек всегда рядом, чтобы подправить ответ. В продакшене всё иначе:
То, что казалось «немного нестабильным», превращается в постоянные падения сценариев, залипшие воркфлоу и трудноотлавливаемые баги.
Ключевые источники хрупкости агентных систем:
Без явной архитектуры под эти риски агент ведёт себя как «чёрный ящик», чьи сбои почти невозможно воспроизводить.
Цель этого материала — показать практичные инженерные приёмы, которые помогают агентным системам не рассыпаться при реальной нагрузке: паттерны повторов и идемпотентности, машины состояний и workflow-оркестрацию, жёсткие контракты инструментов, стратегии обработки ошибок и наблюдаемость.
Дальше по разделам мы разложим эти элементы по полочкам и соберём из них архитектурный каркас, пригодный для продакшена.
Одноразовый LLM-вызов — это просто функция:
вход → промпт → один ответ модели → выход.
Нет состояния, нет циклов, нет внешних вызовов. Такой вызов легко масштабировать и отлаживать: запрос либо прошёл, либо нет.
Агент — это уже процесс:
цель → план → серия шагов с инструментами и памятью → результат.
Он делает несколько итераций, принимает решения по ходу, читает и обновляет состояние, ходит во внешние сервисы и может работать долго (минуты, часы, иногда днями через планировщик).
Как только вы добавляете:
вам приходится решать вопросы, которых не было у single-call LLM:
Именно здесь и рождаются проблемы надёжности.
Практически всегда можно нарисовать одни и те же блоки:
Агент почти никогда не живёт в вакууме. На его надёжность напрямую влияют:
По сути, агентная система — это не "умный промпт", а распределённое приложение, где LLM — лишь один из компонентов, а не центр вселенной.
Даже аккуратно собранный прототип агента часто разваливается при первых реальных нагрузках. Основные причины почти всегда одни и те же.
LLM по природе вероятностна: она может галлюцинировать факты, нарушать формат ответа, зависать на сложных промптах и упираться в таймауты.
Типичные сбои:
Без жёстких проверок формата, валидаторов и ограничений по времени такие ответы быстро приводят к отказам всего сценария.
Промпт легко ломается при малейшем изменении: другой язык пользователя, новый тип запроса, дополнительное поле в контексте.
Когда:
любой релиз превращается в лотерею. Система зависит от текста промпта сильнее, чем от кода.
Частая проблема — инструменты (API, базы, сервисы), к которым обращается агент, не имеют:
В итоге агент может зациклиться на бесконечных ретраях, заблокировать внешнюю систему или, наоборот, сдаться при первой сетевой ошибке.
Без управляемого состояния агент не может корректно продолжить после сбоя: неизвестно, что уже сделано, что ещё нет, и какой шаг безопасно повторять.
Отсутствие идемпотентности приводит к:
Когда нет нормальных логов, трассировок и метрик, команда видит только «что-то упало».
Без:
невозможно понять, где именно агент ломается, какие сценарии нестабильны и что нужно чинить в первую очередь.
Поведение LLM-агента нестабильно по определению, поэтому повторы и идемпотентность — обязательная часть архитектуры, а не «обёртка вокруг HTTP».
Стоит сознательно разделять три слоя повторов:
Важно, чтобы эти уровни не умножали повторы бесконтрольно: задавайте лимиты попыток и общий дедлайн на запрос.
Полезно явно классифицировать ошибки:
Стратегия: для transient-ошибок — 3–5 попыток, экспоненциальный backoff с джиттером, общий дедлайн на шаг/запрос (например, 20–30 секунд).
Чтобы повторы были безопасными, операции должны быть идемпотентны: повторный вызов с теми же входными данными не меняет итоговое состояние.
Приёмы:
Минимальная схема аудита и идемпотентности шагов агента может выглядеть так:
CREATE TABLE agent_steps (
request_id TEXT, -- внешний запрос / сессия
step_id INT, -- логический шаг агента
attempt INT, -- номер попытки шага
status TEXT, -- pending / success / failed
input_hash TEXT, -- хэш входных данных шага
output_data JSONB,
error_code TEXT,
created_at TIMESTAMPTZ,
PRIMARY KEY (request_id, step_id, attempt)
);
Логика агента:
(request_id, step_id).success и input_hash совпадает — не выполняет шаг повторно, а переиспользует результат.Такой подход позволяет безопасно ретраить шаги, не дублируя реальные бизнес-операции.
Наивная схема агента часто выглядит так:
while not done:
ответ = LLM(контекст)
выполнить_инструменты(ответ)
обновить_контекст()
Цикл не ограничен явной моделью состояния. Вся «логика», на каком шаге мы находимся, какие инструменты уже вызывались, что можно повторять, а что нет, живёт только в тексте промпта и внутренних «рассуждениях» модели.
Результат:
Нужна явная модель состояния вне LLM.
Машина состояний (FSM) задаёт конечный набор состояний и переходов между ними. Пример высокоуровневых состояний агента:
INIT — получили задачуPLANNING — спланировали шагиEXECUTING_STEP — выполняем текущий шаг / инструментWAITING_EXTERNAL — ждём внешнего события или callbackDONE — задача завершенаFAILED — невосстановимая ошибкаПереходы между состояниями запускаются событиями:
user_request_receivedtool_result_receivedtimeoutvalidation_errorcancelLLM в этой схеме не «гуляет» как хочет. Он получает текущее состояние и может предложить действие (следующий шаг, набор инструментов), но оркестратор проверяет, допустим ли такой переход и что делать при ошибке.
Важно разделять:
Бизнес-состояние нужно доменной логике и пользователю. Системное — только оркестратору и мониторингу. Разделение упрощает миграции, отладку и повторное выполнение шагов без порчи бизнес-данных.
Состояние агента должно лежать в надёжном хранилище, а не только в промпте:
task_id / conversation_id{
"fsm_state": "EXECUTING_STEP",
"current_step": "PAYMENT_VALIDATION",
"attempt": 2,
"business_state": { "order_id": 123, "total": 49.9 },
"last_error": null
}
Оркестратор при каждом событии:
Так обеспечивается идемпотентность: при повторном событии (например, дубль callback’а) мы видим, что состояние уже перешло дальше, и просто игнорируем лишний вызов.
Возьмём сложный запрос: «Оформить кредит и открыть счёт компании».
Workflow можно задать так:
COLLECT_COMPANY_DATA — агент собирает реквизиты и документы.RISK_CHECK — вызывается скоринговый сервис.OFFER_SELECTION — LLM подбирает подходящий продукт по правилам.ACCOUNT_OPENING — вызов внутренних API открытия счёта.CONTRACT_SIGNING — генерация и подписание документов.DONE / FAILED — финальный статус.Каждый шаг — отдельное состояние. LLM может:
COLLECT_COMPANY_DATARISK_CHECKно не может «перепрыгнуть» напрямую к CONTRACT_SIGNING, пока FSM не позволит такой переход.
Такой подход делает поведение агента предсказуемым: последовательность шагов фиксирована, точки ошибок и повторов формализованы, а LLM используется там, где нужна гибкая генерация текста и принятие мягких решений, а не для управления всей жизнью процесса.
Агент без жёстких контрактов с инструментами превращается в гадалку: он «примеряет» аргументы и интерпретирует ответы как придётся. Это главный источник скрытых, плохо воспроизводимых багов.
Контракт инструмента — это чётко определённые:
Агент не «угадывает» формат, а опирается на этот контракт при планировании и верификации своих действий.
Используйте формальные описания вместо «устной договорённости» в коде:
Схема должна быть единственным источником правды. Генерируйте из неё типы клиента, документацию и подсказки для промптов, чтобы агент и разработчики смотрели на один и тот же контракт.
Текстовые сообщения удобны человеку, но бесполезны для стратегии агента. Инструмент должен возвращать машинно-обрабатываемые признаки:
status (например, success | temporary_error | permanent_error | invalid_input);error_code из ограниченного набора (enum);error_message как дополнение.Так агент может принимать осознанные решения: повторить запрос, скорректировать аргументы, отключить инструмент или завершить задачу с объяснением.
Минимум два уровня проверки:
До вызова инструмента: валидация аргументов по схеме.
После вызова: валидация ответа.
Нарушения контракта фиксируйте как ошибку инструмента, а не агента. Это сильно ускоряет отладку.
Контракты инструментов должны эволюционировать аккуратно. Базовые правила:
amount из «в рублях» в «в долларах» без смены имени/версии).v1, v2) и параллельная поддержка, пока агенты не мигрируют.deprecated, отдельные алармы.Так вы избежите ситуации, когда малозаметное изменение в одном микросервисе приводит к каскадным сбоям всех агентов в продакшене.
Агентная система живёт в мире ненадёжных сетей, медленных API и непредсказуемых моделей. Если ошибки и таймауты не спроектированы заранее, агент начинает вести себя «магически» и непоследовательно.
Для LLM-агентов критичны те же проблемы, что и для микросервисов, но осложнённые стохастичностью модели:
Если не зафиксировать политику обработки каждого из этих сценариев, агент будет каждый раз «решать с нуля», и ошибки станут хаотичными.
Важнее всего различать два класса ошибок:
Для агента это разные ветки сценария:
Смешивание этих двух типов ведёт либо к бесконечным повторам, либо к бессмысленным отказам.
Circuit breaker для инструментов агентов работает так же, как и в обычных сервисах:
Вместе с этим нужны явные политики:
Главное — описать это как часть протокола агента, а не надеяться, что LLM сам догадается.
Агент не должен «притворяться, что всё получилось». Нужен явный шаблон сообщений об ошибках, который модель использует в промпте:
Отдельно важно различать:
Каждый серьёзный провал агента должен оставлять след:
Эти данные нужны не только для отладки, но и для последующего обучения: по ним можно строить эвристики, улучшать промпты и определять, где агенту вообще не стоило пытаться действовать автоматически.
Надёжный агент без наблюдаемости быстро превращается в «чёрный ящик». Сначала нужно договориться о сигналах, которые вы собираете.
Помимо стандартных RPS и latency, важны:
Каждый лог‑запись должна содержать чёткий контекст:
{
"trace_id": "...",
"user_id": "...",
"task_id": "...",
"step_id": 7,
"agent_name": "support-bot",
"tool": "crm.lookup",
"level": "error"
}
Без таких идентификаторов сложно понять, где именно сломался сценарий.
Логируйте промпты и ответы частично и с маскированием:
Минимальный набор триггеров:
Такие алерты позволяют поймать момент, когда агент начал «ломаться», задолго до жалоб пользователей.
Надёжность агента начинается не с продакшена, а с того, насколько безопасно и системно вы умеете на нём экспериментировать.
Агенту нужна полноценная песочница:
В песочнице вы проверяете рискованные стратегии (новые инструменты, автодействия без подтверждения пользователя) и паттерны восстановления после сбоев, не рискуя реальными деньгами и данными.
Для агентных систем юнит-тесты — это не только про код:
Температура модели в тестах — 0, чтобы минимизировать вариативность.
Сценарные (end-to-end) тесты фиксируют последовательность шагов агента: запросы к модели, ответы, вызовы инструментов.
Подход record & replay:
Так вы проверяете логику оркестрации и обработки состояний, не упираясь в нестабильность модели и квоты провайдера.
Нагрузочные тесты для агентов важны по двум причинам:
Добавьте моделирование сбоев внешних сервисов: задержки, 5xx, кривые ответы, частичную недоступность. Это позволяет проверить стратегии повторов, обратных откатов и переключения на деградированный режим.
Даже хорошая песочница не заменяет эксперименты на реальном трафике.
Практики:
Так вы эволюционируете агента по шагам, удерживая риск под контролем.
Продакшен-агент — это не только prompt и модель, но и дисциплина деплоя. Ошибки здесь бьют по устойчивости не хуже багов в коде.
Для LLM-агентов критично конфигурировать «ограничители» отдельно для dev, staging и prod:
На dev можно разрешить более длинные таймауты и детальные логи, на prod — агрессивнее резать по времени, но с продуманными ретраями и fallback’ами. Конфигурацию лучше хранить в одном формате (например, YAML/JSON), но с различными профилями окружений.
Основной принцип — «конфигурация через код»: все важные значения описаны в репозитории и проходят code review. Сюда входят:
Переменные окружения используются для чувствительных и быстро меняющихся вещей: ключи, URL сервисов, лимиты, привязанные к инфраструктуре. Так вы сохраняете повторяемость и при этом можете оперативно менять настройки без релиза.
У агентов часто есть долговременное состояние: сессии, контексты, прогресс workflow. Чтобы не «ронять» прод при изменении схем:
/tools/report/v1, /tools/report/v2 и поэтапно переводите трафик.Хорошая практика — blue‑green или canary‑деплой: часть трафика уходит на новую версию агента, и при проблемах откат занимает минуты.
Новые возможности агента лучше включать через feature flags:
Версионируйте не только код, но и:
Одновременно держите несколько поколений: новая версия обкатывается на части трафика, старая остаётся безопасным fallback’ом. Это делает эволюцию агентной системы прогнозируемой, а инциденты — управляемыми.
Агентная архитектура легко превращается в дорогостоящий эксперимент, если не договориться заранее о границах, ответственности и рисках. Ниже — типичные ловушки и ориентиры, когда агенты действительно уместны.
1. «Агент умеет всё»
Один универсальный супер‑агент с инструкцией «решай любые задачи»:
2. Монолитный промпт вместо архитектуры
Вся логика зашита в один длинный системный промпт:
Это «монолитный промпт» — аналог монолитного приложения без слоёв и сервисов.
3. Скрытые побочные эффекты инструментов
Инструменты:
Агент в такой среде неотличим от хаотичного скрипта, а не от управляемого компонента.
4. Чрезмерная автономия без ограничений
Агенту разрешено всё: любой инструмент, любая длительность сессии, любой объём запросов наружу. Это ведёт к:
Разбивайте на специализированные роли:
Вместо одного «агента на всё» лучше несколько агентов или модулей с узкой зоной ответственности и явным контрактом.
Ограничивайте:
Явно фиксируйте, что агент не делает: не пишет в прод‑БД, не шлёт письма клиентам, не меняет конфигурацию без дополнительного подтверждения.
Откажитесь от агентной архитектуры в пользу детерминированной логики, если:
Во многих случаях достаточно обычного LLM‑запроса, RAG‑слоя или классического сервиса с чёткими правилами. Агентная архитектура окупается там, где есть высокая вариативность задач, необходимость адаптации по ходу выполнения и ценность частичной автоматизации сложных, слабо формализованных процессов.
К агенту в проде требования простые: не терять деньги, данные и нервы команды. Ниже — концентрированный чек-лист и базовый шаблон, с которого разумно начинать.
Минимальный прод-вариант может выглядеть так:
Всё остальное (сложные воркфлоу, многоагентность, стриминг и т.п.) добавляется только после того, как этот базис стабильно работает.
Повторы и идемпотентность
Состояние и переходы
Контракты инструментов и данных
Ошибки, таймауты, деградация
Наблюдаемость и тесты
Конфигурация и запуск
Надёжность здесь — не «магия ИИ», а дисциплина: код-ревью на промпты и схемы, контроль изменений конфигурации, регулярный просмотр логов и инцидентов. Команда, которая следует этому чек-листу, получает не эксперимент, а рабочий продукт.
Начните с минимально полезного и наблюдаемого сценария.
Когда один сценарий стабилен, расширяйте набор задач и инструментов поэтапно, а не «включайте всё сразу».
Используйте агента только там, где нужна вариативность и принятие «мягких» решений.
Оставьте обычный LLM / RAG / правила если:
Имеет смысл агентная архитектура, если:
Цель — чтобы повторный вызов не создавал новых побочных эффектов.
Основные приёмы:
Контракт должен быть одинаково понятен и коду, и модели.
Нужно ограничивать и глубину рассуждений, и обращения к внешним ресурсам.
Что контролировать:
Сделайте минимальный, но связный набор сигналов.
Минимум, что стоит внедрить сразу:
Разделите тестирование на уровни и держите изменение под контролем.
Для авто-действий нужен более жёсткий контроль, чем для «советника».
Подход тот же, что и в микросервисах, но с учётом состояния агента.
На проблемы часто указывают повторяющиеся симптомы.
Обратите внимание, если вы видите:
Практический фильтр: если можно честно описать задачу как конечный автомат или набор if/else — начните с этого, а агента добавляйте только для плохо формализуемых участков (например, общение с пользователем или выбор стратегии).
Idempotency key:
operation_id (или берёте внешний request_id);Запись операций в БД:
operation_id вместо «insert всегда»;pending/success/failed) и параметры вызова.Логика агента:
operation_id;success — не выполняете действие повторно, а берёте сохранённый результат;Контракты инструментов:
idempotency_key в схеме;Так вы можете смело добавлять ретраи без риска двойных платежей и дубликатов заявок.
Формализуйте контракт:
status и ограниченный error_code, а не только текст ошибок.Встроите контракт в промпты:
Валидация:
Эволюция:
v1, v2), если меняется смысл полей.Так агент перестаёт «угадывать» формат и работает по тем же правилам, что обычные сервисы.
Время и шаги:
Токены и вызовы моделей:
Инструменты:
Конфигурация:
Агент должен уметь честно завершать сценарий при превышении бюджетов и объяснять пользователю, что было сделано и что осталось несделанным.
Корреляция:
trace_id / request_id / task_id во всех логах;step_id, имя агента, имя инструмента.Логи:
Метрики:
tool_error_rate);Алерты:
Это уже позволяет быстро локализовать: «сломался агент целиком, один сценарий или конкретный инструмент».
Юнит‑тесты промптов:
temperature=0 или используйте записанные ответы;Тесты контрактов:
Сценарные тесты (record & replay):
Эксперименты в проде:
Так изменения промптов проходят тот же цикл, что и код: тесты, review, поэтапный rollout.
Ограничьте зону ответственности:
Добавьте явную верификацию:
Лимиты и аудит:
Постепенный rollout:
Важно, чтобы в любой момент можно было быстро отключить автодействия через feature flag или конфиг.
Для данных и состояния:
schema_version), чтобы агент понимал, как интерпретировать запись.Для инструментов:
/tool/v1, /tool/v2);Для самого агента:
Ключевой принцип — не менять сразу и схему БД, и контракты инструментов, и логику агента. Делайте маленькие, совместимые шаги, каждый из которых можно откатить.
Хаотичные, плохо воспроизводимые сбои:
Сверхсложный промпт:
Нет явных состояний и шагов:
while not done;Инструменты ведут себя непредсказуемо:
Быстрые шаги по исправлению:
Уже этих мер обычно достаточно, чтобы превратить «магический скрипт» в управляемую систему.