Сравниваем Nginx и HAProxy как reverse proxy: балансировка, SSL/TLS, L4/L7, наблюдаемость и сценарии, чтобы выбрать подходящий вариант.
Reverse proxy — это «входная дверь» для вашего приложения: пользователи обращаются к одному публичному адресу, а прокси уже решает, куда именно отправить запрос внутри инфраструктуры. В результате бэкенды можно менять, масштабировать и обслуживать без того, чтобы клиентам приходилось знать о внутренней архитектуре.
Во-первых, это SSL/TLS: прокси принимает HTTPS‑соединение, управляет сертификатами и шифрованием, а до внутренних сервисов может передавать трафик по приватной сети (иногда тоже по TLS — по требованиям безопасности).
Во-вторых, балансировка нагрузки. Когда один сервер уже не справляется, добавляют несколько экземпляров приложения, а reverse proxy распределяет запросы между ними — равномерно, по весам, по состоянию сервера или с «прилипанием» сессий, если это нужно.
В-третьих, маршрутизация. По домену, пути (/api, /static), заголовкам или другим признакам можно отправлять трафик в разные сервисы: отдельно API, отдельно админку, отдельно статику. Это удобно для микросервисов, постепенных миграций и A/B‑тестов.
Также reverse proxy нередко берёт на себя ограничение частоты запросов (rate limiting), базовую защиту от подозрительных клиентов, единую точку логирования и диагностики, а иногда — кэширование и ускорение раздачи статических файлов.
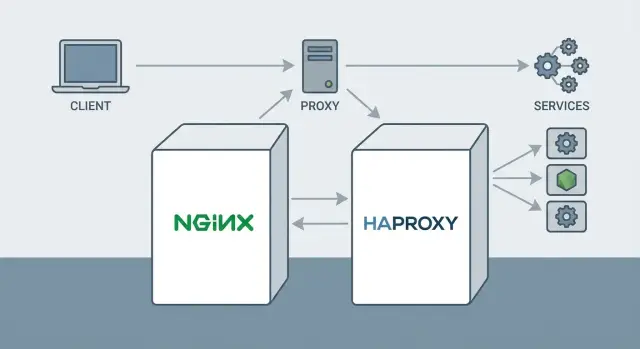
Оба инструмента часто оказываются на одном и том же участке схемы — на границе между интернетом и приложением — и закрывают похожие потребности: принять трафик, безопасно обработать соединение и передать его дальше. Поэтому выбор возникает почти автоматически, особенно когда нужно и «умно» маршрутизировать HTTP, и надёжно балансировать, и контролировать доступ.
Выбор обычно очевиден, если нужен универсальный веб‑фронт с удобной работой со статикой и простыми правилами обработки HTTP — чаще смотрят в сторону Nginx.
Если же главные критерии — гибкая балансировка, продвинутые проверки бэкендов и тонкий контроль поведения прокси под нагрузкой, многие команды склоняются к HAProxy.
Но в реальных системах граница размыта: требования смешанные, и дальше важно разбирать конкретный профиль трафика, протоколы и эксплуатационные привычки команды.
Выбор между Nginx и HAProxy часто сводится не к тому, «какой лучше», а к тому, какую роль reverse proxy должен играть рядом с приложением: больше «веб‑сервер и фронт» или больше «балансировщик и прокси». Оба решения зрелые, широко применяются в продакшене и могут работать на уровнях L4 и L7 — но с разными акцентами.
Nginx исторически воспринимается как веб‑сервер, который отлично справляется со статикой, кэшем и ролью edge‑прокси перед приложениями. В типовой схеме он принимает входящий HTTP‑трафик, делает терминацию SSL/TLS, может обслужить часть контента сам (например, файлы, кэшируемые ответы), а остальное проксировать на бэкенды.
При этом Nginx нередко используют и для балансировки нагрузки на уровне L7 (HTTP), особенно когда важны маршрутизация по host/path, работа с заголовками и желание держать «всё в одном» компоненте.
HAProxy изначально заточен под высокопроизводительное проксирование и балансировку нагрузки. Его часто выбирают, когда на первом месте: предсказуемая работа балансировщика, тонкая настройка алгоритмов распределения трафика, health checks, высокая доступность и контроль соединений. На практике HAProxy одинаково уверенно используют и как L4‑балансировщик (TCP), и как L7‑прокси для HTTP.
В VM‑окружениях оба инструмента ставят отдельным слоем перед приложениями. В контейнерах их часто запускают как ingress/edge‑компонент — важно лишь продумать конфигурацию, обновления и наблюдаемость (логи, метрики), а также сценарии отказа и отката.
Перед сравнением Nginx vs HAProxy зафиксируйте требования: какие протоколы нужны (HTTP/2, HTTP/3), где будет терминация SSL/TLS, какой профиль нагрузки (короткие запросы или долгие соединения), какие health checks обязательны, требуется ли rate limiting, и кто будет поддерживать конфигурацию в вашей команде.
Разница между L4 и L7 — не про «что современнее», а про то, на каком уровне прокси принимает решения.
L4‑прокси работает на уровне транспортного протокола (обычно TCP). Он видит IP/порт, устанавливает соединение с бэкендом и «прокачивает» байты туда‑обратно, не разбирая HTTP‑заголовки и URL.
Это удобно, когда:
HAProxy исторически очень силён в L4‑балансировке: гибкие алгоритмы, тонкие таймауты, удобные проверки доступности и сценарии failover для TCP‑сервисов.
L7‑прокси работает на уровне приложения: разбирает HTTP, видит host, path, заголовки, cookies, методы, может принимать решения по содержимому запроса и ответа.
Здесь Nginx особенно удобен как HTTP‑прокси и роутер:
/api → сервис A, /static → сервис B);HAProxy тоже умеет L7 и часто выбирается, когда основной фокус — именно балансировка и контроль трафика на HTTP‑уровне: правила маршрутизации, ACL, распределение по пулам, детальная статистика соединений.
API (HTTP/1.1/HTTP/2): L7 даёт удобную маршрутизацию по /v1 и /v2, канареечные релизы по заголовку, отдельные лимиты на разные эндпоинты.
WebSocket: технически это HTTP‑upgrade. На практике важны корректные таймауты, поддержка upgrade и «длинных» соединений. И Nginx, и HAProxy справляются; выбор обычно упирается в то, где вам удобнее управлять HTTP‑логикой и наблюдаемостью.
gRPC: чаще требует HTTP/2 и аккуратного обращения с long‑lived потоками. Здесь полезны L7‑возможности (маршрутизация, политики), но важно убедиться, что прокси прозрачно поддерживает HTTP/2 в вашем режиме (терминация или passthrough) и правильно настроены таймауты.
Итого: L4 выбирают за универсальность и простоту транспортного уровня, L7 — когда нужно «понимать» HTTP и управлять поведением трафика на уровне запросов.
Балансировка нагрузки отвечает за две вещи: чтобы запросы распределялись «честно» между несколькими экземплярами приложения и чтобы пользователи не замечали, что часть бэкендов перегружена или временно недоступна.
Самые популярные варианты:
В практических внедрениях HAProxy обычно даёт больше гибкости в выборе и комбинировании алгоритмов и правил, а Nginx часто выбирают за простоту настройки и широкую распространённость.
Sticky sessions («прилипание» пользователя к одному бэкенду) нужны, если приложение хранит состояние сессии локально на сервере и не может быстро разделить его через Redis/БД.
Минусы:
Если есть возможность, лучше выносить состояние в общее хранилище и использовать обычную балансировку.
Политику отказов лучше продумать заранее:
TLS на reverse proxy обычно решает две задачи: шифрование «на входе» (терминация) и контроль параметров безопасности (протоколы, шифры, заголовки). И Nginx, и HAProxy умеют терминировать TLS и проксировать дальше уже обычный HTTP — это упрощает бэкенды и централизует настройки.
Nginx часто выбирают как edge‑прокси: TLS‑настройки читаются прямолинейно (сертификат/ключ, версии TLS, шифры), а дальше в том же месте можно включить HTTP/2 и настроить заголовки. Плюс — привычная многим модель конфигов (включения через include, отдельные server‑блоки).
HAProxy тоже уверенно закрывает TLS‑терминацию и многим нравится за единый, достаточно строгий стиль конфигурации и за то, что балансировка и политика маршрутизации находятся рядом с TLS‑настройками. На практике «проще» зависит от центра управления трафиком: если это балансировка и правила — часто удобнее HAProxy; если ещё и фронт (статика/кэш/простые редиректы) — чаще Nginx.
HTTP/2 сегодня базовый минимум для браузерного фронта и нередко для публичных API: мультиплексирование снижает накладные расходы на множество запросов. И Nginx, и HAProxy поддерживают HTTP/2 (важно проверить режим: «frontend HTTP/2 → backend HTTP/1.1» — самый частый сценарий).
HTTP/3 (QUIC) может дать выгоду на мобильных сетях и при потере пакетов, но экосистема ещё догоняет. Поддержка есть в новых версиях обоих решений, однако часто она требует свежих сборок и внимательного тестирования. Если HTTP/3 — must‑have, заложите время на пилот и понятный план отката.
Сертификаты обычно живут вне прокси (ACME‑клиент вроде certbot/acme.sh, корпоративный PKI), а Nginx/HAProxy лишь подхватывают файлы.
fullchain.includeSubDomains и без больших сроков), потому что откат HSTS всегда болезненный.TLS добавляет стоимость рукопожатия и шифрования трафика: это CPU, задержки на handshake и память под сессии.
Что реально помогает:
В итоге выбирать стоит не «кто быстрее шифрует», а кто проще вписывается в вашу схему обновления сертификатов, требования по протоколам (HTTP/2/HTTP/3) и операционный процесс без простоев.
Reverse proxy часто становится «единой точкой входа» для пользователей, поэтому умение вовремя заметить проблемы на бэкендах и правильно пережить сбой критично.
Активные проверки — прокси сам регулярно обращается к бэкенду (например, по HTTP‑эндпоинту) и фиксирует статус. Это позволяет отлавливать ситуации, когда сервис отвечает ошибками, зависает или «подвис» после деплоя.
Пассивные проверки — решение принимается по реальному трафику: если на запросы пользователей бэкенд начинает отвечать 5xx/таймаутами, прокси помечает его проблемным. Такой подход проще, но «узнаёт» о проблеме, когда уже есть пострадавшие запросы.
На практике HAProxy исторически сильнее в гибких проверках (порог ошибок, окна времени, разные режимы), а Nginx чаще используют в сочетании с таймаутами/повторами и внешними проверками (оркестратор, сервис‑дискавери, мониторинг).
Отказоустойчивость — это не только «выкинуть» бэкенд из пула, но и сделать это аккуратно:
Когда бэкенд деградирует, важно не добить его волной ретраев. Здесь помогают ограничения соединений, очереди и таймауты на стороне прокси. HAProxy обычно даёт более «тонкие» механизмы очередей/лимитов на уровне балансировщика; в Nginx сопоставимое поведение достигается комбинацией лимитов и корректных таймаутов.
Хорошо настроенный прокси превращает хаос в понятные сценарии: часть пользователей получит чуть более высокую задержку (очередь), кто‑то — аккуратную ошибку 503 с быстрым ответом, а не бесконечное ожидание. Цель — чтобы система вела себя предсказуемо и восстанавливалась без ручных «пинков».
Reverse proxy часто выбирают не только за балансировку, но и за то, насколько удобно «разрулить» HTTP‑трафик: куда отправить запрос, что отдать сразу, а что — проксировать дальше.
Если у вас несколько сервисов за одним входным адресом, маршрутизация уровня L7 становится ключевой. Типичный сценарий — разные домены или поддомены (api.example.com и app.example.com), либо разнесение по путям (/api, /auth, /static).
Nginx традиционно силён в таких задачах: конфигурация под «виртуальные хосты» и location‑правила читается как карта маршрутов. Это удобно, когда нужно смешивать условия: путь + метод + заголовки, или аккуратно обработать исключения (например, один конкретный endpoint отправить на отдельный upstream).
HAProxy тоже умеет продвинутую L7‑маршрутизацию через ACL (по Host, path, headers, cookies). Он часто выигрывает там, где правил много и они должны быть максимально явными и проверяемыми: ACL дают структурность, а поведение проще стандартизировать в команде.
Переписывание путей нужно, когда внешние URL не совпадают с внутренними (например, /api/v1 → /). Редиректы — для канонизации (http→https, без www→с www) или миграций.
Здесь Nginx обычно воспринимается как более «веб‑серверный»: редиректы и rewrite — привычные инструменты. HAProxy тоже поддерживает редиректы и манипуляции с заголовками/путями, но при сложных правилах конфигурация может быть менее интуитивной для тех, кто привык мыслить категориями location.
Кэш на reverse proxy полезен, если много повторяющихся запросов к одинаковым ресурсам (каталоги, публичные API, страницы без персонализации). Но он добавляет риски: устаревшие данные, сложность инвалидации, тонкая настройка Cache‑Control.
Практически: Nginx чаще выбирают, когда нужен встроенный HTTP‑кэш «из коробки». В HAProxy кэширование не является основной стороной: обычно его комбинируют с отдельным cache/CDN‑слоем, если это критично.
Если proxy должен ещё и раздавать статику (CSS/JS, изображения, precompressed файлы, fallback для SPA), Nginx — естественный кандидат: он умеет эффективно отдавать файлы, выставлять заголовки и управлять cache‑policy.
HAProxy чаще используют как «чистый» прокси/балансировщик перед приложениями, а раздачу статики выносят в Nginx, CDN или объектное хранилище. Такое разделение ролей нередко упрощает конфигурацию и снижает риск неожиданных побочных эффектов.
Reverse proxy часто становится «первой линией» перед приложением, поэтому базовые ограничения лучше задавать именно здесь: это дешевле по ресурсам, быстрее реагирует на всплески и снижает шанс, что до бэкенда дойдёт мусорный трафик.
И Nginx, и HAProxy умеют ограничивать частоту запросов/соединений, что полезно против:
Практика: лимит обычно задают по IP, по ключу (например, API‑token) или по группам URI. Важно отдельно продумать реакцию (429, задержка, бан на N минут) и исключения для доверенных сетей.
Контроль доступа на уровне прокси удобен, когда правила простые и стабильные:
В Nginx это часто делают директивами allow/deny и маппингом правил. В HAProxy — ACL‑правилами, которые удобно комбинировать (например, «путь + заголовок + источник»).
Прокси — хорошее место, чтобы централизованно добавить/проверить security headers для веб‑части:
X-Content-Type-Options, X-Frame-Options / CSP;Также стоит «ужимать поверхность»: не светить версии серверов, ограничивать методы (например, запретить TRACE), аккуратно настраивать доверие к X-Forwarded-* (чётко определить, кто может их присылать).
Прокси не заменяет полноценный WAF/IDS. Если нужна защита от сложных атак (SQLi/XSS сигнатуры, виртуальные патчи, поведенческий анализ, бот‑менеджмент), лучше подключать WAF (внешний или встроенный в инфраструктуру) и использовать прокси как место для базовых, предсказуемых правил. Такое разделение снижает риск «самодельной» фильтрации, которая ломает легитимный трафик.
Хороший reverse proxy — это не только «пропускает трафик», но и объясняет, что именно произошло, когда пользователи жалуются на ошибки или медленную работу. Наблюдаемость складывается из логов, метрик и удобной диагностики проблем между клиентом и бэкендом.
В access‑логах ценны не «кто пришёл», а «как прошёл запрос»: код ответа, размер, время обработки и что происходило с апстримом. Полезно, когда в логах есть:
X-Forwarded-For/PROXY protocol);Error‑логи нужны не только при падениях. По ним часто видно таймауты, обрывы соединений, проблемы TLS‑рукопожатия, переполнение лимитов, ошибки резолвинга и несовместимость протоколов.
Для эксплуатации обычно хватает нескольких «витрин»: p95/p99 задержки, доля 4xx/5xx, количество активных соединений, очередь/лимиты, а также состояние бэкендов (up/down, число фейлов, время восстановления). Важно смотреть метрики раздельно: по фронтенду (клиенты) и по апстриму (бэкенды) — иначе трудно понять, где именно «узкое место».
Подход, который работает почти всегда: отдавать метрики в Prometheus (напрямую или через exporter), логи — в централизованное хранилище (ELK/Opensearch/Loki), а корреляцию — через request id (и при необходимости OpenTelemetry на уровне приложений). Ключевое — единые теги: service, route, upstream, status.
Начинайте с симптома: всплеск 5xx или рост p95. Затем проверьте, на чьей стороне задержка (прокси vs апстрим), не «посыпались» ли конкретные бэкенды, не упёрлись ли в лимиты соединений/файловых дескрипторов, и нет ли изменений в конфигурации или сертификатах. Если request id проходит через все компоненты, поиск конкретного проблемного запроса занимает минуты, а не часы.
Даже самый быстрый прокси не поможет, если его сложно безопасно менять. В ежедневной эксплуатации важны читаемость конфигов, предсказуемые обновления и понятный процесс внесения правок — особенно когда над этим работает несколько людей.
У Nginx конфигурация обычно «декларативная» и знакома многим: блоки http/server/location, директивы и включения файлов. Ошибки в проде часто связаны с приоритетами матчинга location, наследованием директив и неожиданными эффектами rewrite/try_files.
У HAProxy конфиг более «табличный»: фронтенды/бекенды, ACL и правила маршрутизации. Частые промахи — порядок правил (что сработает раньше), слишком широкие ACL и несоответствие таймаутов реальным ожиданиям приложения.
Практический совет: держите рядом с конфигом короткий документ «как у нас маршрутизируется трафик» и примеры запросов, чтобы новичку было проще проверять логику.
Оба инструмента позволяют применять изменения без заметных даунтаймов, если делать это правильно.
Ключевой момент для команды: зафиксируйте единый «правильный» способ reload/rollback и автоматизируйте его, чтобы не было разночтений.
Если конфиги генерируются (Ansible, Helm, Kustomize), важнее не инструмент, а дисциплина:
Внедрите обязательные проверки в CI:
nginx -t или haproxy -c -f …;Так эксплуатация становится не «магией админа», а воспроизводимым процессом, который выдерживает рост команды и числа сервисов.
На практике выбор reverse proxy часто всплывает не «в вакууме», а на этапе, когда вы быстро собираете прототип или первую прод‑версию сервиса: появляется фронтенд, API, авторизация, нужно разнести маршруты (/api, /admin, статика), включить HTTPS и базовые лимиты.
Если вы делаете продукт через TakProsto.AI (vibe‑coding платформа для российского рынка), часть рутинной работы можно ускорить: в чате описать архитектуру, получить каркас приложения (типично React на вебе, Go + PostgreSQL на бэкенде, Flutter для мобильных клиентов) и параллельно сформировать «первую версию» схемы входного трафика — какие домены/пути куда идут, где терминируется TLS, какие таймауты и лимиты нужны. Дальше удобно двигаться итерациями: включать planning mode для планирования изменений, а при правках инфраструктуры опираться на snapshots и rollback, чтобы безопасно откатываться. При необходимости можно экспортировать исходники и развернуть всё у себя.
Споры «Nginx быстрее HAProxy» почти всегда упираются в детали: какой протокол, какие таймауты, сколько keep‑alive, есть ли TLS, какой размер ответов и как ведёт себя бэкенд. Поэтому сравнивать стоит не «в целом», а под ваш профиль трафика и требования к надёжности.
На практике полезнее всего измерять несколько метрик одновременно:
Отдельный сигнал — ошибки и ретраи: рост 4xx/5xx, таймауты, сбросы соединений. Высокий RPS не радует, если p99 расползается или появляются таймауты.
Nginx часто показывает сильные результаты в HTTP‑сценариях, где важны работа со статикой, буферизация и кэширование, а также гибкая маршрутизация на уровне запросов.
HAProxy традиционно хорош там, где нужно много соединений и предсказуемая балансировка с тонкой настройкой, а также когда критичны детальные health checks и поведение при деградациях.
Но итог почти всегда упирается в конфигурацию: один и тот же продукт может стать «быстрым» или «медленным» из‑за таймаутов, буферов, лимитов и режима логирования.
Чтобы результаты были сравнимыми:
Смотрите на баланс: если решение даёт +10% throughput, но увеличивает p99 вдвое или требует заметно больше CPU, это спорная «победа». Отдельно проверяйте поведение при пиках, медленных клиентах и частичных отказах бэкендов — именно там чаще проявляются различия, которые в среднем RPS не видны.
Выбор между Nginx и HAProxy проще, если не сравнивать «кто круче», а начать с вашей задачи: вы строите веб‑слой с раздачей статики и кэшем или центр тяжести — в балансировке, маршрутизации и контроле трафика.
Nginx часто выигрывает, когда reverse proxy — часть «веб‑фронта»: нужно отдавать статику, включать простое кэширование, удобно настраивать правила для URL и заголовков, держать понятную конфигурацию для команды.
Учитывайте:
HAProxy обычно выбирают, когда ключевое — предсказуемая балансировка, тонкие политики маршрутизации, управление соединениями и удобные health checks, а прокси — отдельный слой в архитектуре.
Проверьте заранее:
Если 5–7 пунктов ниже про вас — это хороший «маяк» выбора:
Миграция между ними обычно безопасна, если двигаться поэтапно: поднять второй прокси параллельно, переключать часть трафика постепенно (через балансировку/DNS), держать быстрый откат и заранее унифицировать TLS‑настройки и таймауты, чтобы сравнение было честным.
Reverse proxy — это публичная точка входа, которая принимает запросы от клиентов и проксирует их во внутренние сервисы.
Практически это даёт:
Если ваш proxy выполняет роль «веб-фронта» (статика, простые редиректы, кэш, удобная маршрутизация по server/location) — чаще проще жить с Nginx.
Если ключевое — предсказуемая балансировка, продвинутые health checks, тонкий контроль соединений/таймаутов и явные правила маршрутизации через ACL — чаще логичнее HAProxy.
На практике выбор упирается в ваш профиль трафика и то, что команда готова поддерживать ежедневно.
L4 (TCP) проксирует соединение «как есть»: proxy видит IP/порт и пересылает байты, не разбирая HTTP.
L7 (HTTP) разбирает запрос: Host, path, заголовки, cookies — и может маршрутизировать «умнее».
Выбирайте L4, если балансируете не-HTTP (например, PostgreSQL/Redis) или хотите минимум логики. L7 — если нужны правила по URL/заголовкам, канареечные релизы, разные политики для разных эндпоинтов.
Частые варианты:
Практика: начните с round-robin или leastconn, а затем подтверждайте выбор метриками (p95/p99, ошибки, перегрев отдельных узлов).
Sticky sessions нужны, когда состояние сессии хранится локально на узле и вы не можете быстро вынести его в общее хранилище.
Риски:
Если есть возможность, переносите состояние в Redis/БД и используйте обычную балансировку без прилипания.
Самый частый сценарий — терминировать TLS на reverse proxy, а внутрь отдавать HTTP по приватной сети.
Чек-лист практики:
fullchain), иначе часть клиентов будет ругаться;max-age, без includeSubDomains на старте);HTTP/2 обычно уже must-have для фронта и часто для публичных API: мультиплексирование уменьшает накладные расходы.
HTTP/3 (QUIC) может помочь в мобильных сетях, но часто требует более свежих версий/сборок и тщательного тестирования.
Практически:
Health checks бывают:
/health) и заранее исключает проблемные узлы;Для устойчивости важны не только проверки, но и политика возврата:
Rate limiting имеет смысл ставить на proxy, потому что это дёшево и быстро «срезает» мусор до бэкенда.
Практические шаги:
429, задержка, временный бан;X-Forwarded-For/PROXY protocol: определите, кто имеет право их присылать, иначе лимиты будут обходиться.Для поддержки важнее всего видеть «путь запроса» через proxy:
По метрикам держите минимум витрин:
Так вы быстрее отличите «проблема в proxy» от «проблема в приложении/БД».