Кто такой Ноам Шазир и почему Transformer стал стандартом: внимание, энкодер‑декодер, ключевые блоки, масштабирование и применение в LLM.
Transformer — архитектура нейросети, которая научилась работать с текстом (и не только) иначе, чем прежние модели. Вместо того чтобы читать фразу строго слева направо и «тащить» информацию через длинную цепочку шагов, Transformer смотрит на все токены одновременно и решает, что в данном контексте действительно важно. Поэтому о нём постоянно говорят, когда обсуждают современные LLM: большинство крупных языковых моделей — это вариации Transformer.
Главный практический эффект — качество и масштабирование. Когда модель может быстро «сопоставлять» слова и смыслы по всему предложению, ей проще понимать связи вроде: кто что сделал, к чему относится местоимение, где причина и следствие. А ещё такую архитектуру удобно обучать на огромных объёмах данных на современных ускорителях: параллельность заложена в саму идею.
Ноам Шазир (Noam Shazeer) — один из ключевых авторов статьи «Attention Is All You Need» (2017), где Transformer был описан и показан как рабочая альтернатива предыдущим подходам. Его вклад важен не как «случайная деталь истории», а как часть инженерного и исследовательского поворота: внимание (attention) перестало быть вспомогательной надстройкой и стало центром архитектуры.
Без погружения в матанализ вы разберётесь:
До появления Transformer в задачах языка доминировали рекуррентные модели — RNN и их более «прокачанные» версии LSTM/GRU. Они дали большой рывок по сравнению с классическими n-граммами, но по мере роста объёма данных и ожиданий от качества стали заметны их системные ограничения.
Главная особенность RNN/LSTM — они читают текст строго по одному токену за шаг: сначала слово №1, потом №2 и так далее. Из‑за этого обучение плохо параллелится: GPU может эффективно перемножать большие матрицы, но не любит длинные цепочки зависимых операций, где следующий шаг зависит от результата предыдущего.
На практике это означало: дольше эпохи обучения, сложнее масштабировать модель по длине текста и по размеру датасета, выше стоимость экспериментов.
Теоретически LSTM умеет «помнить» далёкий контекст благодаря механизму «ячеек памяти». Но в реальных задачах сигнал из начала длинного предложения часто «размывался» — модели становилось труднее связать местоимение с существительным через несколько строк или удержать тему абзаца.
Это особенно заметно в длинных документах, диалогах и текстах, где важны отсылки назад: юридические формулировки, инструкции, научные статьи.
Когда данные стали измеряться миллиардами токенов, а модели — сотнями миллионов параметров, скорость обучения превратилась в ключевой фактор прогресса. Хотелось обучать на больших батчах, распределять вычисления по многим GPU и не упираться в «узкое горлышко» последовательных шагов.
Рекуррентные сети именно в это упирались: даже при распределённом обучении их природа ограничивала выигрыш.
Задачи машинного перевода, суммаризации и ответа на вопросы требуют одновременно двух вещей: видеть широкий контекст (чтобы не терять смысл) и точно выстраивать соответствия между частями текста (например, согласование рода/числа, перевод устойчивых выражений, связь причины и следствия).
Модели до Transformer могли справляться, но часто ценой сложных трюков (внимание поверх RNN, глубокие стеки, хитрые регуляризации) и всё равно с ограничениями по скорости и качеству на длинных зависимостях.
Transformer перевернул привычный подход к обработке текста: вместо того чтобы «читать» фразу шаг за шагом, модель сразу рассматривает все токены и решает, какие из них важны друг для друга. Это и есть внимание — механизм, который распределяет «фокус» по входному тексту.
Ранние подходы часто были завязаны на последовательность: слово за словом, состояние за состоянием. В Transformer центральным становится вопрос не «что было до этого?», а «с чем это слово связано прямо сейчас?». Модель строит связи между токенами напрямую, даже если они далеко друг от друга в предложении.
Фраза «Attention is all you need» не означает, что в модели больше ничего нет. Смысл в другом: внимание — главный механизм, который позволяет понимать контекст и зависимости, а не вспомогательная деталь. Если модель умеет правильно расставлять фокус, она может собрать смысл из текста эффективнее, чем при строгом пошаговом чтении.
Когда модель не обязана обрабатывать токены строго по очереди, вычисления можно распараллелить. На практике это значит: быстрее обучение на больших датасетах и лучшее использование современных GPU/TPU. Вместо длинной «очереди» операций многие расчёты выполняются одновременно.
Возьмём фразу: «Маша положила книгу на стол, потому что он был устойчивым». Чтобы понять, к чему относится «он», внимание усилит связь между «он» и «стол», а не с «книга» или «Маша». Именно такие «подсветки» по всему предложению помогают Transformer выбирать правильные зависимости при ответе или продолжении текста.
Self-attention — способ для модели «посмотреть» на весь текущий фрагмент текста и решить, какие слова важны друг для друга. В отличие от последовательных подходов (где информация проталкивается шаг за шагом), self-attention сравнивает токены параллельно: каждый токен оценивает, на какие другие токены ему стоит опереться, чтобы уточнить смысл.
У каждого токена (условно «слова») есть три представления:
Дальше модель сравнивает Query текущего токена с Key всех токенов в контексте и получает веса внимания: чем выше совпадение, тем больше доля Value этого токена попадёт в итоговое представление.
Классическое внимание часто описывают как «подсказку» между двумя частями модели (например, декодер смотрит на энкодер). Self-attention работает внутри одной и той же последовательности: токены «консультируются» друг с другом, чтобы понять, к чему относится местоимение, где граница устойчивого выражения, что является уточнением и т. п.
Сходство Q и K обычно считают скалярным произведением. При большой размерности векторов значения могут становиться слишком крупными, и softmax начинает «залипать» на нескольких позициях. Поэтому используют масштабирование: делят на \(\sqrt{d_k}\). Практически это делает распределение внимания стабильнее и обучение — предсказуемее.
Self-attention напрямую зависит от того, сколько токенов модель «видит» одновременно. Чем длиннее контекст, тем лучше она удерживает нити разговора, сопоставляет факты из разных частей текста и реже просит повторить вводные.
Ограничение контекста заметно пользователю как потеря деталей: модель забывает ранние условия, путает ссылки на предыдущие абзацы или неверно продолжает стиль.
Если бы внимание было «одним прожектором», модель каждый раз подсвечивала бы только один набор связей между токенами — и часто выбирала бы самое очевидное. Multi-head attention делает иначе: оно запускает несколько независимых «прожекторов» параллельно, чтобы одновременно увидеть разные отношения в одной и той же фразе.
Технически это выглядит так: вместо одного вычисления внимания модель проецирует представления токенов в несколько пространств (для каждой головы свои матрицы), считает attention отдельно, а затем склеивает результаты и смешивает их в общий вектор. Пользователю это важно не из‑за формул, а из‑за эффекта: меньше пропущенных смысловых нюансов.
В одном предложении могут одновременно жить разные связи:
Одна голова может «специализироваться» на согласовании, другая — на разрешении местоимений, третья — на устойчивых сочетаниях. Это не жёсткое правило, но на практике такие паттерны часто обнаруживаются при анализе.
Несколько голов почти всегда дают лучшее качество, но стоят дороже: больше матричных операций и памяти. Поэтому в моделях подбирают число голов и размерность так, чтобы выигрыш в понимании текста оправдывал цену по скорости.
В длинной фразе важно удерживать сразу несколько «нитей» смысла. Multi-head attention помогает не «залипать» на ближайших словах: одна голова может держать общий смысл абзаца, другая — локальную грамматику, третья — редкие, но важные дальние связи. В результате модель точнее понимает, что к чему относится, и реже путается в сложных конструкциях.
Transformer часто объясняют как «два блока, которые разговаривают друг с другом»: энкодер понимает вход, а декодер по этому пониманию пишет выход. Эта схема особенно понятна на задачах, где один текст превращается в другой — например, перевод или краткое изложение.
Энкодер получает последовательность токенов (например, предложение на английском) и пропускает её через несколько слоёв self-attention и небольших полносвязных сетей. На выходе получается не «одна строка смысла», а набор векторов — по одному на каждый токен, но уже «обогащённых» контекстом.
Важно: энкодер не генерирует текст. Его задача — построить представление, с которым удобно работать дальше: понять связи, уточнить значения слов по контексту, выделить важные части.
Декодер работает как писатель: он выдаёт текст по одному токену. При этом он смотрит:
В переводе это выглядит естественно: энкодер «прочитал» исходную фразу, декодер «пишет» перевод, постоянно обращаясь к прочитанному.
Энкодер‑декодер классически используют в машинном переводе и суммаризации, где вход и выход — разные тексты.
Многие современные LLM стали в основном «декодер-онли», потому что их ключевая задача — продолжать текст (next-token prediction) по уже имеющемуся контексту. Это проще унифицируется под чат, письмо, кодинг и ответы на вопросы: одна модель, один режим генерации, без отдельного энкодера.
Механизм self-attention отлично находит связи между токенами, но сам по себе он «не знает», в каком порядке эти токены стоят. Для него фраза «собака укусила человека» и «человек укусил собаку» выглядит как один и тот же набор токенов, если не добавить сигнал о позиции.
Порядок влияет на смысл, грамматику и даже на то, к чему относится местоимение. Attention умеет сравнивать токены между собой, но без подсказки он не отличит «первое слово» от «последнего». Поэтому к представлению каждого токена добавляют информацию о его месте в последовательности — так модель получает и «что это за токен», и «где он стоит».
Позиционный эмбеддинг — вектор, который кодирует номер позиции (0, 1, 2, …). Его складывают с эмбеддингом токена (или добавляют иным способом), и дальше attention работает уже с суммой: токен + позиция. Интуитивно это похоже на координаты на карте: два одинаковых «объекта» в разных точках — это разные ситуации.
Фиксированные позиционные эмбеддинги задаются формулой (часто синусами/косинусами). Плюс: они могут лучше обобщать на длины, которых модель не видела при обучении.
Обучаемые — это таблица векторов, которая настраивается вместе с моделью. Плюс: гибкость и способность подстроиться под данные, но хуже перенос на более длинные последовательности, если позициям «за пределами» просто не хватило обучения.
Когда контекст растёт, модели нужно не только помнить факты, но и понимать расстояния: что было «недавно», а что «давно», где начинается цитата, к какому абзацу относится вывод. Позиционная схема напрямую влияет на то, насколько уверенно Transformer держит структуру текста на больших длинах — именно поэтому в современных LLM так много внимания уделяют улучшенным способам кодировать позиции.
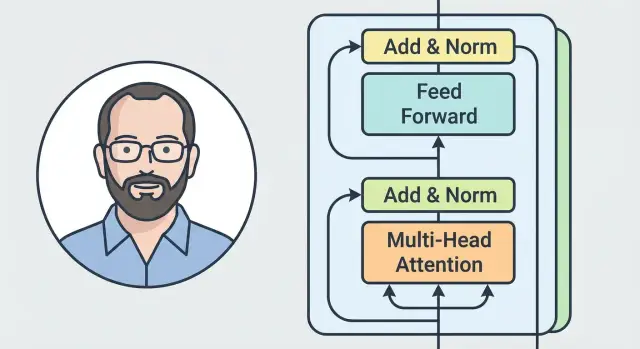
В Transformer внимание отвечает за «с кем и насколько связан» каждый токен. Но одного внимания недостаточно: после того как модель собрала контекст, ей нужно преобразовать полученную информацию в более полезные признаки для следующего слоя. Эту работу и выполняют FFN, остаточные связи и нормализация.
FFN (Feed-Forward Network) — небольшой одинаковый для всех позиций блок из двух линейных преобразований с нелинейностью между ними. Если внимание смешивает информацию между токенами, то FFN «дорабатывает» результат локально — отдельно для каждого токена.
Интуитивно: внимание решает, что взять у других токенов, а FFN решает, как именно это превратить в удобное представление (например, усилить важный сигнал, подавить шум, «сжать» или «развернуть» признаки). Благодаря этому слой становится более выразительным, чем просто внимание.
Остаточная связь (residual) добавляет вход блока к его выходу: модель как бы учится не «строить всё заново», а вносить поправки.
Практический эффект простой: градиентам легче проходить через много слоёв, сеть стабильнее обучается, а полезные базовые признаки меньше теряются при глубоком стеке блоков.
LayerNorm нормализует активации внутри каждого токена. Это снижает риск того, что значения «разъедутся» по масштабам от слоя к слою.
В результате обучение становится более предсказуемым: проще подобрать скорость обучения, меньше срывов и перепадов качества.
Комбинация работает как конвейер: внимание собирает контекст, FFN превращает его в богатые признаки, остаточные связи сохраняют полезный сигнал и облегчают обучение, а LayerNorm поддерживает численную стабильность. Поэтому Transformer можно делать глубоким и эффективно обучать на больших данных — ключевое свойство для масштабирования LLM.
Когда Transformer работает как генератор текста (как в GPT‑подобных моделях), ему нельзя «видеть» слова справа — те, которые ещё не сгенерированы. Для этого используется каузальное (causal) внимание: модель смотрит только на прошлое и на текущий токен.
В декодере применяется маска (обычно треугольная матрица), которая запрещает вниманию обращаться к будущим позициям. На практике это значит: при вычислении внимания для позиции t модель может использовать информацию только из позиций ≤ t.
Если бы маски не было, модель во время обучения могла бы «считать» правильный ответ из будущих токенов и показывать отличные метрики, но при реальной генерации (когда будущего нет) качество резко бы упало.
Большинство LLM обучаются задаче next-token prediction: по контексту слева предсказать следующий токен. Каузальное внимание делает эту задачу честной: при предсказании токена на позиции t+1 модель использует только токены 1…t.
Генерация происходит итеративно:
Каузальная маска обеспечивает, что на каждом шаге модель опирается только на уже сгенерированное.
Иногда кажется, что модель «заранее знала», чем закончится фраза. На деле она просто хорошо оценивает вероятные продолжения по статистическим и смысловым подсказкам в контексте. Во время обучения правильные токены действительно присутствуют в последовательности, но маскирование не позволяет использовать их напрямую — поэтому «знание будущего» остаётся иллюзией, а не скрытым читом.
Transformer стал основой больших языковых моделей (LLM) не потому, что «умнее» сам по себе, а потому что его качество обычно предсказуемо растёт вместе с масштабом. Если дать модели больше параметров и обучающих данных, она чаще начинает лучше обобщать: запоминает меньше «в лоб», а эффективнее учится закономерностям языка. На практике это проявляется как более точные ответы, лучшее следование инструкциям и меньше странных ошибок — при условии, что вы поддерживаете качество данных и режим обучения.
Ключевой плюс — простая, повторяемая архитектура. Модель собирается из одинаковых блоков (внимание + небольшая нейросеть FFN), которые можно «наращивать» в глубину и ширину. Такая модульность хорошо дружит с современным железом: большие матричные операции легко распараллеливаются, а обучение можно распределять между многими GPU/TPU.
В результате Transformer превращается в конструктор: хотите сильнее — добавляете слои, увеличиваете размер скрытых представлений, число голов внимания, объём данных и длительность обучения. Инженерно это проще, чем архитектуры, где качество сильно зависит от хитрых, плохо переносимых приёмов.
Масштабирование не бесплатное. Обучение становится дорогим по вычислениям и энергии, а инференс — по задержке и памяти: чтобы ответить, модель должна «прокрутить» через себя много параметров.
Отдельная боль — «контекстное окно»: сколько токенов модель может учесть за один запрос. В self-attention вычисления и память растут примерно квадратично от длины контекста, поэтому длинные документы быстро упираются в ресурсы. Отсюда ограничения на размер окна и постоянные попытки сделать внимание дешевле.
Transformer отлично «понимает» связи между токенами благодаря self-attention, но у этого механизма есть цена: чем длиннее текст, тем быстрее растут вычисления и потребление памяти. Именно поэтому длинный контекст до сих пор остаётся дорогим удовольствием.
В self-attention каждый токен сравнивается с каждым другим, чтобы решить, на что «смотреть» сильнее. Если токенов вдвое больше, то пар для сравнения становится примерно в четыре раза больше.
На практике это означает простую вещь: увеличение контекста не добавляет нагрузку линейно. Модель не просто читает больше — она делает значительно больше сопоставлений внутри этого текста.
Длинный контекст бьёт по двум направлениям:
Из-за этого сервисы часто вводят ограничения: максимальное число токенов в запросе, разные тарифы на «длинный контекст» и более строгие лимиты для быстрых режимов.
Есть несколько популярных подходов, которые уменьшают цену длинного контекста:
Ограничения проявляются очень приземлённо: ответы становятся медленнее, «окно контекста» упирается в лимит, а длинные диалоги могут требовать сокращения истории или пересказа. Поэтому умение сжимать ввод и формулировать запросы компактно — не трюк, а способ экономить время и деньги.
Transformer — это не только «про большие языковые модели». Его идеи (особенно внимание и удобная для параллелизации архитектура) стали универсальным инструментом для работы с текстом — поэтому вы сталкиваетесь с ним гораздо чаще, чем кажется.
Чаще всего — там, где системе нужно понять смысл фразы, сопоставить её с контекстом и выдать ответ или действие:
Отдельный практичный сценарий — ускорение разработки: LLM на базе Transformer позволяют описывать требования текстом и быстро получать работающий прототип. Например, в TakProsto.AI (vibe-coding платформа для российского рынка) вы можете собрать веб‑, серверное или мобильное приложение через чат, а затем экспортировать исходники. Под капотом обычно используются типовые для продакшена технологии (React на фронтенде, Go + PostgreSQL на бэкенде, Flutter для мобильных приложений), а из инженерных удобств важны планирование, снапшоты и откат. Для команд также полезно, что данные и выполнение размещаются на серверах в России и используются локализованные open-source LLM — без отправки данных в другие страны.
Сильные стороны Transformer-моделей — понимание контекста, умение суммировать, переформулировать и находить связи между фрагментами текста. Они хорошо справляются с шаблонными задачами и черновиками.
Типичные ошибки тоже повторяются:
Практика, которая реально снижает риски:
Идеи, связанные с Transformer и людьми вроде Ноама Шазира, сделали модели одновременно гибкими и масштабируемыми — поэтому архитектура стала стандартом для LLM и прикладных текстовых сервисов. Для пользователя это означает больше удобных функций «понимания языка», а для инженеров и продуктов — возможность быстрее строить решения вокруг текста, диалогов и автоматизации, сохраняя при этом необходимость критически проверять результат, когда на кону точность.
Transformer — архитектура нейросети, где ключевой механизм — внимание (attention).
Вместо пошагового «чтения» токенов слева направо модель сопоставляет слова параллельно и строит связи между любыми позициями в тексте. Это ускоряет обучение на GPU/TPU и обычно улучшает работу с дальними зависимостями в тексте.
У RNN/LSTM есть два типичных ограничения:
Transformer снимает часть этих проблем за счёт параллельного внимания.
Ноам Шазир — один из ключевых авторов статьи «Attention Is All You Need» (2017), где Transformer описали как полноценную альтернативу рекуррентным архитектурам.
Практический смысл его вклада в контексте статьи: внимание стало центром архитектуры, а не вспомогательным модулем поверх RNN.
Self-attention позволяет каждому токену «посмотреть» на другие токены в том же контексте и решить, на кого опереться, чтобы уточнить смысл.
На практике это помогает:
У каждого токена есть три проекции:
Модель сравнивает Q текущего токена с K остальных, получает веса (через softmax) и собирает итог как взвешенную сумму V. Это и есть «куда модель смотрит» в данном контексте.
При большой размерности скалярные произведения Q·K могут становиться слишком большими, и softmax начинает давать слишком «острые» распределения (обучение становится менее стабильным).
Масштабирование (деление на (\sqrt{d_k})) делает значения более контролируемыми, поэтому:
Multi-head attention — это несколько независимых «взглядов» на один и тот же текст.
Пользовательский эффект обычно такой:
Цена — больше вычислений и памяти, поэтому число голов подбирают как компромисс.
Self-attention сам по себе не знает порядка токенов: без дополнительного сигнала набор слов выглядит одинаково независимо от перестановки.
Позиционные эмбеддинги добавляют информацию «где находится токен»:
В классическом Transformer для задач «текст → текст» есть энкодер (понимает вход) и декодер (генерирует выход, сверяясь с входом через cross-attention).
Во многих LLM используют decoder-only подход, потому что основная цель обучения — предсказание следующего токена по левому контексту. Это удобно унифицируется под чат, письмо, код и ответы на вопросы без отдельного энкодера.
Каузальное (causal) внимание использует маску, которая запрещает смотреть на будущие токены: позиция t видит только ≤ t.
Чтобы это работало быстрее на генерации, обычно применяют:
Так модель генерирует текст шаг за шагом без «подсматривания».